
Привет. В конце прошлого года мы стали автоматически скрывать номера автомобилей на фотографиях в карточках объявлений на Авито. О том, зачем мы это сделали, и какие есть способы решения таких задач, читайте в статье.

На Авито за 2018 год было продано 2,5 миллиона автомобилей. Это почти 7000 в день. Всем объявлениям о продаже нужна иллюстрация — фото автомобиля. Но по государственному номеру на нём можно найти много дополнительной информации о машине. И некоторые наши пользователи стараются самостоятельно закрывать госномер.
Причины, почему пользователи хотят скрывать госномер, могут быть разными. Со своей стороны мы хотим помогать им защищать свои данные. И стараемся улучшать процессы продажи и покупки для пользователей. Например, у нас уже давно работает услуга анонимного номера: когда вы продаёте автомобиль, для вас создается временный сотовый номер. Ну а чтобы защитить данные о госномерах, мы обезличиваем фотографии.

Чтобы автоматизировать процесс защиты пользовательских фотографий, можно воспользоваться сверточными нейронными сетями для детектирования полигона с номерным знаком.
Сейчас для детекции объектов используются архитектуры двух групп: двухэтапные сети, например, Faster RCNN и Mask RCNN; одноэтапные (singleshot) — SSD, YOLO, RetinaNet. Детектированием объекта является вывод четырёх координат прямоугольника, в которые вписан объект интереса.
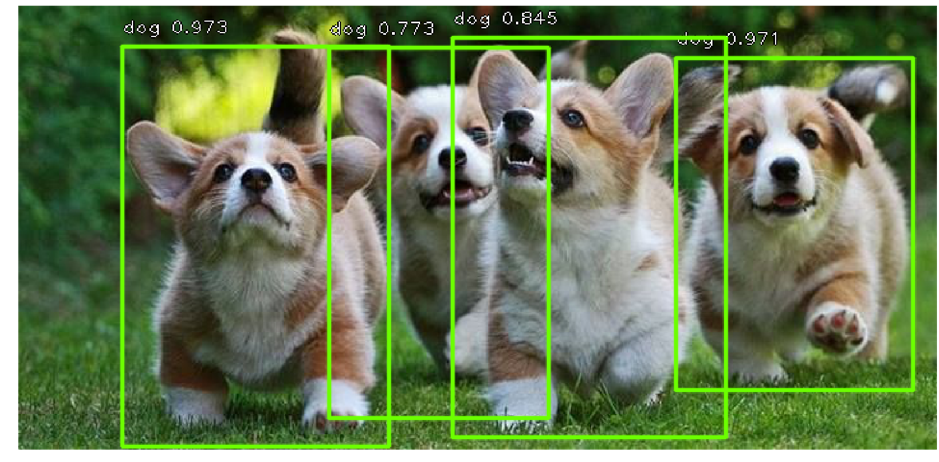
Упомянутые выше сети способны находить на картинках множество объектов разных классов, что уже является избыточным для решения задачи поиска номерного знака, потому что машина у нас на картинках, как правило, всего одна (бывают исключения, когда люди фотографируют свою продаваемую машину и её случайную соседку, но это происходит достаточно редко, поэтому этим можно было пренебречь).
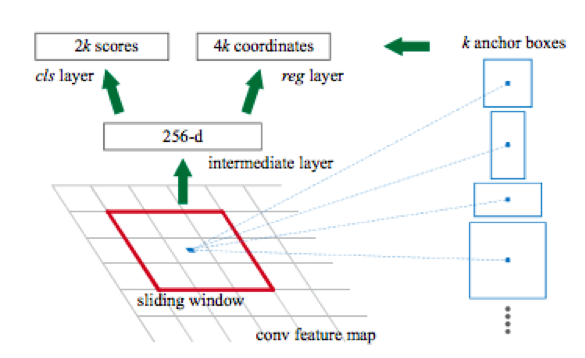
Ещё одна особенность этих сетей состоит в том, что по умолчанию они выдают bounding box со сторонами, параллельными осям координат. Это происходит так, потому что для детектирования используется набор заранее определённых видов прямоугольных рамок, называемых anchor boxes. Если точнее, то сначала с помощью какой-то сверточной сети (например resnet34) из картинки получают матрицу признаков. Потом для каждого подмножества признаков, полученного с помощью скользящего окна, происходит классификация: есть или нет объект для k anchor box и проводится регрессия в четыре координаты рамки, которые корректируют её положение.
Подробнее об этом можно прочитать здесь.
После этого есть ещё две головы:
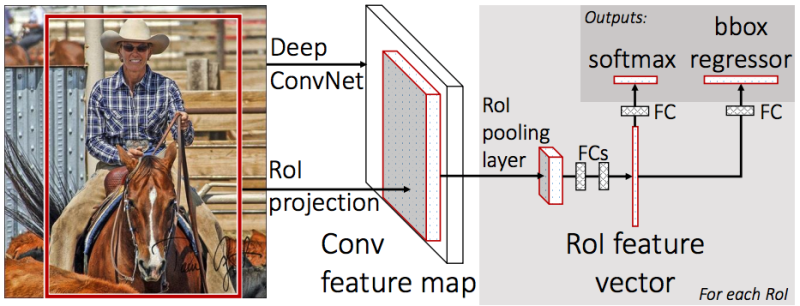
одна для классификации объекта (собака/кошка/растение и т.д),
вторая (bbox regressor) — для регрессии координат рамки, полученной на предыдущем шаге, чтобы увеличить соотношение площади объекта к площади рамки.
Для того, чтобы предсказать повернутую рамку бокса, нужно изменить bbox regressor так, чтобы получать ещё и угол поворота рамки. Если этого не делать, то получится как-то так.

Кроме двухэтапного Faster R-CNN, есть одноэтапные детекторы, например RetinaNet. Он отличается от предыдущей архитектуры тем, что сразу предсказывает класс и рамку, без предварительного этапа предложения участков картинки, которые могут содержать объекты. Для того чтобы предсказывать повернутые маски, нужно также изменить голову box subnet.
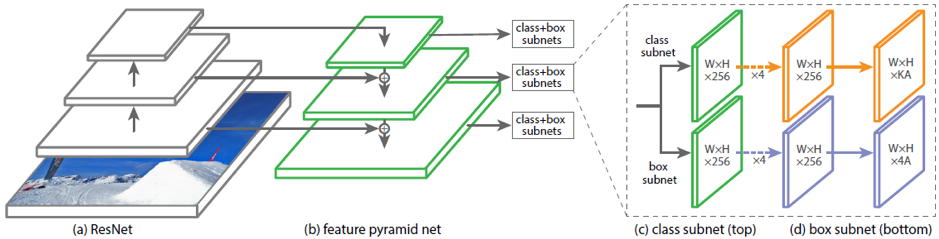
Один из примеров существующих архитектур для предсказания повернутых bounding box — DRBOX. Эта сеть не использует предварительный этап предложения региона, как в Faster RCNN, поэтому она является модификацией одноэтапных методов. Для обучения этой сети используется K повернутых под определенными углами bounding box (rbox). Сеть предсказывает вероятности для каждого из K rbox содержать таргет объект, координаты, размер bbox и угол поворота.
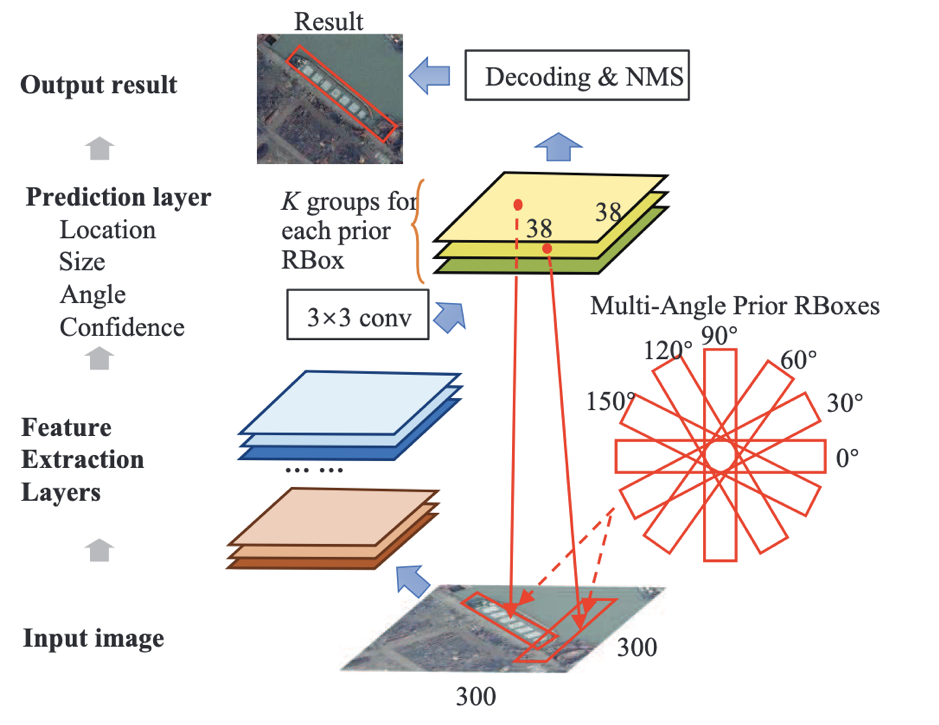
Модифицировать архитектуру и заново обучить одну из рассмотренных сетей на данных с повернутыми bounding boxes — задача реализуемая. Но нашу цель можно достигнуть проще, ведь область применения сети у нас гораздо уже — только для скрытия номерных знаков.
Поэтому мы решили начать с простой сети для предсказания четырёх точек номера, впоследствии можно будет усложнить архитектуру.
Сборка датасета разбивается на два шага: собрать картинки автомобилей и разметить на них область с госномером. Первая задача уже решена в нашей инфраструктуре: все объявления, которые были когда-либо размещены на Авито, мы аккуратно храним. Для решения второй задачи мы используем Толоку. На toloka.yandex.ru/requester создаём задание:

С помощью Толоки можно создавать задания по разметке данных. Например, оценивать качество поисковой выдачи, размечать разные классы объектов (текстов и картинок), размечать видео и т.д. Их будут выполнять пользователи Толоки, за плату, которую вы назначите. Например, в нашем случае толокеры должны выделить полигон с госномером автомобиля на фото. В целом это очень удобно для разметки большого датасета, но получить высокое качество довольно сложно. На толоке много ботов, задачей которых является получить с вас деньги, наставив ответы рандомно или с помощью какой-то стратегии. Для противодействия этим ботам есть система правил и проверок. Основной проверкой является подмешивание контрольных вопросов: вы размечаете вручную часть заданий, пользуясь интерфейсом Толоки, а далее подмешиваете их в основное задание. Если размечающий часто ошибается на контрольных вопросах, вы его блокируете и разметку не учитываете.
Для задачи классификации очень просто определить, ошибся размечающий или нет, а для задачи выделения области это не так просто. Классический способ — считать IoU.
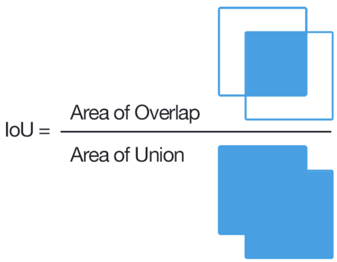
Если это отношение меньше некоторого заданного порога для нескольких заданий, то такой пользователь блокируется. Однако для двух произвольных четырехугольников посчитать IoU не так просто, тем более, что в Толоке приходится это реализовать на JavaScript. Мы сделали небольшой хак, и считаем, что пользователь не ошибся, если для каждой точки исходного полигона в небольшой окрестности находится точка, отмеченная разметчиком. Ещё есть правило быстрых ответов, чтобы блокировались слишком быстро отвечающие пользователи, капча, расхождение с мнением большинства и т.д. Настроив эти правила, можно ожидать довольно неплохую разметку, но если нужно действительно высокое качество и сложная разметка, нужно специально нанимать фрилансеров-разметчиков. В итоге наш датасет составил 4к размеченных картинок, и стоило всё это 28$ на Толоке.
Теперь сделаем сеть для предсказания четырёх точек области. Получим признаки с помощью resnet18 (11.7M параметров против 21.8M параметров у resnet34), далее делаем голову для регрессии в четыре точки (восемь координат) и голову для классификации, есть на картинке номерной знак или нет. Вторая голова нужна, потому что в объявлениях о продаже машины не все фотографии с машинами. На фото может быть деталь автомобиля.

Подобное нам, конечно, детектить не надо.
Обучение двух голов делаем одновременно, добавив в датасет фото без номерного знака с таргетом bounding box (0,0,0,0,0,0,0,0) и значением для классификатора «картинка с номерным знаком / без» — (0,1).
Тогда можно составить единую лосс функцию для обеих голов как cумму следующих лоссов. Для регрессии в координаты полигона номерного знака используем гладкий L1 loss.
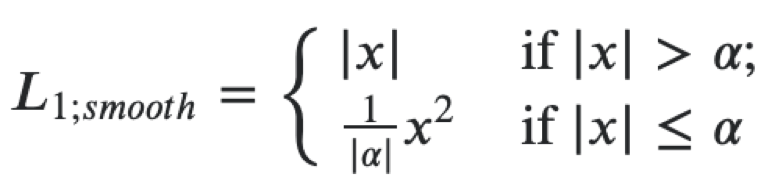
Его можно интерпретировать как комбинацию L1 и L2, который ведёт себя как L1, когда абсолютное значение аргумента велико и как L2, когда значение аргумента близко к нулю. Для классификации используем softmax и crossentropy loss. Экстрактор признаков — resnet18, используем веса, предобученные на ImageNet, дальше дообучаем на нашем датасете экстрактор и головы. В данной задаче мы использовали фреймворк mxnet, так как он является основным для computer vision в Авито. Вообще, микросервисная архитектура позволяет не привязываться к конкретному фреймворку, но когда имеешь большую кодовую базу, лучше использовать ее и не писать тот же самый код заново.
Получив приемлемое качество на нашем датасете, мы обратились к дизайнерам, чтобы нам сделали номерной знак с логотипом Авито. Сначала мы конечно попробовали сделать сами, но выглядел он не очень красиво. Дальше требуется изменить яркость номерного знака Авито на яркость оригинальной области с номерным знаком и можно накладывать логотип на изображение.

Проблема воспроизводимости результатов, поддержки и развития проектов, решённая с некоторой погрешностью в мире backend- и frontend-разработки, всё ещё стоит открытой там, где требуется использовать модели машинного обучения. Вам наверняка приходилось разбираться в легаси коде моделек. Хорошо если в readme есть ссылки на статьи или опенсорс-репозитории, на которых базировалось решение. Скрипт для запуска переобучения может упасть с ошибками, например, поменялась версия cudnn, и та версия tensorflow уже не работает с этой версией cudnn, а cudnn не работает с этой версией драйверов nvidia. Может, для обучения использовался один итератор по данным, а для тестирования и в продакшене другой. Так можно продолжать довольно долго. В общем, проблемы с воспроизводимостью существуют.
Мы стараемся убрать их, используя nvidia-docker окружение для обучения моделек, в нём есть все необходимые зависимости для сuda, также туда устанавливаем зависимости для питона. Версия библиотеки с итератором по данным, аугментациями, инференсу моделек — общая для стадии обучения/экспериментирования и для продакшена. Таким образом, чтобы дообучить модель на новых данных, вам нужно выкачать репозиторий на сервер, запустить shell скрипт, который соберет докер-окружение, внутри которого поднимется jupyter notebook. Внутри у вас будут все notebook’и для обучения и тестирования, которые точно не упадут с ошибкой из-за окружения. Лучше, конечно, иметь один файл train.py, но практика показывает, что всегда требуется смотреть глазами на то, что выдаёт моделька и что-то менять в процессе обучения, так что в конце вы всё равно запустите jupyter.
Веса модели хранятся в git lfs — это специальная технология для хранения больших файлов в гите.До этого мы пользовались артифактори, но через git lfs удобнее, потому что скачивая репозиторий с сервисом, вы сразу получаете актуальную версию весов, как на продакшене. Для инференса моделей написаны автотесты, так что не получится раскатить сервис с весами, которые их не проходят. Сам сервис запускается в докере внутри микросервисной инфраструктуры на кластере kubernetes. Для мониторинга производительности мы используем grafana. После раскатки мы постепенно увеличиваем нагрузку на инстансы сервисов с новой моделькой. При выкатке новой фичи мы создаем а/б тесты и выносим вердикт по дальнейшей судьбе фичи, опираясь на статистические тесты.
В результате: мы запустили замазывание номеров на объявлениях в категории авто для частников, 95 перцентиль времени обработки одной картинки для скрытия номера равен 250 мс.
Задача
На Авито за 2018 год было продано 2,5 миллиона автомобилей. Это почти 7000 в день. Всем объявлениям о продаже нужна иллюстрация — фото автомобиля. Но по государственному номеру на нём можно найти много дополнительной информации о машине. И некоторые наши пользователи стараются самостоятельно закрывать госномер.
 |
 |
 |
 |
 |
|
Причины, почему пользователи хотят скрывать госномер, могут быть разными. Со своей стороны мы хотим помогать им защищать свои данные. И стараемся улучшать процессы продажи и покупки для пользователей. Например, у нас уже давно работает услуга анонимного номера: когда вы продаёте автомобиль, для вас создается временный сотовый номер. Ну а чтобы защитить данные о госномерах, мы обезличиваем фотографии.
Обзор способов решения
Чтобы автоматизировать процесс защиты пользовательских фотографий, можно воспользоваться сверточными нейронными сетями для детектирования полигона с номерным знаком.
Сейчас для детекции объектов используются архитектуры двух групп: двухэтапные сети, например, Faster RCNN и Mask RCNN; одноэтапные (singleshot) — SSD, YOLO, RetinaNet. Детектированием объекта является вывод четырёх координат прямоугольника, в которые вписан объект интереса.
Упомянутые выше сети способны находить на картинках множество объектов разных классов, что уже является избыточным для решения задачи поиска номерного знака, потому что машина у нас на картинках, как правило, всего одна (бывают исключения, когда люди фотографируют свою продаваемую машину и её случайную соседку, но это происходит достаточно редко, поэтому этим можно было пренебречь).
Ещё одна особенность этих сетей состоит в том, что по умолчанию они выдают bounding box со сторонами, параллельными осям координат. Это происходит так, потому что для детектирования используется набор заранее определённых видов прямоугольных рамок, называемых anchor boxes. Если точнее, то сначала с помощью какой-то сверточной сети (например resnet34) из картинки получают матрицу признаков. Потом для каждого подмножества признаков, полученного с помощью скользящего окна, происходит классификация: есть или нет объект для k anchor box и проводится регрессия в четыре координаты рамки, которые корректируют её положение.
Подробнее об этом можно прочитать здесь.
После этого есть ещё две головы:
одна для классификации объекта (собака/кошка/растение и т.д),
вторая (bbox regressor) — для регрессии координат рамки, полученной на предыдущем шаге, чтобы увеличить соотношение площади объекта к площади рамки.
Для того, чтобы предсказать повернутую рамку бокса, нужно изменить bbox regressor так, чтобы получать ещё и угол поворота рамки. Если этого не делать, то получится как-то так.
Кроме двухэтапного Faster R-CNN, есть одноэтапные детекторы, например RetinaNet. Он отличается от предыдущей архитектуры тем, что сразу предсказывает класс и рамку, без предварительного этапа предложения участков картинки, которые могут содержать объекты. Для того чтобы предсказывать повернутые маски, нужно также изменить голову box subnet.
Один из примеров существующих архитектур для предсказания повернутых bounding box — DRBOX. Эта сеть не использует предварительный этап предложения региона, как в Faster RCNN, поэтому она является модификацией одноэтапных методов. Для обучения этой сети используется K повернутых под определенными углами bounding box (rbox). Сеть предсказывает вероятности для каждого из K rbox содержать таргет объект, координаты, размер bbox и угол поворота.
Модифицировать архитектуру и заново обучить одну из рассмотренных сетей на данных с повернутыми bounding boxes — задача реализуемая. Но нашу цель можно достигнуть проще, ведь область применения сети у нас гораздо уже — только для скрытия номерных знаков.
Поэтому мы решили начать с простой сети для предсказания четырёх точек номера, впоследствии можно будет усложнить архитектуру.
Данные
Сборка датасета разбивается на два шага: собрать картинки автомобилей и разметить на них область с госномером. Первая задача уже решена в нашей инфраструктуре: все объявления, которые были когда-либо размещены на Авито, мы аккуратно храним. Для решения второй задачи мы используем Толоку. На toloka.yandex.ru/requester создаём задание:
В задании дана фотография автомобиля. Необходимо выделить номерной знак автомобиля, используя для этого четырёхугольник. При этом следует выделять государственный номер максимально точно.
С помощью Толоки можно создавать задания по разметке данных. Например, оценивать качество поисковой выдачи, размечать разные классы объектов (текстов и картинок), размечать видео и т.д. Их будут выполнять пользователи Толоки, за плату, которую вы назначите. Например, в нашем случае толокеры должны выделить полигон с госномером автомобиля на фото. В целом это очень удобно для разметки большого датасета, но получить высокое качество довольно сложно. На толоке много ботов, задачей которых является получить с вас деньги, наставив ответы рандомно или с помощью какой-то стратегии. Для противодействия этим ботам есть система правил и проверок. Основной проверкой является подмешивание контрольных вопросов: вы размечаете вручную часть заданий, пользуясь интерфейсом Толоки, а далее подмешиваете их в основное задание. Если размечающий часто ошибается на контрольных вопросах, вы его блокируете и разметку не учитываете.
Для задачи классификации очень просто определить, ошибся размечающий или нет, а для задачи выделения области это не так просто. Классический способ — считать IoU.
Если это отношение меньше некоторого заданного порога для нескольких заданий, то такой пользователь блокируется. Однако для двух произвольных четырехугольников посчитать IoU не так просто, тем более, что в Толоке приходится это реализовать на JavaScript. Мы сделали небольшой хак, и считаем, что пользователь не ошибся, если для каждой точки исходного полигона в небольшой окрестности находится точка, отмеченная разметчиком. Ещё есть правило быстрых ответов, чтобы блокировались слишком быстро отвечающие пользователи, капча, расхождение с мнением большинства и т.д. Настроив эти правила, можно ожидать довольно неплохую разметку, но если нужно действительно высокое качество и сложная разметка, нужно специально нанимать фрилансеров-разметчиков. В итоге наш датасет составил 4к размеченных картинок, и стоило всё это 28$ на Толоке.
Модель
Теперь сделаем сеть для предсказания четырёх точек области. Получим признаки с помощью resnet18 (11.7M параметров против 21.8M параметров у resnet34), далее делаем голову для регрессии в четыре точки (восемь координат) и голову для классификации, есть на картинке номерной знак или нет. Вторая голова нужна, потому что в объявлениях о продаже машины не все фотографии с машинами. На фото может быть деталь автомобиля.
Подобное нам, конечно, детектить не надо.
Обучение двух голов делаем одновременно, добавив в датасет фото без номерного знака с таргетом bounding box (0,0,0,0,0,0,0,0) и значением для классификатора «картинка с номерным знаком / без» — (0,1).
Тогда можно составить единую лосс функцию для обеих голов как cумму следующих лоссов. Для регрессии в координаты полигона номерного знака используем гладкий L1 loss.
Его можно интерпретировать как комбинацию L1 и L2, который ведёт себя как L1, когда абсолютное значение аргумента велико и как L2, когда значение аргумента близко к нулю. Для классификации используем softmax и crossentropy loss. Экстрактор признаков — resnet18, используем веса, предобученные на ImageNet, дальше дообучаем на нашем датасете экстрактор и головы. В данной задаче мы использовали фреймворк mxnet, так как он является основным для computer vision в Авито. Вообще, микросервисная архитектура позволяет не привязываться к конкретному фреймворку, но когда имеешь большую кодовую базу, лучше использовать ее и не писать тот же самый код заново.
Получив приемлемое качество на нашем датасете, мы обратились к дизайнерам, чтобы нам сделали номерной знак с логотипом Авито. Сначала мы конечно попробовали сделать сами, но выглядел он не очень красиво. Дальше требуется изменить яркость номерного знака Авито на яркость оригинальной области с номерным знаком и можно накладывать логотип на изображение.
Запуск в прод
Проблема воспроизводимости результатов, поддержки и развития проектов, решённая с некоторой погрешностью в мире backend- и frontend-разработки, всё ещё стоит открытой там, где требуется использовать модели машинного обучения. Вам наверняка приходилось разбираться в легаси коде моделек. Хорошо если в readme есть ссылки на статьи или опенсорс-репозитории, на которых базировалось решение. Скрипт для запуска переобучения может упасть с ошибками, например, поменялась версия cudnn, и та версия tensorflow уже не работает с этой версией cudnn, а cudnn не работает с этой версией драйверов nvidia. Может, для обучения использовался один итератор по данным, а для тестирования и в продакшене другой. Так можно продолжать довольно долго. В общем, проблемы с воспроизводимостью существуют.
Мы стараемся убрать их, используя nvidia-docker окружение для обучения моделек, в нём есть все необходимые зависимости для сuda, также туда устанавливаем зависимости для питона. Версия библиотеки с итератором по данным, аугментациями, инференсу моделек — общая для стадии обучения/экспериментирования и для продакшена. Таким образом, чтобы дообучить модель на новых данных, вам нужно выкачать репозиторий на сервер, запустить shell скрипт, который соберет докер-окружение, внутри которого поднимется jupyter notebook. Внутри у вас будут все notebook’и для обучения и тестирования, которые точно не упадут с ошибкой из-за окружения. Лучше, конечно, иметь один файл train.py, но практика показывает, что всегда требуется смотреть глазами на то, что выдаёт моделька и что-то менять в процессе обучения, так что в конце вы всё равно запустите jupyter.
Веса модели хранятся в git lfs — это специальная технология для хранения больших файлов в гите.До этого мы пользовались артифактори, но через git lfs удобнее, потому что скачивая репозиторий с сервисом, вы сразу получаете актуальную версию весов, как на продакшене. Для инференса моделей написаны автотесты, так что не получится раскатить сервис с весами, которые их не проходят. Сам сервис запускается в докере внутри микросервисной инфраструктуры на кластере kubernetes. Для мониторинга производительности мы используем grafana. После раскатки мы постепенно увеличиваем нагрузку на инстансы сервисов с новой моделькой. При выкатке новой фичи мы создаем а/б тесты и выносим вердикт по дальнейшей судьбе фичи, опираясь на статистические тесты.
В результате: мы запустили замазывание номеров на объявлениях в категории авто для частников, 95 перцентиль времени обработки одной картинки для скрытия номера равен 250 мс.
