Недавно мы рассказывали о том, как попасть на стажировку в Google. Помимо Google наши студенты пробуют свои силы в JetBrains, Яндекс, Acronis и других компаниях.
В этой статье я поделюсь своим опытом прохождения стажировки в JetBrains Research, расскажу о задачах, которые там решают, и подробнее остановлюсь на том, как при помощи машинного обучения можно искать баги в программном коде.

Меня зовут Егор Богомолов, я студент 4-го курса бакалавриата Питерской Вышки по направлению “Прикладная математика и информатика”. Первые 3 года я, как и мои однокурсники, учился в Академическом Университете, а с этого сентября мы всей кафедрой переместились в Высшую школу экономики.
После 2-го курса я ездил на летнюю стажировку в Google Zurich. Там я в течение трех месяцев работал в команде Android Calendar, большую часть времени занимаясь frontend’ом и немного UX-research. Самой интересной частью моей работы было исследование, как могут выглядеть интерфейсы календаря в будущем. Приятным оказалось то, что почти вся проделанная мной работа к концу стажировки попала в основную версию приложения. Но тема стажировок в Google очень хорошо освещена в предыдущем посте, поэтому я расскажу о том, чем занимался этим летом.
JetBrains Research представляет из себя набор лабораторий, работающих в разных областях: языках программирования, прикладной математике, машинном обучении, робототехнике и других. Внутри каждого направления есть несколько научных групп. Я, в силу своего направления, лучше всего знаком с деятельностью групп в сфере машинного обучения. В каждой из них проходят еженедельные семинары, на которых члены группы или приглашенные гости рассказывают о своей работе или интересных статьях в их области. На эти семинары приходит много студентов из Вышки, благо проходят они через дорогу от основного корпуса Питерского кампуса ВШЭ.
На нашей бакалаврской программе мы обязательно занимаемся научно-исследовательской работой (НИР) и два раза в год презентуем результаты исследований. Часто эта работа плавно перерастает в летние стажировки. Это произошло и с моей научно-исследовательской работой: летом этого года я проходил стажировку в лаборатории “Методы машинного обучения в программной инженерии” у своего научного руководителя Тимофея Брыксина. В задачи, над которыми работают в этой лаборатории, входят автоматическое предложение рефакторингов, анализ стиля кода программистов, автодополнение кода, поиск ошибок в программном коде.
Моя стажировка длилась два месяца (июль и август), а осенью я продолжил заниматься поставленными задачами в рамках НИРа. Я работал в нескольких направлениях, самым интересным из них, на мой взгляд, был автоматический поиск багов в коде, про него я и хочу рассказать. Отправной точкой стала статья Майкла Прадела.
Зачем искать баги более-менее понятно. Давайте разберемся, как это делают сейчас. Современные баг-детекторы в основном базируются на статическом анализе кода. Для каждого вида ошибок ищут заранее замеченные паттерны, по которым его можно определить. Затем, чтобы уменьшить количество ложных срабатываний, добавляются эвристики, придуманные для каждого отдельного случая. Паттерны можно искать как в абстрактном синтаксическом дереве (AST), построенном по коду, так и в графах потока управления или данных.
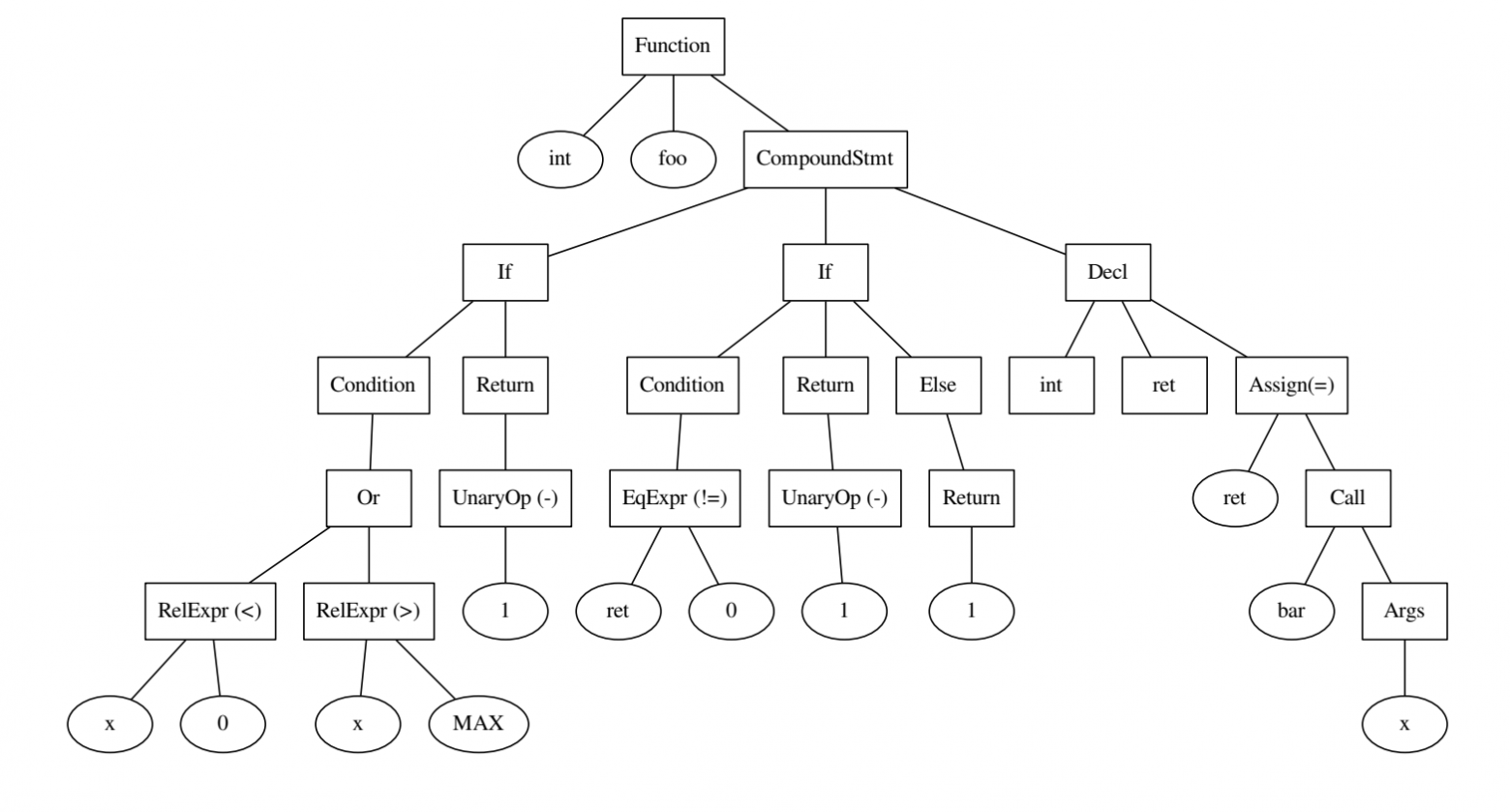
Код и дерево, которое по нему построили.
Чтобы понять, как это работает, рассмотрим пример. Видом багов может быть использование = вместо == в C++. Посмотрим на следующий кусочек кода:
В нем в условном выражении допущена ошибка, при этом первое = в присвоении значения переменной правильное. Отсюда возникает паттерн: если присвоение используется внутри условия в if, это потенциальный баг. Ища такой паттерн в AST, мы сможем обнаружить ошибку и исправить ее.
В более общем случае у нас уже не получится так легко найти способ описать ошибку. Допустим, что мы хотим определять правильность порядка операндов. Опять посмотрим на фрагменты кода:
В первом случае использование 1-i было ошибочным, а во втором вполне корректным, что понятно из контекста. Но как описать это в виде паттерна? С усложнением вида ошибок приходится рассматривать все больший участок кода и разбирать все больше отдельных случаев.
Последний мотивирующий пример: полезная информация содержится еще и в именах методов и переменных. Ее еще сложнее выразить какими-то вручную заданными условиями.
Человеку понятно, что, скорее всего, аргументы в вызове функции перепутаны, ведь у нас есть понимание того, что x больше похоже на xDim, чем на yDim. Но как сообщить об этом детектору? Можно добавлять какие-то эвристики вида “имя переменной это префикс имени аргумента”, но, допустим, то, что x чаще является шириной, чем высотой, так уже не выразить.
Итого: проблемой современного подхода к поиску ошибок является то, что очень много работы приходится проделывать руками: определять паттерны, добавлять эвристики, из-за этого добавление поддержки нового типа ошибок в детектор становится трудоемким. Помимо этого сложно использовать важную часть информации, которую в коде оставил разработчик: имена переменных и методов.
Как вы могли заметить, во многих примерах ошибки видны человеку, но их тяжело описать формально. В таких ситуациях часто могут помочь методы машинного обучения. Давайте остановимся на поиске переставленных аргументов в вызове функции и поймем, что нам нужно, чтобы их искать при помощи машинного обучения:
Мы можем надеяться, что в большей части кода, выложенного в открытый доступ, аргументы в вызовах функций стоят в правильном порядке. Поэтому для примеров кода без багов можно взять какой-нибудь большой датасет. В случае автора оригинальной статьи это был JS 150K (150 тысяч файлов на Javascript), в нашем случае — аналогичный датасет для Python.
Найти код с багами гораздо сложнее. Но мы можем не искать чьи-то ошибки, а делать их самостоятельно! Для типа ошибок нужно задать функцию, которая по корректному куску кода будет делать испорченный. В нашем случае — переставлять аргументы в вызове функции.
Вооруженные большим количеством хорошего и плохого кода мы почти готовы кого-нибудь чему-нибудь учить. До этого нам еще нужно ответить на вопрос: а как представлять фрагменты кода?
Вызов функции можно представить как кортеж из названия метода, названия того, чей это метод, имен и типов аргументов, передаваемых переменных. Если мы научимся векторизовать отдельные токены (имена переменных и методов, все “слова”, встречающиеся в коде), то сможем взять конкатенацию векторов интересных нам токенов и получить желаемый вектор для фрагмента.
Чтобы векторизовать токены посмотрим на то, как векторизуют слова в обычных текстах. Одним из наиболее успешных и популярных способов является предложенный в 2013 году word2vec.
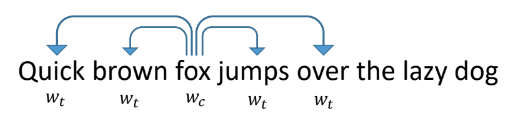
Работает он следующим образом: мы учим сеть предсказывать по слову другие слова, которые встречаются рядом с ним в текстах. Сеть при этом выглядит как входной слой размером равный словарю, скрытый слой размера векторизации, которую мы хотим получить, и выходной слой, тоже размера словаря. В ходе обучения сети подаются на вход вектора с одной единицей на месте рассматриваемого слова (fox), а на выходе мы хотим получать слова, которые встречаются в рамках окна вокруг этого слова (quick, brown, jumps, over). При этом сеть сперва переводит все слова в вектор на скрытом слое, а потом делает предсказание.
Получающиеся в результате векторы для отдельных слов обладают хорошими свойствами. Например, вектора слов с похожим значением близки друг к другу, а сумма и разность векторов являются сложением и разностью “смыслов” слов.
Чтобы сделать аналогичную векторизацию токенов в коде, нужно как-то задать окружение, которое будет предсказываться. Им может выступать информация из AST: типы вершин вокруг, встречающиеся токены, позиция в дереве.
Получив векторизацию можно посмотреть, какие токены похожи друг на друга. Для этого посчитаем косинусное расстояние между ними. В итоге для Javascript получаются следующие соседние вектора (число — косинусное расстояние):
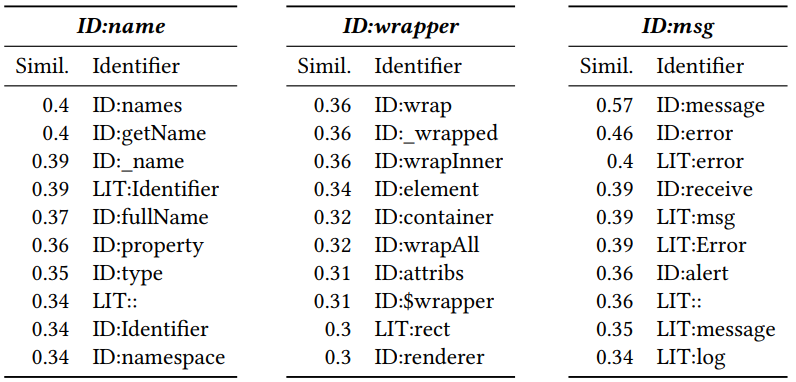
ID и LIT дописанные в начале обозначают, является ли токен идентификатором (имя переменной, метода) или литералом (константа). Видно, что близость является осмысленной.
Получив векторизацию для отдельных токенов, получить представление для куска кода с потенциальной ошибкой достаточно просто: это конкатенация векторов важных для классификации токенов. По кускам кода обучается двухслойный перцептрон с ReLU в качестве функции активации и dropout для уменьшения переобучения. Обучение сходится быстро, полученная модель имеет маленький размер и может делать предсказания для сотен примеров в секунду. Это позволяет использовать ее в режиме реального времени, о чем будет сказано дальше.
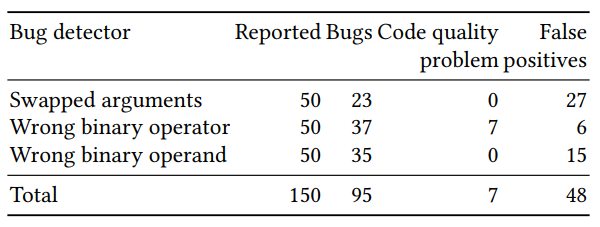
Оценка качества полученного классификатора была разбита на две части: оценка на большом количестве искусственно сгенерированных примеров и ручная проверка на небольшом количестве (50 для каждого детектора) примеров с самой большой предсказанной вероятностью. Результаты для трех детекторов (переставленные аргументы, правильность бинарного оператора и бинарного операнда) получились следующими:
Некоторые из предсказанных ошибок было бы тяжело найти классическими методами поиска. Пример с переставленными res и err в вызове p.done:
Также встречались примеры, в которых ошибки не содержится, но переменные стоило бы переименовать, чтобы не вводить человека, пытающегося разобраться в коде, в заблуждение. Например, сложение width и each не кажется хорошей идеей, хотя оказалось и не багом:
Я занимался переносом работы Майкла Прадела с js на python, а затем созданием плагина для PyCharm, реализующим инспекции на основе вышеописанного метода. При этом использовался датасет Python 150K (150 тысяч файлов на Python, доступных на GitHub).
Во-первых, оказалось, что в Python встречается больше разных токенов, чем в javascript. Для js 10000 самых популярных токенов составляли больше 90% от всех встречавшихся, в то время как для Python пришлось использовать около 40000. Это привело к росту размера отображения токенов в вектора, что осложнило портирование в плагин.
Во-вторых, реализовав для Python поиск неправильных аргументов в вызовах функции и посмотрев на результаты вручную, я получил долю ошибок больше 90%, что расходилось с результатами для js. Разобравшись в причинах, оказалось, что в javascript большее количество функций объявлено в том же файле, что и их вызовы. Я, последовав примеру автора статьи, сперва не стал разрешать объявления функций из других файлов, что и привело к плохим результатам.
К концу августа я закончил реализацию для Python и написал основу для плагина. Плагин продолжает разрабатываться, теперь этим занимается студентка Анастасия Тучина из нашей лаборатории.
Шаги для того, чтобы попробовать, как работает плагин, вы можете найти в вики репозитория.
Ссылки на github:
Репозиторий с реализацией для питона
Репозиторий с плагином
В этой статье я поделюсь своим опытом прохождения стажировки в JetBrains Research, расскажу о задачах, которые там решают, и подробнее остановлюсь на том, как при помощи машинного обучения можно искать баги в программном коде.

О себе
Меня зовут Егор Богомолов, я студент 4-го курса бакалавриата Питерской Вышки по направлению “Прикладная математика и информатика”. Первые 3 года я, как и мои однокурсники, учился в Академическом Университете, а с этого сентября мы всей кафедрой переместились в Высшую школу экономики.
После 2-го курса я ездил на летнюю стажировку в Google Zurich. Там я в течение трех месяцев работал в команде Android Calendar, большую часть времени занимаясь frontend’ом и немного UX-research. Самой интересной частью моей работы было исследование, как могут выглядеть интерфейсы календаря в будущем. Приятным оказалось то, что почти вся проделанная мной работа к концу стажировки попала в основную версию приложения. Но тема стажировок в Google очень хорошо освещена в предыдущем посте, поэтому я расскажу о том, чем занимался этим летом.
Что такое JB Research?
JetBrains Research представляет из себя набор лабораторий, работающих в разных областях: языках программирования, прикладной математике, машинном обучении, робототехнике и других. Внутри каждого направления есть несколько научных групп. Я, в силу своего направления, лучше всего знаком с деятельностью групп в сфере машинного обучения. В каждой из них проходят еженедельные семинары, на которых члены группы или приглашенные гости рассказывают о своей работе или интересных статьях в их области. На эти семинары приходит много студентов из Вышки, благо проходят они через дорогу от основного корпуса Питерского кампуса ВШЭ.
На нашей бакалаврской программе мы обязательно занимаемся научно-исследовательской работой (НИР) и два раза в год презентуем результаты исследований. Часто эта работа плавно перерастает в летние стажировки. Это произошло и с моей научно-исследовательской работой: летом этого года я проходил стажировку в лаборатории “Методы машинного обучения в программной инженерии” у своего научного руководителя Тимофея Брыксина. В задачи, над которыми работают в этой лаборатории, входят автоматическое предложение рефакторингов, анализ стиля кода программистов, автодополнение кода, поиск ошибок в программном коде.
Моя стажировка длилась два месяца (июль и август), а осенью я продолжил заниматься поставленными задачами в рамках НИРа. Я работал в нескольких направлениях, самым интересным из них, на мой взгляд, был автоматический поиск багов в коде, про него я и хочу рассказать. Отправной точкой стала статья Майкла Прадела.
Автоматический поиск багов
Как ищут баги сейчас?
Зачем искать баги более-менее понятно. Давайте разберемся, как это делают сейчас. Современные баг-детекторы в основном базируются на статическом анализе кода. Для каждого вида ошибок ищут заранее замеченные паттерны, по которым его можно определить. Затем, чтобы уменьшить количество ложных срабатываний, добавляются эвристики, придуманные для каждого отдельного случая. Паттерны можно искать как в абстрактном синтаксическом дереве (AST), построенном по коду, так и в графах потока управления или данных.
int foo() {
if ((x < 0) || x > MAX) {
return -1;
}
int ret = bar(x);
if (ret != 0) {
return -1;
} else {
return 1;
}
}
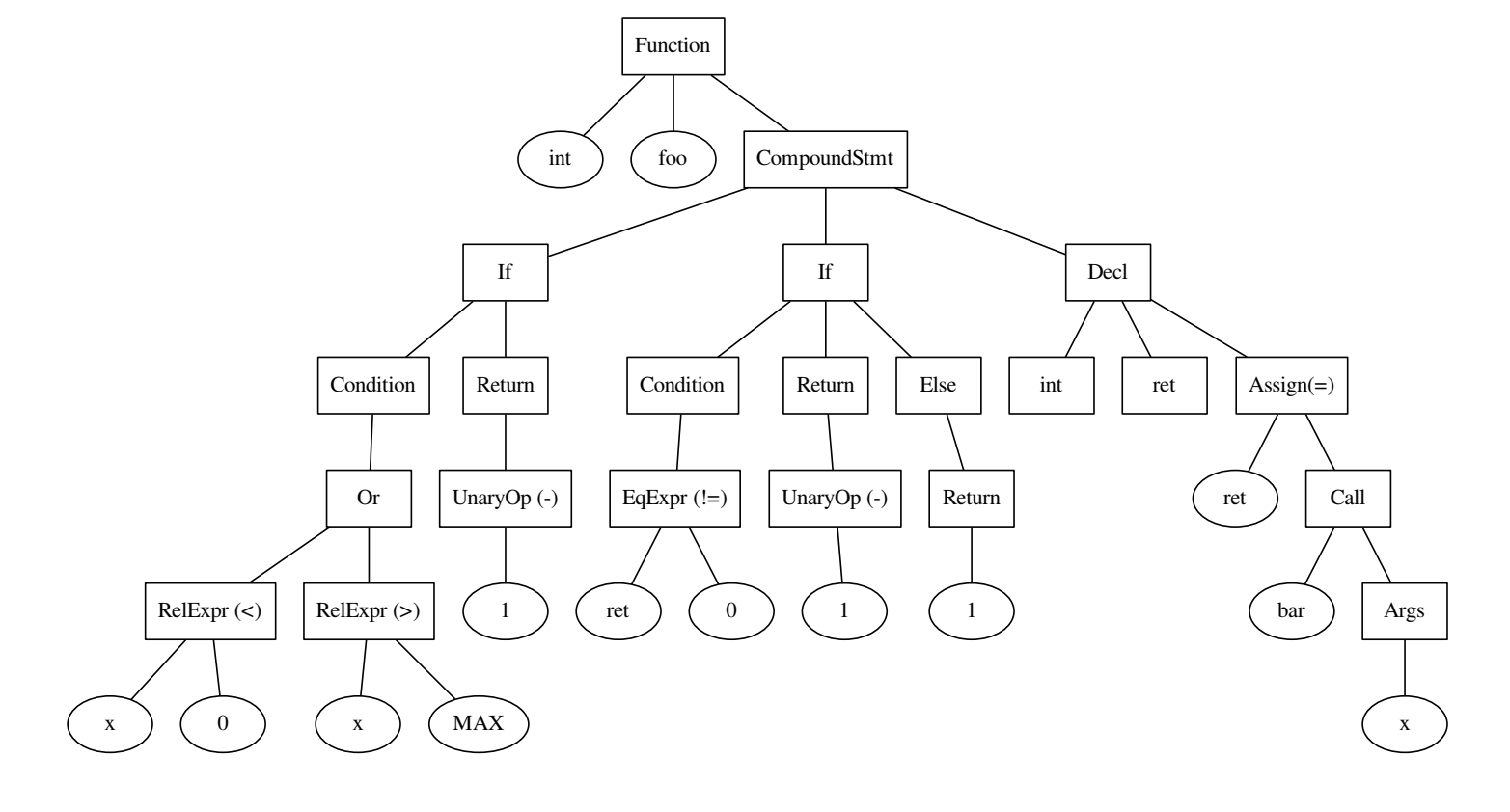
Код и дерево, которое по нему построили.
Чтобы понять, как это работает, рассмотрим пример. Видом багов может быть использование = вместо == в C++. Посмотрим на следующий кусочек кода:
int value = 0;
…
if (value = 1) {
...
} else { … }
В нем в условном выражении допущена ошибка, при этом первое = в присвоении значения переменной правильное. Отсюда возникает паттерн: если присвоение используется внутри условия в if, это потенциальный баг. Ища такой паттерн в AST, мы сможем обнаружить ошибку и исправить ее.
int value = 0;
…
if (value == 1) {
...
} else { … }
В более общем случае у нас уже не получится так легко найти способ описать ошибку. Допустим, что мы хотим определять правильность порядка операндов. Опять посмотрим на фрагменты кода:
for (int i = 2; i < n; i++) {
a[i] = a[1 - i] + a[i - 2];
}
int bitReverse(int i) {
return 1 - i;
}
В первом случае использование 1-i было ошибочным, а во втором вполне корректным, что понятно из контекста. Но как описать это в виде паттерна? С усложнением вида ошибок приходится рассматривать все больший участок кода и разбирать все больше отдельных случаев.
Последний мотивирующий пример: полезная информация содержится еще и в именах методов и переменных. Ее еще сложнее выразить какими-то вручную заданными условиями.
int getSquare(int xDim, int yDim) { … }
int x = 3, y = 4;
int s = getSquare(y, x);
Человеку понятно, что, скорее всего, аргументы в вызове функции перепутаны, ведь у нас есть понимание того, что x больше похоже на xDim, чем на yDim. Но как сообщить об этом детектору? Можно добавлять какие-то эвристики вида “имя переменной это префикс имени аргумента”, но, допустим, то, что x чаще является шириной, чем высотой, так уже не выразить.
Итого: проблемой современного подхода к поиску ошибок является то, что очень много работы приходится проделывать руками: определять паттерны, добавлять эвристики, из-за этого добавление поддержки нового типа ошибок в детектор становится трудоемким. Помимо этого сложно использовать важную часть информации, которую в коде оставил разработчик: имена переменных и методов.
Как может помочь машинное обучение?
Как вы могли заметить, во многих примерах ошибки видны человеку, но их тяжело описать формально. В таких ситуациях часто могут помочь методы машинного обучения. Давайте остановимся на поиске переставленных аргументов в вызове функции и поймем, что нам нужно, чтобы их искать при помощи машинного обучения:
- Большое количество примеров кода без багов
- Большое количество кода с ошибками заданного типа
- Способ векторизации фрагментов кода
- Модель, которую мы обучим различать код с ошибками и без
Мы можем надеяться, что в большей части кода, выложенного в открытый доступ, аргументы в вызовах функций стоят в правильном порядке. Поэтому для примеров кода без багов можно взять какой-нибудь большой датасет. В случае автора оригинальной статьи это был JS 150K (150 тысяч файлов на Javascript), в нашем случае — аналогичный датасет для Python.
Найти код с багами гораздо сложнее. Но мы можем не искать чьи-то ошибки, а делать их самостоятельно! Для типа ошибок нужно задать функцию, которая по корректному куску кода будет делать испорченный. В нашем случае — переставлять аргументы в вызове функции.
Как векторизовать код?
Вооруженные большим количеством хорошего и плохого кода мы почти готовы кого-нибудь чему-нибудь учить. До этого нам еще нужно ответить на вопрос: а как представлять фрагменты кода?
Вызов функции можно представить как кортеж из названия метода, названия того, чей это метод, имен и типов аргументов, передаваемых переменных. Если мы научимся векторизовать отдельные токены (имена переменных и методов, все “слова”, встречающиеся в коде), то сможем взять конкатенацию векторов интересных нам токенов и получить желаемый вектор для фрагмента.
Чтобы векторизовать токены посмотрим на то, как векторизуют слова в обычных текстах. Одним из наиболее успешных и популярных способов является предложенный в 2013 году word2vec.
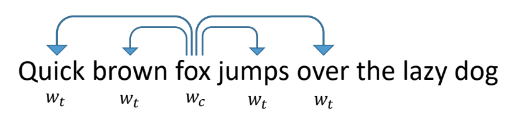
Работает он следующим образом: мы учим сеть предсказывать по слову другие слова, которые встречаются рядом с ним в текстах. Сеть при этом выглядит как входной слой размером равный словарю, скрытый слой размера векторизации, которую мы хотим получить, и выходной слой, тоже размера словаря. В ходе обучения сети подаются на вход вектора с одной единицей на месте рассматриваемого слова (fox), а на выходе мы хотим получать слова, которые встречаются в рамках окна вокруг этого слова (quick, brown, jumps, over). При этом сеть сперва переводит все слова в вектор на скрытом слое, а потом делает предсказание.
Получающиеся в результате векторы для отдельных слов обладают хорошими свойствами. Например, вектора слов с похожим значением близки друг к другу, а сумма и разность векторов являются сложением и разностью “смыслов” слов.
Чтобы сделать аналогичную векторизацию токенов в коде, нужно как-то задать окружение, которое будет предсказываться. Им может выступать информация из AST: типы вершин вокруг, встречающиеся токены, позиция в дереве.
Получив векторизацию можно посмотреть, какие токены похожи друг на друга. Для этого посчитаем косинусное расстояние между ними. В итоге для Javascript получаются следующие соседние вектора (число — косинусное расстояние):
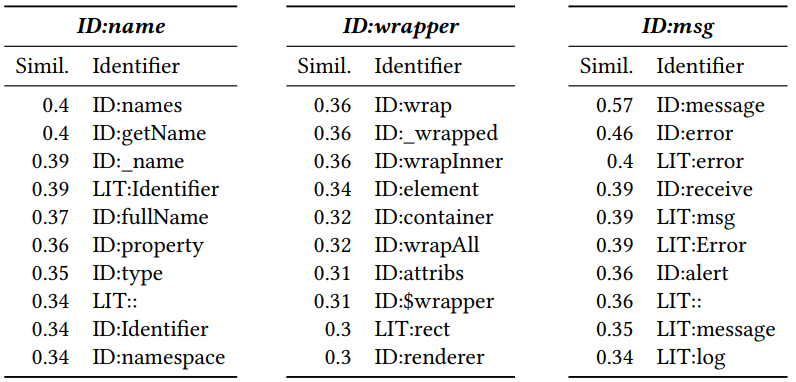
ID и LIT дописанные в начале обозначают, является ли токен идентификатором (имя переменной, метода) или литералом (константа). Видно, что близость является осмысленной.
Обучение классификатора
Получив векторизацию для отдельных токенов, получить представление для куска кода с потенциальной ошибкой достаточно просто: это конкатенация векторов важных для классификации токенов. По кускам кода обучается двухслойный перцептрон с ReLU в качестве функции активации и dropout для уменьшения переобучения. Обучение сходится быстро, полученная модель имеет маленький размер и может делать предсказания для сотен примеров в секунду. Это позволяет использовать ее в режиме реального времени, о чем будет сказано дальше.
Результаты
Оценка качества полученного классификатора была разбита на две части: оценка на большом количестве искусственно сгенерированных примеров и ручная проверка на небольшом количестве (50 для каждого детектора) примеров с самой большой предсказанной вероятностью. Результаты для трех детекторов (переставленные аргументы, правильность бинарного оператора и бинарного операнда) получились следующими:
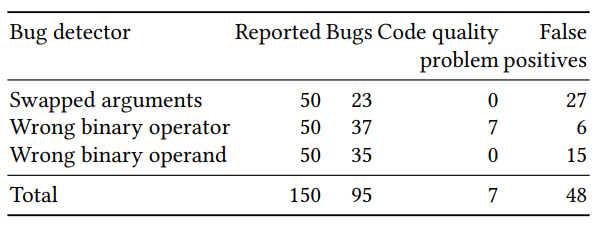
Некоторые из предсказанных ошибок было бы тяжело найти классическими методами поиска. Пример с переставленными res и err в вызове p.done:
var p = new Promise ();
if ( promises === null || promises . length === 0) {
p. done (error , result )
} else {
promises [0](error, result).then( function(res, err) {
p.done(res, err);
});
}
Также встречались примеры, в которых ошибки не содержится, но переменные стоило бы переименовать, чтобы не вводить человека, пытающегося разобраться в коде, в заблуждение. Например, сложение width и each не кажется хорошей идеей, хотя оказалось и не багом:
var cw = cs[i].width + each;
Перенос на Python
Я занимался переносом работы Майкла Прадела с js на python, а затем созданием плагина для PyCharm, реализующим инспекции на основе вышеописанного метода. При этом использовался датасет Python 150K (150 тысяч файлов на Python, доступных на GitHub).
Во-первых, оказалось, что в Python встречается больше разных токенов, чем в javascript. Для js 10000 самых популярных токенов составляли больше 90% от всех встречавшихся, в то время как для Python пришлось использовать около 40000. Это привело к росту размера отображения токенов в вектора, что осложнило портирование в плагин.
Во-вторых, реализовав для Python поиск неправильных аргументов в вызовах функции и посмотрев на результаты вручную, я получил долю ошибок больше 90%, что расходилось с результатами для js. Разобравшись в причинах, оказалось, что в javascript большее количество функций объявлено в том же файле, что и их вызовы. Я, последовав примеру автора статьи, сперва не стал разрешать объявления функций из других файлов, что и привело к плохим результатам.
К концу августа я закончил реализацию для Python и написал основу для плагина. Плагин продолжает разрабатываться, теперь этим занимается студентка Анастасия Тучина из нашей лаборатории.
Шаги для того, чтобы попробовать, как работает плагин, вы можете найти в вики репозитория.
Ссылки на github:
Репозиторий с реализацией для питона
Репозиторий с плагином
