 Как и обещали, продолжаем рассказывать про освоение процессоров Эльбрус. Данная статья является технической. Информация, приведенная в статье, не является официальной документацией, ведь получена она при исследовании Эльбруса во многом как черного ящика. Но будет безусловно интересна для лучшего понимания архитектуры Эльбруса, ведь хотя у нас и была официальная документация, многие детали стали понятны только после длительных экспериментов, когда Embox все-таки заработал.
Как и обещали, продолжаем рассказывать про освоение процессоров Эльбрус. Данная статья является технической. Информация, приведенная в статье, не является официальной документацией, ведь получена она при исследовании Эльбруса во многом как черного ящика. Но будет безусловно интересна для лучшего понимания архитектуры Эльбруса, ведь хотя у нас и была официальная документация, многие детали стали понятны только после длительных экспериментов, когда Embox все-таки заработал.Напомним, что в предыдущей статье мы рассказали про базовую загрузку системы и драйвер последовательного порта. Embox запустился, но для дальнейшего продвижения были нужны прерывания, системный таймер и, конечно, хотелось бы включить какой-то набор unit-тестов, а для этого нам нужен setjmp. В этой статье речь пойдет о регистрах, стеках, и других технических деталях, необходимых для реализации всех этих вещей.
Начнем с краткого введения в архитектуру, которое представляет собой минимальную информацию, необходимую для понимания того, что будет рассматриваться далее. В дальнейшем мы будем ссылаться на информацию из данного раздела.
Краткое введение: Стеки
В Эльбрусе есть три стека:
- Стек процедур (Procedure Stack — PS)
- Стек связующей информации (Procedure Chain Stack — PCS)
- Стек пользователя (User Stack — US)
Разберем их чуть подробнее. Адреса на рисунке условные, показывают, в какую сторону направлены движения — от большего адреса к меньшему или наоборот.

Стек процедур (PS) предназначен для данных, вынесенных на “оперативные” регистры.
Например, это могут быть аргументы функции, в “обычных” архитектурах это понятие ближе всего соответствуют регистрам общего назначения. В отличие от “обычных” процессорных архитектур, в E2K регистры, используемые в функции, укладываются на отдельный стек.
Стек связующей информации (PCS) предназначен для размещения информации о предыдущей (вызвавшей) процедуре и используемой при возврате. Данные об адресе возврата, также как и в случае с регистрами, укладываются в отдельное место. Поэтому раскрутка стека (например, для выхода по исключению в C++) — более трудоемкий процесс чем в “обычных” архитектурах. С другой стороны, это исключает проблемы с переполнением стека.
Оба эти стека (PS и PCS) характеризуются базовым адресом, размером и текущим смещением. Эти параметры задаются в регистрах PSP и PCSP, они 128-битные и в ассемблере нужно обращаться к конкретным полям (например high или low). Кроме того, функционирование стеков тесно связано с понятием регистрового файла, об этом ниже. Взаимодействие с файлом происходит посредством механизма откачки/подкачки регистров. В этом механизме активную роль играет так называемый “аппаратный указатель на вершину стека” процедурного или стека связующей информации соответственно. Об этом также ниже. Важно, что в каждый момент времени данные этих стеков находятся либо в оперативной памяти, либо в регистровом файле.
Стоит также отметить, что эти стеки (процедурный стек и стек связывающей информации) растут вверх. Мы столкнулись с этим когда реализовывали context_switch.
Пользовательский стек тоже задается базовым адресом и размером. Текущий указатель находится в регистре USD.lo. По своей сути, это классический стек, который растет вниз. Только в отличие от “обычных” архитектур туда не укладывается информация из других стеков (регистры и адреса возвратов).
Одним нестандартным, на мой взгляд, требованием к границам и размерам стеков является выравнивание на 4Кб, причем на 4Кб должен быть выровнен как базовый адрес стека, так и его размер. В других архитектурах я такого ограничения не встречал. С этой деталью мы столкнулись, опять же, когда реализовывали context_switch.
Краткое введение: Регистры. Регистровые файлы. Окна регистров
Теперь, когда мы немного разобрались со стеками, надо понять, как же в них представлена информация. Для этого нам нужно ввести еще немного понятий.
Регистровый файл (RF) это набор всех регистров. Существует два регистровых файла, которые нам нужны: один файл связующей информации (chain file — CF), другой так и называется — регистровый файл (RF), в нем хранятся “оперативные” регистры, которые сохраняются на процедурном стеке.
Регистровым окном называется область (набор регистров) регистрового файла, доступная в данный момент.
Объясню подробнее. Что такое набор регистров, думаю, объяснять никому не нужно.
Общеизвестно, что одним из узких мест в архитектуре x86 является именно небольшое количество регистров. В RISC-архитектурах с регистрами попроще, обычно где-то 16 регистров, из них несколько (2-3) заняты под служебные нужды. Почему просто не сделать 128 регистров, ведь, казалось бы, это увеличит производительность системы? Ответ достаточно прост: в процессорной инструкции нужно место под хранение адреса регистра, а если их много, бит под это также нужно много. Поэтому идут на всякие ухищрения, делают теневые регистры, регистровые банки, окна и так далее. Под теневыми регистрами, я имею в виду принцип организации регистров в ARM. Если происходит прерывание или другая ситуация, то доступен другой набор регистров с теми же именами (номерами), при этом информация хранящаяся в оригинальном наборе, так и остается лежать там. Банки регистров, по сути дела, очень похожи на теневые регистры, просто нет аппаратного переключения наборов регистров и программист сам выбирает, к какому банку (набору регистров) сейчас обращаться.
Регистровые окна придуманы для оптимизации работы со стеком. Как вы наверное понимаете, в “обычной” архитектуре вы входите в процедуру, сохраняете регистры на стек (или вызывающая процедура сохраняет, зависит от договоренностей) и можете использовать регистры, ведь информация уже сохранена на стеке. Но обращение к памяти медленное, а следовательно его нужно избегать. Давайте при входе в процедуру просто сделаем доступным новый набор регистров, данные на старом сохранятся, и значит их не нужно скидывать в память. При этом когда вы вернетесь обратно в вызывающую процедуру, вернется и предыдущее регистровое окно, следовательно все данные на регистрах будут актуальны. Это и есть понятие регистрового окна.
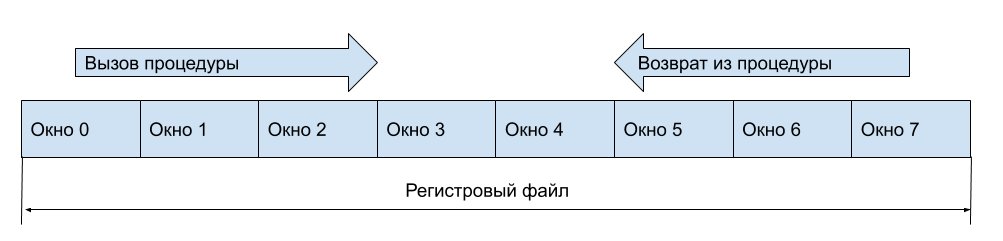
Понятно, что сохранять регистры на стеке (в памяти) все-таки нужно, но это можно сделать когда закончились свободные регистровые окна.
А что делать с входными и выходными регистрами (аргументы при входе в функцию и возвращаемый результат)? Давайте окно будет содержать часть регистров, видимых из предыдущего окна, точнее, часть регистров будет доступна для обоих окон. Тогда вообще при вызове функции не придется обращаться к памяти. Предположим, что наши регистры будут выглядеть так
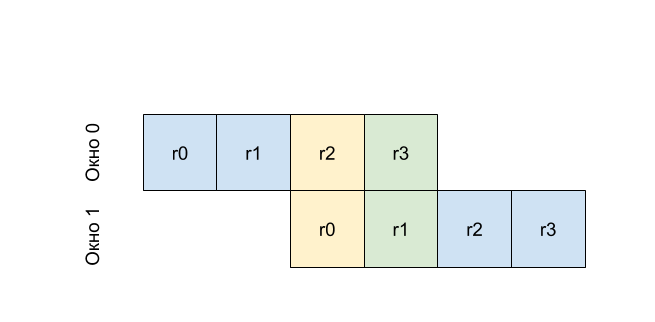
То есть r0 в первом окне будет тем же регистром что и r2 в нулевом, а r1 из первого окна тем же регистром, что и r3. То есть записав в r2 перед вызовом процедуры (изменением номера окна) мы получим значение в r0 в вызванной процедуре. Данный принцип называется механизмом вращающихся окон.
Давайте еще немного оптимизируем, ведь создатели Эльбруса так и сделали. Давайте окна у нас будут не фиксированного размера, а переменного, размер окна можно задать в момент входа в процедуру. Так же поступим с количеством вращаемых регистров. Это конечно приведет нас к некоторым проблемам, ведь если в классических вращаемых окнах, есть индекс окна, через который определяется, что нужно сохранить данные из регистрового файла на стек или загрузить их. Но если ввести не индекс окна, а индекс регистра, с которого начинается наше текущее окно, то этой проблемы не возникнет. В Эльбрусе эти индексы содержатся в регистрах PSHTP (для PS стека процедур) и PCSHTP (для PCS стека процедурной информации). В документации называются “аппаратными указателями на вершину стека”. Теперь можно еще раз попробовать перечитать про стеки, думаю будет более понятно.
Как вы понимаете, подобный механизм подразумевает, что у вас есть возможность управлять тем, что находится в памяти. То есть синхронизировать регистровый файл и стек. Я имею в виду системного программиста. Если вы прикладной программист, то аппаратура обеспечит прозрачный вход и выход из процедуры. То есть, если при попытке выделить новое окно не хватит регистров, то произойдет автоматическая “откачка” регистрового окна. При этом все данные из регистрового файла будут сохранены на соответствующий стек (в память), а “указатель на аппаратную вершину стека” (индекс смещения) будет сброшен в ноль. Аналогично подкачка регистрового файла из стека происходит автоматически. Но если вы разрабатываете, например, переключение контекста, чем собственно мы и занимались, то вам необходим механизм работы со скрытой частью регистрового файла. В Эльбрусе для этого используются команды FLUSHR и FLUSHC. FLUSHR — очистка регистрового файла, на процедурный стек сбрасываются все окна за исключением текущего, индекс PSHTP соответственно обнуляется. FLUSHC — очистка файла связующей информации, на стек связующей информации сбрасывается все за исключением текущего окна, индекс PCSHTP также сбрасывается в ноль.
Краткое введение: Реализация в Эльбрусе
Теперь когда обсудили неочевидную работу с регистрами и стеками поговорим более конкретно о различных ситуациях в Эльбрусе.
Когда мы заходим в очередную функцию, процессор создает два окна: окно в стеке PS и окно в стеке PCS.
Окно в стеке PCS содержит информацию, необходимую для возврата из функции: например, IP (Instruction Pointer) той инструкции, куда нужно будет вернуться из функции. С этим все более-менее понятно.
Окно в PS-стеке устроено несколько хитрее. Вводится понятие регистров текущего окна. В этом окне у вас появляется доступ к регистрам текущего окна — %dr0, %dr1, …, %dr15,… То есть для нас, как для пользователя они имеют нумерацию всегда от 0, но это нумерация относительно базового адреса текущего окна. Через эти регистры производится и передача аргументов при вызове функции, и возврат значения, и использование внутри функции как регистров общего назначения. Собственно это объяснялось при рассмотрении механизма вращающихся регистровых окон.
Размером регистрового окна в Эльбрусе можно управлять. Это, как я уже говорил, нужно для оптимизации. Например, нам в функции потребуется всего 4 регистра для передачи аргументов и каких-то вычислений, в этом случае программист (или компилятор) принимает решение, сколько нужно выделить регистров для функции, и исходя из этого задает размер окна. Размер окна задается операцией setwd:
setwd wsz=0x10Задает размер окна в терминах квадро-регистров (128-битные регистры).

А теперь, допустим, вы хотите вызвать функцию из функции. Для этого применяется уже описанное понятие вращаемого окна регистров. На картинке выше изображен фрагмент регистрового файла, где функция с окном 1 (зеленое) вызывает функцию с окном 2 (оранжевое). В каждой из этих двух функций у вас будут доступны свои %dr0, %dr1,… Но вот аргументы будут переданы через так называемые вращаемые регистры. Иначе говоря, часть регистров окна 1 станут регистрами окна 2 (обратите внимание на то, что эти два окна пересекаются). Эти регистры тоже задаются окном (см. Вращаемые регистры на картинке) и имеют адресацию %db[0], %db[1], … Таким образом, регистр %dr0 в окне 2 есть не что иное как регистр %db[0] в окне 1.
Окно вращаемых регистров задается операцией setbn:
setbn rbs = 0x3, rsz = 0x8rbs задает размер вращаемого окна, а rsz — базовый адрес, но относительно текущего регистрового окна. Т.е. Здесь мы выделили 3 регистра, начиная с 8го.
Исходя из вышесказанного, покажем, как выглядит вызов функции. Для простоты будем считать, что функция принимает один аргумент:
void my_func(uint64_t a) {
}Тогда для вызова этой функции нужно подготовить окно вращаемых регистров (мы уже сделали это через setbn). Далее, в регистр %db0 помещаем значение, которое будет передано в my_func. После это нужно вызвать инструкцию CALL и не забыть сказать ей, где начинается окно вращаемых регистров. Подготовку к вызову (команду disp) мы сейчас пропускаем, поскольку она не имеет отношения к регистрам. В итоге на ассемблере вызов этой функции должен выглядеть следующим образом:
addd 0, %dr9, %db[0]
disp %ctpr1, my_func
call %ctpr1, wbs = 0x8Так, с регистрами немного разобрались. Теперь посмотрим что касается стека связующей информации. В нем хранятся так называемые регистры CR-ы. По сути два — CR0, CR1. И в них уже содержится необходимая для возврата из функции информация.

Зеленым отмечены регистры CR0 и CR1 окна функции, которая вызвала функцию с регистрами, отмеченными оранжевым. Регистры CR0 содержат Instruction Pointer вызвавшей функции и некий файл предикатов (PF-Predicate File), рассказ о нем точно выходит за рамки данной статьи.
Регистры CR1 содержат такие данные как PSR (слово состояние процессора), номер окна, размеры окон и так далее. В Эльбрусе до такой степени все гибко, что каждая процедура сохраняет в CR1 информацию даже о том, включена ли в процедуре работа с плавающей точкой, и регистр, содержащий информацию о программных исключительных ситуациях, но за это, естественно, нужно платить сохранением дополнительной информации.
Очень важно не забывать, что регистровый файл и файл связующей информации могут откачиваться и подкачиваться из оперативной памяти и обратно (из стеков PS и PCS описанных выше). Этот момент важен при реализации setjmp описанном далее.
SETJMP / LONGJMP
И, наконец, хоть как-то поняв как устроены стеки и регистры в Эльбрусе, можно приступить к чему-то полезному, то есть добавить новый функционал в Embox.
В Embox система unit-тестирования требует setjmp/longjmp, поэтому нам пришлось реализовать эти функции.
Для реализации требуется сохранить/восстановить регистры: CR0, CR1, PSP, PCSP, USD, — уже знакомые нам из краткого введения. По сути сохранение/восстановление у нас реализуется в лоб, но есть существенный нюанс, на который часто намекалось в описании стеков и регистров, а именно: стеки должны быть синхронизированы, ведь они располагаются не только в памяти, но и в регистровом файле. Этот нюанс означает, что нужно позаботиться о нескольких особенностях, без которых ничего работать не будет.
Первая особенность заключается в отключении прерываний в моменты сохранения и восстановления. При восстановлении прерывания запрещать обязательно, иначе может возникнуть ситуация, при которой мы войдем в обработчик прерывания с наполовину переключенными стеками (имеется в виду откачка подкачка регистровых файлов описанных в “кратком описании”). А при сохранении проблема в том, что после входа и выхода из прерывания процессор может опять подкачать часть регистрового файла из оперативной памяти (а это испортит инвариантные условия PSHTP = 0 и PСSHTP = 0, о них чуть ниже). Собственно поэтому и в setjmp и в longjmp прерывания необходимо запрещать. Здесь нужно еще отметить, что специалисты из МЦСТ нам посоветовали вместо отключения прерываний использовать атомарные скобки, но пока мы используем самую простую (понятную нам) реализацию.
Вторая особенность связана с подкачкой/откачкой регистрового файла из памяти. Она заключается в следующем. Регистровый файл имеет ограниченный размер и следовательно довольно часто откачивается в память и обратно. Поэтому если мы просто сохраним значения регистров PSP и PSHTP, то мы зафиксируем значение текущего указателя в памяти и в регистровом файле. Но так как регистровый файл меняется, то в момент восстановления контекста он будет указывать на уже некорректные (не те, что мы “сохранили”) данные. Для того, чтобы этого избежать нужно, сделать flush всего регистрового файла в память. Таким образом, при сохранении в setjmp мы имеем PСSP.ind регистров в памяти и PСSHTP.ind регистров в регистровом окне. Получается, что нужно сохранить всего PСSP.ind + PСSHTP.ind регистров. Ниже приведена функция, которая выполняет эту операцию:
/* First arg is PCSP, 2nd arg is PCSHTP
* Returns new PCSP value with updated PCSP.ind
*/
.type update_pcsp_ind,@function
$update_pcsp_ind:
setwd wsz = 0x4, nfx = 0x0
/* Here and below, 10 is size of PCSHTP.ind. Here we
* extend the sign of PCSHTP.ind */
shld %dr1, (64 - 10), %dr1
shrd %dr1, (64 - 10), %dr1
/* Finally, PCSP.ind += PCSHTP.ind */
addd %dr1, %dr0, %dr0
E2K_ASM_RETURNНужно еще пояснить небольшой момент в этом коде, описанный в комментарии, а именно — нужно программно расширить знак в индексе PCSHTP.ind, ведь индекс может быть отрицательным и хранится в дополнительном коде. Для этого мы сдвигаем сначала на (64-10) влево (регистр 64 битный), на поле 10 бит, а потом обратно.
То же самое касается и PSP (стека процедур)
/* First arg is PSP, 2nd arg is PSHTP
* Returns new PSP value with updated PSP.ind
*/
.type update_psp_ind,@function
$update_psp_ind:
setwd wsz = 0x4, nfx = 0x0
/* Here and below, 12 is size of PSHTP.ind. Here we
* extend the sign of PSHTP.ind as stated in documentation */
shld %dr1, (64 - 12), %dr1
shrd %dr1, (64 - 12), %dr1
muld %dr1, 2, %dr1
/* Finally, PSP.ind += PSHTP.ind */
addd %dr1, %dr0, %dr0
E2K_ASM_RETURNС небольшой разницей (поле 12 бит, и регистры там отсчитываются в 128-битных терминах, то есть значение нужно умножить на 2).
Код самой setjmp
C_ENTRY(setjmp):
setwd wsz = 0x14, nfx = 0x0
/* It's for db[N] registers */
setbn rsz = 0x3, rbs = 0x10, rcur = 0x0
/* We must disable interrupts here */
disp %ctpr1, ipl_save
ipd 3
call %ctpr1, wbs = 0x10
/* Store current IPL to dr9 */
addd 0, %db[0], %dr9
/* Store some registers to jmp_buf */
rrd %cr0.hi, %dr1
rrd %cr1.lo, %dr2
rrd %cr1.hi, %dr3
rrd %usd.lo, %dr4
rrd %usd.hi, %dr5
/* Prepare RF stack to flush in longjmp */
rrd %psp.hi, %dr6
rrd %pshtp, %dr7
addd 0, %dr6, %db[0]
addd 0, %dr7, %db[1]
disp %ctpr1, update_psp_ind
ipd 3
call %ctpr1, wbs = 0x10
addd 0, %db[0], %dr6
/* Prepare CF stack to flush in longjmp */
rrd %pcsp.hi, %dr7
rrd %pcshtp, %dr8
addd 0, %dr7, %db[0]
addd 0, %dr8, %db[1]
disp %ctpr1, update_pcsp_ind
ipd 3
call %ctpr1, wbs = 0x10
addd 0, %db[0], %dr7
std %dr1, [%dr0 + E2K_JMBBUFF_CR0_HI]
std %dr2, [%dr0 + E2K_JMBBUFF_CR1_LO]
std %dr3, [%dr0 + E2K_JMBBUFF_CR1_HI]
std %dr4, [%dr0 + E2K_JMBBUFF_USD_LO]
std %dr5, [%dr0 + E2K_JMBBUFF_USD_HI]
std %dr6, [%dr0 + E2K_JMBBUFF_PSP_HI]
std %dr7, [%dr0 + E2K_JMBBUFF_PCSP_HI]
/* Enable interrupts */
addd 0, %dr9, %db[0]
disp %ctpr1, ipl_restore
ipd 3
call %ctpr1, wbs = 0x10
/* return 0 */
adds 0, 0, %r0
E2K_ASM_RETURNПри реализации longjmp важно не забывать про синхронизацию обоих регистровых файлов, следовательно нужно сделать flush не только регистрового окна (flushr), но и flush файла связующей информации (flushc). Опишем макрос:
#define E2K_ASM_FLUSH_CPU \
flushr; \
nop 2; \
flushc; \
nop 3;Теперь, когда вся информация находится в памяти, мы можем безопасно сделать восстановление регистров в longjmp.
C_ENTRY(longjmp):
setwd wsz = 0x14, nfx = 0x0
setbn rsz = 0x3, rbs = 0x10, rcur = 0x0
/* We must disable interrupts here */
disp %ctpr1, ipl_save
ipd 3
call %ctpr1, wbs = 0x10
/* Store current IPL to dr9 */
addd 0, %db[0], %dr9
/* We have to flush both RF and CF to memory because saved values
* of P[C]SHTP can be not valid here. */
E2K_ASM_FLUSH_CPU
/* Load registers previously saved in setjmp. */
ldd [%dr0 + E2K_JMBBUFF_CR0_HI], %dr2
ldd [%dr0 + E2K_JMBBUFF_CR1_LO], %dr3
ldd [%dr0 + E2K_JMBBUFF_CR1_HI], %dr4
ldd [%dr0 + E2K_JMBBUFF_USD_LO], %dr5
ldd [%dr0 + E2K_JMBBUFF_USD_HI], %dr6
ldd [%dr0 + E2K_JMBBUFF_PSP_HI], %dr7
ldd [%dr0 + E2K_JMBBUFF_PCSP_HI], %dr8
rwd %dr2, %cr0.hi
rwd %dr3, %cr1.lo
rwd %dr4, %cr1.hi
rwd %dr5, %usd.lo
rwd %dr6, %usd.hi
rwd %dr7, %psp.hi
rwd %dr8, %pcsp.hi
/* Enable interrupts */
addd 0, %dr9, %db[0]
disp %ctpr1, ipl_restore
ipd 3
call %ctpr1, wbs = 0x10
/* Actually, we return to setjmp caller with second
* argument of longjmp stored on r1 register. */
adds 0, %r1, %r0
E2K_ASM_RETURNПереключение контекста потоков (context switch)
После того, как мы разобрались с setjmp/longjmp, базовая реализация context_switch показалась нам достаточно понятной. Ведь как и в первом случае, нам требуется сохранить/восстановить регистры связующей информации и стеки, плюс нужно правильно восстановить регистр состояния процессора (UPSR).
Поясню. Как и в случае с setjmp, при сохранении регистров, сначала необходимо сбросить регистровый файл и файл связующей информации в память (flushr + flushc). После этого нам необходимо сохранить текущие значения регистров CR0 и CR1 для того, чтобы при возврате прыгнуть именно туда, откуда текущий поток переключили. Далее сохраняем дескрипторы стеков PS, PCS и US. И последнее, необходимо позаботиться о правильном восстановлении режима прерываний — для этих целей сохраняем еще и регистр UPSR.
Ассемблерный код context_switch:
C_ENTRY(context_switch):
setwd wsz = 0x10, nfx = 0x0
/* Save prev UPSR */
rrd %upsr, %dr2
std %dr2, [%dr0 + E2K_CTX_UPSR]
/* Disable interrupts before saving/restoring context */
rrd %upsr, %dr2
andnd %dr2, (UPSR_IE | UPSR_NMIE), %dr2
rwd %dr2, %upsr
E2K_ASM_FLUSH_CPU
/* Save prev CRs */
rrd %cr0.lo, %dr2
rrd %cr0.hi, %dr3
rrd %cr1.lo, %dr4
rrd %cr1.hi, %dr5
std %dr2, [%dr0 + E2K_CTX_CR0_LO]
std %dr3, [%dr0 + E2K_CTX_CR0_HI]
std %dr4, [%dr0 + E2K_CTX_CR1_LO]
std %dr5, [%dr0 + E2K_CTX_CR1_HI]
/* Save prev stacks */
rrd %usd.lo, %dr3
rrd %usd.hi, %dr4
rrd %psp.lo, %dr5
rrd %psp.hi, %dr6
rrd %pcsp.lo, %dr7
rrd %pcsp.hi, %dr8
std %dr3, [%dr0 + E2K_CTX_USD_LO]
std %dr4, [%dr0 + E2K_CTX_USD_HI]
std %dr5, [%dr0 + E2K_CTX_PSP_LO]
std %dr6, [%dr0 + E2K_CTX_PSP_HI]
std %dr7, [%dr0 + E2K_CTX_PCSP_LO]
std %dr8, [%dr0 + E2K_CTX_PCSP_HI]
/* Load next CRs */
ldd [%dr1 + E2K_CTX_CR0_LO], %dr2
ldd [%dr1 + E2K_CTX_CR0_HI], %dr3
ldd [%dr1 + E2K_CTX_CR1_LO], %dr4
ldd [%dr1 + E2K_CTX_CR1_HI], %dr5
rwd %dr2, %cr0.lo
rwd %dr3, %cr0.hi
rwd %dr4, %cr1.lo
rwd %dr5, %cr1.hi
/* Load next stacks */
ldd [%dr1 + E2K_CTX_USD_LO], %dr3
ldd [%dr1 + E2K_CTX_USD_HI], %dr4
ldd [%dr1 + E2K_CTX_PSP_LO], %dr5
ldd [%dr1 + E2K_CTX_PSP_HI], %dr6
ldd [%dr1 + E2K_CTX_PCSP_LO], %dr7
ldd [%dr1 + E2K_CTX_PCSP_HI], %dr8
rwd %dr3, %usd.lo
rwd %dr4, %usd.hi
rwd %dr5, %psp.lo
rwd %dr6, %psp.hi
rwd %dr7, %pcsp.lo
rwd %dr8, %pcsp.hi
/* Restore next UPSR */
ldd [%dr1 + E2K_CTX_UPSR], %dr2
rwd %dr2, %upsr
E2K_ASM_RETURNЕще одним важным моментом является первичная инициализация потока ОС. В Embox каждый поток имеет некую первичную процедуру
void _NORETURN thread_trampoline(void);в которой будет исполняться вся дальнейшая работа потока. Таким образом, нам нужно как-то подготовить стеки для вызова этой функции, именно здесь мы столкнулись с тем, что есть три стека, и растут они не в одну и ту же сторону. По архитектуре у нас поток создается с единым стеком, точнее, место под стек оно единое, наверху у нас лежит структура, описывающая сам поток и так далее, здесь же пришлось позаботиться о разных стеках, не забыть про то, что они должны быть выровнены по 4 кБ, не забыть всякие права доступа и так далее.
В итоге, на данный момент мы решили, что разделим пространство под стек на три части, четверть под стек связующей информации, четверть под процедурный стек и половина под пользовательский стек.
Привожу код для того чтобы можно было оценить, насколько он большой, нужно учитывать что это минимальная инициализация.
/* This value is used for both stack base and size align. */
#define E2K_STACK_ALIGN (1UL << 12)
#define round_down(x, bound) ((x) & ~((bound) - 1))
/* Reserve 1/4 for PSP stack, 1/4 for PCSP stack, and 1/2 for USD stack */
#define PSP_CALC_STACK_BASE(sp, size) binalign_bound(sp - size, E2K_STACK_ALIGN)
#define PSP_CALC_STACK_SIZE(sp, size) binalign_bound((size) / 4, E2K_STACK_ALIGN)
#define PCSP_CALC_STACK_BASE(sp, size) \
(PSP_CALC_STACK_BASE(sp, size) + PSP_CALC_STACK_SIZE(sp, size))
#define PCSP_CALC_STACK_SIZE(sp, size) binalign_bound((size) / 4, E2K_STACK_ALIGN)
#define USD_CALC_STACK_BASE(sp, size) round_down(sp, E2K_STACK_ALIGN)
#define USD_CALC_STACK_SIZE(sp, size) \
round_down(USD_CALC_STACK_BASE(sp, size) - PCSP_CALC_STACK_BASE(sp, size),\
E2K_STACK_ALIGN)
static void e2k_calculate_stacks(struct context *ctx, uint64_t sp,
uint64_t size) {
uint64_t psp_size, pcsp_size, usd_size;
log_debug("Stacks:\n");
ctx->psp_lo |= PSP_CALC_STACK_BASE(sp, size) << PSP_BASE;
ctx->psp_lo |= E2_RWAR_RW_ENABLE << PSP_RW;
psp_size = PSP_CALC_STACK_SIZE(sp, size);
assert(psp_size);
ctx->psp_hi |= psp_size << PSP_SIZE;
log_debug(" PSP.base=0x%lx, PSP.size=0x%lx\n",
PSP_CALC_STACK_BASE(sp, size), psp_size);
ctx->pcsp_lo |= PCSP_CALC_STACK_BASE(sp, size) << PCSP_BASE;
ctx->pcsp_lo |= E2_RWAR_RW_ENABLE << PCSP_RW;
pcsp_size = PCSP_CALC_STACK_SIZE(sp, size);
assert(pcsp_size);
ctx->pcsp_hi |= pcsp_size << PCSP_SIZE;
log_debug(" PCSP.base=0x%lx, PCSP.size=0x%lx\n",
PCSP_CALC_STACK_BASE(sp, size), pcsp_size);
ctx->usd_lo |= USD_CALC_STACK_BASE(sp, size) << USD_BASE;
usd_size = USD_CALC_STACK_SIZE(sp, size);
assert(usd_size);
ctx->usd_hi |= usd_size << USD_SIZE;
log_debug(" USD.base=0x%lx, USD.size=0x%lx\n",
USD_CALC_STACK_BASE(sp, size), usd_size);
}
static void e2k_calculate_crs(struct context *ctx, uint64_t routine_addr) {
uint64_t usd_size = (ctx->usd_hi >> USD_SIZE) & USD_SIZE_MASK;
/* Reserve space in hardware stacks for @routine_addr */
/* Remark: We do not update psp.hi to reserve space for arguments,
* since routine do not accepts any arguments. */
ctx->pcsp_hi |= SZ_OF_CR0_CR1 << PCSP_IND;
ctx->cr0_hi |= (routine_addr >> CR0_IP) << CR0_IP;
ctx->cr1_lo |= PSR_ALL_IRQ_ENABLED << CR1_PSR;
/* Divide on 16 because it field contains size in terms
* of 128 bit values. */
ctx->cr1_hi |= (usd_size >> 4) << CR1_USSZ;
}
void context_init(struct context *ctx, unsigned int flags,
void (*routine_fn)(void), void *sp, unsigned int stack_size) {
memset(ctx, 0, sizeof(*ctx));
e2k_calculate_stacks(ctx, sp, stack_size);
e2k_calculate_crs(ctx, (uint64_t) routine_fn);
if (!(flags & CONTEXT_IRQDISABLE)) {
ctx->upsr |= (UPSR_IE | UPSR_NMIE);
}
}Статья содержала в себе еще и работу с прерываниями, исключениями и таймерами, но поскольку и так получилась большая, мы решили об этом рассказать в следующей части.
На всякий случай повторюсь, данный материал не является официальной документацией! Для получения официальной поддержки, документации и остального, нужно обращаться напрямую в МЦСТ. Код в Embox, ественно, является открытым, но для того, чтобы его собрать, понадобится кросс-компилятор, который, опять, же можно получить у МЦСТ.
