

На сегодняшний день ЦЕРН является одним из крупнейших пользователей Kubernetes в мире. Согласно недавней статистике, в этой европейской организации, стоящей за Большим адронным коллайдером (БАК) и рядом других известных научно-исследовательских проектов, запущено 210 кластеров K8s, обслуживающих одновременное выполнение сотен тысяч задач. Эта история успеха — о них.
Контейнеры в ЦЕРН: начало
Для тех, кто хотя бы поверхностно знаком с деятельностью ЦЕРН, не секрет, что в этой организации немало внимания уделяется актуальным информационным технологиям: достаточно вспомнить, что это место рождения World Wide Web, а среди более свежих заслуг можно вспомнить грид-системы (включая LHC Computing Grid), специализированную интегральную схему, дистрибутив Scientific Linux и даже свою лицензию на open hardware. Как правило, эти проекты, будь они программными или аппаратными, связаны с главным детищем ЦЕРНа — БАК. Это касается и ИТ-инфраструктуры ЦЕРН, во многом обслуживающей его же потребности.

В дата-центре ЦЕРНа в Женеве
Самые ранние публично доступные сведения о практическом применении контейнеров в инфраструктуре организации, что удалось найти, датируются апрелем 2016 года. В рамках «внутреннего» доклада «Containers and Orchestration in the CERN Cloud» сотрудники ЦЕРНа рассказывали, как они используют OpenStack Magnum (компонент OpenStack для работы с движками оркестровки контейнеров) для обеспечения поддержки контейнеров в своейм облаке (CERN Cloud) и их оркестровки. Уже тогда упоминая Kubernetes, инженеры преследовали цель быть независимыми от выбранного инструмента оркестровки, поддерживая и другие опции: Docker Swarm и Mesos.
Примечание: Само облако с OpenStack было введено в production-инфраструктуру ЦЕРН за несколько лет до этого, в 2013 году. По состоянию на февраль 2017 года, в этом облаке было доступно 188 тысяч ядер, 440 Тб RAM, создано 4 миллиона виртуальных машин (из них — 22 тысячи были активны).
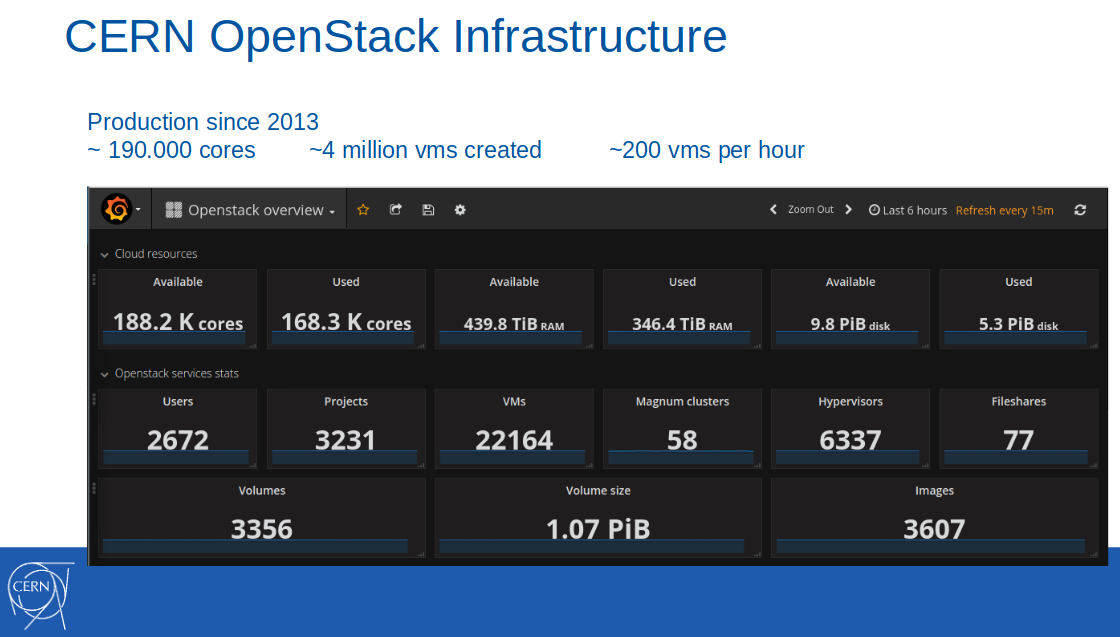
На тот момент времени поддержка контейнеров в формате Containers-as-a-Service позиционировалась как пилотный сервис и использовалась в десяти ИТ-проектах организации. Среди сценариев применения называлась непрерывная интеграция с GitLab CI для сборки и выката приложений в Docker-контейнерах.
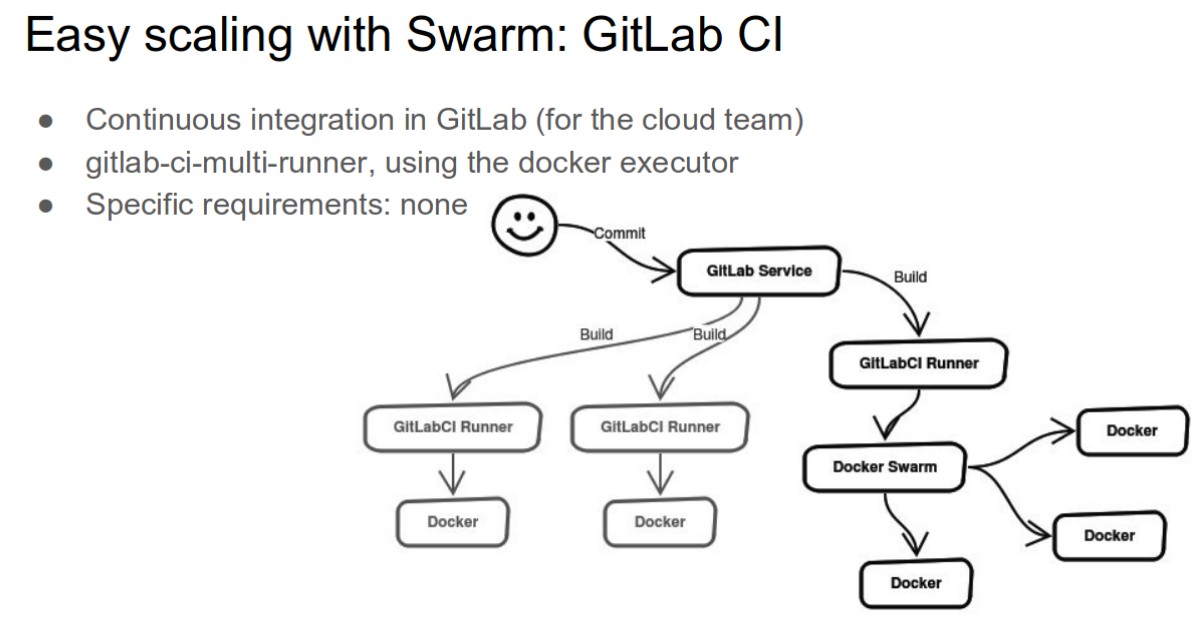
Из презентации к докладу в ЦЕРН от 8 апреля 2016 г.
Запуск этого сервиса в production ожидался к третьему кварталу 2016 г.
Примечание: Стоит отдельно отметить, что сотрудники ЦЕРНа неизменно помещают свои наработки в upstream используемых Open Source-проектов, в т.ч. и многочисленных компонентов OpenStack, какими в данном случае являлись Magnum, puppet-magnum, Rally и т.п.
Миллионы запросов в секунду с Kubernetes
По состоянию на июнь того же (2016) года сервис в ЦЕРНе всё ещё имел статус pre-production:
«Мы постепенно движемся к полноценному режиму production, чтобы включить Containers-as-a-Service в стандартный набор ИТ-услуг, доступных в ЦЕРНе».
И тогда, вдохновившись публикацией в блоге Kubernetes об обслуживании 1 миллиона HTTP-запросов в секунду без простоя во время обновления сервиса в K8s, инженеры научной организации решили повторить этот успех в своём кластере на OpenStack Magnum, Kubernetes 1.2 и аппаратной базе из 800 ядер CPU.
Причём простым повторением эксперимента они решили не ограничиваться и с успехом довели количество запросов до 2 миллионов в секунду, попутно подготовив несколько патчей для всё того же OpenStack Magnum и проделав тесты с разным количеством узлов в кластере (300, 500 и 1000).
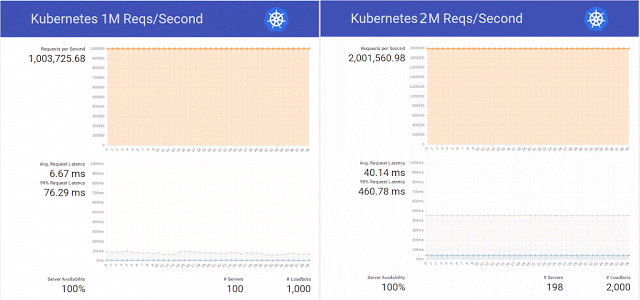
Подводя итоги этого тестирования, инженеры вновь отмечали, что «есть ещё Swarm и Mesos, и мы планируем в скором времени провести тесты и на них». Дошло ли дело до этих тестов, интернет-пространству неизвестно, зато к концу того же года эксперимент с Kubernetes получил продолжение — уже с 10 миллионами запросов в секунду. Результат оказался достаточно положительным, но был ограничен успешной отметкой в чуть более 7 миллионов — из-за сетевой проблемы, не имеющей отношения к OpenStack.
Инженеры, специализирующиеся на OpenStack Heat и Magnum, заодно измерили, что масштабирование кластера с 1 до 1000 узлов занимало 23 минуты, оценив это как хороший результат (см. также выступление «Toward 10,000 Containers on OpenStack» на OpenStack Summit Barcelona 2016).
Контейнеры в ЦЕРН: переход в production
В феврале следующего (2017) года, контейнеры в ЦЕРНе уже достаточно широко применялись для решения задач из разных областей: пакетной обработки данных, машинного обучения, управления инфраструктурой, непрерывного деплоя… Об этом стало известно из доклада «OpenStack Magnum at CERN. Scaling container clusters to thousands of nodes» (видео) на FOSDEM 2017:

В нём же сообщалось, что использование Magnum в ЦЕРНе перешло в стадию production в октябре 2016 года, а также снова подчёркивалась поддержка трёх инструментов для оркестровки: Kubernetes, Docker Swarm и Mesos. Почему это было так важно, пояснил на одном из своих выступлений (OpenStack Summit в Бостоне, май 2017 г.) Ricardo Rocha из ИТ-подразделения ЦЕРНа:
«Magnum также позволяет выбирать движок для контейнеров, что было очень ценным для нас. В организации работали группы людей, которые ратовали за Kubernetes, но были и те, кто уже использовал Mesos, а некоторые и вовсе работали с обычным Docker, желая и дальше полагаться на Docker API, и здесь большой потенциал у Swarm. Мы хотели добиться простоты использования, не требовать от людей понимания сложных шаблонов для настройки своих кластеров».
На тот момент в ЦЕРНе использовали около 40 кластеров с Kubernetes, 20 — с Docker Swarm и 5 — с Mesosphere DC/OS.
Уже через год, к маю 2018 года, ситуация в значительной мере изменилась. Из выступления «CERN Experiences with Multi-Cloud Federated Kubernetes» (видео) того же Ricardo и его коллеги (Clenimar Filemon) на KubeCon Europe 2018 стали известны новые подробности об использовании Kubernetes. Теперь это не просто один из инструментов оркестровки контейнеров, доступных пользователям научной организации, но и важная для всей инфраструктуры технология, позволяющая — благодаря федерации — значительно расширить вычислительное облако, добавив сторонние ресурсы (GKE, AKS, Amazon, Oracle…) к собственным мощностям.
Примечание: Федерация в Kubernetes — специальный механизм, упрощающий управление множеством кластеров за счёт синхронизации находящихся в них ресурсов и автоматического обнаружения сервисов во всех кластерах. Актуальный случай её применения — работа со множеством Kubernetes-кластеров, распределённых по разным провайдерам (свои дата-центры, сторонние облачные сервисы).
Как видно из этого слайда, демонстрирующего некоторые количественные характеристики дата-центра ЦЕРН в Женеве…

… внутренняя инфраструктура организации сильно выросла. Например, количество доступных ядер за год выросло почти в два раза — уже до 320 тысяч. Инженеры пошли дальше и объединили несколько своих дата-центров, добившись доступности 700 тысяч ядер в облаке ЦЕРН, которые заняты параллельным выполнением 400 тысяч задач (по реконструкции событий, калибровке детекторов, симуляции, анализу данных и т.п.)…
Но в контексте этой статьи больший интерес представляет тот факт, что в ЦЕРНе функционировали уже 210 кластеров Kubernetes, размеры которых сильно варьировались (от 10 до 1000 узлов).
Федерация с Kubernetes
Однако внутренних мощностей ЦЕРНа не всегда хватало — например, на периоды резких всплесков нагрузки: перед большими международными конференциями по физике и в случае крупных кампаний по реконструкции проводимых экспериментов. Заметным use case, требующим больших ресурсов, стала система пакетной обработки ЦЕРН (CERN Batch Service), на которую приходится около 80 % от всей нагрузки на вычислительные ресурсы организации.
В основе этой системы — фреймворк с открытым кодом HTCondor, предназначенный для решения задач категории HTC (high-throughput computing). За вычисления в нём отвечает демон StartD, который стартует на каждом узле и отвечает за запуск рабочей нагрузки на нём. Именно он и был контейнеризирован в ЦЕРНе с целью запуска на Kubernetes и дальнейшей федерации.
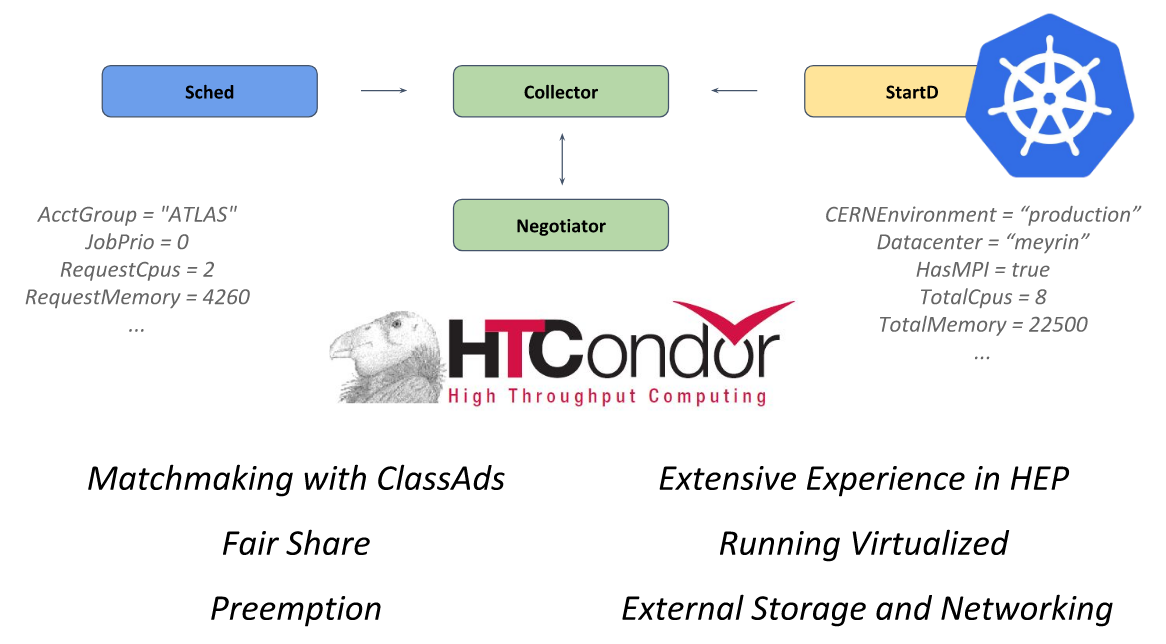
Устройство HTCondor из презентации ЦЕРНа на KubeCon Europe 2018
Пойдя этим путём, инженеры ЦЕРНа смогли описывать единственный ресурс (
DaemonSet с контейнером, где запускается StartD из HTCondor) и деплоить его на узлах всех кластеров Kubernetes, объединённых федерацией: сначала в рамках своего дата-центра, а затем — подключая внешних провайдеров (публичное облако от T-Systems и других компаний):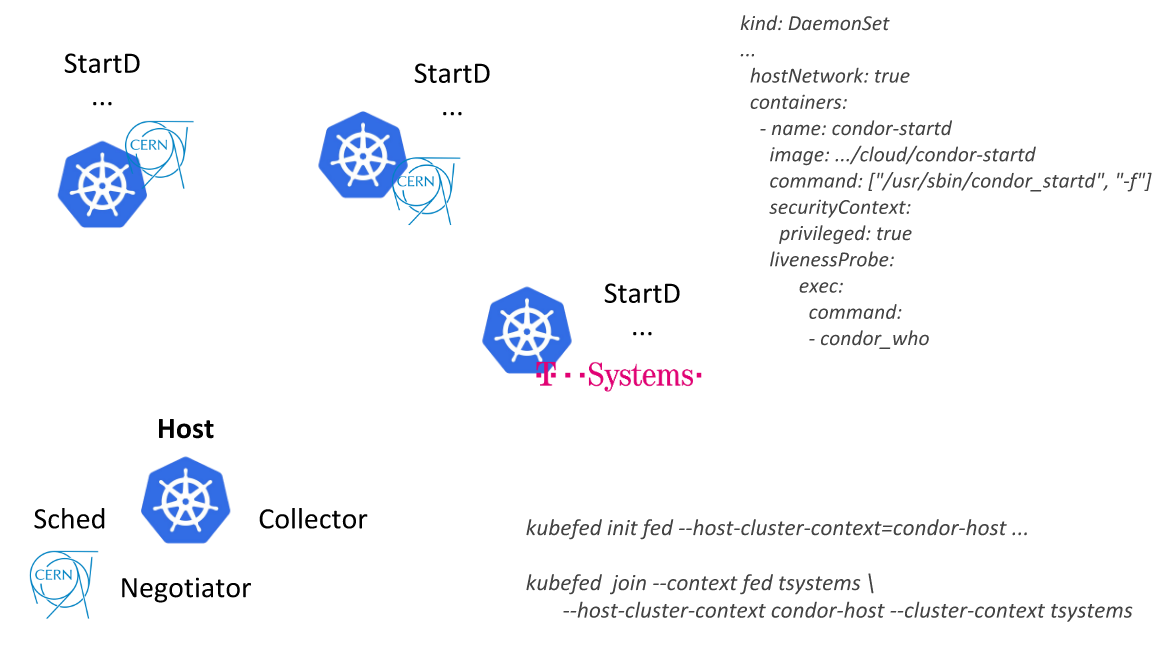
Другой пример применения — аналитическая платформа на базе REANA, RECAST и Yadage. В отличие от CERN Batch Service, являющейся «устоявшимся» программным обеспечением в организации, это новая разработка, в которой сразу учитывалась специфика применения вместе с Kubernetes. Рабочие процессы в этой системе реализованы таким образом, что каждый этап преобразуется в
Job для Kubernetes.Если изначально все эти задачи запускались на единственном кластере, то со временем запросы росли и «на сегодняшний день это наш лучший use case федерации в Kubernetes». Небольшое видео с его демонстрацией смотрите в этом фрагменте выступления Ricardo Rocha.
P.S.
Дополнительные сведения об актуальных масштабах применения ИТ в ЦЕРНе можно получить на сайте организации.
Другие статьи из цикла
- «Истории успеха Kubernetes в production. Часть 1: 4200 подов и TessMaster у eBay».
- «Истории успеха Kubernetes в production. Часть 2: Concur и SAP».
- «Истории успеха Kubernetes в production. Часть 3: GitHub».
- «Истории успеха Kubernetes в production. Часть 4: SoundCloud (авторы Prometheus)».
- «Истории успеха Kubernetes в production. Часть 5: цифровой банк Monzo».
- «Истории успеха Kubernetes в production. Часть 6: BlaBlaCar».
- «Истории успеха Kubernetes в production. Часть 7: BlackRock».
- «Истории успеха Kubernetes в production. Часть 8: Huawei».
- «Истории успеха Kubernetes в production. Часть 10: Reddit».
