
В одном из прошлых постов мы разбирали методологию аудита инфраструктуры. С течением времени эта тема ничуть не потеряла своей актуальности: комментаторы интересовались, можно ли на фоне полупроводникового кризиса хотя бы чуть-чуть «дожать» свою инфраструктуру, чтобы ее мощностей хватило еще на полгода-год. Иными словами, компаниям требуется апгрейд, однако оборудование приходит с большими задержками и поэтому требуется искать способы «переждать» этот период с минимальными издержками.
Мы провели ревизию и подготовили небольшой гайд, который поможет тем, кто оказался в подобной ситуации. Под катом разберем наиболее распространенные причины потери производительности и инструменты для аудита утилизации.

Чаще всего клиенты обращаются к нам за аудитом инфраструктуры в трех ситуациях:
Оборудование утилизируется не полностью «по историческим причинам».
К примеру, бизнес запрашивает у ИТ-департамента ресурсы под свои нужды: серверы, виртуальные машины, однако утилизирует их далеко не полностью, а со временем и вовсе «забывает» об их существовании. С подобной проблемой к нам обратился один крупный банк. По окончании аудита удалось «высвободить» порядка 25% неиспользуемых мощностей.
Простой, но часто встречающийся кейс: приходит пора закупать новое оборудование.
На первый взгляд ландшафт утилизирования инфраструктуры у клиента выглядит равномерно, ресурсы расходуются грамотно. Но на разных по объему платформах утилизация происходит по-разному. Иногда можно высвободить немало ресурсов за счет консолидации платформ.
Трансформация ИТ-инфраструктуры.
Например, переезд в облако, — это повод провести аудит и определить, сколько облачных ресурсов потребуется бизнесу. Кто-то переезжает «как есть», кто-то предпочитает заранее исправить старые ошибки, кое-что оптимизировать и в результате сэкономить. А некоторые заказчики после миграции используют освободившееся оборудование как резервное.
Перейдем к обзору утилит, которые мы используем в рамках обследований инфраструктуры. Для удобства все средства анализа утилизации будут разбиты по направлениям их применения.
Обзор средств анализа серверной инфраструктуры
Особенности утилизации серверов
Короткий аудит позволяет выявить «кандидатов» на оптимизацию. К слову, подобная услуга полезна не только при дефиците оборудования. В нашей практике были случаи, когда такие обследования инициировали новые ИТ-директора, чтобы понять, почему основная нагрузка приходится всего на 10% имеющихся систем и зачем тогда нужны все остальные. При слияниях и поглощениях это также актуально, так как перед интеграцией систем важно понимать, что из оборудования и в каком состоянии стоит на балансе. Примечательно, что при подобном «перетряхивании» можно обнаружить массу интересного. Например, серверы-призраков, закупленные ранее под проекты, но и в итоге так и не использованные. И такие случае не единичны в нашей практике. В целом, если судить по опыту крупных компаний, при парке от 50 до 100 серверов усредненный параметр утилизации центрального процессора на всех серверах может быть равен 5 – максимум 10%. Следовательно, найти незадействованные ресурсы можно практически всегда. Но важно понимать, как правильно перебалансировать нагрузку между системами, чтобы не пострадали бизнес-сервисы.
Использовать бесплатное/общедоступное ПО?
Оптимизационный аудит можно провести самостоятельно или с привлечением подрядчика. Все работы занимают около недели. При этом применяются специальные утилиты – по большей части свободное ПО.
Для каждого типа инфраструктуры они различны. Например, для оценки утилизации виртуальных машин (CPU/RAM/Disk) мы используем RVTools, а для физических серверов — Live Optics. Затем делаем срез конфигурации, в том числе во времени. В результате собираем статистику по параметрам (время отклика, задержка и т.д.). На основе этой информации можно обнаружить неоптимальные процессы и затем их «починить». В частности, можно виртуализовать физические серверы, перераспределить ресурсы по кластерам виртуализации, устранить причины аномальных нагрузок отдельных серверов, перенести часть виртуальных машин в облако.
Какие средства вообще есть:
самописные скрипты: RVTools, Get-HyperVInventory. Эти скрипты собирают данные с хостов в средах виртуализации VMware и Hyper-V соответственно. Их функционал схож, собранные данные сохраняются в форматы .xls и .html.
средства производителей, доступные бесплатно: Live optics;
средства производителей, доступные за деньги: HPE SAF.
Live Optics: как может быть использовано
Устанавливается на одну из централизованных машин в сети с серверами. Для его работы требуется Net.4.5. Софт работает с анализом не только серверов, но и СХД и данных, поэтому раздел для серверов — Server&Virtualization.
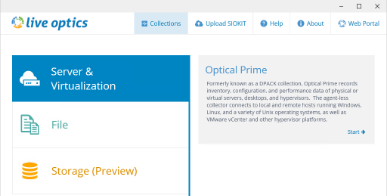
ПО устанавливает подключение к сайту и в этом случае может «отправлять данные» тому, кто проводит обследование (подрядчик), «Establish a secure connection (HTTPS)», а при отсутствии доступа к интернету сохраняет собранную статистику локально. В этом случае статистика будет ограничена 24 часами, но для целей аудита это, как правило, приемлемо.
Как подключить сервер: добавить удаленный сервер через «Add Remote Server» и ввести запрашиваемые данные (Server URL), выбрав Connect to a Windows Server/supported Linux/UNIX Server.

Выбрать длительность сбора и нажать «Start Capture».
После окончания сбора статистики появится файл с расширением .iokit. Обычно его размер не более нескольких десятков МБ. Сбор данных увеличивает нагрузку на CPU незначительно, как правило, всего на несколько процентов.
Файл .iokit должен быть загружен на портал app.liveoptics.com. После выбора проекта на панели мониторинга на вкладке «среда» будет доступна информация о физических и виртуальных серверах, ресурсах и кластерах, по которым были собраны данные.

Здесь видна статистика по серверам, включенным в обследование. Можно увидеть суммарный объем физических характеристик обследуемого объема серверов, распределение используемых ОС, пять основных серверов по выбранному параметру.
На вкладке «виртуальный» можно увидеть суммарную информацию по физическим и виртуальным ресурсам, графики распределения ресурсов и полный перечень виртуальных машин с их основными характеристиками.


Для каждой виртуальной машины доступна информация о ее статусе, имени, ОС, полном и занятом объеме дисковых ресурсов, полном и используемом объеме ОЗУ, количестве виртуальных CPU и платформе виртуализации.
На вкладке «производительность» представлены кластеры виртуализации, входящие в них гипервизоры и расположенные на них виртуальные машины. По каждому из вышеперечисленных объектов составляются графики за выбранный период сбора данных по следующим величинам:
Для кластера и гипервизора:
IOPS;
пропускная способность диска;
объем ввода-вывода;
задержка чтения и записи;
длина очереди;
утилизация CPU;
память;
ошибки страницы;
участие;
пропускная способность сети;
график плотности загрузки;
пузырьковая диаграмма плотности загрузки.
Для виртуальной машины:
IOPS;
пропускная способность диска;
объем ввода-вывода;
задержка чтения и записи;
длина очереди.
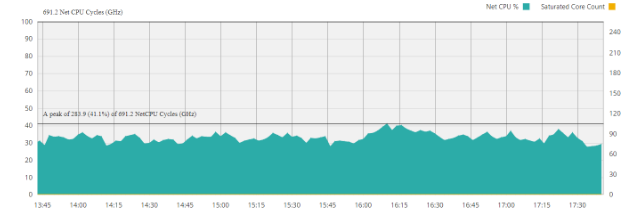
По графикам утилизации выявляются аномалии по каждому виду ресурсов:
неутилизированный – хост отключен или загрузка составляет <5% на протяжении всего времени обследования;
недоутилизированные – загрузка составляет <30% на протяжении всего времени обследования;
высокая утилизация – загрузка составляет >70% на протяжении всего времени обследования.
Средства производителей: HPE SAF
HPE SAF – инструмент, который может быть использован для сбора данных о производительности серверов под управлением операционных систем Windows и Linux. Также с его помощью можно собрать информацию с хостов виртуализации под управлением гипервизоров VMware и Hyper-V. Помимо этого, HPE SAF может собирать данные с различных типов СХД.
Доступ к утилите на сайте производителя предоставляется свободно, для скачивания необходим лишь HPE Passport Login, скачать можно по ссылке. В скачиваемом архиве, помимо исполняемого файла, можно найти руководство пользователя.
Для запуска потребуется компьютер под управлением OC Windows. Собранные данные по умолчанию хранятся в том же каталоге, что и исполняемый файл, эти настройки можно изменить. Общий размер файлов собираемых данных даже для относительно больших инфраструктур (около 100 серверов) обычно не превышает нескольких десятков мегабайт. Для получения информации для систем MS Windows используется механизм WMI.
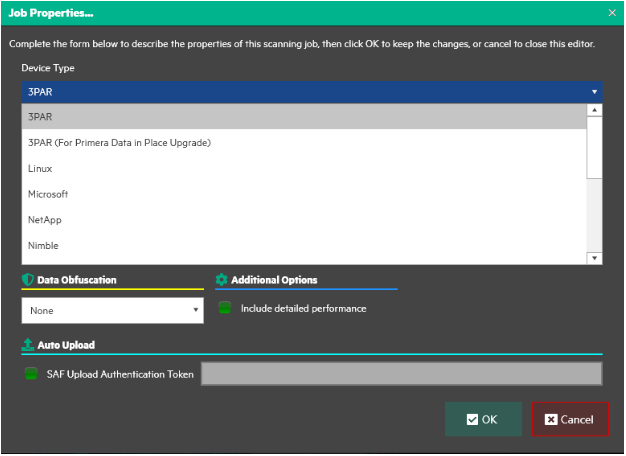
Для каждого сервера, с которого мы хотим собрать данные, необходимо запустить отдельное задание, в котором вводятся данные для подключения. Для системы виртуализации VMware возможно подключение к vCenter. Длительность сбора данных можно выставить в диапазоне от одного часа до семи дней.
Для запуска нового задания необходимо выполнить его настройку. Делается это нажатием на панель New Jobs в разделе Actions в правом верхнем углу окна программы:

Информацию по настройке для разных типов оборудования можно найти в руководстве пользователя.
Сообщения о всех событиях (в т.ч. о выполненных заданиях и ошибках) будет появляться в окне Event, которое, в свою очередь, станет доступно после запуска заданий по сбору данных в нижней части окна программы:

После сбора информации с оборудования данные необходимо загрузить на портал HPE SAF. К сожалению, в руководстве пользователя нет информации по части взаимодействия с порталом — она есть только во встроенной справке самого портала — но найти ее не очень просто. Сам портал выглядит следующим образом (в нем по умолчанию присутствуют два отчета для получения представления о предоставляемой сводной информации):
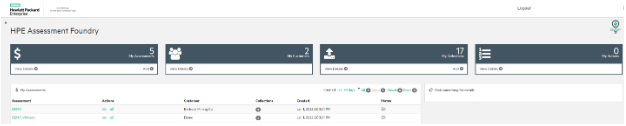
Для загрузки данных необходимо создать новый Assessment, заполнить поля и нажать Add. При этом в поле Customer обязательно нужно ввести какую-либо информацию — без этого кнопка Add не станет активной. При необходимости предоставления доступа еще кому-либо в поле Contact и Email добавляются соответствующие данные и ставится галочка в поле Send Invitation Email. Сама форма представлена на рисунке ниже:

После заполнения формы появится возможность загрузить собранные данные для анализа:

После загрузки данных для получения отчета необходимо запустить анализ

После завершения процедуры обработки данных повторное нажатие пиктограммы Analyze позволит посмотреть сводные данные и скачать готовые отчеты.
Система формирует два файла – Analysis Summary (в формате MS Word) и Details Spreadsheet (в формате MS Excel). В первом из них содержатся сводные данные за весь период сбора информации, представленные значения выводятся в двух видах: диаграммах и графиках, пример можно увидеть ниже:
1.4 | 0.2 | 9 |
*Read ms | *Write ms | *Write % |

В файле Details Spreadsheet представлена информация по hardware-составляющей: производитель, модель процессора, памяти, используемое дисковое пространство.
В целом описанный инструмент позволяет получить достаточно данных для анализа оборудования при минимальных затратах. Главным его достоинством, на мой взгляд, помимо простоты использования, является представление полученной информации в готовом структурированном виде.
Если сравнивать два инструмента — HPE SAF и Live Optics, то по большинству характеристик выигрывает именно Live Optics, так как он предоставляет намного более детальную информацию, а в части отображаемых данных (например, утилизации сетевых интерфейсов для серверного оборудования или построения диаграмм утилизации CPU и RAM по времени) является просто незаменимым, потому что в HPE SAF такая возможность либо сильно урезана, либо ее просто нет. С другой стороны, HPE SAF можно использовать, когда детальная информация не требуется, а достаточно лишь составить представление о парке используемого оборудования и его общих характеристиках.
Виртуализация
Особенности аудита виртуализации с использованием RVTools
Для использования необходимо установить утилиту на любом хосте и при запуске указать целевой vCenter и учетную запись для доступа к нему.


После успешной авторизации будет отображено главное окно программы, отсюда данные можно экспортировать в Excel.

Собранные данные представляют собой таблицу Excel со множеством вкладок:
vHost — данные о хостах виртуализации, включая информацию о статусе хоста, принадлежности хоста к кластеру, объеме ресурсов (CPU, vCPU, RAM, vRAM и т.д.), модель и серийный номер сервера и т.п.
vCluster — суммарные данные о статусе и ресурсах кластеров.
vInfo — информация о виртуальных машинах, включая статус вм, ресурсы вм, принадлежность вм к кластеру, ОС виртуальной машины и т.п.
vDatastore — информация об объеме датасторов, их адресе и подключенным хостам.
Особенности аудита виртуализации с использованием Hyper-V Inventory
Для сбора данных PowerShell скрипт запускается на любой Windows-машине. Собранные данные представляют собой html-файл, содержащий разделы с информацией о кластере и входящих в него хостах.

Раздел General Cluster Information описывает общую информацию о кластере. В отчете существуют разделы, описывающие ПО, hardware, storage, network по каждому хосту.
Для большинства вендоров Hyper-V Inventory, так же как и RVTools, корректно вытаскивает серийник, что позволяет получить информацию о статусе поддержки сервера через вендорские инструменты.
Раздел Virtual Machine Information содержит информацию о виртуальных машинах, их статусе, ресурсах, ПО и т.п.
Hyper-V Inventory и RVTools – утилиты со схожим функционалом, используются в зависимости от среды виртуализации, которую надо обследовать. Они дают представление о том, сколько и каких машин расположено в кластерах и сколько ресурсов им доступно. Их применением можно ограничиться, когда цель аудита – инвентаризация имеющейся инфраструктуры или выявление устаревшего оборудования.
Когда обследование проводится для выявления проблем с производительностью или оптимизации используемых ресурсов, практически необходимо получить динамические данные утилизации за продолжительный период времени. Тут нам на помощь приходят HPE SAF и Live Optics. Лучше собирать данные хотя бы за неделю, так как нагрузка может меняться в связи с расписанием резервного копирования и особенностей прикладного ПО.
СХД
Анализ СХД – огромная область со своей спецификой и чаще всего связана с анализом производительности систем хранения и таких параметров, как количество операций ввода-вывода, времен времена отклика, задержек.
Чаще всего на СХД мы смотрим для оценки утилизации и вариантов масштабирования. Это анализ утилизации или использования пространства хранения (в течение короткого/анализируемого периода) или в течение длительного времени с планированием предстоящих периодов.
Утилиты для анализа СХД мы делим на несколько категорий, про них дальше кратко и расскажем:
средства производителей СХД;
подручные средства и утилиты (Iometer);
Zabbix и пакеты расширенного мониторинга СХД.
Средства производителей СХД
У каждого из крупных производителей есть сервис или услуга, которая позволяет пользоваться аналитическими инструментами вендора «в своих» целях и оформить детальное описание параметров статистики СХД за заданный период. Чаще всего используется портал вендора, который после загрузки логов с СХД формирует отчет о состоянии системы. Примерами таких средств могут быть Hitachi Health check report, тот же функционал HPE SAF или Live Optics, Dell Copilot NetApp ActiveIQ и средства других производителей.
Такой отчет показывает:
наличие ошибок и HealthCheck;
характер нагрузки СХД с указанием профиля нагрузки, максимальных и аномальных значений – IOPS, задержек, пропускной способности;
проактивную аналитику (по темпам роста данных, возможным ошибкам/ срокам отказа оборудования и т.п.);
дополнительную «автоматизированную» и «кастомизированную» (под конкретного заказчика в зависимости от вендора) аналитику от вендора по оптимальной настройке окружения.
Особенностью таких решений является то, что аналитика преподносится обычно в разрезе, выгодным определенному производителю, и воспринимать её стоит с осторожностью. Средства такого уровня используются для заданных моделей СХД, когда нужен разносторонний анализ «в общем виде» с достаточной степенью погружения.
Подручные средства и утилиты
Кейсы, в которых нужен не столько общий обзор СХД, сколько детальный анализ таких направлений, как производительность/утилизация, предполагает использование специализированных утилит. Перечислим основные из них.
Утилиты анализа нагрузки от производителей СХД
Практически все производители СХД предлагают отдельные утилиты для анализа производительности и сбору статистики с ее отображением в виде графиков. Примером может быть Performance Advisor от NetApp. К подобным можно отнести perfstat, собирающую в текстовый файл нагрузку на СХД. С их помощью можно проанализировать нагрузку на СХД с разных сторон: со стороны хостов, нагрузку на Front-End, На Back-End. Обычно такие инструменты не требуют наличия специальных лицензий.
IOMeter
Средство генерации заданного профиля нагрузки, включающего такие параметры как block size, соотношение чтения/записи, характеристики I/O и другие. Работает посредством специальных worker, которые могут генерировать трафик. Несмотря на то, что средство предоставляет инструмент и для сбора данных, анализ проще и удобнее проводить посредством других утилит.
Средства ОС
К средствам ОС можно отнести широко известные утилиты, такие как: Explorer для Solaris, ESXi performance для VMware, Iostat для Linux, счетчики Windows, Perfmon (GUI), Logman (CLI), сбор статистики. Утилиты используются в разрезе по логическим и физическим дискам.
Средства анализа SAN
Помимо указанных, часто используемым средством является Brocade SANHealth, и рассмотрение комплексных кейсов не обходится без этого инструмента и анализа SAN. Битые линки, очереди на HBA-адаптерах/портах, оптимизация политик мультипассинга – все это можно отследить и понять с помощью этой утилиты.
Расширенный мониторинг СХД
Отдельный случай при анализе больших ИТ-инфраструктур – обследования, требующие максимально эффективного/расширенного мониторинга систем хранения данных в течение определенного (возможно, длительного) периода без приобретения дорогостоящих лицензий
В таких случаях мы используем подход, предполагающий краткосрочную инсталляцию системы мониторинга в рамках инфраструктуры заказчика, «заточенной» под анализ конкретных моделей СХД. Это решение можно использовано исключительно в рамках аудита, но некоторые заказчики оставляют его у себя и после обследования, чтобы получать информацию об ИТ-инфраструктуре на постоянной основе в режиме реального времени за невысокую стоимость.
Примером системы мониторинга служит платформа Zabbix, на базе которой мы разработали и используем модули расширенного мониторинга различных платформ, в том числе и систем хранения. Это мощный инструмент для мониторинга ИТ-инфраструктуры с открытым исходным кодом, который распространяется под лицензией GPL v2. Модули собирают данные, используя базовые протоколы мониторинга, и поддерживают СХД Hitachi, DellEMC, HPE, NetApp, Huawei и другие. Перечень оборудования пополняется новыми моделями и поколениями.
Возможны следующие варианты внедрения в рамках обследования у заказчика:
готовая виртуальная машина с установленным ПО;
полноценная инсталляция в масштабируемой конфигурации;
мониторинг из облака.
Основные преимущества – это а) бесплатно, б) дает максимально детализированные метрики, в) предоставляет возможность использовать функционал онлайн-мониторинга в процессе обследования – оповещений/триггеров, прогнозирования, анализа соблюдения SLA и так далее.
Развертывание в базовом варианте без кастомизации занимает 2-3 дня, в зависимости от размера пилотной зоны и количества модулей.
Мы разработали специальные модули под популярные на рынке России СХД, которые, помимо данных с самих систем хранения, собирают информацию о состоянии коммутаторов сети хранения данных, дисковых и ленточных библиотек, потреблении хранилищ платформами виртуализации.
В таблице 1 приведены группы и перечень основных собираемых метрик для каждой из них. Набор метрик, параметры хранения исторических данных для задач мониторинга, параметры оповещений настраиваются индивидуально для каждого заказчика с учетом особенностей бизнеса.
Таблица 1:
Группа собираемых данных | Перечень метрик |
Инвентарные данные СХД | Серийный номер Модель Версия микрокода Имя |
Общее состояние СХД | Статус Состояние |
Инвентарные данные портов | Имя Номер порта Скорость работы WWpN |
Состояние портов/томов/пулов/аппаратных компонент СХД | Входящий/исходящий трафик Количество операций ввода/вывода Время отклика |
Статистика портов | Суммарный трафик Количество операций ввода/вывода Время отклика |
Статистика томов | Входящий/исходящий/суммарный трафик Количество операций ввода/вывода Количество операций случайного ввода/вывода Количество операций последовательного ввода/вывода Попадание в кэш Время отклика Другие метрики в зависимости от модели системы хранения |
Утилизация (свободное и занятое пространство) пулов и СХД в целом | Общий объем Занятое пространство Свободное пространство |
Решение обеспечивает полную видимость инфраструктуры и в режиме реального времени позволяет построить:
общие топологические карты сети хранения данных;
В топологических картах отображаются соединения между всеми устройствами сети хранения.
Здесь и далее устройства, порты устройств и соединения в случае обнаружения проблем будут иметь цветовую подсветку. Она зависит от настроенного уровня критичности события.

топологические карты для платформ виртуализации;
В них отображаются соединения и связи между виртуальными машинами, гипервизорами, коммутаторами сети хранения, системами хранения, томами, пулами.

комплексные экраны с отображением состояния систем:
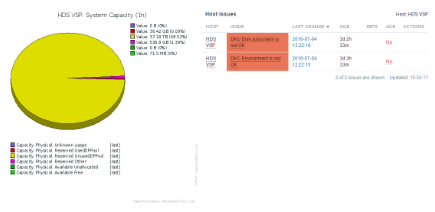
отображение состояния аппаратных компонентов СХД:

графики:
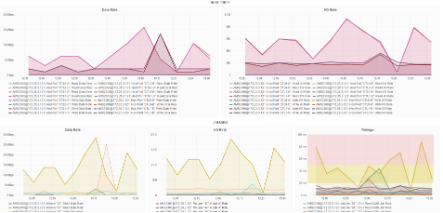
Представлять данные в графическом виде можно путем использования существующих шаблонов или создания собственных. Представление собранных данных в графическом формате позволяет быстрее и глубже анализировать информацию в едином интерфейсе.
Таким образом, использование платформы мониторинга в совокупности с разработанными модулями расширенного мониторинга — недорогое и максимально мощное средство для:
краткосрочного анализа и оптимизации инфраструктуры хранения данных, сокращения затрат за счет эффективного управления;
анализа производительности систем хранения путем анализа полученных данных и удобной визуализации;
визуализации топологии инфраструктуры.
Что когда использовать?
Чаще всего обследование СХД связано с анализом масштабируемости, утилизации и производительности СХД. Вопросы локальной производительности или глубокого анализа решаются подбором и использованием специализированных утилит.
Поверхностный анализ состояния здоровья СХД в целом чаще всего реализуется средствами вендора – с привлечением его служб — или общедоступными утилитами, «работающими» с СХД конкретного производителя.
Долгосрочный анализ конкретных СХД с максимальной степенью детализации может быть выполнен средствами систем мониторинга с максимально возможными метриками.
Средства резервного копирования (СРК)
СРК стоит рассмотреть отдельно, ведь это далеко не всегда софт + сервер с дисками/СХД, когда можно обойтись и описанными выше средствами анализа, но зачастую нужны ещё и специфические апплаенсы на бэкенде, которые требуют особого подхода. Также существует возможность выполнения специфического анализа и со стороны ПО СРК.
Утилиты для выполнения анализа можно разделить на две категории:
сторонние средства анализа;
собственные средства производителей ПО/устройств СРК.
Сторонние средства анализа
Незаменимым сторонним средством анализа является всё тот же Live Optics. Во-первых, он бесплатен, во-вторых, для анализа доступна большая линейка ПО СРК Enterprise-уровня:
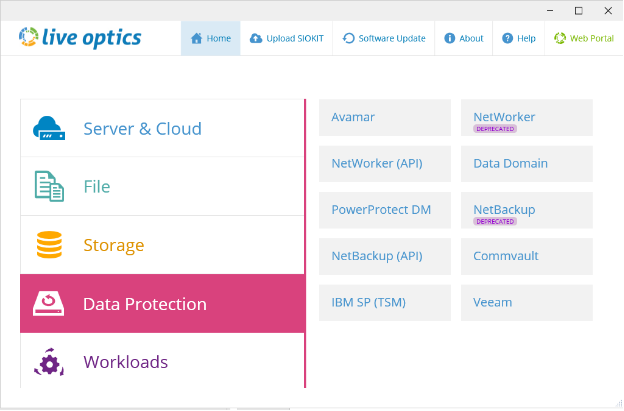
Со специфическими бэкапными back-end устройствами ситуация не такая радужная – выполнение анализа доступно только для Dell EMC DataDomain.
Особенность анализа ПО СРК средствами Live Optics – отсутствие прямой интеграции с большинством ПО. Так, для Veeam или CommVault придётся сначала выгрузить дампы БД СРК средствами ПО СРК, а потом уже загрузить их в анализатор Live Optics. Более тесная интеграция через API, которая позволяет Live Optics подключить напрямую к серверу управления СРК и собрать все необходимые данные, пока доступна только для Networker и NetBackup. Вывод результатов работы Live Optics возможен в двух форматах: презентация и таблицы.
Презентация состоит из 9 слайдов, позволяющих получить overview о домене СРК. Она подсвечивает основные узкие места на следующих графиках:
общие параметры СРК, включая версии ОС и ПО, количество и тип клиентов;
распределение заданий резервного копирования по длительности выполнения за последние 120 дней;
топ-10 самых длительных по выполнению заданий РК;
топ-5 самых больших по объёму заданий РК;
топ-10 самых больших по объёму клиентов РК;
ежедневные объемы РК в заданиях и ГБ;
средняя скорость записи.
Пример графика ежедневного объема резервных копий из презентации Live Optics:

Табличное представление – это по сути экспорт БД СРК в xls. В книге, в нескольких таблицах, представлен огромный массив сырых данных по всем заданиям и клиентам СРК. Представление на первый взгляд нечитабельно, но с помощью обыкновенного поиска по таблицам или фильтрам можно раскопать любые статистические данные о заданиях или отдельных клиентах СРК, включая длительность выполнения, количество успешных и неуспешных попыток резервного копирования, характер ошибок сбоев, объемы данных, места хранения данных, версии ОС, ПО СРК и так далее.
Аналогичным средством сбора диагностической информации о СРК является Mitrend.
Принцип работы, охват ПО СРК аналогичен Live Optics. Среди ПО СРК и back-end устройств для анализа доступны: ArcServe, Avamar, Backup Exec, CommVault, Data Protector, Microsoft DPM, NetBackup, NetVault, NetWorker, Oracle RMAN, TSM, Veeam, VMware VDP, Data Domain.
Вывод результатов работы Mitrend scanner также доступен в двух форматах: презентация и таблицы.
В презентации Mitrend представлены данные, несколько отличающиеся от тех, что содержатся в презентации Live Optics. Но суть от этого не меняется — презентация состоит всего из 10 слайдов и даёт лишь overview о домене СРК. В данном представлении содержится следующая информация за последние 7 дней:
общие сведения о сервере РК;
информация о ежедневных потоках резервного копирования и восстановления данных в GiB;
summary по устройствам резервного копирования: тип и утилизация в GiB;
информация о лицензиях;
распределение заданий резервного копирования по длительности выполнения;
топ бэкапов по длительности выполнения;
топ самых больших по объёму заданий РК;
топ самых больших по объёму клиентов РК.
Пример графика ежедневных потоков резервного копирования и восстановления данных из презентации Mitrend.

Табличное представление аналогично Live Optics, ведь оно зависит только от структуры самой БД СРК.
Резюме: оба средства обладают приблизительно одинаковым функционалом с одной лишь разницей — за подписку Mitrend придётся заплатить, тогда как Live Optics бесплатен.
По эффективности использования указанных средств вывод неоднозначен.
Представление данных в виде презентации ограничено и не всегда информативно. Есть большой шанс не найти нужный график среди имеющихся, поэтому такое представление может служить, скорее, верхнеуровневым описанием СРК для руководства, а не надёжным инструментом администратора.
Более глубоко копнуть позволяет табличное представление, но оно нуждается в дополнительном трудозатратном парсинге, если данные нужны сразу по нескольким выбранным клиентам/заданиям. Такой вариант анализа подойдет тем, кто хочет получить подробную статистику по единичным заданиям/клиентам либо, наоборот, собрать общие суммы по заданиям РК, например, для последующего сайзинга или лицензирования СРК.
Средства основных производителей
У некоторых Enterprise-производителей есть собственные средства аналитики. Например, Veritas OpsCenter Analytics, Veritas Aptare, EMC Data Protection Advisor, Veeam One Monitoring & Analytics. Такие средства позволяют получить наиболее полную картину о домене СРК в наиболее удобном представлении. Зачастую они являются ещё и вендоронезависимыми, то есть аналитику можно получить не только по ассоциированному с конкретным вендором продукту, но и по большинству популярных ПО/устройств РК. Более того, такие продукты, как Veritas Aptare и EMC Data Protection Advisor, позволяют анализировать всю ИТ-инфраструктуру. Помимо устройств и ПО СРК, доступен анализ серверов, СХД, средств репликации, IaaS-платформ и средств виртуализации. Но есть и минусы: такие средства требуют отдельной постоянной инсталляции и, как правило, не бесплатны.
В зависимости от производителя набор различных отчетов, генерируемых подобным ПО, и дашбордов может незначительно отличаться, но концепция работы практически идентична. По этой причине предлагаем не рассматривать всех производителей, а остановиться на паре утилит с наибольшим охватом возможностей.
Veritas Aptare
С помощью Veritas Aptare можно получать аналитику о значительном количестве компонентов ИТ-инфраструктуры. Все они представлены на рисунке:

Что же позволяет анализировать Aptare применительно к СРК?
Инвентаризация ресурсов. С помощью Aptare можно получить графическое представление домена СРК, по клику на каждый из компонентов домена получить информацию о нем: аппаратная конфигурация, сетевые настройки, версия ОС, лицензирование.

Соответствие SLA. Aptare позволяет получить информацию в виде графических отчетов о трендах СРК: окна резервного копирования, продолжительность выполнения заданий, незащищенные СРК данные. Также доступен функционал поиска ложно-успешных заданий РК – частично завершенные или неуспешные задания, отмеченные в интерфейсе ПО СРК как успешные. Статус РК и информация об алертах автоматически подтягивается в Aptare и выводится на Dashbord:

Производительность. Следующая область анализа Aptare связана с производительностью ресурсов. Aptare позволяет строить множество отчетов и получать графическое представление следующих данных:
дисковая утилизация и производительность систем ввода-вывода;
производительность и утилизация ленточных приводов и ленточных накопителей;
статистика заданий РК: наиболее ресурсоёмкие клиенты, наиболее продолжительные задания, наиболее нагруженные устройства РК;
анализ утилизации устройств РК – оценка текущего состояния с точки зрения производительности и утилизации, прогнозирование роста объёмов устройств СРК для своевременного планирования дозакупки дополнительных ресурсов.
Мониторинг и оповещение. Aptare позволяет интегрироваться с системами мониторинга и настраивать оповещения на все возможные типы событий: от алертов от компонентов СРК до генерации и отправки различных отчетов о состоянии СРК.
Dell EMC Data Protection Advisor
Dell EMC DPA не уступает Aptare по охвату компонентов РК:

По функционалу тоже. Работа ПО строится на тех же принципах:
Консолидация ресурсов – единый dashboard для отражения конфигурации и состояния всех компонент СРК. Агрегация алертов от различных устройств домена СРК.
Поиск и предотвращение. Динамический анализ событий СРК, генерация всевозможных отчётов о конфигурации, утилизации, производительности ресурсов.
Демонстрация и оповещение. Демонстрация потенциальных возможностей/изменений СРК для приведения СРК в соответствие с SLA, настройка уведомлений.
Dashboard СРК в DPA выглядит следующим образом:

Отчеты, логи и скриншоты — запасной вариант аудита
Когда по каким-то причинам нет возможности прибегнуть к специальному ПО анализа состояния СРК (будь то сторонние или нативные средства), на помощь приходит способ аудита, который сработает всегда, – сбор и анализ логов, протоколирование данных из дэшбордов ПО и устройств СРК.
Это наименее гибкий и быстрый способ анализа, но по широте возможностей он не уступает ни одному из вышеперечисленных средств.
Мы собрали данные о том, как и что смотреть руками, без сторонних средств, по наиболее популярным ПО и устройствам РК.
ПО или устройство РК | Логи | Отчеты/скриншоты |
Veritas NBU | Сбор информации об объектах домена СРК и их характеристиках, хранящихся на сервере управления: /usr/openv/netbackup/bin/admincmd/nbdeployutil --gather nbsu - сами настройки NBU | Анализ с помощью OpsCenter/ Зайти в Opscenter во вкладку Backup Reports, перейти в пункт Job Activity Reports. Далее отчеты: Backup Reports > Job Activity Reports, Job Browser Reports > Tabular Backup Reports, Status & Success Rate Reports Client Report > Risk Analysis Reports Deduplication Reports Disk & Tape Device Activity Reports Media Reports Performance Reports Policy Reports Workload Analyzer Reports |
Veritas BE | Сбор информации об политиках и ключевых настройках с использованием самиписных скриптов на базе команд типа: bppllist -allpolicies -U | Анализ с помощью отчетов GUI |
EMC Networker | Сбор информации об объектах домена СРК и их характеристиках, хранящихся на сервере управления: Windows: ftp://nwc:nwc@ftp.emc.com/nsrget.zip Unix: ftp://nwc:nwc@ftp.emc.com/nsrget.tar Nsrget.bat / nsrget.sh - ? – информация о ключах запуска …\Nsrget.log | more Самостоятельный анализ outputs или анализ с помощью Dell EMC support | Анализ с помощью DellEMC DataProtection Advisor |
Veeam B&R | Выгрузка и удаленный анализ БД SQL - С использованием SQL Server Management Studio или с использованием утилиты sqlcmd | Анализ с помощью Veeam One (проще и удобнее) |
CommVault | Выгрузка отчётов из GUI: Backup Job Summary Report (Web) Infrastructure Load Report CommCell Readiness Report License Summary Report SLA Report Использование Commvault Analytics Engine | |
DataDomain | # autosupport send <email address> — сбор основных данных о состоянии массива, утилизации, производительности. # iostat <time interval> — динамический просмотр утилизации портов | Просмотр информации об ошибках, утилизации, коэффициенте дедупликации на экране GUI, меню Health |
NBU Appliance | Анализ содержимого DataCollect - dsuhe (Main -> Support, выгрузка доступна в архиве по адресу /log/DataCollect.zip), содержит помимо прочего: Release information Disk performance logs Command output logs CPU information Memory information Patch logs Storage logs File system logs Test hardware logs Hardware information Sysinfo logs | Анализ данных портала OpsCenter (расширенная аналитика) Анализ данных Aptare (сверхрасширенная аналитика) |
HPE StoreOnce | Анализ содержимого Support Ticket с устройства Configuration, system configuration Production Status, system status iSCSIstatus Network, network information Disc System SystemLogs1, ticket.SystemLogs2, system log (syslog), kernel log (dmesg) DiscInfo DiscUsage MtckData MtckErrors ScsiLog CartridgeDir DiskSpace Eventlog | Анализ данных портала Infosight (расширенная аналитика) Анализ данных портала SAF |
TL | Генерация Support Bundle | Просмотр состояния библиотеки с помощью меню Health |
В качестве резюме мы подготовили диаграмму, отражающую основные кейсы использования того или иного метода аудита СРК. Для каждого способа рассматривается совокупность стоимости и получаемого выхлопа. Нужно заметить, что сравнение приводится в условных попугаях для среднестатистического проекта аудита и может отличаться под конкретный специфический кейс.

Верхняя правая четверть – лучшее соотношение цены и качества. Возможность получения достаточно подробных отчётов за небольшие деньги или бесплатно.
Нижняя правая четверть – наиболее широкие возможности и удобство администрирования. Но, скорее всего, за решение придется заплатить. Причем затраты будут как прямые – лицензия, так и косвенные – ресурсы для развёртывания ПО.
Левая верхняя четверть – долго, неудобно, но бесплатно. С большой долей вероятности возможно решить практически любые задачи, но только ценой потери времени.
На практике мы рекомендуем клиентам Midrange и Enterprise своевременно внедрять решения уровня Aptare/DPA. Они здорово помогают не заблудится в собственной инфраструктуре и существенно экономят силы администраторов на мониторинг.
В случае отсутствия подобного ПО большинство задач аудита закроют сторонние средства оперативного анализа типа LiveOptics/Mitrend. При невозможности запуска подобного ПО, его неполноте или в случае маленьких инфраструктур на помощь всегда придут логи и встроенные дэшборды. Предлагаемое решение предоставляет возможность настройки состояний, пороговых значений и критичности триггеров
[Если у вас остались вопросы, пишите: serverchenov@croc.ru]
