Профессии Data Scientist и Data Engineer часто путают. У каждой компании своя специфика работы с данными, разные цели их анализа и разное представление, кто из специалистов какой частью работы должен заниматься, поэтому и требования каждый предъявляет свои.
Разбираемся, в чём разница этих специалистов, какие задачи бизнеса они решают, какими навыками обладают и сколько зарабатывают. Материал получился большим, поэтому разделили его на две публикации.
В первой статье Елена Герасимова, руководитель факультета «Data Science и аналитика» в Нетологии, рассказывает, в чём разница между Data Scientist и Data Engineer и с какими инструментами они работают.
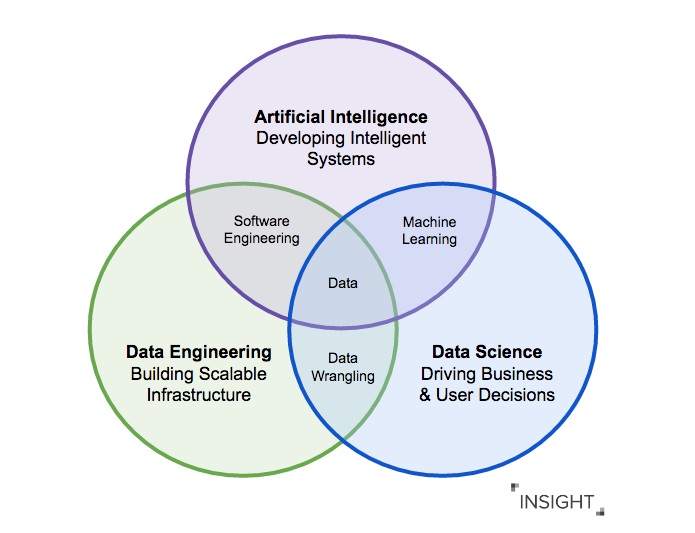
Инженер данных — это специалист, который, с одной стороны, разрабатывает, тестирует и поддерживает инфраструктуру работы с данными: базы данных, хранилища и системы массовой обработки. С другой стороны — это тот, кто очищает и «причёсывает» данные для использования аналитиками и дата-сайентистами, то есть создаёт конвейеры обработки данных.
Data Scientist создаёт и обучает предиктивные (и не только) модели с помощью алгоритмов машинного обучения и нейросетей, помогая бизнесу находить скрытые закономерности, прогнозировать развитие событий и оптимизировать ключевые бизнес-процессы.
Главное различие между Data Scientist и Data Engineer состоит в том, что обычно у них разные цели. Оба работают для того, чтобы данные были доступными и качественными. Но Data Scientist находит ответы на свои вопросы и проверяет гипотезы в экосистеме данных (например, на базе Hadoop), а Data Engineer — создаёт пайплайн обслуживания алгоритма машинного обучения, написанного дата-сайентистом, в кластере Spark внутри той же экосистемы.
Инженер данных приносит ценность бизнесу, работая в команде. Его задача — выступить важным звеном между разными участниками: от разработчиков до бизнес-потребителей отчетности, — и повысить продуктивность аналитиков — от маркетинговых и продуктовых до BI.
Data Scientist же, напротив, принимает активное участие в стратегии компании и извлечении инсайтов, принятии решений, внедрении алгоритмов автоматизации, моделирования и генерации ценности из данных.
Работа с данными подчиняется принципу GIGO (garbage in — garbage out): если аналитики и дата-сайентисты имеют дело с неподготовленными и потенциально некорректными данными, то результаты даже с помощью самых изощрённых алгоритмов анализа будут неверны.
Инженеры данных решают эту проблему, выстраивая пайплайны по обработке, очистке и трансформации данных и позволяя дата-сайентисту работать уже с качественными данными.
На рынке много инструментов для работы с данными, которые покрывают каждый из этапов: от появления данных до вывода на дашборд для совета директоров. И важно, чтобы решение об их использовании принималось инженером, — не потому, что это модно, а потому что он действительно поможет в работе остальным участникам процесса.
Условно: если компании нужно подружить BI и ETL — загрузку данных и обновления отчётов, вот типичный legacy-фундамент, с которым придётся иметь дело Data Engineer (хорошо, если в команде кроме него будет ещё и архитектор).
Обязанности Data Engineer
Существует ещё одна специализация внутри траектории Data Engineer — ML engineer. Если коротко, то такие инженеры специализируются на доведении моделей машинного обучения до промышленного внедрения и использования. Зачастую модель, поступившая от дата-сайентиста, является частью исследования и может не заработать в боевых условиях.
Обязанности Data Scientist
Сегодня ожидания от специалистов по обработке данных изменились. Раньше инженеры собирали большие SQL-запросы, вручную писали MapReduce и обрабатывали данные с помощью таких инструментов, как Informatica ETL, Pentaho ETL, Talend.
В 2020 году специалисту не обойтись без знания Python и современных инструментов проведения вычислений (например Airflow), понимания принципов работы с облачными платформами (использования их для экономии на «железе», при соблюдении принципов безопасности).
SAP, Oracle, MySQL, Redis — это традиционные для инженера данных инструменты в больших компаниях. Они хороши, но стоимость лицензий настолько высока, что учиться работать с ними имеет смысл только в промышленных проектах. При этом есть бесплатная альтернатива в виде Postgres — он бесплатный и подходит не только для обучения.

Исторически часто встречается запрос на Java и Scala, хотя по мере развития технологий и подходов эти языки отходят на второй план.
Тем не менее, хардкорная BigData: Hadoop, Spark и остальной зоопарк — это уже не обязательное условие для инженера данных, а разновидность инструментов для решения задач, которые не решить традиционным ETL.
Популярны промышленные решения от SAS и SPSS, при этом Tableau, Rapidminer, Stata и Julia также широко используются дата-сайентистами для локальных задач.
Возможность самим строить пайплайны появилась у аналитиков и дата-сайентистов всего пару лет назад: например, уже можно относительно несложными скриптами направлять данные в хранилище на основе PostgreSQL.
Обычно использование конвейеров и интегрированных структур данных остаётся в ведении дата-инженеров. Но сегодня как никогда силён тренд на Т-образных специалистов — с широкими компетенциями в смежных областях, ведь инструменты постоянно упрощаются.
Работая в тесном сотрудничестве с инженерами, Data Scientist могут сосредоточиться на исследовательской части, создавая готовые к работе алгоритмы машинного обучения.
А инженеры — сфокусироваться на масштабируемости, повторном использовании данных и гарантировать, что пайплайны ввода и вывода данных в каждом отдельно взятом проекте соответствуют глобальной архитектуре.
Такое разделение обязанностей обеспечивает согласованность действий между группами специалистов, работающими над разными проектами машинного обучения.
Сотрудничество помогает эффективно создавать новые продукты. Скорость и качество достигаются, благодаря балансу между созданием сервиса для всех (глобальное хранилище или интеграция дашбордов) и реализацией каждой конкретной потребности или проекта (узкоспециализированный пайплайн, подключение внешних источников).
Тесная работа с дата-сайентистами и аналитиками помогает инженерам развивать аналитические и исследовательские навыки для написания более качественного кода. Улучшается обмен знаниями между пользователями хранилищ и озёр данных, что делает проекты более гибкими и обеспечивает более устойчивые долгосрочные результаты.
В компаниях, которые ставят своей целью развитие культуры работы с данными и выстраивание бизнес-процессов на их основе, Data Scientist и Data Engineer дополняют друг друга и создают полноценную систему анализа данных.
В следующем материале расскажем о том, какое образование должно быть у Data Engineer и Data Scientists, какие навыки им нужно развивать и как устроен рынок.
Если присматриваетесь к профессии Data Engineer или Data Scientist, приглашаем изучить программы наших курсов:
Разбираемся, в чём разница этих специалистов, какие задачи бизнеса они решают, какими навыками обладают и сколько зарабатывают. Материал получился большим, поэтому разделили его на две публикации.
В первой статье Елена Герасимова, руководитель факультета «Data Science и аналитика» в Нетологии, рассказывает, в чём разница между Data Scientist и Data Engineer и с какими инструментами они работают.
Как различаются роли инженеров и сайентистов
Инженер данных — это специалист, который, с одной стороны, разрабатывает, тестирует и поддерживает инфраструктуру работы с данными: базы данных, хранилища и системы массовой обработки. С другой стороны — это тот, кто очищает и «причёсывает» данные для использования аналитиками и дата-сайентистами, то есть создаёт конвейеры обработки данных.
Data Scientist создаёт и обучает предиктивные (и не только) модели с помощью алгоритмов машинного обучения и нейросетей, помогая бизнесу находить скрытые закономерности, прогнозировать развитие событий и оптимизировать ключевые бизнес-процессы.
Главное различие между Data Scientist и Data Engineer состоит в том, что обычно у них разные цели. Оба работают для того, чтобы данные были доступными и качественными. Но Data Scientist находит ответы на свои вопросы и проверяет гипотезы в экосистеме данных (например, на базе Hadoop), а Data Engineer — создаёт пайплайн обслуживания алгоритма машинного обучения, написанного дата-сайентистом, в кластере Spark внутри той же экосистемы.
Инженер данных приносит ценность бизнесу, работая в команде. Его задача — выступить важным звеном между разными участниками: от разработчиков до бизнес-потребителей отчетности, — и повысить продуктивность аналитиков — от маркетинговых и продуктовых до BI.
Data Scientist же, напротив, принимает активное участие в стратегии компании и извлечении инсайтов, принятии решений, внедрении алгоритмов автоматизации, моделирования и генерации ценности из данных.

Работа с данными подчиняется принципу GIGO (garbage in — garbage out): если аналитики и дата-сайентисты имеют дело с неподготовленными и потенциально некорректными данными, то результаты даже с помощью самых изощрённых алгоритмов анализа будут неверны.
Инженеры данных решают эту проблему, выстраивая пайплайны по обработке, очистке и трансформации данных и позволяя дата-сайентисту работать уже с качественными данными.
На рынке много инструментов для работы с данными, которые покрывают каждый из этапов: от появления данных до вывода на дашборд для совета директоров. И важно, чтобы решение об их использовании принималось инженером, — не потому, что это модно, а потому что он действительно поможет в работе остальным участникам процесса.
Условно: если компании нужно подружить BI и ETL — загрузку данных и обновления отчётов, вот типичный legacy-фундамент, с которым придётся иметь дело Data Engineer (хорошо, если в команде кроме него будет ещё и архитектор).
Обязанности Data Engineer
- Разработка, построение и обслуживание инфраструктуры работы с данными.
- Обработка ошибок и создание надёжных конвейеров обработки данных.
- Приведение неструктурированных данных из различных динамических источников к виду, необходимому для работы аналитиков.
- Предоставление рекомендаций по повышению консистентности и качества данных.
- Обеспечение и поддержка архитектуры данных, используемой дата- сайентистами и аналитиками данных.
- Обработка и хранение данных последовательно и эффективно в распределенном кластере на десятки или сотни серверов.
- Оценка технических компромиссов инструментов для создания простых, но надежных архитектур, которые смогут пережить сбои.
- Контроль и поддержка потоков данных и связанных систем (настройка мониторинга и алертов).
Существует ещё одна специализация внутри траектории Data Engineer — ML engineer. Если коротко, то такие инженеры специализируются на доведении моделей машинного обучения до промышленного внедрения и использования. Зачастую модель, поступившая от дата-сайентиста, является частью исследования и может не заработать в боевых условиях.
Обязанности Data Scientist
- Извлечение признаков из данных для применения алгоритмов машинного обучения.
- Использование различных инструментов машинного обучения для прогнозирования и классификации паттернов в данных.
- Повышение производительности и точности алгоритмов машинного обучения за счет тонкой настройки и оптимизации алгоритмов.
- Формирование «сильных» гипотез в соответствии со стратегией компании, которые необходимо проверить.
И Data Engineer, и Data Scientist объединяет ощутимый вклад в развитие культуры работы с данными, с помощью которой компания может получать дополнительную прибыль или сокращать издержки.
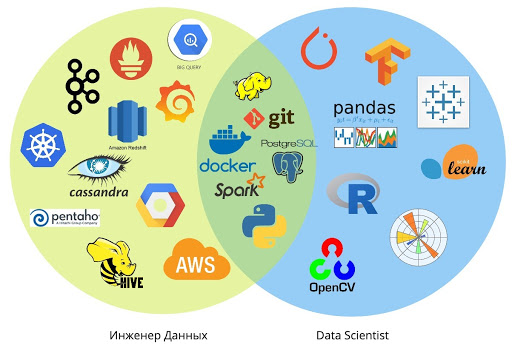
С какими языками и инструментами работают инженеры и сайентисты
Сегодня ожидания от специалистов по обработке данных изменились. Раньше инженеры собирали большие SQL-запросы, вручную писали MapReduce и обрабатывали данные с помощью таких инструментов, как Informatica ETL, Pentaho ETL, Talend.
В 2020 году специалисту не обойтись без знания Python и современных инструментов проведения вычислений (например Airflow), понимания принципов работы с облачными платформами (использования их для экономии на «железе», при соблюдении принципов безопасности).
SAP, Oracle, MySQL, Redis — это традиционные для инженера данных инструменты в больших компаниях. Они хороши, но стоимость лицензий настолько высока, что учиться работать с ними имеет смысл только в промышленных проектах. При этом есть бесплатная альтернатива в виде Postgres — он бесплатный и подходит не только для обучения.

Исторически часто встречается запрос на Java и Scala, хотя по мере развития технологий и подходов эти языки отходят на второй план.
Тем не менее, хардкорная BigData: Hadoop, Spark и остальной зоопарк — это уже не обязательное условие для инженера данных, а разновидность инструментов для решения задач, которые не решить традиционным ETL.
В тренде — сервисы для использования инструментов без знания языка, на котором они написаны (например, Hadoop без знания Java), а также предоставление готовых сервисов для обработки потоковых данных (распознавание голоса или образов на видео).
Популярны промышленные решения от SAS и SPSS, при этом Tableau, Rapidminer, Stata и Julia также широко используются дата-сайентистами для локальных задач.

Возможность самим строить пайплайны появилась у аналитиков и дата-сайентистов всего пару лет назад: например, уже можно относительно несложными скриптами направлять данные в хранилище на основе PostgreSQL.
Обычно использование конвейеров и интегрированных структур данных остаётся в ведении дата-инженеров. Но сегодня как никогда силён тренд на Т-образных специалистов — с широкими компетенциями в смежных областях, ведь инструменты постоянно упрощаются.
Зачем Data Engineer и Data Scientist работать вместе
Работая в тесном сотрудничестве с инженерами, Data Scientist могут сосредоточиться на исследовательской части, создавая готовые к работе алгоритмы машинного обучения.
А инженеры — сфокусироваться на масштабируемости, повторном использовании данных и гарантировать, что пайплайны ввода и вывода данных в каждом отдельно взятом проекте соответствуют глобальной архитектуре.
Такое разделение обязанностей обеспечивает согласованность действий между группами специалистов, работающими над разными проектами машинного обучения.
Сотрудничество помогает эффективно создавать новые продукты. Скорость и качество достигаются, благодаря балансу между созданием сервиса для всех (глобальное хранилище или интеграция дашбордов) и реализацией каждой конкретной потребности или проекта (узкоспециализированный пайплайн, подключение внешних источников).
Тесная работа с дата-сайентистами и аналитиками помогает инженерам развивать аналитические и исследовательские навыки для написания более качественного кода. Улучшается обмен знаниями между пользователями хранилищ и озёр данных, что делает проекты более гибкими и обеспечивает более устойчивые долгосрочные результаты.
В компаниях, которые ставят своей целью развитие культуры работы с данными и выстраивание бизнес-процессов на их основе, Data Scientist и Data Engineer дополняют друг друга и создают полноценную систему анализа данных.
В следующем материале расскажем о том, какое образование должно быть у Data Engineer и Data Scientists, какие навыки им нужно развивать и как устроен рынок.
От редакции Нетологии
Если присматриваетесь к профессии Data Engineer или Data Scientist, приглашаем изучить программы наших курсов:
- Профессия «Data-инженер».
- Профессия «Data Scientist».
