
В разработке hh.ru сегодня около 150 человек. У нас множество интересных команд, и каждая вносит значительный вклад. Но в этой статье я расскажу лишь про одну из них.

Потому что я ее тимлид И на это есть несколько причин:
Поэтому я постараюсь на понятных примерах разобрать, в чем в действительности заключается наша работа.
Начнем с самого общего, то есть с приоритетов, их два:
Из этих приоритетов и следуют основные направления нашей работы:
hh.ru — это 5-6к rps от пользователей, в пике доходящие до 10к, которые вырастают на порядок, доходя до бэкендов. Это более 1500 инстансов, крутящих около 150 сервисов в 3 ДЦ. Так что да, в первую очередь, это те самые развесистые схемы с квадратиками, банками и стрелочками: кто куда ходит, где что должно находиться. Схемы мы, конечно, не рисуем — потребности закрываем автоматикой, логированием и мониторингом, но наших школьников мы пугали, например, такими штуками:
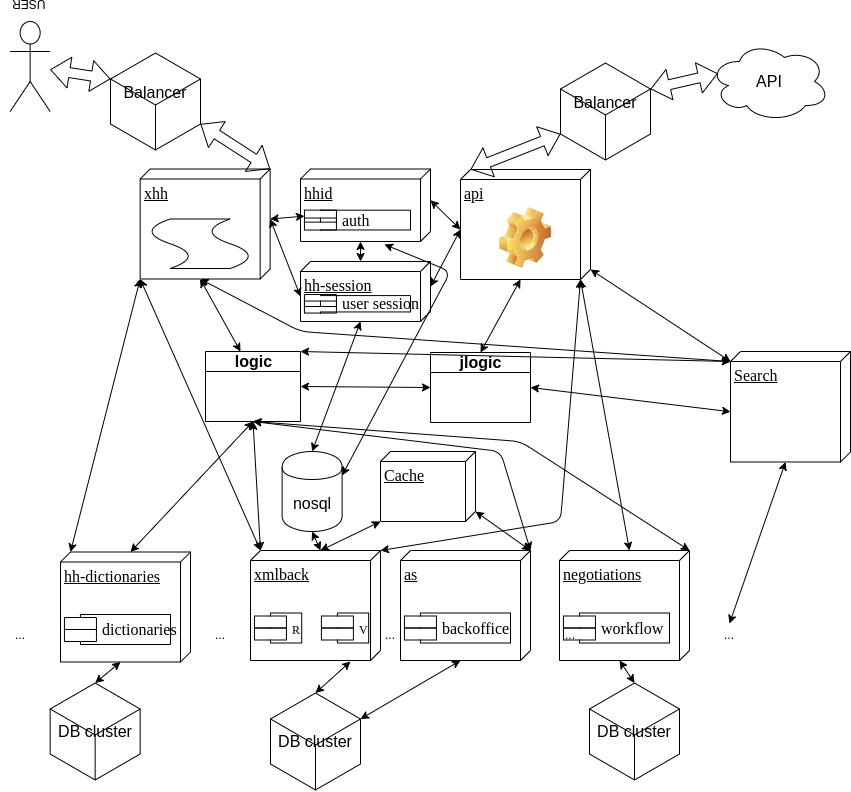
Мы действительно отвечаем за то, чтобы находить и устранять в архитектуре узкие места и негибкие решения и развивать ее согласно потребностям.
Приведу пример:
hh.ru работает уже далеко не первый год, и когда-то казалось хорошей идеей иметь отдельную машинку для выполнения фоновых задач по расписанию — на нее можно выделить побольше ресурсов и на ней не будет гонок. Но что мы имеем в итоге:
Когда мы это поняли, то убедились, что у нас есть все средства для перевода кроновых задач на общие инстансы, и завели большую задачу в категории техдолга — теперь, когда приходит время отдавать долги, коллеги постепенно устраняют эту проблему.
1. Стандартизация
В первую очередь это наши фреймворки и инструменты для быстрой разработки сервисов: nuts-and-bolts и frontik. Да и вообще jclient и многие другие библиотеки, открытые у нас на гитхабе появились из идеи, что опыт эксплуатации различных технологий имеет смысл агрегировать. Это позволяет культивировать те ограничения, паттерны дизайна и поведения, которые мы отработали в бою, и считаем наиболее подходящими, понятными и надежными.
Помимо таких очевидных примеров стандартизации бывают и те, в которых имеет смысл обобщить частные решения.
Например, в какой-то момент у нас стала периодически возникать необходимость гарантированно (at least once) отправлять сообщения в rabbitmq. Задачи раз за разом решались самописными очередями на базе, и раз за разом dba говорили, как СИЛЬНО любят очереди на базе, особенно нагруженные. В конце концов стало очевидно, что тут необходимо стандартное решение, которое было бы приемлемо для dba, обеспечивало бы надежность доставки и было удобным для разработки — так мы написали свою библиотеку для интеграции pgq и rabbitmq. Сейчас есть большая вероятность, что будем использовать pgq так же в связке с kafka.
Баги тоже бывают глобальными. Например, в какой-то момент мы выяснили, что наш python-фреймворк регистрируется в consul в каждом процессе-воркере, да еще и делает это раньше, чем приложение готово принимать запросы. После фикса во фреймворке, изменения постепенно доедут до всех сервисов по мере обновления.
Еще об одном общем баге, связанном с настройками jvm я рассказывал на demo stage jpoint 2019.
Иногда удается придумать стандартные решения еще до того, как это станет серьезной проблемой. В качестве примеров тут можно привести задачу о процессинге логов, о которой рассказывал наш Влад Сенин на том же jpoint 2019, или задачу управления таймаутами в нашем http-клиенте.
Смысл ее в том, что разумный таймаут полезно определять не на стороне клиента, а на стороне сервера. Для сервера у нас есть данные по тому, как быстро он отвечает по своим endpoint-ам. Сейчас наш клиент поддерживает один таймаут для сервиса. Но очевидно, что не все endpoint-ы сервиса отвечают одинаково — какие-то дольше, какие-то быстрее. Хочется иметь возможность использовать разные таймауты. Иначе, возникает ситуация, похожая на эту:
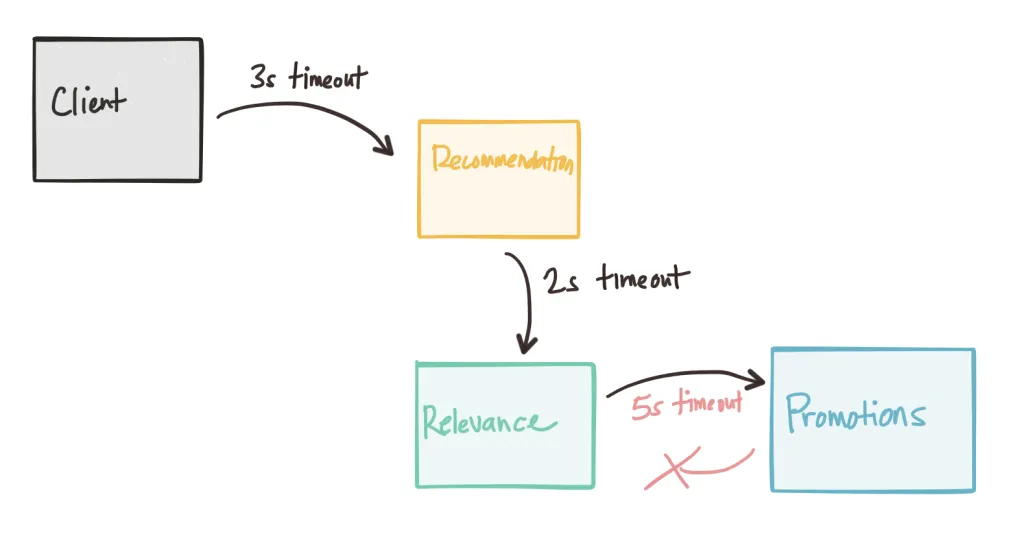
Пока такие ситуации проявляются только под нагрузочным тестированием, но решить их хочется до того, как это станет проблемой.
Но не все проблемы объясняются какими-то бажными местами и сложными ручными процессами. Далее, я приведу несколько примеров вопросов, которые тоже попадают в поле наших приоритетов, но при этом являются куда менее детерминированными. Поэтому я опишу только исходные данные, а варианты решения при желании можем обсудить в комментариях.
Итак, первый пример: сейчас становится понятно, что есть проблема интеграции наших сервисов между собой. Интеграция, скажем, сайтовой ручки в API может занять больше времени, чем изначальная ее разработка.
Другой, наверняка знакомый многим, пример подобной проблемы — распиливание монолита. Все понимают, что монолит, обросший большим количеством легаси, усложняет разработку и эксплуатацию. Но кто может сказать насколько? Стоит ли жертвовать другими задачами техдолга в пользу распиливания, каждый кусочек которого по отдельности несет исчезающе малую ценность?
Масштаб этих и им подобных проблем таков, что для их решения иногда приходится выходить далеко за технические рамки и погружаться в совершенно новые области рабочего процесса. Это с одной стороны пугает, но с другой дает невероятную свободу в выборе решений.
Рассказ о направлениях нашей работы будет неполным без описания того, КАК мы со всем этим работаем.
Начну с того, что привлекло в работе в “Архитектуре” меня самого и что нас всех мотивирует: мы действительно работаем на качество.
И прежде чем в меня полетят камни, я попробую объяснить, что имею в виду. Я верю, что ни один разработчик сознательно не забивает на качество. Дело в техдолге: если мы говорим об участке бизнес-логики, который не планируется переиспользовать, то скорее всего количество долга от не самого идеального решения со временем будет расти медленно, если вообще будет.
Это позволяет немного охладить свой перфекционизм — завести задачу на долг и добраться в следующей итерации. А вот если мы говорим о фреймворке или глобальном инструменте подготовки конфигурации, который используется в сотне приложений и закрепляет определенные паттерны дизайна или именования, то скорость роста долга от его неудачного решения может перекрыть любые выигрыши вообще. Понятно, что есть ситуации, когда даже лучшее решение по мере использования вскрывает недостатки, но такое случается не часто…
Ближе к завершению я бы хотел поговорить о препятствиях, которые всё же возникают у нас на пути. Без этого рассказ о нашей работе был бы нечестным. Итак.
Выше я уже говорил, что мы можем оценить полезный эффект не для всех задач. Насколько уменьшится время выпуска задач, когда для какой-то функции выйдет “коробочное” решение? Какой из двух проблемных участков кода надо рефакторить в первую очередь? Для выработки адекватной системы оценки задач мы встречались пару раз в неделю на протяжении нескольких месяцев, но это тема для отдельного поста.
Согласовать что-то на 150 человек — задача не из легких. Наша очень децентрализованная оргструктура чаще всего проявляет себя своими лучшими сторонами, но для “Архитектуры” порой это серьезная преграда. Очень мало соглашений до которых удается договориться, еще меньше тех, соблюдение которых потом удается отслеживать.
А еще все изменения надо катить плавно. Сервис может месяцами не обновляться, а еще есть монолит… Ну, довольно о грустном.
Надеюсь, после моего рассказа слегка прояснилось, чем занимается “Архитектура” в hh.ru. А уж если мне удалось пробудить в вас интерес к нашей работе — это вообще фантастика. Тем более, что как раз сейчас в нашу команду открыта вакансия. Мы будем очень рады свежим идеям, которые помогут нам в достижении наших скрытых от праздных взглядов, но таких важных побед.
з.ы. оригинал КДПВ это, оказывается, иллюстрация вот этого человека. Надеюсь, он не против использования своих изображений в качестве КДПВ

- зачастую кандидаты не понимают, чем мы занимаемся;
- иногда этого не знают даже сотрудники внутри компании, ведь у нашей команды нет продакт-менеджера, своей зоны бизнес-функционала и списка поддерживаемых нами сервисов...;
- наши заслуги чаще всего остаются в тени;
- в конце концов, “хочешь в чем-то разобраться — попробуй это кому-нибудь объяснить” :)
Поэтому я постараюсь на понятных примерах разобрать, в чем в действительности заключается наша работа.
Начнем с самого общего, то есть с приоритетов, их два:
- системное обеспечение надежности и отказоустойчивости нашей платформы. Тут стоит обратить внимание на слово “системное” — оно говорит о том, что мы не фиксим конкретные дефекты производительности, а вырабатываем общие правила и паттерны, закрепляем их во фреймворках, автоматических проверках и пр. так, чтобы это работало для всех.
- фокус разработки на бизнес-логике. То есть, чем меньше разработчик задумывается о поддержке надежности, архитектуры и т.п. — тем лучше. Понятно, что совсем избавлять коллег от таких мыслей скорее даже вредно, но поддерживать разумный баланс смысл есть.
Из этих приоритетов и следуют основные направления нашей работы:
0. Поддержка и развитие архитектуры
hh.ru — это 5-6к rps от пользователей, в пике доходящие до 10к, которые вырастают на порядок, доходя до бэкендов. Это более 1500 инстансов, крутящих около 150 сервисов в 3 ДЦ. Так что да, в первую очередь, это те самые развесистые схемы с квадратиками, банками и стрелочками: кто куда ходит, где что должно находиться. Схемы мы, конечно, не рисуем — потребности закрываем автоматикой, логированием и мониторингом, но наших школьников мы пугали, например, такими штуками:

Мы действительно отвечаем за то, чтобы находить и устранять в архитектуре узкие места и негибкие решения и развивать ее согласно потребностям.
Приведу пример:
hh.ru работает уже далеко не первый год, и когда-то казалось хорошей идеей иметь отдельную машинку для выполнения фоновых задач по расписанию — на нее можно выделить побольше ресурсов и на ней не будет гонок. Но что мы имеем в итоге:
- точку отказа для всех задач
- уникальную конфигурацию, воспроизводимую только в проде
- задачи, логика которых рассчитана на выделенный запуск на отдельной жирной машине и не масштабируется горизонтально
Когда мы это поняли, то убедились, что у нас есть все средства для перевода кроновых задач на общие инстансы, и завели большую задачу в категории техдолга — теперь, когда приходит время отдавать долги, коллеги постепенно устраняют эту проблему.
1. Стандартизация костылей
В первую очередь это наши фреймворки и инструменты для быстрой разработки сервисов: nuts-and-bolts и frontik. Да и вообще jclient и многие другие библиотеки, открытые у нас на гитхабе появились из идеи, что опыт эксплуатации различных технологий имеет смысл агрегировать. Это позволяет культивировать те ограничения, паттерны дизайна и поведения, которые мы отработали в бою, и считаем наиболее подходящими, понятными и надежными.
Помимо таких очевидных примеров стандартизации бывают и те, в которых имеет смысл обобщить частные решения.
Например, в какой-то момент у нас стала периодически возникать необходимость гарантированно (at least once) отправлять сообщения в rabbitmq. Задачи раз за разом решались самописными очередями на базе, и раз за разом dba говорили, как СИЛЬНО любят очереди на базе, особенно нагруженные. В конце концов стало очевидно, что тут необходимо стандартное решение, которое было бы приемлемо для dba, обеспечивало бы надежность доставки и было удобным для разработки — так мы написали свою библиотеку для интеграции pgq и rabbitmq. Сейчас есть большая вероятность, что будем использовать pgq так же в связке с kafka.
1.0. Баги
Баги тоже бывают глобальными. Например, в какой-то момент мы выяснили, что наш python-фреймворк регистрируется в consul в каждом процессе-воркере, да еще и делает это раньше, чем приложение готово принимать запросы. После фикса во фреймворке, изменения постепенно доедут до всех сервисов по мере обновления.
Еще об одном общем баге, связанном с настройками jvm я рассказывал на demo stage jpoint 2019.
А что, например, делать с багом, который воспроизводится раз в неделю на одном из инстансов, лечится рестартом, но ни нагрузочное, ни синтетика его не воспроизводят?
Суть бага заключается в том, что периодически инстансы java-сервисов дедлочились. Судя по треддампу это был код nuts-and-bolts:
но позже очередной дедлок показал стек в недрах спринга:
а затем и вовсе в недрах jackson:
По графикам использования памяти каждый раз перед дедлоком было видно увеличение Code Cache:

Поиск багов java результатов не дал. Однако поднятие версии java, похоже, как-то исправляет проблему. Локализовать ее не удалось, поэтому от дальнейшего исследования мы отказались.
"qtp1778300121-22" #22 prio=5 os_prio=0 cpu=797.67ms elapsed=11737.06s tid=0x00007f5890139000 nid=0x26 waiting for monitor entry [0x00007f58922c7000]
java.lang.Thread.State: BLOCKED (on object monitor)
at ch.qos.logback.core.AppenderBase.doAppend(AppenderBase.java:63)
- waiting to lock <0x00000000e86acad0> (a ru.hh.nab.logging.HhSyslogAppender)
at ru.hh.nab.logging.HhMultiAppender.doAppend(HhMultiAppender.java:47)
at ru.hh.nab.logging.HhMultiAppender.doAppend(HhMultiAppender.java:21)
at ch.qos.logback.core.spi.AppenderAttachableImpl.appendLoopOnAppenders(AppenderAttachableImpl.java:51)но позже очередной дедлок показал стек в недрах спринга:
"qtp1778300121-22" #22 prio=5 os_prio=0 cpu=5718.81ms elapsed=7767.14s tid=0x00007f1537dba000 nid=0x24 waiting for monitor entry [0x00007f153d2b9000]
java.lang.Thread.State: BLOCKED (on object monitor)
at java.util.concurrent.ConcurrentHashMap.computeIfAbsent(java.base@11.0.4/ConcurrentHashMap.java:1723)
- waiting to lock <0x00000000e976a668> (a java.util.concurrent.ConcurrentHashMap$Node)
at org.springframework.beans.factory.BeanFactoryUtils.transformedBeanName(BeanFactoryUtils.java:86)а затем и вовсе в недрах jackson:
"qtp1778300121-23" #23 prio=5 os_prio=0 cpu=494.19ms elapsed=7234.32s tid=0x00007f6c01218800 nid=0x25 waiting for monitor entry [0x00007f6c07cfa000]
java.lang.Thread.State: BLOCKED (on object monitor)
at org.glassfish.jersey.jackson.internal.jackson.jaxrs.base.ProviderBase._endpointForWriting(ProviderBase.java:711)
- waiting to lock <0x00000000e9f94c38> (a org.glassfish.jersey.jackson.internal.jackson.jaxrs.util.LRUMap)
at org.glassfish.jersey.jackson.internal.jackson.jaxrs.base.ProviderBase.writeTo(ProviderBase.java:588)По графикам использования памяти каждый раз перед дедлоком было видно увеличение Code Cache:

Поиск багов java результатов не дал. Однако поднятие версии java, похоже, как-то исправляет проблему. Локализовать ее не удалось, поэтому от дальнейшего исследования мы отказались.
1.1. Общие решения
Иногда удается придумать стандартные решения еще до того, как это станет серьезной проблемой. В качестве примеров тут можно привести задачу о процессинге логов, о которой рассказывал наш Влад Сенин на том же jpoint 2019, или задачу управления таймаутами в нашем http-клиенте.
Смысл ее в том, что разумный таймаут полезно определять не на стороне клиента, а на стороне сервера. Для сервера у нас есть данные по тому, как быстро он отвечает по своим endpoint-ам. Сейчас наш клиент поддерживает один таймаут для сервиса. Но очевидно, что не все endpoint-ы сервиса отвечают одинаково — какие-то дольше, какие-то быстрее. Хочется иметь возможность использовать разные таймауты. Иначе, возникает ситуация, похожая на эту:

Пока такие ситуации проявляются только под нагрузочным тестированием, но решить их хочется до того, как это станет проблемой.
1.2. Открытые проблемы
Но не все проблемы объясняются какими-то бажными местами и сложными ручными процессами. Далее, я приведу несколько примеров вопросов, которые тоже попадают в поле наших приоритетов, но при этом являются куда менее детерминированными. Поэтому я опишу только исходные данные, а варианты решения при желании можем обсудить в комментариях.
Итак, первый пример: сейчас становится понятно, что есть проблема интеграции наших сервисов между собой. Интеграция, скажем, сайтовой ручки в API может занять больше времени, чем изначальная ее разработка.
Другой, наверняка знакомый многим, пример подобной проблемы — распиливание монолита. Все понимают, что монолит, обросший большим количеством легаси, усложняет разработку и эксплуатацию. Но кто может сказать насколько? Стоит ли жертвовать другими задачами техдолга в пользу распиливания, каждый кусочек которого по отдельности несет исчезающе малую ценность?
Масштаб этих и им подобных проблем таков, что для их решения иногда приходится выходить далеко за технические рамки и погружаться в совершенно новые области рабочего процесса. Это с одной стороны пугает, но с другой дает невероятную свободу в выборе решений.
2. Как мы работаем
Рассказ о направлениях нашей работы будет неполным без описания того, КАК мы со всем этим работаем.
Начну с того, что привлекло в работе в “Архитектуре” меня самого и что нас всех мотивирует: мы действительно работаем на качество.
И прежде чем в меня полетят камни, я попробую объяснить, что имею в виду. Я верю, что ни один разработчик сознательно не забивает на качество. Дело в техдолге: если мы говорим об участке бизнес-логики, который не планируется переиспользовать, то скорее всего количество долга от не самого идеального решения со временем будет расти медленно, если вообще будет.
Это позволяет немного охладить свой перфекционизм — завести задачу на долг и добраться в следующей итерации. А вот если мы говорим о фреймворке или глобальном инструменте подготовки конфигурации, который используется в сотне приложений и закрепляет определенные паттерны дизайна или именования, то скорость роста долга от его неудачного решения может перекрыть любые выигрыши вообще. Понятно, что есть ситуации, когда даже лучшее решение по мере использования вскрывает недостатки, но такое случается не часто…
Ближе к завершению я бы хотел поговорить о препятствиях, которые всё же возникают у нас на пути. Без этого рассказ о нашей работе был бы нечестным. Итак.
2.0. Сложность оценки задач
Выше я уже говорил, что мы можем оценить полезный эффект не для всех задач. Насколько уменьшится время выпуска задач, когда для какой-то функции выйдет “коробочное” решение? Какой из двух проблемных участков кода надо рефакторить в первую очередь? Для выработки адекватной системы оценки задач мы встречались пару раз в неделю на протяжении нескольких месяцев, но это тема для отдельного поста.
2.1. Коллективное бессознательное
Согласовать что-то на 150 человек — задача не из легких. Наша очень децентрализованная оргструктура чаще всего проявляет себя своими лучшими сторонами, но для “Архитектуры” порой это серьезная преграда. Очень мало соглашений до которых удается договориться, еще меньше тех, соблюдение которых потом удается отслеживать.
А еще все изменения надо катить плавно. Сервис может месяцами не обновляться, а еще есть монолит… Ну, довольно о грустном.
Вот и поговорили
Надеюсь, после моего рассказа слегка прояснилось, чем занимается “Архитектура” в hh.ru. А уж если мне удалось пробудить в вас интерес к нашей работе — это вообще фантастика. Тем более, что как раз сейчас в нашу команду открыта вакансия. Мы будем очень рады свежим идеям, которые помогут нам в достижении наших скрытых от праздных взглядов, но таких важных побед.
з.ы. оригинал КДПВ это, оказывается, иллюстрация вот этого человека. Надеюсь, он не против использования своих изображений в качестве КДПВ
