Давненько никто не собирал статистику о постах на Хабрахабре. Мы в Cloud4Y решили узнать какие изменения произошли за последние полгода. Нас интересовало:
И многое другое…

24 апреля 2017 года была собрана статистика по всем последним публикациям на Хабрахабре. Оказалось, что в период с 20 сентября 2016 года по 22 апреля 2017 года:
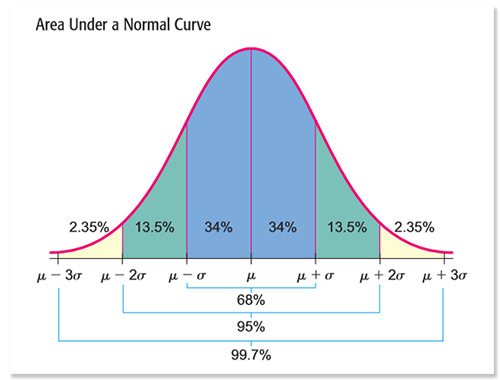
Для достоверности статистики из более 6,5к публикаций мы удалили публикации, количество просмотров которых не попадает в 99,7% область нормального распределения просмотров. Такие посты могут испортить статистику, сильно повлияв на средние значения и стандартные отклонения в дальнейших расчетах. Публикации мы удаляли до тех пор, пока все они не укладывались в . Всего было удалено 7,4% супер-публикаций.
. Всего было удалено 7,4% супер-публикаций.
Плотность нормального распределения
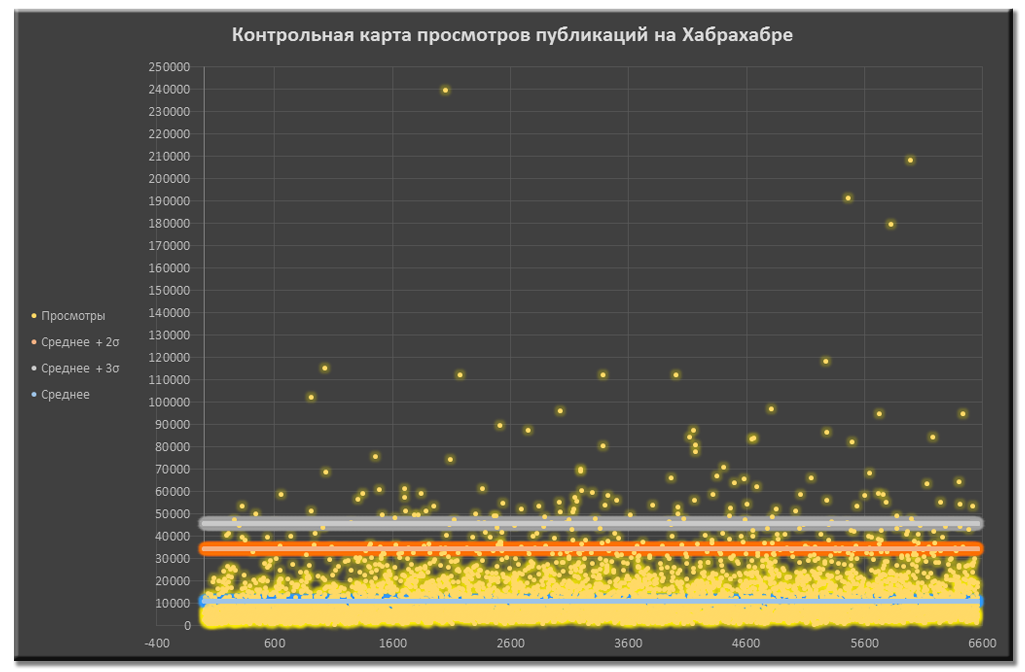 Контрольная карта просмотров публикаций до чистки данных
Контрольная карта просмотров публикаций до чистки данных
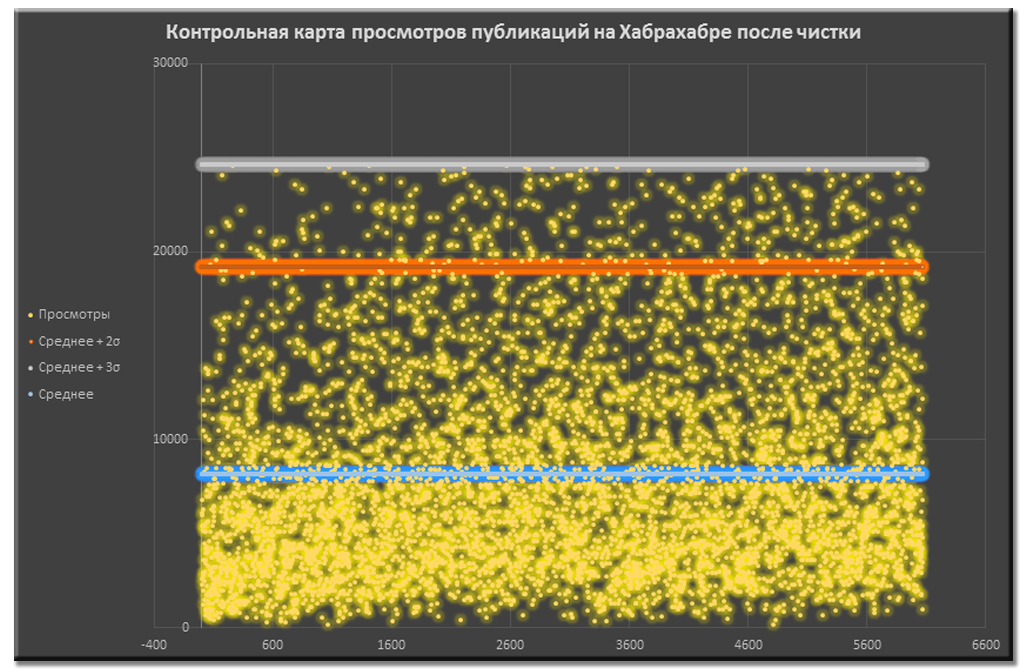 Контрольная карта просмотров публикаций после чистки данных
Контрольная карта просмотров публикаций после чистки данных
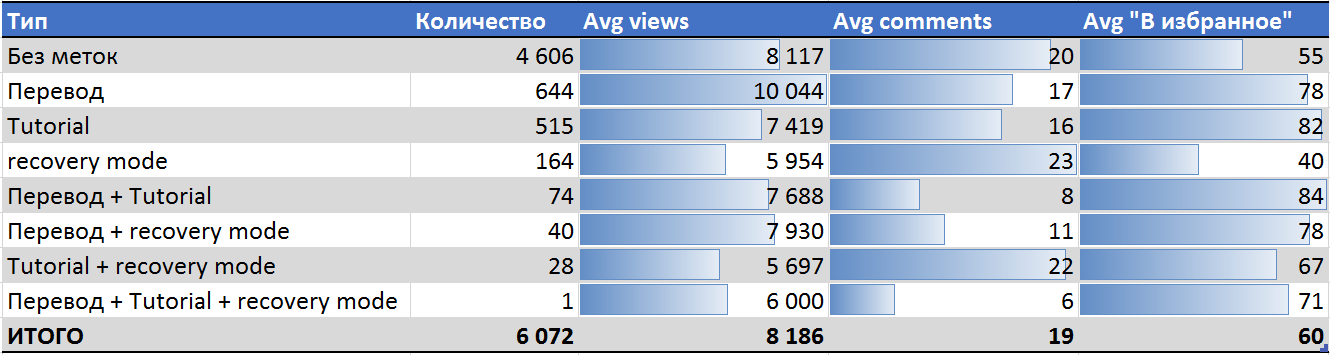
Среди почищенного набора данных
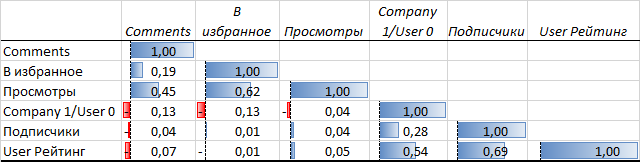
Попарная корреляция основных показателей
Лучшие дни недели
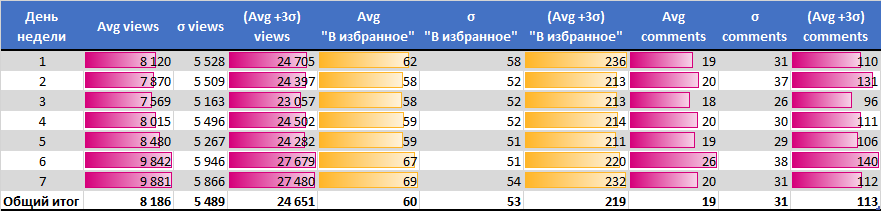
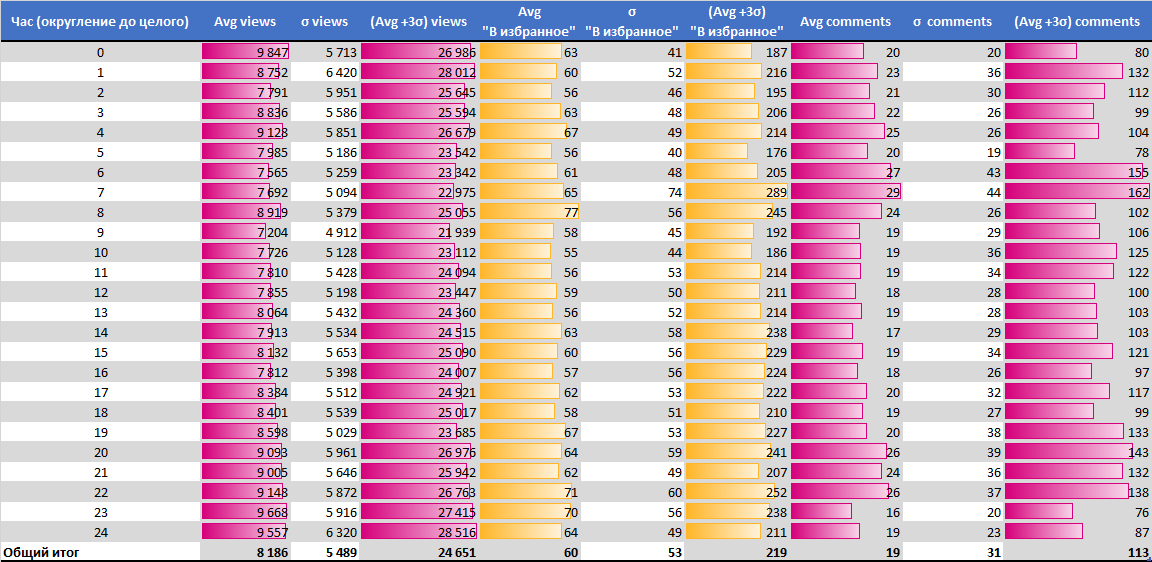
Лучшее время
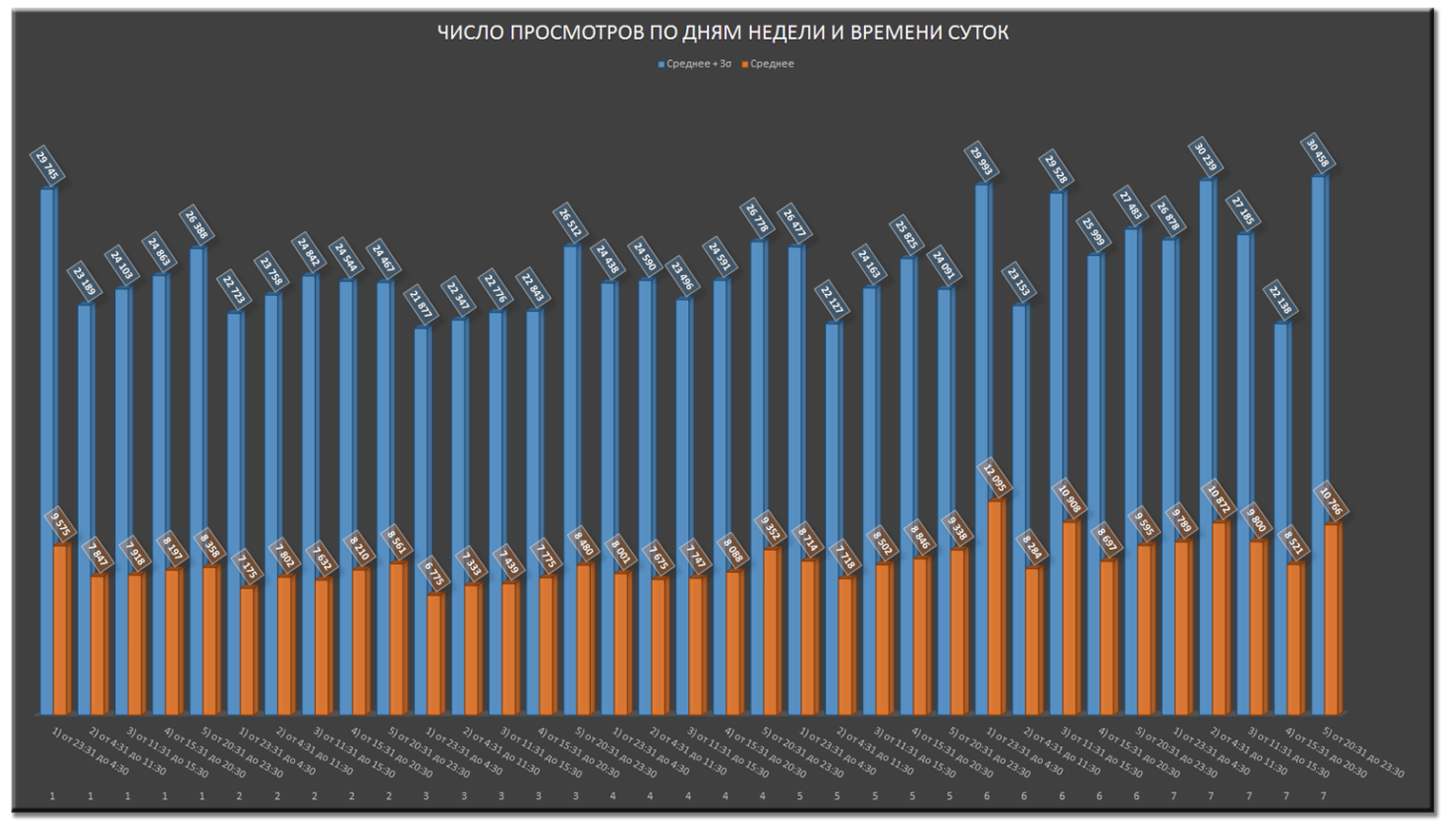
Лучшее время публикации при учете дня недели — ночь с пятницы на субботу или вечер воскресенья.
 Картинка может быть увеличена по клику (открывается в текущем окне)
Картинка может быть увеличена по клику (открывается в текущем окне)
Согласно смыслу закона больших чисел, всегда найдётся такое конечное число испытаний, при котором с любой заданной наперёд вероятностью меньше 1 относительная частота появления некоторого события будет сколь угодно мало отличаться от его вероятности. На этом свойстве основаны методы оценки вероятности на основе анализа конечной выборки. Наша выборка для каждого разреза имела более 30 результатов эмпирических испытаний — фактических показателей публикаций.
При публикации одной конкретной статьи приведенные выше закономерности могут не оказать значительного влияния или будут нивелированы другими факторами. Если же планируется опубликовывать серию постов, использование этих закономерностей может принести пользу. В каждом отдельном случае наибольшее влияние на показатели популярности статьи имеет её содержание.
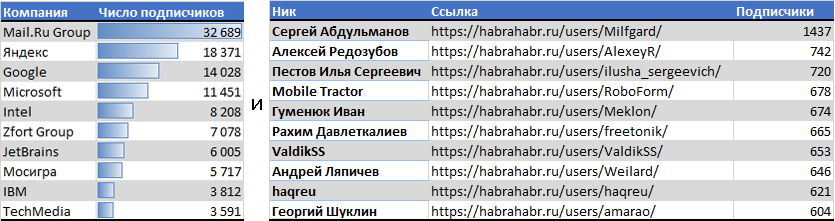
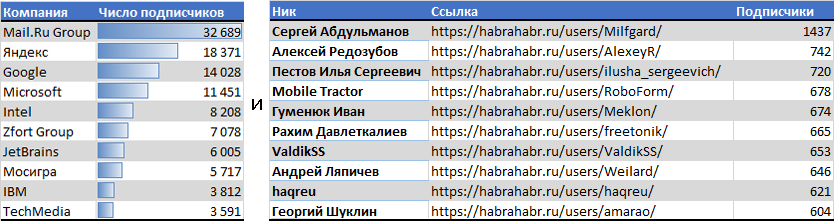
ТОП10 Компаний и Пользователей с наибольшим числом подписчиков
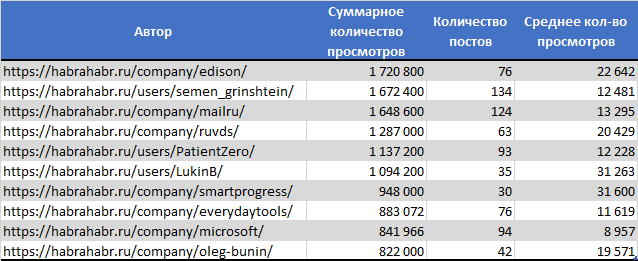
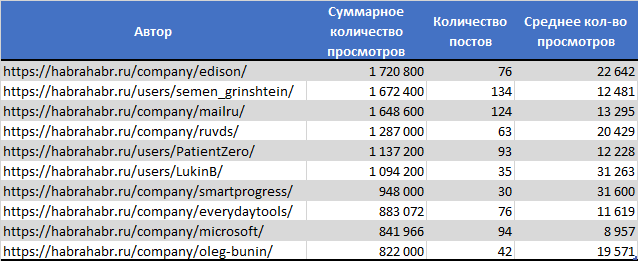
ТОП10 с наибольшим числом просмотров
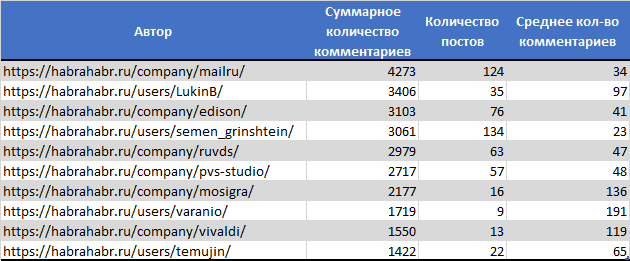
ТОП10 с наибольшим числом комментариев
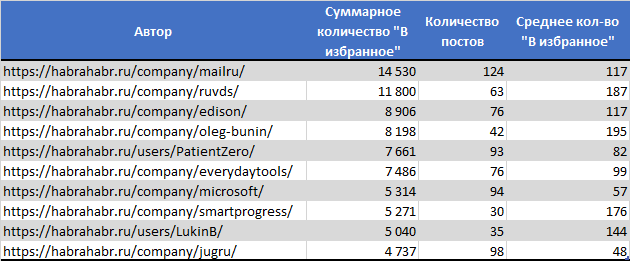
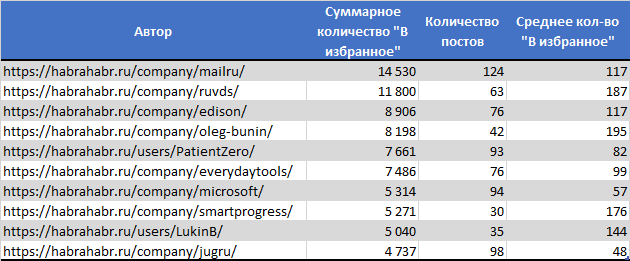
ТОП10 с наибольшим числом добавлений в избранное
Если Вас интересует какая-либо зависимость показателей, оставьте комментарий, по возможности постараемся рассчитать и опубликовать. Напишите нам и мы отправим вам ссылку на файл Excel c данным о публикациях, которые мы собрали.
- В какой день недели и время суток лучше всего публиковаться?
- Есть ли зависимость между числом подписчиков и популярностью постов?
- Каких постов больше: обучающих материалов, переводов или прочих?
И многое другое…

Что мы сделали?
24 апреля 2017 года была собрана статистика по всем последним публикациям на Хабрахабре. Оказалось, что в период с 20 сентября 2016 года по 22 апреля 2017 года:
- Создано 6550 публикаций, исключая «Мегапосты» с анонсом в верхнем меню и посты, опубликованные компаниями, прекратившими активность на Хабре.
- В среднем в день публиковалось 30 постов, а в месяц более 900.
- Около 12,5% было помечено тегом «Перевод», 10% с пометкой «Tutorial» и 4% с «recovery mode». Около 76% постов не имело таких отметок, при этом некоторые записи обозначены двумя и более тегами.
Для достоверности статистики из более 6,5к публикаций мы удалили публикации, количество просмотров которых не попадает в 99,7% область нормального распределения просмотров. Такие посты могут испортить статистику, сильно повлияв на средние значения и стандартные отклонения в дальнейших расчетах. Публикации мы удаляли до тех пор, пока все они не укладывались в
. Всего было удалено 7,4% супер-публикаций.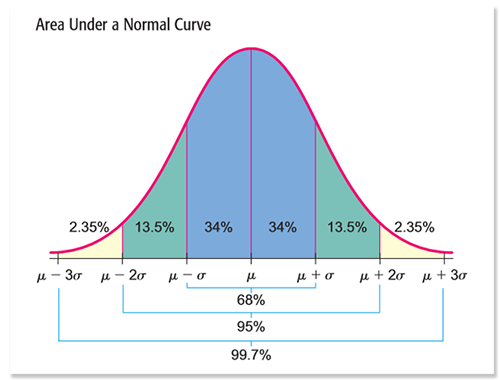
Плотность нормального распределения
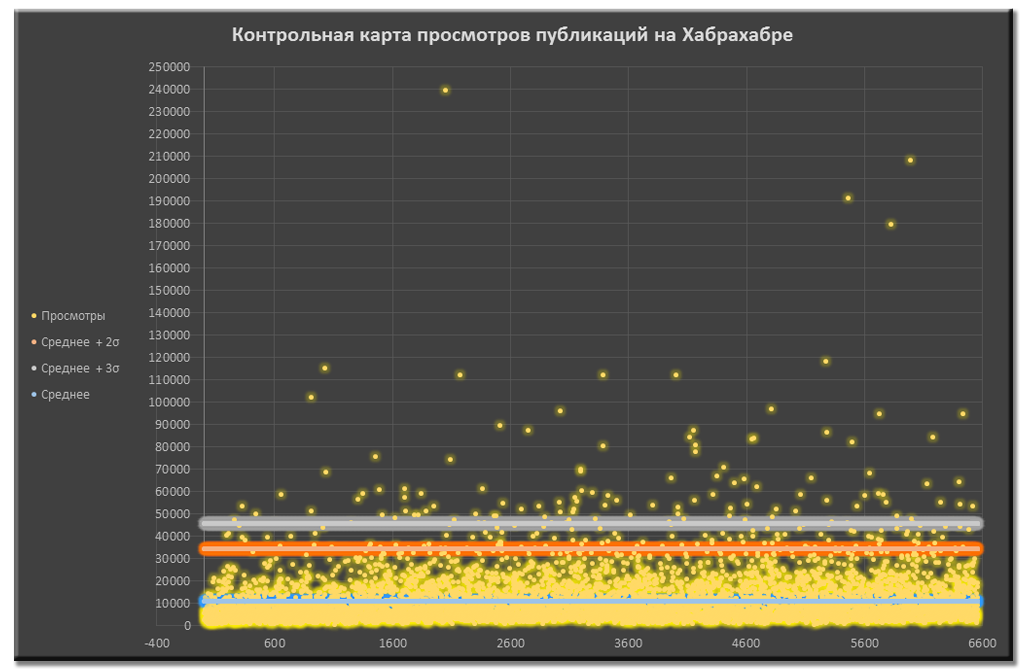 Контрольная карта просмотров публикаций до чистки данных
Контрольная карта просмотров публикаций до чистки данных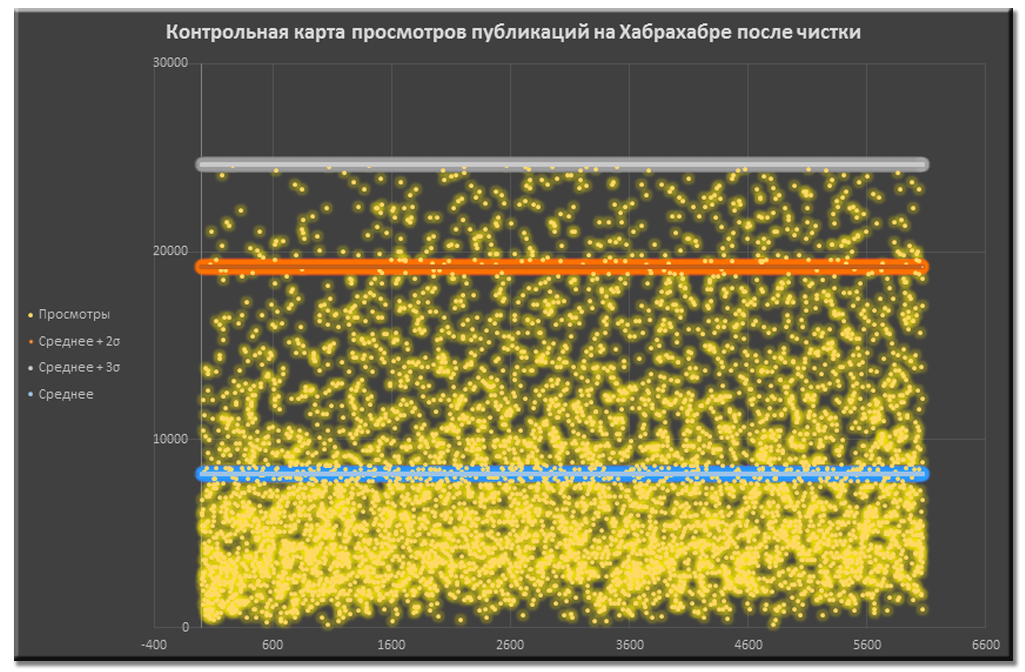 Контрольная карта просмотров публикаций после чистки данных
Контрольная карта просмотров публикаций после чистки данныхПолезная находка #1
Среди почищенного набора данных
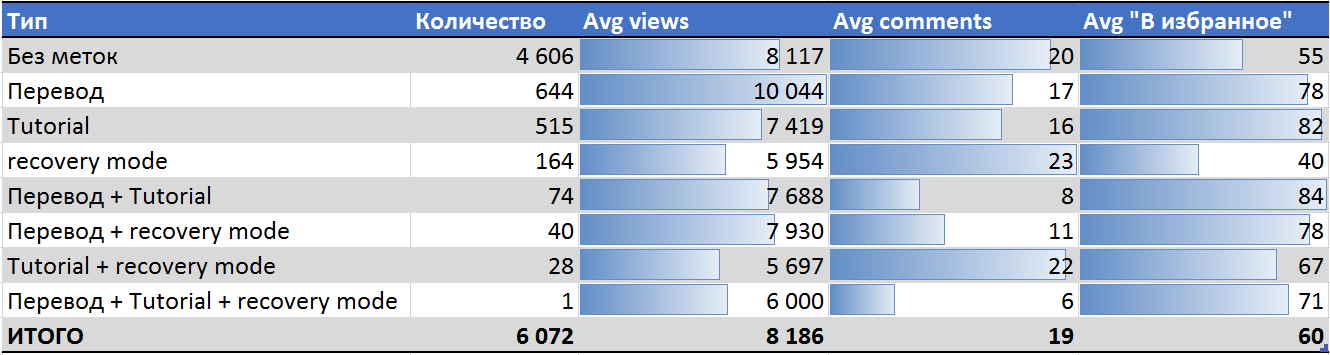
- Переводы набирают наибольшее число просмотров и лучше среднего поста добавляются в избранное, вызывая при этом меньше среднего число комментариев.
- Обучающие материалы просматриваются меньшее количество раз, чем средняя статья, но лучше всех добавляются в избранное, особенно в случае с переводным Tutorial.
- Для реабилитационного поста пользователю с отрицательной кармой лучше всего сделать перевод годного материала.
Полезная находка #2
- Количество подписчиков не влияет на количество просмотров публикации. Например, google с 14000 подписчиками на момент публикации набрал 570 просмотров одного из своих постов за 40 дней.
- Чтобы хуже всего сконвертировать количество подписчиков в количество просмотров, необходимо публиковать статьи частями и добавлять номера частей в заголовок. К 3 или 4 части публикации количество просмотров, как правило, падает до минимума. Срабатывает принцип «воронки». Те, кто не читал первую часть, редко берутся за вторую. Среди читавших 1 статью серии лишь часть пользователей будет читать вторую. Возможно, выходом будет расположить информацию о прочих статьях серии внутри публикации.
- Приглашения и объявления, конечно, соберут малое число просмотров. Статистика рекомендует интегрировать приглашения и объявления внутрь статей.
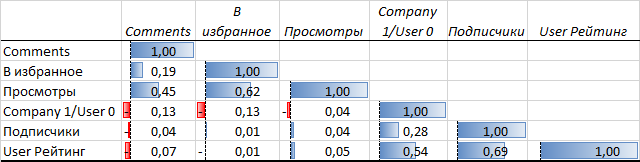
Попарная корреляция основных показателей
Полезная находка #3
Лучшие дни недели
- по количеству просмотров Суббота и Воскресенье (худший Среда).
- по количеству добавлений в избранное Понедельник и Воскресенье.
- по количеству комментариев Вторник и Суббота.
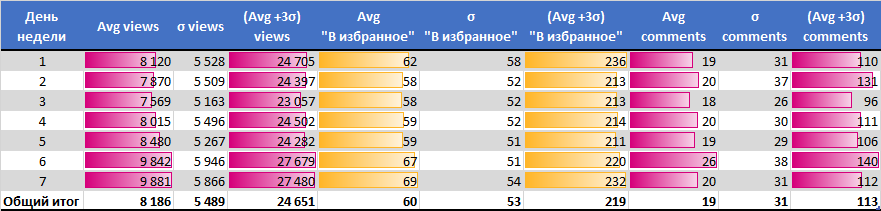
Лучшее время
- по количеству просмотров с 23:30 до 00:00
- по количеству добавлений в избранное с 6:30 до 8:30
- по количеству комментариев с 5:30 до 7:30

Лучшее время публикации при учете дня недели — ночь с пятницы на субботу или вечер воскресенья.
 Картинка может быть увеличена по клику (открывается в текущем окне)
Картинка может быть увеличена по клику (открывается в текущем окне)О выводах
Согласно смыслу закона больших чисел, всегда найдётся такое конечное число испытаний, при котором с любой заданной наперёд вероятностью меньше 1 относительная частота появления некоторого события будет сколь угодно мало отличаться от его вероятности. На этом свойстве основаны методы оценки вероятности на основе анализа конечной выборки. Наша выборка для каждого разреза имела более 30 результатов эмпирических испытаний — фактических показателей публикаций.
При публикации одной конкретной статьи приведенные выше закономерности могут не оказать значительного влияния или будут нивелированы другими факторами. Если же планируется опубликовывать серию постов, использование этих закономерностей может принести пользу. В каждом отдельном случае наибольшее влияние на показатели популярности статьи имеет её содержание.
Рейтинги
ТОП10 Компаний и Пользователей с наибольшим числом подписчиков
ТОП10 с наибольшим числом просмотров
ТОП10 с наибольшим числом комментариев

ТОП10 с наибольшим числом добавлений в избранное
- Наибольшее число комментариев собрала статья «Почему мы злые?»
- Самой просматриваемой статьей, обладающей также наибольшим количеством добавлением в избранное, стала «Как «пробить» человека в Интернет: используем операторы Google и логику»
- 2 место по количеству добавлений в избранное заняла публикация «Самые полезные приёмы работы в командной строке Linux»
P.S.
Если Вас интересует какая-либо зависимость показателей, оставьте комментарий, по возможности постараемся рассчитать и опубликовать. Напишите нам и мы отправим вам ссылку на файл Excel c данным о публикациях, которые мы собрали.
