
Вслед за shell-operator мы представляем его старшего брата — addon-operator. Это Open Source-проект, который используется для установки в кластер Kubernetes системных компонентов, которые можно назвать общим словом — дополнения.
Зачем вообще какие-то дополнения?
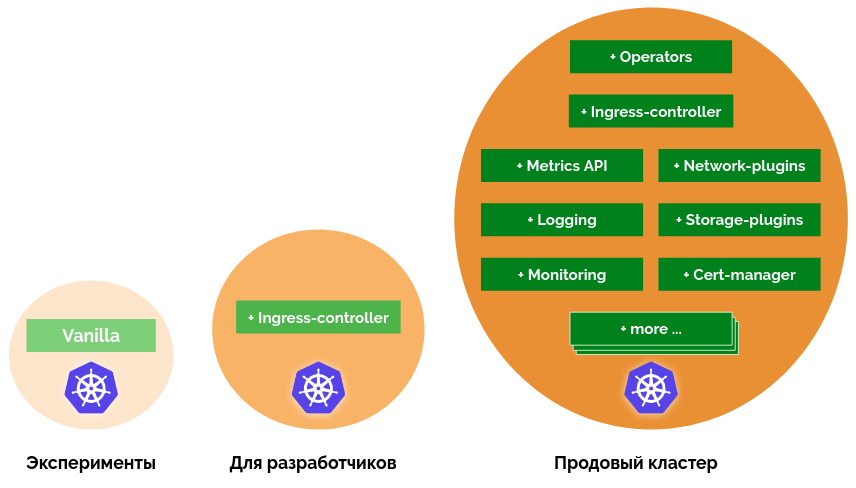
Не секрет, что Kubernetes это не готовый продукт всё-в-одном, и для построения «взрослого» кластера понадобятся различные дополнения. Addon-operator поможет установить, настроить и поддерживать эти дополнения в актуальном состоянии.
Необходимость дополнительных компонентов в кластере раскрыта в докладе коллеги driusha. Вкратце, ситуация с Kubernetes на данный момент такова, что для простой установки «поиграться» можно обойтись компонентами из коробки, для разработчиков и тестирования можно добавить Ingress, а вот для полноценной установки, о которой можно сказать «ваш production готов», необходимо добавить с десяток различных дополнений: что-то для мониторинга, что-то для логов, не забыть ingress и cert-manager, выделить группы узлов, добавить сетевые политики, приправить настройками sysctl и pod autoscaler’ом…
В чем специфика работы с ними?
Как показывает практика, одной установкой дело не ограничивается. Для комфортной работы с кластером дополнения нужно будет обновлять, отключать (удалять из кластера), а что-то захочется протестировать перед установкой в production-кластер.
Так, может, тут и Ansible хватит? Возможно. Но полноценные дополнения в общем случае не живут без настроек. Эти настройки могут отличаться в зависимости от варианта кластера (aws, gce, azure, bare-metal, do, ...). Некоторые настройки нельзя задать заранее — их нужно получать из кластера. А кластер не статичен: для некоторых настроек придётся следить за изменениями. И тут уже Ansible не хватает: нужна программа, которая живёт в кластере, т.е. Kubernetes Operator.
Те, кто попробовал в работе shell-operator, скажут, что задачи установки и обновления дополнений и слежения за настройками вполне можно решить с помощью хуков для shell-operator. Можно написать скрипт, который будет делать условный
kubectl apply и следить, например, за ConfigMap, где будут храниться настройки. Примерно это и реализовано в addon-operator.Как это организовано в addon-operator?
Создавая новое решение, мы исходили из следующих принципов:
- Установщик дополнений должен поддерживать шаблонизацию и декларативную конфигурацию. Не делаем магических скриптов, которые устанавливают дополнения. Addon-operator использует Helm для установки дополнений. Для установки нужно создать чарт и выделить values, которые будут использованы для настройки.
- Настройки можно генерировать при установке, их можно получить из кластера, либо получать обновления, следя за ресурсами кластера. Эти операции можно реализовать с помощью хуков.
- Настройки можно хранить в кластере. Для хранения настроек в кластере создаётся ConfigMap/addon-operator и Addon-operator следит за изменениями этого ConfigMap. Addon-operator даёт хукам доступ к настройкам с помощью простых соглашений.
- Дополнение зависит от настроек. Если настройки изменились, то Addon-operator выкатывает Helm-чарт с новыми values. Объединение Helm-чарта, values для него и хуков мы назвали модулем (подробнее см. ниже).
- Стейджирование. Нет магических релиз-скриптов. Механизм обновлений аналогичен обычному приложению — собрать дополнения и addon-operator в образ, протегировать и выкатить.
- Контроль результата. Addon-operator умеет отдавать метрики для Prometheus.
Что такое дополнение в addon-operator?
Дополнением можно считать всё, что добавляет в кластер новые функции. Например, установка Ingress — отличный пример дополнения. Это может быть любой оператор или контроллер со своим CRD: prometheus-operator, cert-manager, kube-controller-manager, и т.д. Или что-то небольшое, но упрощающее эксплуатацию — например, secret copier, копирующий registry-секреты в новые пространства имён, или sysctl tuner, настраивающий параметры sysctl на новых узлах.
Для реализации дополнений Addon-operator предоставляет несколько концепций:
- Helm-чарт используется, чтобы устанавливать в кластер различное ПО — например, Prometheus, Grafana, nginx-ingress. Если у нужного компонента есть Helm-чарт, то установить его с помощью Addon-operator будет очень просто.
- Хранилище values. У Helm-чартов обычно есть много разных настроек, которые могут меняться со временем. Addon-operator поддерживает хранение этих настроек и умеет следить за их изменениями, чтобы переустановить Helm-чарт с новыми значениями.
- Хуки — это исполняемые файлы, которые Addon-operator запускает по событиям и которые получают доступ к хранилищу values. Хук может следить за изменениями в кластере и обновлять значения в хранилище values. Т.е. с помощью хуков можно сделать discovery, чтобы собирать значения из кластера при старте или по расписанию, а можно и continuous discovery, собирая значения из кластера по изменениям в кластере.
- Модуль — это объединение Helm-чарта, хранилища values и хуков. Модули можно включать и отключать. Отключение модуля — это удаление всех релизов Helm-чарта. Модули могут включать сами себя динамически, например, если включены все необходимые ему модули или если discovery в хуках нашёл нужные параметры — это делается с помощью вспомогательного enabled-скрипта.
- Глобальные хуки. Это хуки «сами по себе», они не включены в модули и имеют доступ к глобальному хранилищу values, значения из которого доступно всем хукам в модулях.
Как эти части работают вместе? Рассмотрим картинку из документации:

Сценария работы два:
- Глобальный хук запускается по событию — например, при изменении ресурса в кластере. Этот хук обрабатывает изменения и записывает новые значения в глобальное хранилище values. Addon-operator замечает, что глобальное хранилище изменилось и запускает все модули. Каждый модуль с помощью своих хуков определяет, нужно ли ему включаться, и обновляет своё хранилище values. Если модуль включен, то Addon-operator запускает установку Helm-чарта. Helm-чарту при этом доступны values из хранилища модуля и из глобального хранилища.
- Второй сценарий проще: модульный хук запускается по событию, изменяет значения в хранилище values модуля. Addon-operator это замечает и запускает Helm-чарт с обновлёнными values.
Дополнение может быть реализовано виде одного единственного хука или как один Helm-чарт, или даже как несколько зависимых модулей — это зависит от сложности устанавливаемого в кластер компонента и от нужного уровня гибкости настроек. Например, в репозитории (/examples) есть дополнение sysctl-tuner, которое реализовано как в виде простого модуля с хуком и Helm-чартом, так и с использованием хранилища values, что даёт возможность добавлять настройки через редактирование ConfigMap.
Доставка обновлений
Несколько слов про организацию обновлений компонентов, которые устанавливает Addon-operator.
Чтобы запустить Addon-operator в кластере, нужно собрать образ с дополнениями в виде файлов хуков и Helm-чартов, добавить бинарный файл
addon-operator и всё, что понадобится для хуков: bash, kubectl, jq, python и т.д. Дальше этот образ можно выкатывать в кластер как обычное приложение и скорее всего вы захотите организовать ту или иную схему тегирования. Если кластеров немного, может подойти тот же подход, что и с приложениями: новый релиз, новая версия, пойти по всем кластерам и поправить image у Pod’ов. Однако, в случае выката на ощутимое количество кластеров, нам больше подошла концепция самообновления из канала. У нас это устроено так:
- Канал — это по сути идентификатор, который можно задавать любым (например, dev/stage/ea/stable).
- Имя канала — это тег образа. Когда нужно выкатить обновления в канал, то собирается новый образ и тегируется именем канала.
- Когда в registry появляется новый образ, Addon-operator рестартуется и запускается с новым образом.
Это не best practice, о чем написано в документации Kubernetes. Так делать не рекомендуется, но речь идёт про обычное приложение, которое живёт в одном кластере. В случае Addon-operator приложение — это множество Deployments, разбросанных по кластерам, и самообновление очень сильно помогает и упрощает жизнь.
Каналы помогают и в тестировании: если есть вспомогательный кластер, можно настроить его на канал
stage и катать обновления в него перед выкатом в каналы ea и stable. Если c кластером на канале ea произошла ошибка, можно его переключить на stable, пока идёт расследование проблемы с этим кластером. Если кластер выведен из активной поддержки, он переключается на свой «застывший» канал — например, freeze-2019-03-20.Помимо обновлений хуков и Helm-чартов может понадобиться обновить и сторонний компонент. Например, вы заметили ошибку в условном node-exporter и даже придумали, как его пропатчить. Далее открыли PR и ждёте нового релиза, чтобы пройтись по всем кластерам и увеличить версию образа. Чтобы не ждать неопределённое время, можно собрать свой node-exporter и переключиться на него до принятия PR.
В общем-то, это можно и без Addon-operator сделать, но с Addon-operator модуль для установки node-exporter будет на виду в одном репозитории, Dockerfile для сборки своего образа можно держать тут же, всем участникам процесса становится проще понимать, что происходит… А если кластеров несколько, то становится проще как тестировать свой PR, так и накатывать новую версию!
Эта организация обновления компонентов работает успешно у нас, но можно реализовать и любую другую подходящую схему — ведь в данном случае Addon-operator является простым бинарным файлом.
Заключение
Принципы, реализованные в Addon-operator, позволяют выстроить прозрачный процесс создания, тестирования, установки и обновления дополнений в кластере, аналогичный процессам разработки обычных приложений.
Дополнения для Addon-operator в формате модулей (Helm-чарт + хуки) можно выкладывать в широкий доступ. Мы, компания Флант, планируем выложить в течение лета наши наработки в виде таких дополнений. Присоединяйтесь к разработке на GitHub (shell-operator, addon-operator), пробуйте сделать своё дополнение на основе примеров и документации, ждите новостей на Хабре и на нашем канале в YouTube!
ОБНОВЛЕНО (14 июня): Если у вас есть англоязычные коллеги, которые могут заинтересоваться addon-operator'ом, то соответствующий анонс для них доступен в нашем блоге на Medium.
P.S.
Читайте также в нашем блоге:
