Задача деплоя моделей машинного обучения в продакшн — это всегда боль и страдания, потому что очень некомфортно вылезать из уютного jupyter notebook в мир мониторинга и отказоустойчивости.
Мы уже писали про первую итерацию рефакторинга рекомендательной системы онлайн-кинотеатра ivi. За прошедший год мы почти не дорабатывали архитектуру приложения (из глобального — только перезд с устаревших python 2.7 и python 3.4 на «свежий» python 3.6), зато добавили несколько новых ML моделей и сразу столкнулись с проблемой выкатывания новых алгоритмов в продакшн. В статье я расскажу про наш опыт внедрения такого инструмента управления потоками выполнения задач как Apache Airflow: почему у команды возникла эта необходимость, чем не устраивало существующее решение, какие костыли пришлось запилить по дороге и что из этого получилось.
→ Видео-версию доклада можно посмотреть на ютубе (начиная с 03:00:00) здесь.

Немного расскажу о проекте: ivi — это несколько десятков тысяч единиц контента, у нас один из крупнейших легальных каталогов в рунете. Главная страница web-версии ivi — персонализованная нарезка из каталога, которая призвана предоставить пользователю самый сочный, самый релевантный контент, основываясь на его фидбэке (просмотрах, рейтингах и так далее).

Онлайн-часть рекомендательной системы представляет собой бэкендовое Flask-приложение с нагрузкой до 600 RPS. В оффлайне модель обучается более чем на 250 миллионах просмотрах контента за месяц. Пайплайны подготовки данных для обучения реализованы на Spark, который работает поверх хранилища Hive.
В команде сейчас 7 разработчиков, которые занимаются как созданием моделей, так и выкатыванием их в продакшн — это довольно большая команда, которая требует удобных инструментов управления потоками задач.
Ниже вы видите схему инфраструктуры потоков данных для рекомендательной системы.

Тут изображены два хранилища данных — Hive для пользовательского фидбэка (просмотры, рейтинги) и Postgres для различной бизнес-информации (типы монетизации контента и прочее), при этом налажена перелиливка из Postgres в Hive. Пачка Spark-приложений высасывает данные из Hive: и обучает на этих данных наши модели (ALS для персональных рекомендаций, различные коллаборативные модели схожести контента).
Spark-приложения традиционно управлялись с выделенной виртуалки, которую мы называем hydra-updater с помощью связки cron+shell-скрипт. Эта связка была создана в отделе эксплуатации ivi в незапамятные времена и отлично работала. Shell-скрипт являлся единой точкой входа для запуска spark-приложений — то есть каждая новая модель начинала крутиться в проде только после того, как админы допилят этот скрипт.
Часть артефактов обучения моделей сохраняется в HDFS на вечное хранение (и ждёт, пока их оттуда кто-нибудь скачает и перенесёт на сервера, где крутится онлайн-часть) а часть пишется прямо из Spark-драйвера в быстрое хранилище Redis, которое мы используем как общую память для нескольких десятков python-процессов онлайн-части.
У такой архитектуры со временем накопился ряд недостатков:

На схеме видно, что потоки данных имеют довольно сложную и запутанную структуру — без простого и понятного инструмента управления этим добром разработка и эксплуатация превратятся в ужас, тлен и страдания.
Кроме управления spark-приложениями, админский скрипт делает множество полезных вещей: рестарт сервисов на бою, дамп Redis и другие системные штуки. Очевидно, что за длительный период эксплуатации скрипт оброс множеством функций, так как каждая новая наша модель порождала пару десятков строчек в нем. Скрипт стал выглядеть слишком перегруженным по функционалу, поэтому нам в команде рекомендательной системы захотелось вынести куда-нибудь часть функционала, которая касается запуска и управления Spark-приложениями. Для этих целей мы и решили заюзать Airflow.
Кроме решения всех эти проблем, конечно, по дороге мы создали себе новых — разворачивание Airflow для запуска и мониторинга Spark-приложений оказалось делом непростым.
Основная трудность заключалась в том, что всю инфраструктуру для нас бы переделывать никто не стал, т.к. devops-ресурс — штука дефицитная. По этой причине нам пришлось не просто внедрить Airflow, а интегрировать его в существующую систему, что намного сложнее запиливания “с нуля”.
Я хочу рассказать про боли, с которыми мы столкнулись в процессе внедрения, и костыли которые нам пришлось запилить, чтобы всё-таки завести Airflow.
Первая и главная боль: как интегрировать Airflow в большой shell-скрипт отдела эксплуатации.
Тут решение самое очевидное — мы стали триггерить графы прямо из shell-скрипта с помощью бинарника airflow c ключом trigger_dag. При этом подходе мы не используем шедулер Airflow и по сути Spark-приложение запускается всё тем же кроном — это религиозно не очень правильно. Зато мы получили бесшовную интеграцию с уже существующим решением. Вот как выглядит старт из shell-скрипта нашего главного Spark-приложения, которое исторически называется hydramatrices.
Боль: Shell-скрипт отдела эксплуатации должен как-то определять статус Airflow-графа, чтобы управлять собственным потоком выполнения.
Костыль: мы расширили Airflow REST API эндпоинтом для мониторинга DAG прямо внутри shell-скриптов. Теперь каждый граф имеет три состояния: RUNNING, SUCCEED, FAILED.
По сути после запуска вычислений в Airflow мы просто регулярно опрашиваем бегущий граф: пуляем GET-запрос, чтобы определить, завершился DAG, или нет. Когда эндпоинт мониторинга отвечает об успешном выполнении графа, shell-скрипт продолжает исполнение своего потока.
Хочется сказать, что Airflow REST API это просто огненная штука, которая позволяет гибко конфигуриловать ваши пайплайны — например, в графы можно прокидывать POST-параметры.
Расширение API Airflow — это просто питоновский класс, который выглядит примерно так:
Используем API в shell-скрипте — опрашиваем эндпоинт каждые 10 минут:
Боль: если вы когда-нибудь запускали Spark-джобу с помощью spark-submit в cluster-режиме, то вы знаете что логи в STDOUT представляют собой неинформативную простыню со строчками “SPARK APPLICATION_ID IS RUNNING”. Логи самого Spark-приложения можно было посмотреть, например, с помощью команды yarn logs. В shell-скрипте эта проблема решалась просто: открывался SSH-туннель до одной из машин кластера и spark-submit выполнялся в client-режиме этой машине. В таком случае в STDOUT будут читаемые и понятные логи. В Airflow мы решили всегда использовать cluster-решим и такой номер уже не пройдёт.
Костыль: после того, как spark-submit отработал, тянем логи драйвера из HDFS по application_id и выводим в интерфейсе Airflow просто через питоновский оператор print(). Единственный минус — в интерфейсе Airflow логи появляются только после того как spark-submit отработал, следить за джобой реалтайм приходится в других местах — например, веб-морде YARN.
Боль: для тестировщиков и разработчиков по-хорошему нужно было бы завести тестовый стенд Airflow, но мы экономим devops ресурсы, поэтому долго думали о том, как же нам развернуть тестовую среду.
Костыль: мы упаковали Airflow в докер-контейнер, а Dockerfile положили прямо в репозиторий со спарк-джобами. Таким образом каждый разработчик или тестировщик может поднять свой собственный Airflow на локальной машине. В силу того, что приложения исполняются в cluster-mode, локальных ресурсов для докера почти не требуется.
Еще внутрь докер-контейнера спряталась локальная установка спарка и вся его настройка через переменные окружения — больше не нужно тратить по несколько часов на настройку окружения. Ниже я привел пример с фрагментом докерфайла для контейнера с Airflow, где можно видеть, как конфигурируется Airflow c помощью переменных среды:
В результате внедрения Airflow мы достигли следующих результатов:
Куда двигаться дальше? Сейчас у нас огромное количество источников и стоков данных, число которых будет расти. Изменения в любом классе репозитория hydramatrices могут привести к крашу в другом пайплайне (или даже в онлайн-части):
В такой ситуации нам жизненно необходим стенд для автоматического тестирования пайплайнов в подготовки данных. Это сильно сократит затраты на тестирование изменений в репозитории, ускорит выкатывание новых моделей в продакшн и резко увеличит уровень эндорфинов у тестировщиков. А ведь без Airflow развернуть стенд для такого рода автотестов было бы невозможно!
Эту статью я написал, чтобы рассказать про наш опыт внедрения Airflow, который может оказаться полезным другим командам в похожей ситуации — у вас уже есть большая работающая система, а вы хотите попробовать что-то новое, модное и молодёжное. Не нужно бояться каких-то обновлений работающей системы, нужно пробовать и экспериментировать — такие эксперименты обычно открывают новые горизонты для дальнейшего развития.
Мы уже писали про первую итерацию рефакторинга рекомендательной системы онлайн-кинотеатра ivi. За прошедший год мы почти не дорабатывали архитектуру приложения (из глобального — только перезд с устаревших python 2.7 и python 3.4 на «свежий» python 3.6), зато добавили несколько новых ML моделей и сразу столкнулись с проблемой выкатывания новых алгоритмов в продакшн. В статье я расскажу про наш опыт внедрения такого инструмента управления потоками выполнения задач как Apache Airflow: почему у команды возникла эта необходимость, чем не устраивало существующее решение, какие костыли пришлось запилить по дороге и что из этого получилось.
→ Видео-версию доклада можно посмотреть на ютубе (начиная с 03:00:00) здесь.

Команда Hydra
Немного расскажу о проекте: ivi — это несколько десятков тысяч единиц контента, у нас один из крупнейших легальных каталогов в рунете. Главная страница web-версии ivi — персонализованная нарезка из каталога, которая призвана предоставить пользователю самый сочный, самый релевантный контент, основываясь на его фидбэке (просмотрах, рейтингах и так далее).
Онлайн-часть рекомендательной системы представляет собой бэкендовое Flask-приложение с нагрузкой до 600 RPS. В оффлайне модель обучается более чем на 250 миллионах просмотрах контента за месяц. Пайплайны подготовки данных для обучения реализованы на Spark, который работает поверх хранилища Hive.
В команде сейчас 7 разработчиков, которые занимаются как созданием моделей, так и выкатыванием их в продакшн — это довольно большая команда, которая требует удобных инструментов управления потоками задач.
Архитектура оффлайн-части
Ниже вы видите схему инфраструктуры потоков данных для рекомендательной системы.
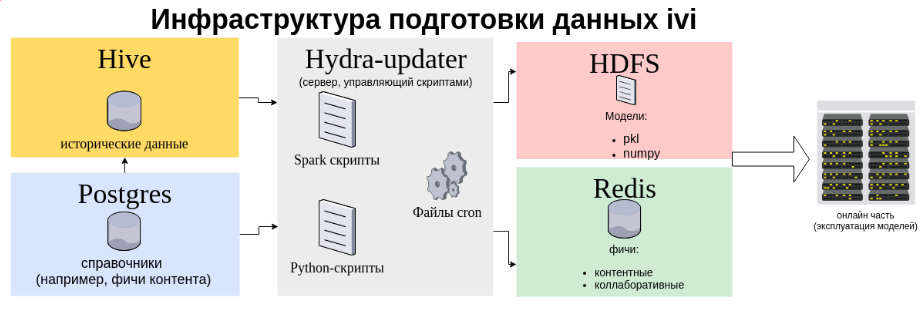
Тут изображены два хранилища данных — Hive для пользовательского фидбэка (просмотры, рейтинги) и Postgres для различной бизнес-информации (типы монетизации контента и прочее), при этом налажена перелиливка из Postgres в Hive. Пачка Spark-приложений высасывает данные из Hive: и обучает на этих данных наши модели (ALS для персональных рекомендаций, различные коллаборативные модели схожести контента).
Spark-приложения традиционно управлялись с выделенной виртуалки, которую мы называем hydra-updater с помощью связки cron+shell-скрипт. Эта связка была создана в отделе эксплуатации ivi в незапамятные времена и отлично работала. Shell-скрипт являлся единой точкой входа для запуска spark-приложений — то есть каждая новая модель начинала крутиться в проде только после того, как админы допилят этот скрипт.
Часть артефактов обучения моделей сохраняется в HDFS на вечное хранение (и ждёт, пока их оттуда кто-нибудь скачает и перенесёт на сервера, где крутится онлайн-часть) а часть пишется прямо из Spark-драйвера в быстрое хранилище Redis, которое мы используем как общую память для нескольких десятков python-процессов онлайн-части.
У такой архитектуры со временем накопился ряд недостатков:

На схеме видно, что потоки данных имеют довольно сложную и запутанную структуру — без простого и понятного инструмента управления этим добром разработка и эксплуатация превратятся в ужас, тлен и страдания.
Кроме управления spark-приложениями, админский скрипт делает множество полезных вещей: рестарт сервисов на бою, дамп Redis и другие системные штуки. Очевидно, что за длительный период эксплуатации скрипт оброс множеством функций, так как каждая новая наша модель порождала пару десятков строчек в нем. Скрипт стал выглядеть слишком перегруженным по функционалу, поэтому нам в команде рекомендательной системы захотелось вынести куда-нибудь часть функционала, которая касается запуска и управления Spark-приложениями. Для этих целей мы и решили заюзать Airflow.
Костыли для Airflow
Кроме решения всех эти проблем, конечно, по дороге мы создали себе новых — разворачивание Airflow для запуска и мониторинга Spark-приложений оказалось делом непростым.
Основная трудность заключалась в том, что всю инфраструктуру для нас бы переделывать никто не стал, т.к. devops-ресурс — штука дефицитная. По этой причине нам пришлось не просто внедрить Airflow, а интегрировать его в существующую систему, что намного сложнее запиливания “с нуля”.
Я хочу рассказать про боли, с которыми мы столкнулись в процессе внедрения, и костыли которые нам пришлось запилить, чтобы всё-таки завести Airflow.
Первая и главная боль: как интегрировать Airflow в большой shell-скрипт отдела эксплуатации.
Тут решение самое очевидное — мы стали триггерить графы прямо из shell-скрипта с помощью бинарника airflow c ключом trigger_dag. При этом подходе мы не используем шедулер Airflow и по сути Spark-приложение запускается всё тем же кроном — это религиозно не очень правильно. Зато мы получили бесшовную интеграцию с уже существующим решением. Вот как выглядит старт из shell-скрипта нашего главного Spark-приложения, которое исторически называется hydramatrices.
log "$FUNCNAME started"
local RETVAL=0
export AIRFLOW_CONFIG=/opt/airflow/airflow.cfg
AIRFLOW_API=api/dag_last_run/hydramatrices/all
log "run /var/www/airflow/bin/airflow trigger_dag hydramatrices"
/var/www/airflow/bin/airflow trigger_dag hydramatrices 2>&1 | tee -a $LOGFILE
Боль: Shell-скрипт отдела эксплуатации должен как-то определять статус Airflow-графа, чтобы управлять собственным потоком выполнения.
Костыль: мы расширили Airflow REST API эндпоинтом для мониторинга DAG прямо внутри shell-скриптов. Теперь каждый граф имеет три состояния: RUNNING, SUCCEED, FAILED.
По сути после запуска вычислений в Airflow мы просто регулярно опрашиваем бегущий граф: пуляем GET-запрос, чтобы определить, завершился DAG, или нет. Когда эндпоинт мониторинга отвечает об успешном выполнении графа, shell-скрипт продолжает исполнение своего потока.
Хочется сказать, что Airflow REST API это просто огненная штука, которая позволяет гибко конфигуриловать ваши пайплайны — например, в графы можно прокидывать POST-параметры.
Расширение API Airflow — это просто питоновский класс, который выглядит примерно так:
import json
import os
from airflow import settings
from airflow.models import DagBag, DagRun
from flask import Blueprint, request, Response
airflow_api_blueprint = Blueprint('airflow_api', __name__, url_prefix='/api')
AIRFLOW_DAGS = '{}/dags'.format(
os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
)
class ApiResponse:
"""Класс обработки ответов на GET запросы"""
STATUS_OK = 200
STATUS_NOT_FOUND = 404
def __init__(self):
pass
@staticmethod
def standard_response(status: int, payload: dict) -> Response:
json_data = json.dumps(payload)
resp = Response(json_data, status=status, mimetype='application/json')
return resp
def success(self, payload: dict) -> Response:
return self.standard_response(self.STATUS_OK, payload)
def error(self, status: int, message: str) -> Response:
return self.standard_response(status, {'error': message})
def not_found(self, message: str = 'Resource not found') -> Response:
return self.error(self.STATUS_NOT_FOUND, message)
Используем API в shell-скрипте — опрашиваем эндпоинт каждые 10 минут:
TRIGGER=$?
[ "$TRIGGER" -eq "0" ] && log "trigger airflow DAG succeeded" || { log "trigger airflow DAG failed"; return 1; }
CMD="curl -s http://$HYDRA_SERVER/$AIRFLOW_API | jq .dag_last_run.state"
STATE=$(eval $CMD)
while [ $STATE == \"running\" ]; do
log "Generating matrices in progress..."
sleep 600
STATE=$(eval $CMD)
done
[ $STATE == \"success\" ] && RETVAL=0 || RETVAL=1
[ $RETVAL -eq 0 ] && log "$FUNCNAME succeeded" || log "$FUNCNAME failed"
return $RETVAL
Боль: если вы когда-нибудь запускали Spark-джобу с помощью spark-submit в cluster-режиме, то вы знаете что логи в STDOUT представляют собой неинформативную простыню со строчками “SPARK APPLICATION_ID IS RUNNING”. Логи самого Spark-приложения можно было посмотреть, например, с помощью команды yarn logs. В shell-скрипте эта проблема решалась просто: открывался SSH-туннель до одной из машин кластера и spark-submit выполнялся в client-режиме этой машине. В таком случае в STDOUT будут читаемые и понятные логи. В Airflow мы решили всегда использовать cluster-решим и такой номер уже не пройдёт.
Костыль: после того, как spark-submit отработал, тянем логи драйвера из HDFS по application_id и выводим в интерфейсе Airflow просто через питоновский оператор print(). Единственный минус — в интерфейсе Airflow логи появляются только после того как spark-submit отработал, следить за джобой реалтайм приходится в других местах — например, веб-морде YARN.
def get_logs(config: BaseConfig, app_id: str) -> None:
"""Получить логи спарка
:param config:
:param app_id:
"""
hdfs = HDFSInteractor(config)
logs_path = '/tmp/logs/{username}/logs/{app_id}'.format(username=config.CURRENT_USERNAME, app_id=app_id)
logs_files = hdfs.files_in_folder(logs_path)
logs_files = [file for file in logs_files if file[-4:] != '.tmp']
for file in logs_files:
with hdfs.hdfs_client.read(os.path.join(logs_path, file), encoding='utf-8', delimiter='\n') as reader:
print_line = False
for line in reader:
if re.search('stdout', line) and len(line) > 30:
print_line = True
if re.search('stderr', line):
print_line = False
if print_line:
print(line)
Боль: для тестировщиков и разработчиков по-хорошему нужно было бы завести тестовый стенд Airflow, но мы экономим devops ресурсы, поэтому долго думали о том, как же нам развернуть тестовую среду.
Костыль: мы упаковали Airflow в докер-контейнер, а Dockerfile положили прямо в репозиторий со спарк-джобами. Таким образом каждый разработчик или тестировщик может поднять свой собственный Airflow на локальной машине. В силу того, что приложения исполняются в cluster-mode, локальных ресурсов для докера почти не требуется.
Еще внутрь докер-контейнера спряталась локальная установка спарка и вся его настройка через переменные окружения — больше не нужно тратить по несколько часов на настройку окружения. Ниже я привел пример с фрагментом докерфайла для контейнера с Airflow, где можно видеть, как конфигурируется Airflow c помощью переменных среды:
FROM ubuntu:16.04
ARG AIRFLOW_VERSION=1.9.0
ARG AIRFLOW_HOME
ARG USERNAME=airflow
ARG USER_ID
ARG GROUP_ID
ARG LOCALHOST
ARG AIRFLOW_PORT
ARG PIPENV_PATH
ARG PROJECT_HYDRAMATRICES_DOCKER_PATH
RUN apt-get update \
&& apt-get install -y \
python3.6 \
python3.6-dev \
&& update-alternatives --install /usr/bin/python3 python3.6 /usr/bin/python3.6 0 \
&& apt-get -y install python3-pip
RUN mv /root/.pydistutils.cf /root/.pydistutils.cfg
RUN pip3 install pandas==0.20.3 \
apache-airflow==$AIRFLOW_VERSION \
psycopg2==2.7.5 \
ldap3==2.5.1 \
cryptography
# Директория с проектом, которая используется в дальнейшем всеми скриптами
ENV PROJECT_HYDRAMATRICES_DOCKER_PATH=${PROJECT_HYDRAMATRICES_DOCKER_PATH}
ENV PIPENV_PATH=${PIPENV_PATH}
ENV SPARK_HOME=/usr/lib/spark2
ENV HADOOP_CONF_DIR=$PROJECT_HYDRAMATRICES_DOCKER_PATH/etc/hadoop-conf-preprod
ENV PYTHONPATH=${SPARK_HOME}/python/lib/py4j-0.10.4-src.zip:${SPARK_HOME}/python/lib/pyspark.zip:${SPARK_HOME}/python/lib
ENV PIP_NO_BINARY=numpy
ENV AIRFLOW_HOME=${AIRFLOW_HOME}
ENV AIRFLOW_DAGS=${AIRFLOW_HOME}/dags
ENV AIRFLOW_LOGS=${AIRFLOW_HOME}/logs
ENV AIRFLOW_PLUGINS=${AIRFLOW_HOME}/plugins
# Для корректного отображения логов в Airflow (log url)
BASE_URL="http://${AIRFLOW_CURRENT_HOST}:${AIRFLOW_PORT}" ;
# Настройка конфига Airflow
ENV AIRFLOW__WEBSERVER__BASE_URL=${BASE_URL}
ENV AIRFLOW__WEBSERVER__ENDPOINT_URL=${BASE_URL}
ENV AIRFLOW__CORE__AIRFLOW_HOME=${AIRFLOW_HOME}
ENV AIRFLOW__CORE__DAGS_FOLDER=${AIRFLOW_DAGS}
ENV AIRFLOW__CORE__BASE_LOG_FOLDER=${AIRFLOW_LOGS}
ENV AIRFLOW__CORE__PLUGINS_FOLDER=${AIRFLOW_PLUGINS}
ENV AIRFLOW__SCHEDULER__CHILD_PROCESS_LOG_DIRECTORY=${AIRFLOW_LOGS}/scheduler
В результате внедрения Airflow мы достигли следующих результатов:
- Сократили релизный цикл: выкатка новой модели (или пайплайна подготовки данных) теперь сводится к написанию нового графа Airflow, сами графы хранятся в репозитории и деплоятся вместе с кодом. Этот процесс полностью находится в руках разработчика. Админы счастливы, мы больше не дёргаем их по мелочам.
- Логи Spark-приложений, которые раньше попадали прямиком в ад теперь хранятся в Aiflow с удобным интерфейсом доступа. Можно посмотреть логи за любой день без ковыряния в HDFS-директориях.
- Завалившийся расчёт можно перезапустить одной кнопкой в интерфейсе, это очень удобно, справится даже джун.
- Можно пулять спарк-джобы из интерфейса, не упарываясь с настройкой Spark на локальной машине. Тестировщики счастливы — все настройки для корректной работы spark-submit уже сделаны в Dockerfile
- Стандартные плюшки Aiflow — расписания, перезапуск упавших джобов, красивые графики (например, длительность выполнения приложений, статистика успешных и неуспешных запусков).
Куда двигаться дальше? Сейчас у нас огромное количество источников и стоков данных, число которых будет расти. Изменения в любом классе репозитория hydramatrices могут привести к крашу в другом пайплайне (или даже в онлайн-части):
- переливки Clickhouse → Hive
- препроцессинг данных: Hive → Hive
- деплой c2c моделей: Hive → Redis
- подготовка справочников (вроде типа монетизации контента): Postgres → Redis
- подготовка моделей: Local FS → HDFS
В такой ситуации нам жизненно необходим стенд для автоматического тестирования пайплайнов в подготовки данных. Это сильно сократит затраты на тестирование изменений в репозитории, ускорит выкатывание новых моделей в продакшн и резко увеличит уровень эндорфинов у тестировщиков. А ведь без Airflow развернуть стенд для такого рода автотестов было бы невозможно!
Эту статью я написал, чтобы рассказать про наш опыт внедрения Airflow, который может оказаться полезным другим командам в похожей ситуации — у вас уже есть большая работающая система, а вы хотите попробовать что-то новое, модное и молодёжное. Не нужно бояться каких-то обновлений работающей системы, нужно пробовать и экспериментировать — такие эксперименты обычно открывают новые горизонты для дальнейшего развития.
