
С помощью кода создаются интерфейсы. Но и сам код — это интерфейс.
Несмотря на то, что читабельность кода очень важна, понятие это определено плохо — и часто в виде просто набора правил: использовать осмысленные имена переменных, большие функции разбивать на меньшие, применять стандартные шаблоны проектирования.
При этом наверняка всем приходилось иметь дело с кодом, который соответствует этим правилам, но почему-то представляет собой какую-то кашу.
Можно попытаться решить эту проблему, добавив новые правила: если имена переменных становятся очень длинными, нужно выполнить рефакторинг основной логики; если в одном классе накопилось множество вспомогательных методов, возможно, следует разделить его на два; нельзя применять шаблоны проектирования в неподходящем контексте.
Такие инструкции превращаются в лабиринт субъективных решений, и чтобы ориентироваться в нем, понадобится разработчик, который сможет делать правильный выбор — то есть, он уже должен уметь писать читабельный код.
Таким образом, набор инструкций — не выход. Поэтому нам придется сформировать более широкое представление о читабельности кода.
Для чего нужна читабельность
На практике под хорошей читабельностью обычно понимают, что код приятно читать. Однако на таком определении далеко не уедешь: во-первых, оно субъективно, во-вторых — привязывает нас к чтению обычного текста.
Нечитабельный код воспринимается как роман, который притворяется кодом: множество раскрывающих суть происходящего комментариев, простыни текста, которые нужно читать последовательно, умные формулировки, единственный смысл которых — быть «умными», боязнь повторного использования слов. Разработчик пытается сделать код читабельным, но нацеливается не на тот тип читателей.
Читабельность текста и читабельность кода — не одно и то же.
Переведено в Alconost
С помощью кода создаются интерфейсы. Но и сам код — это интерфейс.
Если код выглядит красиво, значит ли это, что он читабельный? Эстетичность — приятный побочный эффект читабельности, но как критерий не очень полезна. Возможно, в крайних случаях эстетика кода в проекте поможет удержать сотрудников — но с тем же успехом можно предложить хороший соцпакет. Кроме того, у каждого свое представление о том, что значит «красивый код». И со временем такое определение читабельности превращается в водоворот споров о табуляции, пробелах, скобках, «верблюжьей нотации» и т. п. Вряд ли кто-то потеряет сознание, увидев неправильные отступы, хотя это и привлекает внимание во время проверки кода.
Если код выдает меньше ошибок, можно ли считать его более читабельным? Чем меньше ошибок, тем лучше, но какой здесь механизм? Как сюда отнести расплывчатые приятные ощущения, которые испытываешь при виде читабельного кода? К тому же, сколько ни хмурь брови при чтении кода, ошибок это не добавит.
Если код легко править — он читабельный? А вот это, пожалуй, верное направление мысли. Меняются требования, добавляются функции, возникают ошибки — и в какой-то момент кому-то приходится править ваш код. А чтобы при этом не породить новые проблемы, разработчику нужно понимать, что конкретно он редактирует и как правки изменят поведение кода. Итак, мы нашли новое эвристическое правило: читабельный код должен легко редактироваться.
Какой код редактировать проще?
Сразу же хочется выпалить: «Код легче редактировать, когда имена переменных даются осмысленно», — но так мы просто переименуем «читабельность» в «удобство редактирования». Нам нужно более глубокое понимание, а не тот же набор правил в другом обличье.
Давайте начнем с того, что ненадолго забудем, что речь идет о коде. Программирование, которому несколько десятков лет, — лишь точка на шкале человеческой истории. Ограничившись этой «точкой», мы не сможем копнуть глубоко.
Поэтому посмотрим на читабельность через призму проектирования интерфейсов, с которыми мы сталкиваемся практически на каждому шагу — причем не только с цифровыми. Игрушка обладает функциональностью, которая заставляет ее кататься или пищать. У двери есть интерфейс, который позволяет открывать, закрывать и запирать ее. Данные в книге собраны в страницы, что обеспечивает более быстрый произвольный доступ, чем прокрутка. Изучая дизайн, об этих интерфейсах можно узнать намного больше — поинтересуйтесь у команды дизайнеров, если есть такая возможность. В общем же случае мы все отдаем предпочтение хорошим интерфейсам, даже если не всегда знаем, что делает их хорошими.
С помощью кода создаются интерфейсы. Но и сам код, в сочетании с IDE, — это интерфейс. Интерфейс, предназначенный для очень небольшой группы пользователей — наших коллег. Далее будем называть их «пользователями» — чтобы оставаться в пространстве проектирования пользовательского интерфейса.
Имея это в виду, рассмотрим такие примеры путей пользователя:
- Пользователь хочет добавить новую функцию. Для этого требуется найти нужное место и добавить функцию, не порождая новых ошибок.
- Пользователь хочет исправить ошибку. Ему потребуется найти источник проблемы и отредактировать код так, чтобы ошибка исчезла и при этом не появились новые ошибки.
- Пользователь хочет убедиться, что в пограничных случаях код ведет себя определенным образом. Ему нужно будет отыскать определенный кусок кода, затем проследить логику и смоделировать, что произойдет.
И так далее: большинство путей идут по аналогичной схеме. Чтобы не усложнять, рассмотрим конкретные примеры — но не забывайте, что речь идет о поиске общих принципов, а не составлении списка правил.
Можно уверенно предположить, что пользователь не сможет сразу открыть нужный участок кода. Это касается и собственных хобби-проектов: даже если функция написана вами, очень легко забыть, где она находится. Поэтому код должен быть таким, чтобы в нем было легко найти нужное.
Чтобы реализовать удобный поиск, понадобится некоторая поисковая оптимизация — здесь-то нам и приходят на выручку осмысленные имена переменных. Если пользователь не может найти функцию, перемещаясь по стеку вызовов из известной точки, он может запустить поиск по ключевым словам. Однако нельзя включать в имена слишком много ключевых слов. При поиске по коду ищется единственная точка входа, откуда можно продолжить работу дальше. Поэтому пользователю нужно помочь попасть в конкретное место, а если перестараться с ключевыми словами, будет слишком много бесполезных результатов поиска.
Если пользователь имеет возможность сразу убедиться, что на конкретном уровне логики всё верно, он может забыть предыдущие слои абстракции и освободить ум для последующих.
Искать можно и с помощью автодополнения: если есть общее представление о том, какую функцию нужно вызвать или какое перечисление использовать, можно начать набирать предполагаемое имя, а затем выбрать подходящий вариант из списка автодополнения. Если функция предназначена только для определенных случаев или в ее реализацию нужно внимательно вчитываться из-за особенностей использования, на это можно указать, дав название подлиннее: прокручивая список автодополнения, пользователь будет скорее избегать того, что выглядит сложно — если, конечно, он не уверен, что делает.
Поэтому короткие обычные имена с большей вероятностью будут восприниматься как варианты по умолчанию, подходящие для «случайных» пользователей. В функциях с такими именами не должно быть сюрпризов: нельзя вставлять сеттеры в функции, которые выглядят, как простые геттеры, — по той же причине, по которой кнопка «Просмотр» в интерфейсе не должна изменять пользовательские данные.

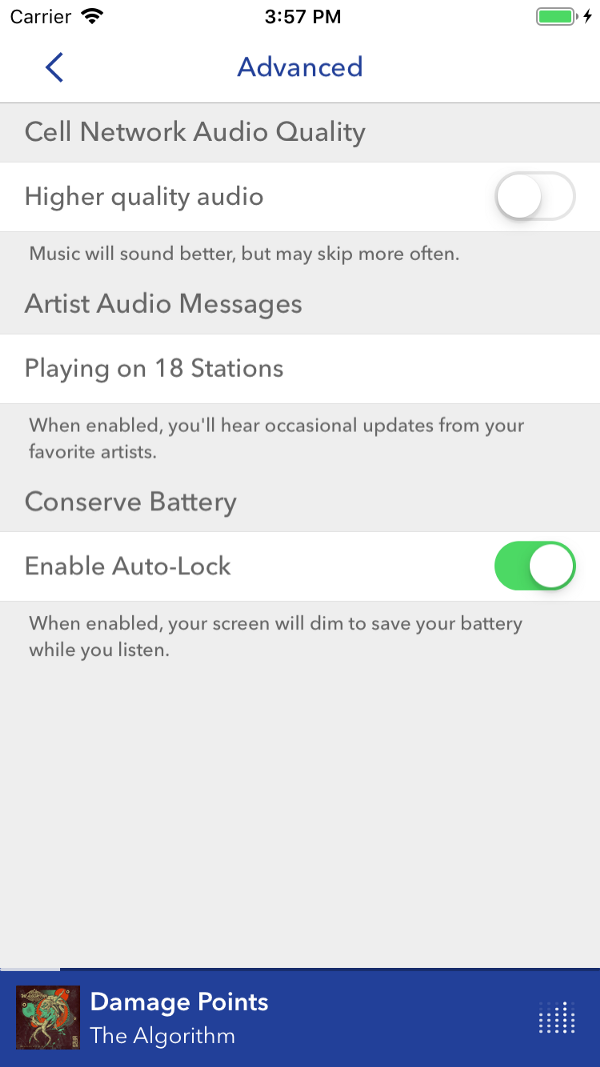
В обращенном к клиенту интерфейсе привычные функции, такие как пауза, обходятся практически без текста. По мере усложнения функциональности названия удлиняются, что заставляет пользователей притормозить и задуматься. Снимок экрана — Pandora
Пользователи хотят находить нужную информацию быстро. В большинстве случаев на компиляцию требуется значительное время, причем в запущенном приложении придется вручную проверить множество различных пограничных случаев. При возможности наши пользователи предпочтут прочитать код и понять, как он себя ведет, а не расставлять точки останова и запускать код.
Чтобы обойтись без запуска кода, должны выполняться два условия:
- Пользователь понимает, что код пытается сделать.
- Пользователь уверен, что код делает то, что заявляет.
Удовлетворить первое условие помогают абстракции: у пользователей должна быть возможность погружаться в слои абстракции до нужного уровня детализации. Представьте себе иерархический пользовательский интерфейс: на первых уровнях навигация осуществляется по обширным разделам, а затем все более конкретизируется — до того уровня логики, который нужно изучить подробнее.
Последовательное чтение файла или метода выполняется за линейное время. Но если пользователь может переходить вверх и вниз по стекам вызовов — это уже поиск по дереву, а если иерархия хорошо сбалансирована, это действие выполняется за логарифмическое время. В интерфейсах, безусловно, есть место и спискам, однако следует тщательно продумывать, должно ли быть в каком-то контексте больше двух-трех вызовов методов.
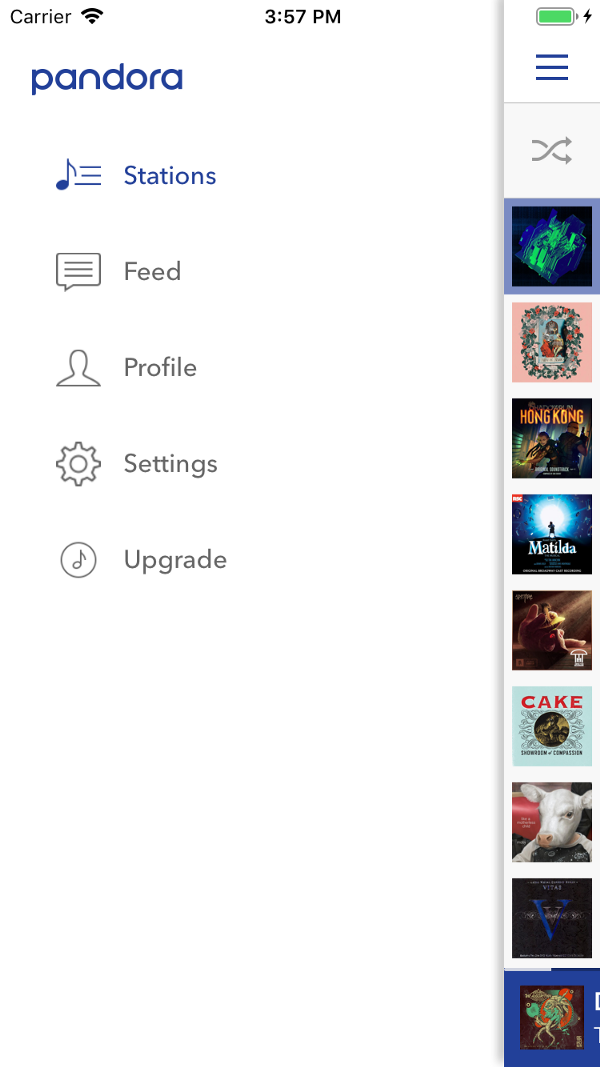

По коротким меню иерархическая навигация выполняется намного быстрее. В «длинном» меню справа — всего 11 строк. Как часто в коде методов мы укладываемся в это число? Снимок экрана — Pandora
Стратегии для второго условия у разных пользователей разные. В ситуациях с низким риском достаточным доказательством будут комментарии или имена методов. В более рискованных, сложных областях, а также когда код перегружен неактуальными комментариями, последние скорее всего будут игнорироваться. Иногда даже имена методов и переменных будут вызывать сомнение. В таких случаях пользователь должен прочитать намного больше кода и держать в голове более обширную модель логики. Здесь также поможет ограничение контекста небольшими областями, на которых легко удержать внимание. Если пользователь имеет возможность сразу убедиться, что на конкретном уровне логики всё верно, он может забыть предыдущие слои абстракции и освободить ум для последующих.
В таком режиме работы большее значение начинают иметь отдельные лексемы. Например, булевский флаг
element.visible = true/falseлегко понять в отрыве от остального кода, однако для этого требуется объединить в уме две разных лексемы. Если же использовать
element.visibility = .visible/.hiddenто значение флага можно понять с ходу: в этом случае не нужно читать имя переменной, чтобы выяснить, что она имеет отношение к видимости.¹ Аналогичные подходы мы видели в проектировании ориентированных на клиента интерфейсов. За последние десятилетия кнопки подтверждения действий «ОК» и «Отмена» превратились в более описательные элементы интерфейса: «Сохранить» и «Отменить», «Отправить» и «Продолжить редактирование» и т. д., — чтобы понять, что будет выполнено, пользователю достаточно взглянуть на предложенные варианты, не считывая весь контекст полностью.
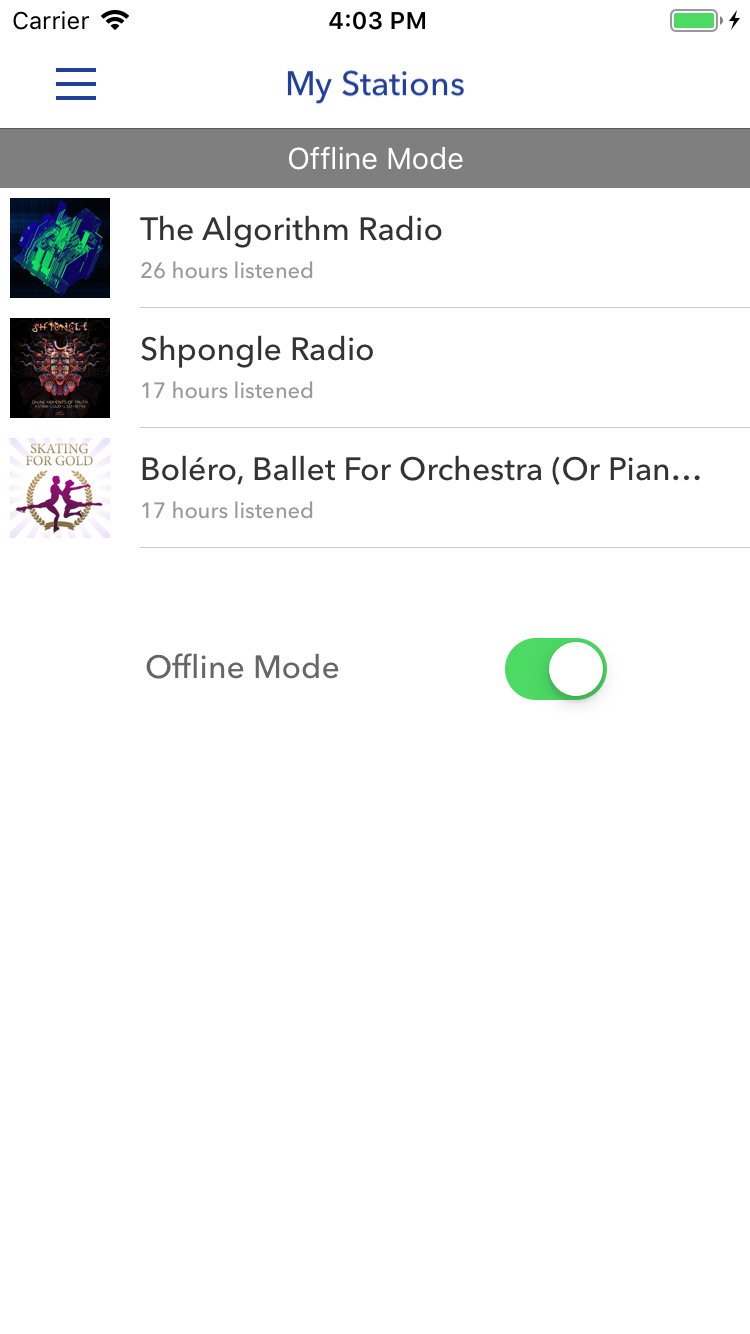
Строка «Offline Mode» в примере сверху указывает, что приложение работает в автономном режиме. Переключатель в примере ниже имеет тот же смысл, но чтобы понять его, нужно взглянуть на контекст. Снимок экрана — Pandora
Подтвердить ожидаемое поведение кода также помогают модульные тесты: они выступают как комментарии — которым, однако, можно доверять в большей степени, поскольку они лучше сохраняют актуальность. Правда, для них тоже нужно выполнять сборку. Но в случае хорошо налаженного CI-конвейера тесты запускаются регулярно, поэтому при внесении изменений в существующий код этот шаг можно пропустить.
В теории, безопасность следует из достаточного понимания: как только наш пользователь поймет поведение кода, он сможет безопасно вносить правки. На практике же приходится учитывать, что разработчики — обычные люди: наш мозг использует те же уловки и так же ленится. Поэтому чем меньше сил нужно потратить на понимание кода, тем безопаснее наши действия.
Читабельный код должен передавать бо́льшую часть проверок на ошибки компьютеру. Один из способов это осуществить — отладочные проверки «assert», однако и для них требуются сборка и запуск. Что еще хуже, если пользователь забыл о пограничных случаях, «assert» не поможет. Модульные тесты с проверкой часто забываемых пограничных случаев могут справляться лучше, но как только пользователь внес изменения, придется ждать прогона тестов.
Резюмируя: читабельный код должен быть удобен в использовании. И — как побочный эффект — он может выглядеть красиво.
Чтобы ускорить цикл разработки, мы используем функцию проверок на ошибки, встроенную в компилятор. Обычно для таких случаев полная сборка не требуется, а ошибки отображаются в реальном времени. Как использовать эту возможность в своих интересах? Вообще говоря, нужно найти ситуации, когда проверки компилятора становятся очень строгими. Например, большинство компиляторов не смотрят, насколько исчерпывающе описан оператор «if», но тщательно проверяют «switch» на пропущенные условия. Если пользователь пытается добавить или изменить условие, будет безопаснее, если все предыдущие аналогичные операторы были исчерпывающими. И в момент изменения условия «case» компилятор пометит все остальные условия, которые необходимо проверить.
Еще одна распространенная проблема читабельности — использование примитивов в условных выражениях. Особенно остро эта проблема проявляется, когда приложение анализирует JSON, ведь так и хочется понаставить операторов «if» вокруг строкового или целочисленного равенства. Это не только повышает вероятность опечаток, но и усложняет пользователям задачу определения возможных значений. При проверке пограничных случаев есть большая разница между тем, когда возможна любая строка, и когда — лишь два-три отдельных варианта. Даже если примитивы зафиксированы в константах, стоит один раз поспешить, стараясь закончить проект в срок, — и появится произвольное значение. Но если применять специально созданные объекты или перечисления, компилятор блокирует недопустимые аргументы и дает конкретный список допустимых.
Точно так же, если некоторые комбинации булевских флагов недопустимы, следует заменить их на одно перечисление. Возьмем, к примеру, композицию, которая может быть в следующих состояниях: буферизируется, загружена полностью и воспроизводится. Если представить состояния загрузки и воспроизведения как два булевских флага
(loaded, playing)компилятор будет разрешать ввод недопустимых значений
(loaded: false, playing: true)А если использовать перечисление
(.buffering/.loaded/.playing)то недопустимое состояние указать будет невозможно. В ориентированном на клиента интерфейсе по умолчанию должен быть запрет недопустимых комбинаций настроек. Но когда мы пишем код внутри приложения, мы часто забываем обеспечить себе такую же защиту.
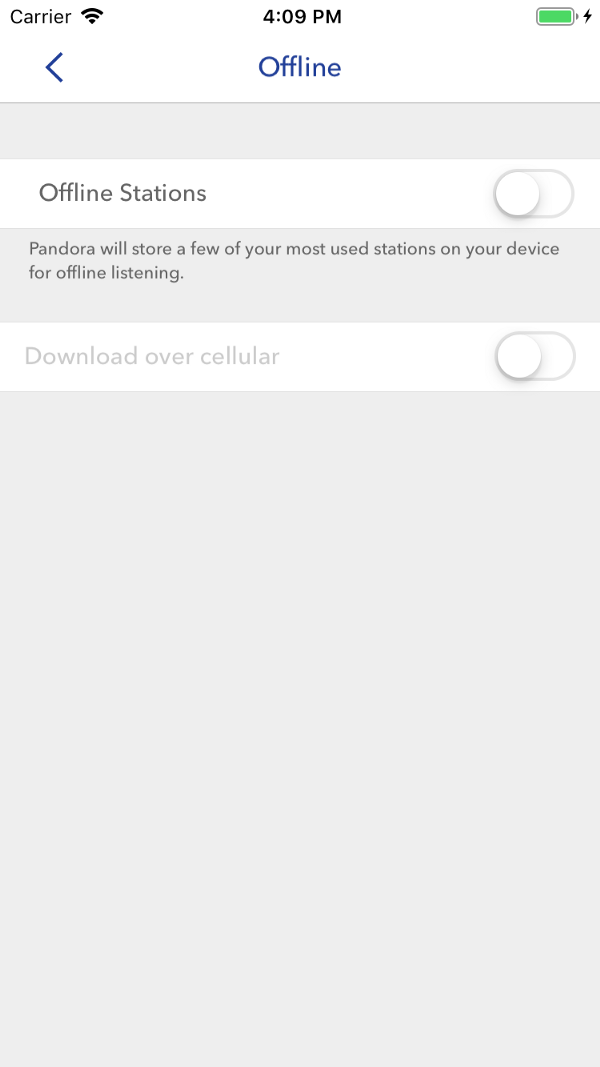
Недопустимые комбинации заранее отключены; пользователям не нужно задумываться, какие конфигурации несовместимы. Снимок экрана — Apple
Следуя по рассмотренным пользовательским путям, мы пришли к тем же правилам, что и в начале. Но теперь у нас есть принцип, по которому их можно формулировать самостоятельно и изменять в соответствии с ситуацией. Для этого мы спрашиваем себя:
- Будет ли пользователю легко искать нужный кусок кода? Не будут ли результаты поиска загромождены функциями, не связанными с запросом?
- Сможет ли пользователь, найдя нужный код, быстро проверить правильность его поведения?
- Обеспечивает ли среда разработки безопасное редактирование и повторное использования кода?
Резюмируя: читабельный код должен быть удобен в использовании. И — как побочный эффект — он может выглядеть красиво.
Примечание
- Может показаться, что булевские переменные удобнее использовать повторно, однако такая возможность повторного использования подразумевает взаимозаменяемость. Возьмем, к примеру, флаги tappable и cached, которые представляют понятия, расположенные в совершенно разных плоскостях: возможность нажатия на элемент и состояние кэширования. Но если оба флага — булевские, их можно случайно поменять местами, получив в одной строке кода нетривиальное выражение, которое будет означать, что кэширование связано с возможностью нажатия на элемент. При использовании перечислений мы, чтобы сформировать подобные отношения, будем вынуждены создавать явную, проверяемую логику преобразования использованных нами «единиц измерения».
О переводчике
Перевод статьи выполнен в Alconost.
Alconost занимается локализацией игр, приложений и сайтов на 70 языков. Переводчики-носители языка, лингвистическое тестирование, облачная платформа с API, непрерывная локализация, менеджеры проектов 24/7, любые форматы строковых ресурсов.
Мы также делаем рекламные и обучающие видеоролики — для сайтов, продающие, имиджевые, рекламные, обучающие, тизеры, эксплейнеры, трейлеры для Google Play и App Store.
→ Подробнее
