Привет, Хабр! В последнее время машинное обучение и data science в целом приобретают все большую популярность. Постоянно появляются новые библиотеки и для тренировки моделей машинного обучения может потребоваться совсем немного кода. В такой ситуации можно забыть, что машинное обучение — не самоцель, а инструмент для решения какой-либо задачи. Мало сделать работающую модель, не менее важно качественно презентовать результаты анализа или сделать работающий продукт.
 Я хотел бы рассказать о том, как создал проект по распознаванию рукописного ввода цифр с моделями, которые дообучаются на нарисованных пользователями цифрах. Используется две модели: простая нейронная сеть (FNN) на чистом numpy и сверточная сеть (CNN) на Tensorflow. Вы сможете узнать, как сделать практически с нуля следующее:
Я хотел бы рассказать о том, как создал проект по распознаванию рукописного ввода цифр с моделями, которые дообучаются на нарисованных пользователями цифрах. Используется две модели: простая нейронная сеть (FNN) на чистом numpy и сверточная сеть (CNN) на Tensorflow. Вы сможете узнать, как сделать практически с нуля следующее:
Для полного понимания проекта желательно знать как работает deep learning для распознавания изображений, иметь базовые знания о Flask и немного разбираться в HTML, JS и CSS.
После окончания экономического факультета МГУ я проработал 4 года в ИТ-консалтинге в сфере внедрения и развития ERP-систем. Работать было очень интересно, за эти годы изучил много полезного, но со временем пришло понимание того, что это не моё. После долгих раздумий я решил сменить сферу деятельности и перейти в направление машинного обучения (не из-за hype, а потому что действительно заинтересовался). Для этого уволился и примерно полгода вкалывал, самостоятельно изучая программирование, машинное обучение и прочее необходимое. После этого с трудом, но всё же нашёл работу в этом направлении. Стараюсь развиваться и прокачивать навыки в свободное время.
Несколько месяцев назад я прошёл специализацию Яндекса и МФТИ на Coursera. У неё есть свой team в Slack, и в апреле там самоорганизовалась группа для прохождения Стенфордского курса cs231n. Как это происходило — отдельная история, но ближе к делу. Важной частью курса является самостоятельный проект (40% оценки для студентов), в котором предоставляется полная свобода действий. Я не видел смысла делать что-то серьёзное и потом писать про это статью, но всё же душа просила достойно завершить курс. Примерно в это время мне на глаза попался сайт, где можно нарисовать цифру и две сетки на Tensorflow мгновенно распознают её и покажут результат. Я решил сделать что-то подобное, но со своими данными и моделями.
Здесь я расскажу о том, что и как я делал, чтобы реализовать проект. Объяснения будут достаточно подробными, чтобы было можно повторить сделанное, но некоторые базовые вещи я буду описывать кратко или пропускать.
Перед тем как приступать к чему-то большому, стоит это что-то распланировать. По ходу дела будут выясняться новые подробности и план придётся корректировать, но некое изначальное видение просто обязано быть.
На сбор данных у меня ушла чуть ли не половина всего времени, потраченного на проект. Дело в том, что я слабо был знаком с тем, что надо было сделать, поэтому приходилось двигаться методом проб и ошибок. Естественно, сложным было не само рисование, а создание сайта, на котором можно было бы рисовать цифры и куда-то сохранять их. Для этого мне потребовалось получше узнать Flask, поковыряться в Javascript, познакомиться с облаком Amazon S3 и узнать о Heroku. Всё это я описываю достаточно подробно, чтобы можно было это повторить, имея такой же уровень знаний, который был у меня на начало проекта.
Предварительно я нарисовал вот такую схему:

Сам сбор данных занял несколько дней, ну или несколько часов чистого времени. Я нарисовал 1000 цифр, примерно по 100 каждой (но не точно), пытался рисовать разными стилями, но, конечно, не мог охватить все возможные варианты почерка, что, впрочем, и не было целью.
Первый вариант сайта выглядел вот так:

В нём была только самая базовая функциональность:
Итак, теперь подробнее обо всём этом. Специально для статьи я сделал минимально рабочую версию сайта, на примере которой и буду рассказывать, как сделать вышеперечисленное: Сайт Код
Примечание: если сайт долгое время никем не открывался, то его запуск может занять до 20-30 секунд — издержки бесплатной версии хостинга. Эта ситуация актуальна и для полноценной версии сайта.
Flask — питоновский фреймворк для создания сайтов. На официальном сайте есть отличное введение. Есть разные способы использования Flask для получения и передачи информации, так в этом проекте я использовал AJAX. AJAX даёт возможность «фонового» обмена данными между браузером и веб-сервером, это позволяет не перезагружать страницы каждый раз при передаче данных.

Все файлы, используемые в проекте можно разделить на 2 неравные группы: меньшая часть необходима для того, чтобы приложение могло работать на Heroku, а все остальные задействованы непосредственно в работе сайта.
HTML-файлы должны храниться в папке «template», на данной стадии было достаточно иметь один. В шапке документа и в конце тега body находятся ссылки на файлы js и css. Сами эти файлы должны находиться в папке «static».
Теперь подробнее о том, как работает рисование на canvas и сохранение рисунка.
Canvas — это двухмерный элемент HTML5 для рисования. Изображение может рисоваться скриптом или пользователь может иметь возможность рисовать, используя мышь (или касаясь сенсорного экрана).
Canvas задаётся в HTML следующим образом:
До этого я не был знаком с этим элементом HTML, поэтому мои изначальные попытки сделать возможность рисования были неудачными. Через некоторое время я нашёл работающий пример и позаимствовал его (ссылка есть в моём файле draw.js).
В интерфейсе есть ещё 4 элемента:
Содержимое canvas очищается, и он заливается белым цветом. Также статус становится пустым.
Сразу же после нажатия кнопки в поле статуса отбражается значение «connecting...». Затем изображение конвертируется в текстовую строку с помощью метода кодирования base64. Результат выглядит следующим образом:
Далее я беру значение активной радио-кнопки (по name='action' и по состоянию
Наконец, AJAX запрос отправляет закодированное изображение и лейбл в питон, а затем получает ответ. Я довольно много времени потратил на то, чтобы заставить работать эту конструкцию, постараюсь объяснить, что происходит в каждой строке.
Вначале указывается тип запроса — в данном случае «POST», то есть данные из JS передаются в python скрипт.
"/hook" — это куда передаются данные. Поскольку я использую Flask, то я могу в нужном декораторе указать "/hook" в качестве URL, и это будет означать, что именно функция в этом декораторе будет использоваться, когда запрос POST идут на этот URL. Подробнее об этом в разделе про Flask ниже.
Наконец,
Чтобы отвлечься хочу рассказать о небольшой проблеме, которая возникла в начале работы над проектом. Этот базовый сайт для обработки изображений почему-то загружался около минуты. Я пробовал минимизировать его, оставлять буквально несколько строк — ничто не помогало. В итоге благодаря консоли удалось выявить источник тормозов — антивирус.

Оказалось, что Касперский вставляет свой скрипт в мой сайт, что и приводило к неадекватно долгой загрузке. После отключения опции сайт стал грузиться мгновенно.
Теперь перейдём уже к тому, как данные из AJAX запроса попадают в python, и как изображение сохраняется.
Гайдов и статей по работе с Flask полно, поэтому я просто кратко опишу базовые вещи, уделю особое внимание строчкам, без которых код не работает, и, конечно, расскажу про остальной код, являющийся основой сайта.
А теперь можно поговорить о том, как работает облако Amazon и что можно с ним делать.
В python есть две библиотеки для работы с облаком Amazon: boto и boto3. Вторая — поновее и лучше поддерживается, но пока некоторые вещи удобнее делать, используя первую.
Теперь собственно говоря о коде. Пока речь пойдёт только о том, как сохранять файлы на Amazon. О получении данных с облака будет сказано немного позже.
Первым делом необходимо создать подключение к облаку. Для этого нужно указать Access Key ID, Secret Access Key и Region Host. Ключи мы уже сгенерили, но указывать их явно — это опасно. Такое можно делать только при тестировании кода локально. Я пару раз коммитил код на github с открыто указанными ключами — их крали в течение пары минут. Не повторяйте моих ошибок. Heroku предоставляет возможность хранить ключи и обращаться к ним по названиям — об этом чуть ниже. Region host — это значение endpoint из таблички с регионами.
После этого нужно подключиться к bucket — здесь уже вполне допустимо указывать имя напрямую.
Пришло время рассказать о том, как разместить сайт на Heroku. Heroku — облачная платформа, поддерживающая несколько языков, и позволяющая быстро и удобно разворачивать веб-приложения. Есть возможность использовать Postgres и много чего интересного. Вообще говоря, я мог бы хранить изображения, используя ресурсы Heroku, но мне нужно хранить разные типы данных, поэтому проще было использовать отдельное облако.
Heroku предлагает несколько ценовых планов, но для моего приложения (в том числе полноценного, а не этого маленького) вполне хватает бесплатного. Единственный минус — приложение «засыпает» через полчаса активности и при следующем запуске оно может потратить секунд 30 на «просыпание».
В сети можно найти много гайдов по разворачиванию приложений на Heroku (вот ссылка на официальный), но большинство из них использует консоль, а я предпочитаю пользоваться интерфейсами. К тому же это кажется мне значительно проще и удобнее.
Теперь можно запускать приложение и работать с ним. На этом описание сайта для сбора данных завершено. Дальше речь пойдёт об обработке данных и следующих стадиях проекта.
Я сохраняю нарисованные изображения как картинки в оригинальном формате, чтобы всегда можно было посмотреть их и попробовать разные варианты обработки.
Вот несколько примеров:

Идея обработки изображений для моего проекта следующая (похожая на mnist): нарисованная цифра масштабируется так, чтобы умещаться в квадрат 20х20, сохраняя пропорции, а затем помещается в центр белого квадрата размерами 28х28. Для этого необходимы следующие шаги:
Очевидно, что 1000 изображений — маловато для тренировки нейронной сети, а ведь часть из них нужно использовать для валидации моделей. Решением этой проблемы является аугментация данных — создание дополнительных изображений, которые помогут увеличить размер датасета. Вариантов аугментации много, но стоит использовать лишь те, которые релевантны для поставленной задачи. Я решил использовать масштабирование и повороты.
Люди могут рисовать цифры шире или уже, с большей или меньшей длиной. При изначальной обработке изображения масштабируются в квадрат 20х20 и одна сторона будет меньше другой. Я решил создавать 4 разных масштабирования — 4 варианта комбинаций двух длин сторон.
Кроме того цифры могут рисоваться с разным наклоном. Я решил, что максимальный возможный наклон — 30 градусов в ту или иную сторону; при использовании шага в 5 градусов, получается 12 разных вариантов. Чтобы было не слишком много изображений, из этих 12 случайным образом выбираются 6.
Пример аугментации:

В итоге получилось 800 * 24 = 19200 изображений в тренировочном датасете и 200 осталось для валидации. Теперь можно выбирать архитектуру нейронных сетей и тренировать их.
Первой из сетей является обычная feed forward neural net. Я использовал структуру, предложенную в cs231n, и она успешно сработала.

Код работает следующим образом:
При начале работе с сетью необходимо задать размеры всех трёх слоёв:
При тренировке необходимо указать большее количество параметров и данных:
Благодаря тому, что тренировка возвращает историю изменения loss и точности на тренировочных и валидационных данных, строить графики довольно просто:

Выбор оптимальных параметров — больная тема. Переобучение, недообучение, предсказание одного и того же класса для разных данных — проблем, которые могут возникнуть при тренировке сети полно. Соответственно возникает вопрос подбора хороших параметров. Здесь я сразу решил, что не гонюсь за максимальной точностью, и разница в несколько процентов не является критичной при построении модели. Напомню, что важной частью проекта является дотренировка моделей, а это значит, что точность всё равно будет изменяться.
Тем не менее всё же хочется получить приличную точность, а значит надо приложить усилия. Я решил идти методом простого перебора параметров. Для этого на глаз были определены возможные значения learning rate, regularization, количества нейронов в скрытом слое, количества эпох и размера мини-батча; для каждой комбинации сеть тренировалась, и запоминались точности на тренировочном и валидационном датасетах. Модель с наивысшей точностью считалась лучшей.
Точность наилучшей модели была хорошей, казалось бы всё неплохо, но я чувствовал, что что-то не так. Дело в том, что количество итераций было небольшим, learning rate оставалась довольно высокой и точность модели была весьма нестабильной. Я решил привнести в параметры модели некоторую логику. Размер мини-батча определялся на глаз, но ведь это не совсем корректно в моём случае: если я планирую дообучение, то модель должна уметь тренироваться на 1 новом изображении. 1 изображение означает 24 аугментированных, исходя из этого было решено попробовать сделать размер мини-батча таким же. Вместе с этим я увеличил количество эпох до 24.
Кроме того мне захотелось узнать точность предсказаний моей модели на MNIST, так что я добавил в код сохранение результатов предсказания на MNIST.
В итоге получился такой вот процесс тренировки:

По графику видно, что можно было бы ограничиться ~10 эпохами, но я решил потренировать модель подольше.
Думаю, что сразу заметно, что точность на MNIST довольно низка. Я было забеспокоился, но подумал о том, что наверняка собранные мной данные и данные MNIST могут различаться. Чтобы проверить это я взял архитектуру CNN из официального гайда Tensorflow для MNIST и натренировал её. На тестовой части MNIST точность была 99%+ (как и ожидалось), а вот на моих данных точность оказалась значительно ниже: 78.5% на неаугментированных и 63.35% на аугментированных. Исходя из этого я решил, что мои данные и MNIST действительно различаются, а моя модель достаточно хороша и не стоит пытаться оптимизировать её для предсказаний на MNIST.
Впрочем, я всё же попытался улучшить модель:
Ничего из этого не смогло значительно увеличить точность модели. Наверное, из имеющихся данных было проблематично извлечь больше информации.
Сохранение весов этой модели довольно просто:
Пришло время перейти к следующему этапу.
Реализация возможности дообучения оказалась до удивления простой. Изменения в коде были следующими:
Я потратил некоторое время на проверку работоспособности этих изменений, на проверку точности — не станет ли она изменяться слишком резко, а также на выбор learning rate.
Выбор learning rate был самым сложным. Изначальное значение было 0.1, а после 24 эпох 0.1 x (0.95 ^ 24). Проблема в том, что это значение использовалось для всей эпохи — 800 итераций. Если использовать это значение, то каждое новое изображение может чувствительно изменять веса. Я пробовал много разных значений и остановился на 0.1 x (0.95 ^ 24) / 32. В итоге одно изображение не сможет значительно изменить веса, но несколько изображений постепенно приведут к заметным изменениям.
Вообще говоря, после создания FNN я занялся созданием рабочей версии сайта, но после того как я сделал CNN, сайт пришлось немного модифицировать, так что значительно удобнее поговорить вначале о CNN, а потом уже о сайте.
При создании архитектуры CNN я опирался на cs231n и вариант из гайда Tenforlow для MNIST, но в итоге модифицировал под свои нужды.

Поскольку используется Tensorflow, код имеет структуру, значительно отличающуюся от FNN на numpy.
Код работает следующим образом:
Загрузка MNIST для TF реализована просто и удобно:
Тренировочные и валидационные данные подготавливаются также, как и для FNN, лишь с небольшим нюансом из-за того, что модель предполагает другие измерения у данных:
Параметры CNN такие же как и в FNN, просто задаются немного по-другому. Из-за того, что CNN тренируется дольше, я пробовал меньше комбинаций параметров. Некоторые из комбинаций давали нестабильные решения, например такие:

Оптимальный же вариант был таким:

Очевидно, что нет смысла тренировать модель так долго, поэтому я перезапустил тренировку и остановился на ~100 эпохах.
Изменения в коде для дотренировки CNN были примерно такими же, как и для дотренировки FNN: передача весов в модель, 1 шаг, метод предсказания возвращает топ-3 предсказания и их вероятности.
Некоторое время опять же ушло на подбор learning rate. В итоге я остановился на 0.00001, что в 100 раз меньше оригинального значения. Впрочем, проверить успешность этого значения было проблематично. Надеюсь, что время покажет корректность или ошибку такого решения.
Наконец пришло время сделать сам сайт (первичный вариант с рисованием картинок не считается). Во-первых, нужен был приличный дизайн, для этого я взял один из шаблонов bootstrap. Использовать эти шаблоны просто: в архиве есть html с примером страницы и css, js для верстки. Кроме того, мне нужна была таблица для отображения результатов предсказания, впрочем это было несложно.
После этого нужно было прикрутить основную функциональность. Предварительная схема выглядела вот так:

Скрипт main.py остался неизменным, зато в functions.py было много добавлений.
При начальной загрузке сайта стоит сразу «запустить» модели, чтобы можно было сразу делать предсказания. Для FNN это проще — веса прямо можно передать в модель, поэтому в
Оригинальные веса не меняются, поэтому они лежат в папке tmp и грузятся напрямую (так как они лежат в папке и не изменяются, система их не трогает при завершении сессии). Веса для второй модели необходимо обновлять, поэтому они находятся в облаке Amazon. Загружаются они, используя метод load_weights_amazon
Код для получения файлов с Amazon отличается от кода для загрузки: регион не нужен, а ключи надо задавать явно (то есть нельзя, например, написать просто
В Tensorflow мне не удалось реализовать загрузку весов подобным образом, поэтому они грузятся в момент предсказания. В первый раз это занимает больше времени, при следующих предсказаниям Tensorflow работает быстрее.
При нажатии кнопки предсказания нарисованная цифра отправляется из JS в Python и идёт в метод
После этого инициализируются все 4 модели. Веса для FNN уже загружены, поэтому они могут быстро сделать предсказания.
В CNN помимо обработанного изображения передаётся параметр для определения того, какую модель использовать — оригинальную или нет. Модели используют соответствующие веса и делают предсказания.
Теперь есть 4 модели и их предсказания. Что же показывать пользователю? Для этого есть отдельный метод
JS отображает основное предсказание в соответствующем поле, а более подробные предсказания от каждой модели — в таблице.
При тренировке модели происходит следующее:
Теперь стоит подробнее поговорить об интерфейсе. Основные активные элементы следующие:
В файле JS можно увидеть как при нажатии тех или иных кнопок появляются/скрываются релевантные элементы интерфейса: для этого
На этом основная часть работы над проектом была завершена, оставалось сделать ряд улучшений, которые были необязательны, но желательны.
23 июля я «официально запустил» свой сайт и выложил ссылку на нескольких ресурсах. Было много положительных отзывов. Кроме того я получил несколько интересных идей и вообще понял, что не все люди смотрят на сайт так, как я предполагал (что неудивительно). На основе этих отзывов я слегка модифицировал интерфейс и при предсказании добавил возможность указать, что нарисованное изображение не является цифрой, ибо многие пробовали рисовать не цифры или спрашивали о том, может ли модель определять, что нарисована «не цифра». Об этом в следующем разделе.
Работа проекта на телефонах была с одной стороны вполне успешна — это работало. Но были 2 проблемы: иногда при рисовании экран прокручивается, побороть это пока не получается; и в коде с mozilla начало и завершение линии отмечалось кружками и квадратами. Я не сразу понял, что это может мешать предсказаниям, благо, что эту проблему было легко устранить.
Ещё один интересный момент — люди часто рисуют цифры, но не нажимают кнопки для подтверждения/опровержения предсказания (многие их тех, кому я показывал, поступали так), наверное, это уменьшает количество «положительных» примеров.
Ну а теперь немного забавного: что именно рисуют люди. К сожалению, я не сразу стал сразу собирать нарисованные картинки, но за последние 2,5 недели их было больше тысячи (это только те, которые сохранялись при дотренировке моделей). Вот примеры самых необычных цифр… или вообще не цифр:

Скорее всего тренировка на подобных изображениях приносит больше вреда чем пользы.
По итогам ~месяца работы сайта, а также обсуждений проекта (в том числе в slack ODS) появился ряд идей по улучшению проекта. Скорее всего этот проект останется в том виде, в каком он есть, но можно сделать новый с учётом этих идей.
В целом я очень доволен получившимся проектом. Изучил много нового и приобрёл полезные навыки. Смог осуществить полный процесс от создания плана и сбора данных до запуска. Получил хорошие идеи на будущее. И вообще это было весьма интересно. Считаю, что для тех, кто решил начать карьеру в data science и машинном обучении, подобные самостоятельные проекты являются одним из лучших способов освоения материала.
Я хотел бы рассказать о том, как создал проект по распознаванию рукописного ввода цифр с моделями, которые дообучаются на нарисованных пользователями цифрах. Используется две модели: простая нейронная сеть (FNN) на чистом numpy и сверточная сеть (CNN) на Tensorflow. Вы сможете узнать, как сделать практически с нуля следующее:- создать простой сайт с использованием Flask и Bootstrap;
- разместить его на платформе Heroku;
- реализовать сохранение и загрузку данных с помощью облака Amazon s3;
- собрать собственный датасет;
- натренировать модели машинного обучения (FNN и CNN);
- сделать возможность дообучения этих моделей;
- сделать сайт, который сможет распознавать нарисованные изображения;
Для полного понимания проекта желательно знать как работает deep learning для распознавания изображений, иметь базовые знания о Flask и немного разбираться в HTML, JS и CSS.
Немного обо мне
После окончания экономического факультета МГУ я проработал 4 года в ИТ-консалтинге в сфере внедрения и развития ERP-систем. Работать было очень интересно, за эти годы изучил много полезного, но со временем пришло понимание того, что это не моё. После долгих раздумий я решил сменить сферу деятельности и перейти в направление машинного обучения (не из-за hype, а потому что действительно заинтересовался). Для этого уволился и примерно полгода вкалывал, самостоятельно изучая программирование, машинное обучение и прочее необходимое. После этого с трудом, но всё же нашёл работу в этом направлении. Стараюсь развиваться и прокачивать навыки в свободное время.
Зарождение идеи
Несколько месяцев назад я прошёл специализацию Яндекса и МФТИ на Coursera. У неё есть свой team в Slack, и в апреле там самоорганизовалась группа для прохождения Стенфордского курса cs231n. Как это происходило — отдельная история, но ближе к делу. Важной частью курса является самостоятельный проект (40% оценки для студентов), в котором предоставляется полная свобода действий. Я не видел смысла делать что-то серьёзное и потом писать про это статью, но всё же душа просила достойно завершить курс. Примерно в это время мне на глаза попался сайт, где можно нарисовать цифру и две сетки на Tensorflow мгновенно распознают её и покажут результат. Я решил сделать что-то подобное, но со своими данными и моделями.
Основная часть
Здесь я расскажу о том, что и как я делал, чтобы реализовать проект. Объяснения будут достаточно подробными, чтобы было можно повторить сделанное, но некоторые базовые вещи я буду описывать кратко или пропускать.
Планирование проекта
Перед тем как приступать к чему-то большому, стоит это что-то распланировать. По ходу дела будут выясняться новые подробности и план придётся корректировать, но некое изначальное видение просто обязано быть.
- Для любого проекта по машинному обучению одним из основополагающих моментов является вопрос о том, какие данные использовать и где их взять. Датасет MNIST активно используется в задачах распознавация цифр, и именно поэтому я не захотел его использовать. В интернете можно найти примеры подобных проектов, где модели натренированы на MNIST (например вышеупомянутый), мне же хотелось сделать что-то новое. И, наконец, мне казалось, что многие из цифр в MNIST далеки от реальности — при просмотре датасета я встречал много таких вариантов, которые сложно представить в реальности (если только у человека совсем уж жуткий почерк). Плюс рисование цифр в браузере мышкой несколько отличается от их написания ручкой. Как следствие я решил собрать собственный датасет;
- Следующий (а точнее одновременный) шаг — это создание сайта для сбора данных. На тот момент у меня имелись базовые знания Flask, а также HTML, JS и CSS. Поэтому я и решил делать сайт на Flask, а в качестве хостинга была выбрана платформа Heroku, как позволяющая быстро и просто захостить маленький сайт;
- Далее предстояло создать сами модели, которые должны делать основную работу. Этот этап казался самым простым, поскольку после cs231n имелся достаточный опыт создания архитектур нейронных сетей для распознавания изображений. Предварительно хотелось сделать несколько моделей, но в дальнейшем решил остановиться на двух — FNN и CNN. Кроме того, нужно было сделать возможность дотренировки этих моделей, некоторые идеи на этот счёт у меня уже были;
- После подготовки моделей следует придать сайту приличный вид, как-то отображать предсказания, дать возможность оценивать корректность ответа, немного описать функционал и сделать ряд других мелких и не очень вещей. На этапе планирования я не стал уделять много времени на размышления об этом, просто составил список;
Сбор данных
На сбор данных у меня ушла чуть ли не половина всего времени, потраченного на проект. Дело в том, что я слабо был знаком с тем, что надо было сделать, поэтому приходилось двигаться методом проб и ошибок. Естественно, сложным было не само рисование, а создание сайта, на котором можно было бы рисовать цифры и куда-то сохранять их. Для этого мне потребовалось получше узнать Flask, поковыряться в Javascript, познакомиться с облаком Amazon S3 и узнать о Heroku. Всё это я описываю достаточно подробно, чтобы можно было это повторить, имея такой же уровень знаний, который был у меня на начало проекта.
Предварительно я нарисовал вот такую схему:
Сам сбор данных занял несколько дней, ну или несколько часов чистого времени. Я нарисовал 1000 цифр, примерно по 100 каждой (но не точно), пытался рисовать разными стилями, но, конечно, не мог охватить все возможные варианты почерка, что, впрочем, и не было целью.
Создание первой версии сайта (для сбора данных)
Первый вариант сайта выглядел вот так:
В нём была только самая базовая функциональность:
- канвас для рисования;
- радио-кнопки для выбора лейбла;
- кнопки для сохранения картинок и очистки канваса;
- поле, в котором писалось успешно ли было сохранение;
- сохранение картинок на облаке Amazon;
Итак, теперь подробнее обо всём этом. Специально для статьи я сделал минимально рабочую версию сайта, на примере которой и буду рассказывать, как сделать вышеперечисленное: Сайт Код
Примечание: если сайт долгое время никем не открывался, то его запуск может занять до 20-30 секунд — издержки бесплатной версии хостинга. Эта ситуация актуальна и для полноценной версии сайта.
Кратко о Flask
Flask — питоновский фреймворк для создания сайтов. На официальном сайте есть отличное введение. Есть разные способы использования Flask для получения и передачи информации, так в этом проекте я использовал AJAX. AJAX даёт возможность «фонового» обмена данными между браузером и веб-сервером, это позволяет не перезагружать страницы каждый раз при передаче данных.
Структура проекта
Все файлы, используемые в проекте можно разделить на 2 неравные группы: меньшая часть необходима для того, чтобы приложение могло работать на Heroku, а все остальные задействованы непосредственно в работе сайта.
HTML и JS
HTML-файлы должны храниться в папке «template», на данной стадии было достаточно иметь один. В шапке документа и в конце тега body находятся ссылки на файлы js и css. Сами эти файлы должны находиться в папке «static».
HTML-файл
<!doctype html>
<html>
<head>
<meta charset="utf-8" />
<title>Handwritten digit recognition</title>
<link rel="stylesheet" type="text/css" href="static/bootstrap.min.css">
<link rel="stylesheet" type="text/css" href="static/style.css">
</head>
<body>
<div class="container">
<div>
Здесь можно порисовать.
<canvas id="the_stage" width="200" height="200">fsf</canvas>
<div>
<button type="button" class="btn btn-default butt" onclick="clearCanvas()"><strong>clear</strong></button>
<button type="button" class="btn btn-default butt" id="save" onclick="saveImg()"><strong>save</strong></button>
</div>
<div>
Please select one of the following
<input type="radio" name="action" value="0" id="digit">0
<input type="radio" name="action" value="1" id="digit">1
<input type="radio" name="action" value="2" id="digit">2
<input type="radio" name="action" value="3" id="digit">3
<input type="radio" name="action" value="4" id="digit">4
<input type="radio" name="action" value="5" id="digit">5
<input type="radio" name="action" value="6" id="digit">6
<input type="radio" name="action" value="7" id="digit">7
<input type="radio" name="action" value="8" id="digit">8
<input type="radio" name="action" value="9" id="digit">9
</div>
</div>
<div class="col-md-6 column">
<h3>result:</h3>
<h2 id="rec_result"></h2>
</div>
</div>
<script src="static/jquery.min.js"></script>
<script src="static/bootstrap.min.js"></script>
<script src="static/draw.js"></script>
</body></html>Теперь подробнее о том, как работает рисование на canvas и сохранение рисунка.
Canvas — это двухмерный элемент HTML5 для рисования. Изображение может рисоваться скриптом или пользователь может иметь возможность рисовать, используя мышь (или касаясь сенсорного экрана).
Canvas задаётся в HTML следующим образом:
<canvas id="the_stage" width="200" height="200"> </canvas>До этого я не был знаком с этим элементом HTML, поэтому мои изначальные попытки сделать возможность рисования были неудачными. Через некоторое время я нашёл работающий пример и позаимствовал его (ссылка есть в моём файле draw.js).
Код для рисования
var drawing = false;
var context;
var offset_left = 0;
var offset_top = 0;
function start_canvas () {
var canvas = document.getElementById ("the_stage");
context = canvas.getContext ("2d");
canvas.onmousedown = function (event) {mousedown(event)};
canvas.onmousemove = function (event) {mousemove(event)};
canvas.onmouseup = function (event) {mouseup(event)};
for (var o = canvas; o ; o = o.offsetParent) {
offset_left += (o.offsetLeft - o.scrollLeft);
offset_top += (o.offsetTop - o.scrollTop);
}
draw();
}
function getPosition(evt) {
evt = (evt) ? evt : ((event) ? event : null);
var left = 0;
var top = 0;
var canvas = document.getElementById("the_stage");
if (evt.pageX) {
left = evt.pageX;
top = evt.pageY;
} else if (document.documentElement.scrollLeft) {
left = evt.clientX + document.documentElement.scrollLeft;
top = evt.clientY + document.documentElement.scrollTop;
} else {
left = evt.clientX + document.body.scrollLeft;
top = evt.clientY + document.body.scrollTop;
}
left -= offset_left;
top -= offset_top;
return {x : left, y : top};
}
function
mousedown(event) {
drawing = true;
var location = getPosition(event);
context.lineWidth = 8.0;
context.strokeStyle="#000000";
context.beginPath();
context.moveTo(location.x,location.y);
}
function
mousemove(event) {
if (!drawing)
return;
var location = getPosition(event);
context.lineTo(location.x,location.y);
context.stroke();
}
function
mouseup(event) {
if (!drawing)
return;
mousemove(event);
context.closePath();
drawing = false;
}
.
.
.
onload = start_canvas;
Как работает рисование
При загрузке страницы запускается функция start_canvas. Первые две строчки находят канвас как элемент с определенным id («the stage») и определяют его как двухмерное изображение. При рисовании на canvas есть 3 события: onmousedown, onmousemove и onmouseup. Есть ещё аналогичные события для касаний, но об этом позже.
onmousedown — происходит при клике на canvas. В этот момент задается ширина и цвет линии, а также определяется начальная точка рисования. На словах определение местоположения курсора звучит просто, но по факту это не совсем тривиально. Для нахождения точки используется функция getPosition() — она находит координаты курсора на странице и определяет координаты точки на canvas с учетом относительного положения canvas на странице и с учетом того, что страница может быть проскроллена. После нахождения точки context.beginPath() начинает путь рисования, а context.moveTo(location.x,location.y) «передвигает» этот путь к точке, которая была определена в момент клика.
onmousemove — следование за движением мышки при нажатой левой клавише. В самом начале сделана проверка на то, что клавиша нажата (то есть drawing = true), если же нет — рисование не осуществляется. context.lineTo() создаёт линию по траектории движения мыши, а context.stroke() непосредственно рисует её.
onmouseup — происходит при отпускании левой клавиши мыши. context.closePath() завершает рисование линии.
onmousedown — происходит при клике на canvas. В этот момент задается ширина и цвет линии, а также определяется начальная точка рисования. На словах определение местоположения курсора звучит просто, но по факту это не совсем тривиально. Для нахождения точки используется функция getPosition() — она находит координаты курсора на странице и определяет координаты точки на canvas с учетом относительного положения canvas на странице и с учетом того, что страница может быть проскроллена. После нахождения точки context.beginPath() начинает путь рисования, а context.moveTo(location.x,location.y) «передвигает» этот путь к точке, которая была определена в момент клика.
onmousemove — следование за движением мышки при нажатой левой клавише. В самом начале сделана проверка на то, что клавиша нажата (то есть drawing = true), если же нет — рисование не осуществляется. context.lineTo() создаёт линию по траектории движения мыши, а context.stroke() непосредственно рисует её.
onmouseup — происходит при отпускании левой клавиши мыши. context.closePath() завершает рисование линии.
В интерфейсе есть ещё 4 элемента:
- «Поле» с текущим статусом. JS обращается к нему по id (rec_result) и отображает текущий статус. Статус либо пуст, либо показывает, что изображение сохраняется, либо показывает название сохранённого изображения.
<div class="col-md-6 column">
<h3>result:</h3>
<h2 id="rec_result"></h2>
</div>
- Радио-кнопки для выбора цифры. На этапе сбора данных нарисованным цифрам нужно как-то присваивать лейблы, для этого и были добавлены 10 кнопок. Кнопки задаются вот таким способом:
<input type="radio" name="action" value="0" id="digit">0
где на месте 0 стоит соответствующая цифра. Name используется для того, чтобы JS мог получить значение активной радио-кнопки (value); - Кнопка для очищения canvas — чтобы можно было нарисовать новую цифру.
<button type="button" class="btn btn-default butt" onclick="clearCanvas()"><strong>clear</strong></button>
При нажатии на эту кнопку происходит следующее:
function draw() {
context.fillStyle = '#ffffff';
context.fillRect(0, 0, 200, 200);
}
function clearCanvas() {
context.clearRect (0, 0, 200, 200);
draw();
document.getElementById("rec_result").innerHTML = "";
}
Содержимое canvas очищается, и он заливается белым цветом. Также статус становится пустым.
- Наконец, кнопка сохранения нарисованного изображения. Она вызывает следующую функцию Javascript:
function saveImg() {
document.getElementById("rec_result").innerHTML = "connecting...";
var canvas = document.getElementById("the_stage");
var dataURL = canvas.toDataURL('image/jpg');
var dig = document.querySelector('input[name="action"]:checked').value;
$.ajax({
type: "POST",
url: "/hook",
data:{
imageBase64: dataURL,
digit: dig
}
}).done(function(response) {
console.log(response)
document.getElementById("rec_result").innerHTML = response
});
}
Сразу же после нажатия кнопки в поле статуса отбражается значение «connecting...». Затем изображение конвертируется в текстовую строку с помощью метода кодирования base64. Результат выглядит следующим образом:
data:image/png;base64,%string%, где можно увидеть тип файла (image), расширение (png), кодирование base64 и сам стринг. Тут хочу заметить, что я слишком поздно заметил ошибку в моём коде. Мне следовало использовать 'image/jpeg' как аргумент для canvas.toDataURL(), но я сделал опечатку и в итоге изображения по факту были png.Далее я беру значение активной радио-кнопки (по name='action' и по состоянию
checked) и сохраняю в переменную dig.Наконец, AJAX запрос отправляет закодированное изображение и лейбл в питон, а затем получает ответ. Я довольно много времени потратил на то, чтобы заставить работать эту конструкцию, постараюсь объяснить, что происходит в каждой строке.
Вначале указывается тип запроса — в данном случае «POST», то есть данные из JS передаются в python скрипт.
"/hook" — это куда передаются данные. Поскольку я использую Flask, то я могу в нужном декораторе указать "/hook" в качестве URL, и это будет означать, что именно функция в этом декораторе будет использоваться, когда запрос POST идут на этот URL. Подробнее об этом в разделе про Flask ниже.
data — это данные, которые передаются в запросе. Вариантов передачи данных много, в данном случае я задаю значение и имя через которое можно получить это значение.Наконец,
done() — это то, что происходит при успешном выполнении запроса. Мой AJAX запрос возвращает некий ответ (а точнее текст с именем сохраненного изображения), этот ответ вначале выводится в консоль (для отладки), а затем отображается в поле статуса.Чтобы отвлечься хочу рассказать о небольшой проблеме, которая возникла в начале работы над проектом. Этот базовый сайт для обработки изображений почему-то загружался около минуты. Я пробовал минимизировать его, оставлять буквально несколько строк — ничто не помогало. В итоге благодаря консоли удалось выявить источник тормозов — антивирус.
Оказалось, что Касперский вставляет свой скрипт в мой сайт, что и приводило к неадекватно долгой загрузке. После отключения опции сайт стал грузиться мгновенно.
Flask и сохранение изображения
Теперь перейдём уже к тому, как данные из AJAX запроса попадают в python, и как изображение сохраняется.
Гайдов и статей по работе с Flask полно, поэтому я просто кратко опишу базовые вещи, уделю особое внимание строчкам, без которых код не работает, и, конечно, расскажу про остальной код, являющийся основой сайта.
main.py
__author__ = 'Artgor'
from functions import Model
from flask import Flask, render_template, request
from flask_cors import CORS, cross_origin
import base64
import os
app = Flask(__name__)
model = Model()
CORS(app, headers=['Content-Type'])
@app.route("/", methods=["POST", "GET", 'OPTIONS'])
def index_page():
return render_template('index.html')
@app.route('/hook', methods = ["GET", "POST", 'OPTIONS'])
def get_image():
if request.method == 'POST':
image_b64 = request.values['imageBase64']
drawn_digit = request.values['digit']
image_encoded = image_b64.split(',')[1]
image = base64.decodebytes(image_encoded.encode('utf-8'))
save = model.save_image(drawn_digit, image)
print('Done')
return save
if __name__ == '__main__':
port = int(os.environ.get("PORT", 5000))
app.run(host='0.0.0.0', port=port, debug=False)
functions.py
__author__ = 'Artgor'
from codecs import open
import os
import uuid
import boto3
from boto.s3.key import Key
from boto.s3.connection import S3Connection
class Model(object):
def __init__(self):
self.nothing = 0
def save_image(self, drawn_digit, image):
filename = 'digit' + str(drawn_digit) + '__' + str(uuid.uuid1()) + '.jpg'
with open('tmp/' + filename, 'wb') as f:
f.write(image)
print('Image written')
REGION_HOST = 's3-external-1.amazonaws.com'
conn = S3Connection(os.environ['AWS_ACCESS_KEY_ID'],
os.environ['AWS_SECRET_ACCESS_KEY'],
host=REGION_HOST)
bucket = conn.get_bucket('testddr')
k = Key(bucket)
fn = 'tmp/' + filename
k.key = filename
k.set_contents_from_filename(fn)
print('Done')
return ('Image saved successfully with the name {0}'.format(filename))
Как работает код
Первым делом необходимо создать экземпляр Flask класса с дефолтным значением
Далее я создаю экземпляр класса для использования второго скрипта. Учитывая, что в нём всего одна функция, можно было бы обойтись без использования классов или вообще держать весь код в одном скрипте. Но я знал, что количество методов будет расти, поэтому решил сразу использовать такой вариант.
CORS (Cross-origin resource sharing) — технология, предоставляющая веб-страницам доступ к ресурсам другого домена. В данном приложении это используется для того, чтобы сохранять изображения на облаке Amazon. Я долго искал способ активировать эту настройку, а потом как сделать это проще. В итоге реализовал одной строчкой:
Далее используется декоратор
Замечу, что оба декоратора в качестве значения параметра method имеют список «POST», «GET», 'OPTIONS'. POST и GET используются для получения и передачи данных (указаны оба на всякий случай), OPTIONS необходим для передачи параметров, таких как CORS. По идее OPTIONS должен использоваться по умолчанию, начиная с версии Flask 0.6, но без его явного указания мне не удалось заставить код заработать.
Теперь поговорим о функции для получения изображения. Из JS в Python приходит 'request'. Это могут быть данные из формы, данные, полученные из AJAX или что-то другое. В моём случае это словарь с ключами и значениями, заданными в JS. Извлечение лейбла картинки тривиально, нужно просто взять значение словаря по ключу, а вот стринг с изображением необходимо обработать — взять часть, относящуюся к самому изображению (отбросив описание) и декодировать.
После этого вызывается функция из второго скрипта для сохранения изображения. Она возвращает стринг с названием сохраненного избражения, который после этого возвращается в JS и отображается на станице браузера.
Последняя часть кода необходима для работы приложения на heroku (взято из документации). О том, как разместить приложение на Heroku, будет подробно написано в соответствующем разделе.
Наконец, посмотрим, как именно сохраняется изображение. На текущий момент изображение хранится в переменной, но для сохранения изображения на облаке Amazon необходимо иметь файл, так что картинку нужно сохранить. Название картинки содержит её лейбл и уникальный id, генерящийся с помощью uuid. После этого картинка сохраняется во временную папку tmp и заливается на облако. Сразу скажу, что файл в папке tmp будет временным: heroku хранит новые/измененные файлы в течение сессии, а по её завершении удаляет файлы или откатывает изменения. Это позволяет не думать о необходимости очищения папки и вообще удобно, но именно из-за этого и приходится использовать облако.
app = Flask(__name__). Это будет основой приложения.Далее я создаю экземпляр класса для использования второго скрипта. Учитывая, что в нём всего одна функция, можно было бы обойтись без использования классов или вообще держать весь код в одном скрипте. Но я знал, что количество методов будет расти, поэтому решил сразу использовать такой вариант.
CORS (Cross-origin resource sharing) — технология, предоставляющая веб-страницам доступ к ресурсам другого домена. В данном приложении это используется для того, чтобы сохранять изображения на облаке Amazon. Я долго искал способ активировать эту настройку, а потом как сделать это проще. В итоге реализовал одной строчкой:
CORS(app, headers=['Content-Type']).Далее используется декоратор
route() — он определяет какая функция выполняется для какого URL. В основном скрипте есть 2 декоратора с функциями. Первый из них используется для главной страницы (поскольку указан адрес "/") и отображает «index.html». Второй же декоратор имеет адрес '"/hook"', а это значит, что именно в него передаются данные из JS (напомню, что там был указан такой же адрес).Замечу, что оба декоратора в качестве значения параметра method имеют список «POST», «GET», 'OPTIONS'. POST и GET используются для получения и передачи данных (указаны оба на всякий случай), OPTIONS необходим для передачи параметров, таких как CORS. По идее OPTIONS должен использоваться по умолчанию, начиная с версии Flask 0.6, но без его явного указания мне не удалось заставить код заработать.
Теперь поговорим о функции для получения изображения. Из JS в Python приходит 'request'. Это могут быть данные из формы, данные, полученные из AJAX или что-то другое. В моём случае это словарь с ключами и значениями, заданными в JS. Извлечение лейбла картинки тривиально, нужно просто взять значение словаря по ключу, а вот стринг с изображением необходимо обработать — взять часть, относящуюся к самому изображению (отбросив описание) и декодировать.
После этого вызывается функция из второго скрипта для сохранения изображения. Она возвращает стринг с названием сохраненного избражения, который после этого возвращается в JS и отображается на станице браузера.
Последняя часть кода необходима для работы приложения на heroku (взято из документации). О том, как разместить приложение на Heroku, будет подробно написано в соответствующем разделе.
Наконец, посмотрим, как именно сохраняется изображение. На текущий момент изображение хранится в переменной, но для сохранения изображения на облаке Amazon необходимо иметь файл, так что картинку нужно сохранить. Название картинки содержит её лейбл и уникальный id, генерящийся с помощью uuid. После этого картинка сохраняется во временную папку tmp и заливается на облако. Сразу скажу, что файл в папке tmp будет временным: heroku хранит новые/измененные файлы в течение сессии, а по её завершении удаляет файлы или откатывает изменения. Это позволяет не думать о необходимости очищения папки и вообще удобно, но именно из-за этого и приходится использовать облако.
А теперь можно поговорить о том, как работает облако Amazon и что можно с ним делать.
Интеграция с Amazon s3
В python есть две библиотеки для работы с облаком Amazon: boto и boto3. Вторая — поновее и лучше поддерживается, но пока некоторые вещи удобнее делать, используя первую.
Создание и настройка bucket в Amazon
Думаю, что регистрация аккаунта не вызовет никаких проблем. Важно не забыть сгенерить ключи для доступа с помощью библиотек (Access Key ID and Secret Access Key). В самом облаке можно создавать buckets, где и будут храниться файлы. По-русски buckets — ведра, что для меня звучит странно, так что предпочитаю использовать оригинальное название.
А вот теперь пошли нюансы.

При создании нужно указать имя, и тут необходимо соблюдать осторожность. Первоначально я использовал название, содержащее дефисы, но никак не мог подключиться к облаку. Оказалось, что некоторые отдельные символы действительно вызывают эту проблему. Есть способы обхода, но они работают не для всех. В итоге я стал использовать вариант названия с нижним подчеркиванием (digit_draw_recognize), с ним проблем не возникало.
Далее нужно указать регион. Можно выбирать практически любой, но при этом стоит руководствоваться вот этой табличкой.
Во-первых, нам понадобится Endpoint для выбранного региона, во-вторых, проще использовать регионы, поддерживающие 2 и 4 версии подписи, чтобы можно были использовать то, что удобно. Я выбрал US East (N. Virginia).
Остальные параметры при создании bucket можно не менять.
Ещё одним важным моментом является настройка CORS.

В настройку нужно внести следующий код:
Про эту настройку можно подробнее прочитать здесь и установить более мягкие/жесткие параметры. Изначально я думал, что нужно указать больше методов (а не только GET), но всё итак работает.
А вот теперь пошли нюансы.
При создании нужно указать имя, и тут необходимо соблюдать осторожность. Первоначально я использовал название, содержащее дефисы, но никак не мог подключиться к облаку. Оказалось, что некоторые отдельные символы действительно вызывают эту проблему. Есть способы обхода, но они работают не для всех. В итоге я стал использовать вариант названия с нижним подчеркиванием (digit_draw_recognize), с ним проблем не возникало.
Далее нужно указать регион. Можно выбирать практически любой, но при этом стоит руководствоваться вот этой табличкой.
Во-первых, нам понадобится Endpoint для выбранного региона, во-вторых, проще использовать регионы, поддерживающие 2 и 4 версии подписи, чтобы можно были использовать то, что удобно. Я выбрал US East (N. Virginia).
Остальные параметры при создании bucket можно не менять.
Ещё одним важным моментом является настройка CORS.
В настройку нужно внести следующий код:
<CORSConfiguration>
<CORSRule>
<AllowedOrigin>*</AllowedOrigin>
<AllowedMethod>GET</AllowedMethod>
<MaxAgeSeconds>3000</MaxAgeSeconds>
<AllowedHeader>Authorization</AllowedHeader>
</CORSRule>
</CORSConfiguration>
Про эту настройку можно подробнее прочитать здесь и установить более мягкие/жесткие параметры. Изначально я думал, что нужно указать больше методов (а не только GET), но всё итак работает.
Теперь собственно говоря о коде. Пока речь пойдёт только о том, как сохранять файлы на Amazon. О получении данных с облака будет сказано немного позже.
REGION_HOST = 's3-external-1.amazonaws.com'
conn = S3Connection(os.environ['AWS_ACCESS_KEY_ID'],
os.environ['AWS_SECRET_ACCESS_KEY'],
host=REGION_HOST)
bucket = conn.get_bucket('testddr')
k = Key(bucket)
fn = 'tmp/' + filename
k.key = filename
k.set_contents_from_filename(fn)
Первым делом необходимо создать подключение к облаку. Для этого нужно указать Access Key ID, Secret Access Key и Region Host. Ключи мы уже сгенерили, но указывать их явно — это опасно. Такое можно делать только при тестировании кода локально. Я пару раз коммитил код на github с открыто указанными ключами — их крали в течение пары минут. Не повторяйте моих ошибок. Heroku предоставляет возможность хранить ключи и обращаться к ним по названиям — об этом чуть ниже. Region host — это значение endpoint из таблички с регионами.
После этого нужно подключиться к bucket — здесь уже вполне допустимо указывать имя напрямую.
Key используется для работы с объектами в корзине. Для сохранения объекта нужно указать название файла (k.key), а затем вызвать k.set_contents_from_filename() с указанием пути к файлу, который нужно сохранить.Heroku
Пришло время рассказать о том, как разместить сайт на Heroku. Heroku — облачная платформа, поддерживающая несколько языков, и позволяющая быстро и удобно разворачивать веб-приложения. Есть возможность использовать Postgres и много чего интересного. Вообще говоря, я мог бы хранить изображения, используя ресурсы Heroku, но мне нужно хранить разные типы данных, поэтому проще было использовать отдельное облако.
Heroku предлагает несколько ценовых планов, но для моего приложения (в том числе полноценного, а не этого маленького) вполне хватает бесплатного. Единственный минус — приложение «засыпает» через полчаса активности и при следующем запуске оно может потратить секунд 30 на «просыпание».
В сети можно найти много гайдов по разворачиванию приложений на Heroku (вот ссылка на официальный), но большинство из них использует консоль, а я предпочитаю пользоваться интерфейсами. К тому же это кажется мне значительно проще и удобнее.
Размещение приложения на Heroku
Итак, к сути. Для подготовки приложения нужно создать несколько файлов:
Теперь можно начинать процесс создания приложения. На этот момент должен иметься аккаунт на heroku и подготовленный github-репозиторий.
Со страницы со списком приложений создаётся новое:

Указываем название и страну:

На вкладке «Deploy» выбираем подключение к Github:

Подключаемся и выбираем репозиторий:

Имеет смысл включить автоматическое обновление приложения на Heroku при каждом обновлении репозитория. И можно начинать развертывание:

Смотрим логи и надеемся, что всё прошло успешно:

Но ещё не всё готово, перед первым запуском приложения на вкладке настроек надо задать переменные — ключи для облака Amazon.

- необходима система контроля версий .git. Обычно она создаётся автоматически при создании репозитория github, но нужно проверить, что она действительно есть;
runtime.txt— в этом файле должна быть указана необходимая версия используемого языка программирования, в моём случае — python-3.6.1;Procfile— это файл без расширения. В нём указывается, какие команды должны запускаться на heroku. Здесь определяется тип процессаweb, что запускается (мой скрипт), и адрес:
web: python main.py runserver 0.0.0.0:5000
requirements.txt— список библиотек, которые будут установлены на Heroku. Лучше указывать нужные версии;- И последнее — в папке «tmp» должен лежать хоть один файл, иначе могут возникнуть проблемы с сохранением файлов в этой папке в процессе работы приложения;
Теперь можно начинать процесс создания приложения. На этот момент должен иметься аккаунт на heroku и подготовленный github-репозиторий.
Со страницы со списком приложений создаётся новое:
Указываем название и страну:
На вкладке «Deploy» выбираем подключение к Github:
Подключаемся и выбираем репозиторий:
Имеет смысл включить автоматическое обновление приложения на Heroku при каждом обновлении репозитория. И можно начинать развертывание:
Смотрим логи и надеемся, что всё прошло успешно:
Но ещё не всё готово, перед первым запуском приложения на вкладке настроек надо задать переменные — ключи для облака Amazon.
Теперь можно запускать приложение и работать с ним. На этом описание сайта для сбора данных завершено. Дальше речь пойдёт об обработке данных и следующих стадиях проекта.
Обработка изображений для моделей
Я сохраняю нарисованные изображения как картинки в оригинальном формате, чтобы всегда можно было посмотреть их и попробовать разные варианты обработки.
Вот несколько примеров:
Идея обработки изображений для моего проекта следующая (похожая на mnist): нарисованная цифра масштабируется так, чтобы умещаться в квадрат 20х20, сохраняя пропорции, а затем помещается в центр белого квадрата размерами 28х28. Для этого необходимы следующие шаги:
- найти границы изображения (граница имеет форму прямоугольника);
- найти высоту и ширину ограниченного прямоугольника;
- приравнять большую сторону к 20, а меньшую масштабировать так, чтобы сохранить пропорции;
- найти точку старта для рисования отмасштабированной цифры на квадрате 28х28 и нарисовать её;
- конвертировать в np.array, чтобы с данными можно было работать, и нормализовать;
Обработка изображения
# Считывание из файла
img = Image.open('tmp/' + filename)
# Нахождение границы
bbox = Image.eval(img, lambda px: 255-px).getbbox()
if bbox == None:
return None
# Оригинальные длины сторон
widthlen = bbox[2] - bbox[0]
heightlen = bbox[3] - bbox[1]
# Новые
if heightlen > widthlen:
widthlen = int(20.0 * widthlen / heightlen)
heightlen = 20
else:
heightlen = int(20.0 * widthlen / heightlen)
widthlen = 20
# Стартовая точка рисования
hstart = int((28 - heightlen) / 2)
wstart = int((28 - widthlen) / 2)
# Отмасштабированная картинка
img_temp = img.crop(bbox).resize((widthlen, heightlen), Image.NEAREST)
# Перенос на белый фон с центрированием
new_img = Image.new('L', (28,28), 255)
new_img.paste(img_temp, (wstart, hstart))
# Конвертация в np.array и нормализация
imgdata = list(new_img.getdata())
img_array = np.array([(255.0 - x) / 255.0 for x in imgdata])
Аугментация изображений
Очевидно, что 1000 изображений — маловато для тренировки нейронной сети, а ведь часть из них нужно использовать для валидации моделей. Решением этой проблемы является аугментация данных — создание дополнительных изображений, которые помогут увеличить размер датасета. Вариантов аугментации много, но стоит использовать лишь те, которые релевантны для поставленной задачи. Я решил использовать масштабирование и повороты.
Люди могут рисовать цифры шире или уже, с большей или меньшей длиной. При изначальной обработке изображения масштабируются в квадрат 20х20 и одна сторона будет меньше другой. Я решил создавать 4 разных масштабирования — 4 варианта комбинаций двух длин сторон.
Кроме того цифры могут рисоваться с разным наклоном. Я решил, что максимальный возможный наклон — 30 градусов в ту или иную сторону; при использовании шага в 5 градусов, получается 12 разных вариантов. Чтобы было не слишком много изображений, из этих 12 случайным образом выбираются 6.
Аугментация
# Считывание из файла
image = Image.open('tmp/' + filename)
# Списки для аугментированных изображений и их лейблов
ims_add = []
labs_add = []
# Углы, на которые может быть повернуто изображение
angles = np.arange(-30, 30, 5)
# Нахождение границы
bbox = Image.eval(image, lambda px: 255-px).getbbox()
# Оригинальные длины сторон
widthlen = bbox[2] - bbox[0]
heightlen = bbox[3] - bbox[1]
# Новые
if heightlen > widthlen:
widthlen = int(20.0 * widthlen/heightlen)
heightlen = 20
else:
heightlen = int(20.0 * widthlen/heightlen)
widthlen = 20
# Стартовая точка рисования
hstart = int((28 - heightlen) / 2)
wstart = int((28 - widthlen) / 2)
# 4 варианта масштабирования
for i in [min(widthlen, heightlen), max(widthlen, heightlen)]:
for j in [min(widthlen, heightlen), max(widthlen, heightlen)]:
# Отмасштабированная картинка
resized_img = image.crop(bbox).resize((i, j), Image.NEAREST)
# Перенос на белый фон с центрированием
resized_image = Image.new('L', (28,28), 255)
resized_image.paste(resized_img, (wstart, hstart))
# Случайный выбор 6 значений из 12.
angles_ = random.sample(set(angles), 6)
for angle in angles_:
# Поворот изображений
transformed_image = transform.rotate(np.array(resized_image),
angle, cval=255, preserve_range=True).astype(np.uint8)
labs_add.append(int(label))
# Преобразование в картинку для удобства
img_temp = Image.fromarray(np.uint8(transformed_image))
# Конвертация в np.array и нормализация
imgdata = list(img_temp.getdata())
normalized_img = [(255.0 - x) / 255.0 for x in imgdata]
ims_add.append(normalized_img)
Пример аугментации:
В итоге получилось 800 * 24 = 19200 изображений в тренировочном датасете и 200 осталось для валидации. Теперь можно выбирать архитектуру нейронных сетей и тренировать их.
FNN
Первой из сетей является обычная feed forward neural net. Я использовал структуру, предложенную в cs231n, и она успешно сработала.
Код для создания картинки
import matplotlib.pyplot as plt
#https://gist.github.com/anbrjohn/7116fa0b59248375cd0c0371d6107a59
def draw_neural_net(ax, left, right, bottom, top, layer_sizes, layer_text=None):
'''
:parameters:
- ax : matplotlib.axes.AxesSubplot
The axes on which to plot the cartoon (get e.g. by plt.gca())
- left : float
The center of the leftmost node(s) will be placed here
- right : float
The center of the rightmost node(s) will be placed here
- bottom : float
The center of the bottommost node(s) will be placed here
- top : float
The center of the topmost node(s) will be placed here
- layer_sizes : list of int
List of layer sizes, including input and output dimensionality
- layer_text : list of str
List of node annotations in top-down left-right order
'''
n_layers = len(layer_sizes)
v_spacing = (top - bottom)/float(max(layer_sizes))
h_spacing = (right - left)/float(len(layer_sizes) - 1)
ax.axis('off')
# Nodes
for n, layer_size in enumerate(layer_sizes):
layer_top = v_spacing*(layer_size - 1)/2. + (top + bottom)/2.
for m in range(layer_size):
x = n*h_spacing + left
y = layer_top - m*v_spacing
circle = plt.Circle((x,y), v_spacing/4.,
color='w', ec='k', zorder=4)
ax.add_artist(circle)
# Node annotations
if layer_text:
text = layer_text.pop(0)
plt.annotate(text, xy=(x, y), zorder=5, ha='center', va='center')
# Edges
for n, (layer_size_a, layer_size_b) in enumerate(zip(layer_sizes[:-1],
layer_sizes[1:])):
layer_top_a = v_spacing*(layer_size_a - 1)/2. + (top + bottom)/2.
layer_top_b = v_spacing*(layer_size_b - 1)/2. + (top + bottom)/2.
for m in range(layer_size_a):
for o in range(layer_size_b):
line = plt.Line2D([n*h_spacing + left, (n + 1)*h_spacing + left],
[layer_top_a - m*v_spacing,
layer_top_b - o*v_spacing], c='k')
ax.add_artist(line)
node_text = ['','','','h1','h2','h3','...', 'h100']
fig = plt.figure(figsize=(8, 8))
ax = fig.gca()
draw_neural_net(ax, .1, .9, .1, .9, [3, 5, 2], node_text)
plt.text(0.1, 0.95, "Input Layer\nImages 28x28", ha='center', va='top', fontsize=16)
plt.text(0.26, 0.78, "W1", ha='center', va='top', fontsize=16)
plt.text(0.5, 0.95, "Hidden Layer\n with ReLU", ha='center', va='top', fontsize=16)
plt.text(0.74, 0.74, "W2", ha='center', va='top', fontsize=16)
plt.text(0.88, 0.95, "Output Layer\n10 classes", ha='center', va='top', fontsize=16)
plt.show()
Код FNN
import numpy as np
class TwoLayerNet(object):
"""
A two-layer fully-connected neural network. The net has an
input dimension of N, a hidden layer dimension of H, and
performs classification over C classes. We train the network
with a softmax loss function and L2 regularization on the
weight matrices. The network uses a ReLU nonlinearity after
the first fully connected layer. In other words, the network
has the following architecture:
input - fully connected layer - ReLU -
fully connected layer - softmax
The outputs of the second fully-connected layer are the
scores for each class.
"""
def __init__(self, input_size, hidden_size, output_size, std):
"""
Initialize the model. Weights are initialized following Xavier
intialization and biases are initialized to zero. Weights and
biases are stored in the variable self.params, which is a
dictionary with the following keys:
W1: First layer weights; has shape (D, H)
b1: First layer biases; has shape (H,)
W2: Second layer weights; has shape (H, C)
b2: Second layer biases; has shape (C,)
Inputs:
- input_size: The dimension D of the input data.
- hidden_size: The number of neurons H in the hidden layer.
- output_size: The number of classes C.
"""
self.params = {}
self.params['W1'] = (((2 / input_size) ** 0.5) *
np.random.randn(input_size, hidden_size))
self.params['b1'] = np.zeros(hidden_size)
self.params['W2'] = (((2 / hidden_size) ** 0.5) *
np.random.randn(hidden_size, output_size))
self.params['b2'] = np.zeros(output_size)
def loss(self, X, y=None, reg=0.0):
"""
Compute the loss and gradients for a two layer fully
connected neural network.
Inputs:
- X: Input data of shape (N, D). X[i] is a training sample.
- y: Vector of training labels. y[i] is the label for X[i], and
each y[i] is an integer in the range 0 <= y[i] < C.
- reg: Regularization strength.
Returns:
- loss: Loss (data loss and regularization loss) for this
batch of training samples.
- grads: Dictionary mapping parameter names to
gradients of those parameters with respect to the loss
function; has the same keys as self.params.
"""
# Unpack variables from the params dictionary
W1, b1 = self.params['W1'], self.params['b1']
W2, b2 = self.params['W2'], self.params['b2']
N, D = X.shape
# Compute the forward pass
l1 = X.dot(W1) + b1
l1[l1 < 0] = 0
l2 = l1.dot(W2) + b2
exp_scores = np.exp(l2)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
scores = l2
# Compute the loss
W1_r = 0.5 * reg * np.sum(W1 * W1)
W2_r = 0.5 * reg * np.sum(W2 * W2)
loss = -np.sum(np.log(probs[range(y.shape[0]), y]))/N + W1_r + W2_r
# Backward pass: compute gradients
grads = {}
probs[range(X.shape[0]),y] -= 1
dW2 = np.dot(l1.T, probs)
dW2 /= X.shape[0]
dW2 += reg * W2
grads['W2'] = dW2
grads['b2'] = np.sum(probs, axis=0, keepdims=True) / X.shape[0]
delta = probs.dot(W2.T)
delta = delta * (l1 > 0)
grads['W1'] = np.dot(X.T, delta)/ X.shape[0] + reg * W1
grads['b1'] = np.sum(delta, axis=0, keepdims=True) / X.shape[0]
return loss, grads
def train(self, X, y, X_val, y_val,
learning_rate=1e-3, learning_rate_decay=0.95,
reg=5e-6, num_iters=100,
batch_size=24, verbose=False):
"""
Train this neural network using stochastic gradient descent.
Inputs:
- X: A numpy array of shape (N, D) giving training data.
- y: A numpy array f shape (N,) giving training labels;
y[i] = c means that [i] has label c, where 0 <= c < C.
- X_val: A numpy array of shape (N_val, D); validation data.
- y_val: A numpy array of shape (N_val,); validation labels.
- learning_rate: Scalar giving learning rate for optimization.
- learning_rate_decay: Scalar giving factor used to decay
the learning rate each epoch.
- reg: Scalar giving regularization strength.
- num_iters: Number of steps to take when optimizing.
- batch_size: Number of training examples to use per step.
- verbose: boolean; if true print progress during optimization.
"""
num_train = X.shape[0]
iterations_per_epoch = max(num_train / batch_size, 1)
# Use SGD to optimize the parameters in self.model
loss_history = []
train_acc_history = []
val_acc_history = []
# Training cycle
for it in range(num_iters):
# Mini-batch selection
indexes = np.random.choice(X.shape[0], batch_size,
replace=True)
X_batch = X[indexes]
y_batch = y[indexes]
# Compute loss and gradients using the current minibatch
loss, grads = self.loss(X_batch, y=y_batch, reg=reg)
loss_history.append(loss)
# Update weights
self.params['W1'] -= learning_rate * grads['W1']
self.params['b1'] -= learning_rate * grads['b1'][0]
self.params['W2'] -= learning_rate * grads['W2']
self.params['b2'] -= learning_rate * grads['b2'][0]
if verbose and it % 100 == 0:
print('iteration %d / %d: loss %f' % (it,
num_iters, loss))
# Every epoch, check accuracy and decay learning rate.
if it % iterations_per_epoch == 0:
# Check accuracy
train_acc = (self.predict(X_batch)==y_batch).mean()
val_acc = (self.predict(X_val) == y_val).mean()
train_acc_history.append(train_acc)
val_acc_history.append(val_acc)
# Decay learning rate
learning_rate *= learning_rate_decay
return {
'loss_history': loss_history,
'train_acc_history': train_acc_history,
'val_acc_history': val_acc_history,
}
def predict(self, X):
"""
Use the trained weights of this two-layer network to predict
labels for points. For each data point we predict scores for
each of the C classes, and assign each data point to the class
with the highest score.
Inputs:
- X: A numpy array of shape (N, D) giving N D-dimensional
data points to classify.
Returns:
- y_pred: A numpy array of shape (N,) giving predicted labels
for each of elements of X. For all i, y_pred[i] = c means that
X[i] is predicted to have class c, where 0 <= c < C.
"""
l1 = X.dot(self.params['W1']) + self.params['b1']
l1[l1 < 0] = 0
l2 = l1.dot(self.params['W2']) + self.params['b2']
exp_scores = np.exp(l2)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
y_pred = np.argmax(probs, axis=1)
return y_pred
def predict_single(self, X):
"""
Use the trained weights of this two-layer network to predict label
for data point. We predict scores for each of the C classes, and
assign the data point to the class with the highest score.
Inputs:
- X: A numpy array of shape (N, D) giving N D-dimensional data
points to classify.
Returns:
- y_pred: A numpy array of shape (1,) giving predicted labels for X.
"""
l1 = X.dot(self.params['W1']) + self.params['b1']
l1[l1 < 0] = 0
l2 = l1.dot(self.params['W2']) + self.params['b2']
exp_scores = np.exp(l2)
y_pred = np.argmax(exp_scores)
return y_pred
Как работает FNN
В курсе cs231n приведена замечательная иллюстрация:
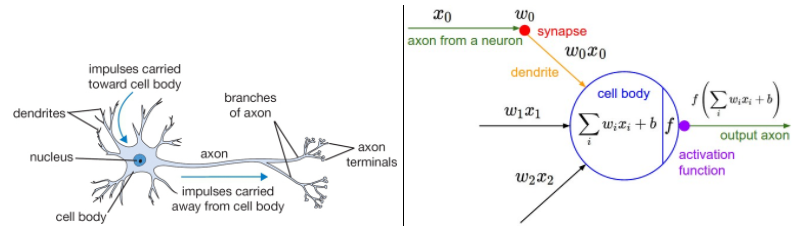
Сравнение биологических нейронов и нейронов в сетях для машинного обучения — избитая тема, так что лучше не буду её трогать, а расскажу, как работает моя сеть.
На вход в модель подаются обработанные изображения, таким образом у нас есть матрица размером N х 784, где N — количество изображений (19200 при тренировке). Чтобы перейти к скрытому слою, нужно умножить матрицу исходных данных на матрицу весов и добавить биас, а затем применить функцию активации:
Можно сказать, что softmax — это логистическая функция в многомерном пространстве. Она даёт вероятностное распределение возможных исходов или, другими словами, вероятность принадлежности к каждому из классов. Учитывая, что веса для этого слоя имеют измерения 100 х 10, то на выходе получаем 10 нейронов, которые показывают с какой вероятностью модель предсказывает ту или иную цифру для изображений. Cross-entropy loss для softmax выглядит так:
Сравнение биологических нейронов и нейронов в сетях для машинного обучения — избитая тема, так что лучше не буду её трогать, а расскажу, как работает моя сеть.
На вход в модель подаются обработанные изображения, таким образом у нас есть матрица размером N х 784, где N — количество изображений (19200 при тренировке). Чтобы перейти к скрытому слою, нужно умножить матрицу исходных данных на матрицу весов и добавить биас, а затем применить функцию активации:




Можно сказать, что softmax — это логистическая функция в многомерном пространстве. Она даёт вероятностное распределение возможных исходов или, другими словами, вероятность принадлежности к каждому из классов. Учитывая, что веса для этого слоя имеют измерения 100 х 10, то на выходе получаем 10 нейронов, которые показывают с какой вероятностью модель предсказывает ту или иную цифру для изображений. Cross-entropy loss для softmax выглядит так:

Код работает следующим образом:
- Для задания начальных значений весов используется инициализация Ксавьера (Xavier). При таком варианте инициализации дисперсия берётся равной 2 / количество входящих нейронов. Благодаря этому веса получаются не слишком большими и не слишком маленькими;
- В методе loss реализован шаг градиентного спуска и расчёт лосса с учетом L2 регуляризации;
- В методе train осуществляется итеративная тренировка на мини-батчах. Лосс считается после каждого шага. После каждой эпохи считается точность на тренировочном и валидационном датасетах, а также уменьшается learning rate с учётом decay;
- Метод predict_single даёт предсказания для одного изображения, а predict — для нескольких;
При начале работе с сетью необходимо задать размеры всех трёх слоёв:
input_size = 28 * 28
hidden_size = 100
num_classes = 10
net = tln(input_size, hidden_size, num_classes)
При тренировке необходимо указать большее количество параметров и данных:
- тренировочные и валидационные данные и их лейблы;
- количество итераций и размер мини-батча, их частное будет количеством эпох;
- изначальное значение learning rate и размер decay, на которое умножается learning rate после каждой эпохи;
- размер коэффициента регуляризации;
- и значение verbose для отображения/скрытия процесса тренировки;
stats = net.train(X_train_, y_train_, X_val, y_val,
num_iters=19200, batch_size=24,
learning_rate=0.1, learning_rate_decay=0.95,
reg=0.001, verbose=True)
Благодаря тому, что тренировка возвращает историю изменения loss и точности на тренировочных и валидационных данных, строить графики довольно просто:
plt.subplot(2, 1, 1)
plt.plot(stats['loss_history'])
plt.title('Loss history')
plt.xlabel('Iteration')
plt.ylabel('Loss')
plt.subplot(2, 1, 2)
plt.plot(stats['train_acc_history'], label='train')
plt.plot(stats['val_acc_history'], label='val')
plt.title('Classification accuracy history')
plt.xlabel('Epoch')
plt.ylabel('Clasification accuracy')
plt.legend()
plt.show()
Тренировка и подбор параметров
Выбор оптимальных параметров — больная тема. Переобучение, недообучение, предсказание одного и того же класса для разных данных — проблем, которые могут возникнуть при тренировке сети полно. Соответственно возникает вопрос подбора хороших параметров. Здесь я сразу решил, что не гонюсь за максимальной точностью, и разница в несколько процентов не является критичной при построении модели. Напомню, что важной частью проекта является дотренировка моделей, а это значит, что точность всё равно будет изменяться.
Тем не менее всё же хочется получить приличную точность, а значит надо приложить усилия. Я решил идти методом простого перебора параметров. Для этого на глаз были определены возможные значения learning rate, regularization, количества нейронов в скрытом слое, количества эпох и размера мини-батча; для каждой комбинации сеть тренировалась, и запоминались точности на тренировочном и валидационном датасетах. Модель с наивысшей точностью считалась лучшей.
Подбор параметров
from itertools import product
best_net = None
results = {}
best_val = -1
learning_rates = [0.001, 0.1, 0.01, 0.5]
regularization_strengths = [0.001, 0.1, 0.01]
hidden_size = [5, 10, 20]
epochs = [1000, 1500, 2000]
batch_sizes = [24, 12]
best_params = 0
best_params = 0
for v in product(learning_rates, regularization_strengths,
hidden_size, epochs, batch_sizes):
print('learning rate: {0}, regularization strength: {1}, hidden size: {2}, \
iterations: {3}, batch_size: {4}.'.format(v[0], v[1], v[2], v[3], v[4]))
net = TwoLayerNet(input_size, v[2], num_classes)
stats = net.train(X_train_, y_train, X_val_, y_val,
num_iters=v[3], batch_size=v[4],
learning_rate=v[0], learning_rate_decay=0.95,
reg=v[1], verbose=False)
y_train_pred = net.predict(X_train_)
train_acc = np.mean(y_train == y_train_pred)
val_acc = (net.predict(X_val_) == y_val).mean()
print('Validation accuracy: ', val_acc)
results[(v[0], v[1], v[2], v[3], v[4])] = val_acc
if val_acc > best_val:
best_val = val_acc
best_net = net
best_params = (v[0], v[1], v[2], v[3], v[4])
Точность наилучшей модели была хорошей, казалось бы всё неплохо, но я чувствовал, что что-то не так. Дело в том, что количество итераций было небольшим, learning rate оставалась довольно высокой и точность модели была весьма нестабильной. Я решил привнести в параметры модели некоторую логику. Размер мини-батча определялся на глаз, но ведь это не совсем корректно в моём случае: если я планирую дообучение, то модель должна уметь тренироваться на 1 новом изображении. 1 изображение означает 24 аугментированных, исходя из этого было решено попробовать сделать размер мини-батча таким же. Вместе с этим я увеличил количество эпох до 24.
Кроме того мне захотелось узнать точность предсказаний моей модели на MNIST, так что я добавил в код сохранение результатов предсказания на MNIST.
Код для считывания и подготовки данных MNIST
def read(path = "."):
fname_img = os.path.join(path, 't10k-images.idx3-ubyte')
fname_lbl = os.path.join(path, 't10k-labels.idx1-ubyte')
with open(fname_lbl, 'rb') as flbl:
magic, num = struct.unpack(">II", flbl.read(8))
lbl = np.fromfile(flbl, dtype=np.int8)
with open(fname_img, 'rb') as fimg:
magic, num, rows, cols = struct.unpack(">IIII", fimg.read(16))
img = np.fromfile(fimg, dtype=np.uint8).reshape(len(lbl), rows, cols)
get_img = lambda idx: (lbl[idx], img[idx])
for i in range(len(lbl)):
yield get_img(i)
test = list(read(path="/MNIST_data"))
mnist_labels = np.array([i[0] for i in test]).astype(int)
mnist_picts = np.array([i[1] for i in test]).reshape(10000, 784) / 255
y_mnist = np.array(mnist_labels).astype(int)
В итоге получился такой вот процесс тренировки:
По графику видно, что можно было бы ограничиться ~10 эпохами, но я решил потренировать модель подольше.
Думаю, что сразу заметно, что точность на MNIST довольно низка. Я было забеспокоился, но подумал о том, что наверняка собранные мной данные и данные MNIST могут различаться. Чтобы проверить это я взял архитектуру CNN из официального гайда Tensorflow для MNIST и натренировал её. На тестовой части MNIST точность была 99%+ (как и ожидалось), а вот на моих данных точность оказалась значительно ниже: 78.5% на неаугментированных и 63.35% на аугментированных. Исходя из этого я решил, что мои данные и MNIST действительно различаются, а моя модель достаточно хороша и не стоит пытаться оптимизировать её для предсказаний на MNIST.
Впрочем, я всё же попытался улучшить модель:
- пробовал добавить скрытые слои;
- пробовал значительно увеличить количество итераций/эпох;
- пробовал разные варианты оптимизации: Нестерова, Адама, rmsprop;
Ничего из этого не смогло значительно увеличить точность модели. Наверное, из имеющихся данных было проблематично извлечь больше информации.
Сохранение весов этой модели довольно просто:
net.param представляет из себя словарь, где ключи — названия весов, а значения — сами веса. В numpy есть удобная функция для сохранения такой структуры: np.save('tmp/updated_weights.npy', net.params). Для загрузки используется np.load('models/original_weights.npy')[()] ([()] используется для того, чтобы извлечь из сохраненного файла словарь с весами).Пришло время перейти к следующему этапу.
Дообучение FNN
Реализация возможности дообучения оказалась до удивления простой. Изменения в коде были следующими:
- Веса не инициализируются случайным образом, а передаются в модель. Соответственно должно быть реализовано сохранение и загрузка весов;
- Лосс не считается, поскольку не нужен;
- Модель делает один шаг градиентного спуска на получаемых данных (1 изображение, аугментированное до 24);
- Все параметры модели (learning rate и другие) фиксированы и заданы прямо в модели;
- Метод predict-single возвращает 3 наиболее вероятных предсказания и их вероятности. Это относится не к самой дотренировке, а к работе кода в целом;
Обновлённый код FNN
import numpy as np
class FNN(object):
"""
A two-layer fully-connected neural network. The net has an
input dimension of N, a hidden layer dimension of H, and
performs classification over C classes. We train the network
with a softmax loss function and L2 regularization on the
weight matrices. The network uses a ReLU nonlinearity after
the first fully connected layer. In other words, the network
has the following architecture:
input - fully connected layer - ReLU -
fully connected layer - softmax
The outputs of the second fully-connected layer are the
scores for each class.
"""
def __init__(self, weights,input_size=28*28,hidden_size=100,output_size=10):
"""
Initialize the model. Weights are initialized following Xavier
intialization and biases are initialized to zero. Weights and
biases are stored in the variable self.params, which is a
dictionary with the following keys:
W1: First layer weights; has shape (D, H)
b1: First layer biases; has shape (H,)
W2: Second layer weights; has shape (H, C)
b2: Second layer biases; has shape (C,)
Inputs:
- input_size: The dimension D of the input data.
- hidden_size: The number of neurons H in the hidden layer.
- output_size: The number of classes C.
"""
self.params = {}
self.params['W1'] = weights['W1']
self.params['b1'] = weights['b1']
self.params['W2'] = weights['W2']
self.params['b2'] = weights['b2']
def loss(self, X, y, reg=0.0):
"""
Compute the loss and gradients for a two layer fully
connected neural network.
Inputs:
- X: Input data of shape (N, D). X[i] is a training sample.
- y: Vector of training labels. y[i] is the label for X[i], and
each y[i] is an integer in the range 0 <= y[i] < C.
- reg: Regularization strength.
Returns:
- loss: Loss (data loss and regularization loss) for this
batch of training samples.
- grads: Dictionary mapping parameter names to
gradients of those parameters with respect to the loss
function; has the same keys as self.params.
"""
# Unpack variables from the params dictionary
W1, b1 = self.params['W1'], self.params['b1']
W2, b2 = self.params['W2'], self.params['b2']
N, D = X.shape
# Compute the forward pass
l1 = X.dot(W1) + b1
l1[l1 < 0] = 0
l2 = l1.dot(W2) + b2
exp_scores = np.exp(l2)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
# Backward pass: compute gradients
grads = {}
probs[range(X.shape[0]), y] -= 1
dW2 = np.dot(l1.T, probs)
dW2 /= X.shape[0]
dW2 += reg * W2
grads['W2'] = dW2
grads['b2'] = np.sum(probs, axis=0, keepdims=True) / X.shape[0]
delta = probs.dot(W2.T)
delta = delta * (l1 > 0)
grads['W1'] = np.dot(X.T, delta)/ X.shape[0] + reg * W1
grads['b1'] = np.sum(delta, axis=0, keepdims=True) / X.shape[0]
return grads
def train(self, X, y, learning_rate=0.1*(0.95**24)/32,
reg=0.001, batch_size=24):
"""
Train this neural network using stochastic gradient descent.
Inputs:
- X: A numpy array of shape (N, D) giving training data.
- y: A numpy array f shape (N,) giving training labels;
y[i] = c means that [i] has label c, where 0 <= c < C.
- X_val: A numpy array of shape (N_val, D); validation data.
- y_val: A numpy array of shape (N_val,); validation labels.
- learning_rate: Scalar giving learning rate for optimization.
- learning_rate_decay: Scalar giving factor used to decay
the learning rate each epoch.
- reg: Scalar giving regularization strength.
- num_iters: Number of steps to take when optimizing.
- batch_size: Number of training examples to use per step.
- verbose: boolean; if true print progress during optimization.
"""
num_train = X.shape[0]
# Compute loss and gradients using the current minibatch
grads = self.loss(X, y, reg=reg)
self.params['W1'] -= learning_rate * grads['W1']
self.params['b1'] -= learning_rate * grads['b1'][0]
self.params['W2'] -= learning_rate * grads['W2']
self.params['b2'] -= learning_rate * grads['b2'][0]
def predict(self, X):
"""
Use the trained weights of this two-layer network to predict
labels for points. For each data point we predict scores for
each of the C classes, and assign each data point to the class
with the highest score.
Inputs:
- X: A numpy array of shape (N, D) giving N D-dimensional
data points to classify.
Returns:
- y_pred: A numpy array of shape (N,) giving predicted labels
for each of elements of X. For all i, y_pred[i] = c means that
X[i] is predicted to have class c, where 0 <= c < C.
"""
l1 = X.dot(self.params['W1']) + self.params['b1']
l1[l1 < 0] = 0
l2 = l1.dot(self.params['W2']) + self.params['b2']
exp_scores = np.exp(l2)
probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
y_pred = np.argmax(probs, axis=1)
return y_pred
def predict_single(self, X):
"""
Use the trained weights of this two-layer network to predict label
for data point. We predict scores for each of the C classes, and
assign the data point to the class with the highest score.
Inputs:
- X: A numpy array of shape (N, D) giving N D-dimensional data
points to classify.
Returns:
- top_3: a list of 3 top most probable predictions with their
probabilities as tuples.
"""
l1 = X.dot(self.params['W1']) + self.params['b1']
l1[l1 < 0] = 0
l2 = l1.dot(self.params['W2']) + self.params['b2']
exp_scores = np.exp(l2)
probs = exp_scores / np.sum(exp_scores)
y_pred = np.argmax(exp_scores)
top_3 = list(zip(np.argsort(probs)[::-1][:3],
np.round(probs[np.argsort(probs)[::-1][:3]] * 100, 2)))
return top_3
Я потратил некоторое время на проверку работоспособности этих изменений, на проверку точности — не станет ли она изменяться слишком резко, а также на выбор learning rate.
Выбор learning rate был самым сложным. Изначальное значение было 0.1, а после 24 эпох 0.1 x (0.95 ^ 24). Проблема в том, что это значение использовалось для всей эпохи — 800 итераций. Если использовать это значение, то каждое новое изображение может чувствительно изменять веса. Я пробовал много разных значений и остановился на 0.1 x (0.95 ^ 24) / 32. В итоге одно изображение не сможет значительно изменить веса, но несколько изображений постепенно приведут к заметным изменениям.
CNN
Вообще говоря, после создания FNN я занялся созданием рабочей версии сайта, но после того как я сделал CNN, сайт пришлось немного модифицировать, так что значительно удобнее поговорить вначале о CNN, а потом уже о сайте.
При создании архитектуры CNN я опирался на cs231n и вариант из гайда Tenforlow для MNIST, но в итоге модифицировал под свои нужды.
Код для создания картинки
import os
import numpy as np
import matplotlib.pyplot as plt
plt.rcdefaults()
from matplotlib.lines import Line2D
from matplotlib.patches import Rectangle
from matplotlib.collections import PatchCollection
#https://github.com/gwding/draw_convnet
NumConvMax = 8
NumFcMax = 20
White = 1.
Light = 0.7
Medium = 0.5
Dark = 0.3
Black = 0.
def add_layer(patches, colors, size=24, num=5,
top_left=[0, 0],
loc_diff=[3, -3],
):
# add a rectangle
top_left = np.array(top_left)
loc_diff = np.array(loc_diff)
loc_start = top_left - np.array([0, size])
for ind in range(num):
patches.append(Rectangle(loc_start + ind * loc_diff, size, size))
if ind % 2:
colors.append(Medium)
else:
colors.append(Light)
def add_mapping(patches, colors, start_ratio, patch_size, ind_bgn,
top_left_list, loc_diff_list, num_show_list, size_list):
start_loc = top_left_list[ind_bgn] \
+ (num_show_list[ind_bgn] - 1) * np.array(loc_diff_list[ind_bgn]) \
+ np.array([start_ratio[0] * size_list[ind_bgn],
-start_ratio[1] * size_list[ind_bgn]])
end_loc = top_left_list[ind_bgn + 1] \
+ (num_show_list[ind_bgn + 1] - 1) \
* np.array(loc_diff_list[ind_bgn + 1]) \
+ np.array([(start_ratio[0] + .5 * patch_size / size_list[ind_bgn]) *
size_list[ind_bgn + 1],
-(start_ratio[1] - .5 * patch_size / size_list[ind_bgn]) *
size_list[ind_bgn + 1]])
patches.append(Rectangle(start_loc, patch_size, patch_size))
colors.append(Dark)
patches.append(Line2D([start_loc[0], end_loc[0]],
[start_loc[1], end_loc[1]]))
colors.append(Black)
patches.append(Line2D([start_loc[0] + patch_size, end_loc[0]],
[start_loc[1], end_loc[1]]))
colors.append(Black)
patches.append(Line2D([start_loc[0], end_loc[0]],
[start_loc[1] + patch_size, end_loc[1]]))
colors.append(Black)
patches.append(Line2D([start_loc[0] + patch_size, end_loc[0]],
[start_loc[1] + patch_size, end_loc[1]]))
colors.append(Black)
def label(xy, text, xy_off=[0, 4]):
plt.text(xy[0] + xy_off[0], xy[1] + xy_off[1], text,
family='sans-serif', size=8)
if __name__ == '__main__':
fc_unit_size = 2
layer_width = 40
patches = []
colors = []
fig, ax = plt.subplots()
############################
# conv layers
size_list = [28, 28, 14, 14, 7]
num_list = [1, 16, 16, 32, 32]
x_diff_list = [0, layer_width, layer_width, layer_width, layer_width]
text_list = ['Inputs'] + ['Feature\nmaps'] * (len(size_list) - 1)
loc_diff_list = [[3, -3]] * len(size_list)
num_show_list = list(map(min, num_list, [NumConvMax] * len(num_list)))
top_left_list = np.c_[np.cumsum(x_diff_list), np.zeros(len(x_diff_list))]
for ind in range(len(size_list)):
add_layer(patches, colors, size=size_list[ind],
num=num_show_list[ind],
top_left=top_left_list[ind], loc_diff=loc_diff_list[ind])
label(top_left_list[ind], text_list[ind] + '\n{}@{}x{}'.format(
num_list[ind], size_list[ind], size_list[ind]))
############################
# in between layers
start_ratio_list = [[0.4, 0.5], [0.4, 0.8], [0.4, 0.5], [0.4, 0.8]]
patch_size_list = [4, 2, 4, 2]
ind_bgn_list = range(len(patch_size_list))
text_list = ['Convolution', 'Max-pooling', 'Convolution', 'Max-pooling']
for ind in range(len(patch_size_list)):
add_mapping(patches, colors, start_ratio_list[ind],
patch_size_list[ind], ind,
top_left_list, loc_diff_list, num_show_list, size_list)
label(top_left_list[ind], text_list[ind] + '\n{}x{} kernel'.format(
patch_size_list[ind], patch_size_list[ind]), xy_off=[26, -65])
############################
# fully connected layers
size_list = [fc_unit_size, fc_unit_size, fc_unit_size]
num_list = [1568, 625, 10]
num_show_list = list(map(min, num_list, [NumFcMax] * len(num_list)))
x_diff_list = [sum(x_diff_list) + layer_width, layer_width, layer_width]
top_left_list = np.c_[np.cumsum(x_diff_list), np.zeros(len(x_diff_list))]
loc_diff_list = [[fc_unit_size, -fc_unit_size]] * len(top_left_list)
text_list = ['Hidden\nunits'] * (len(size_list) - 1) + ['Outputs']
for ind in range(len(size_list)):
add_layer(patches, colors, size=size_list[ind], num=num_show_list[ind],
top_left=top_left_list[ind], loc_diff=loc_diff_list[ind])
label(top_left_list[ind], text_list[ind] + '\n{}'.format(
num_list[ind]))
text_list = ['Flatten\n', 'Fully\nconnected', 'Fully\nconnected']
for ind in range(len(size_list)):
label(top_left_list[ind], text_list[ind], xy_off=[-10, -65])
############################
colors += [0, 1]
collection = PatchCollection(patches, cmap=plt.cm.gray)
collection.set_array(np.array(colors))
ax.add_collection(collection)
plt.tight_layout()
plt.axis('equal')
plt.axis('off')
plt.show()
fig.set_size_inches(8, 2.5)
fig_dir = './'
fig_ext = '.png'
fig.savefig(os.path.join(fig_dir, 'convnet_fig' + fig_ext),
bbox_inches='tight', pad_inches=0)
Поскольку используется Tensorflow, код имеет структуру, значительно отличающуюся от FNN на numpy.
Код CNN
import tensorflow as tf
# Define architecture
def model(X, w, w3, w4, w_o, p_keep_conv, p_keep_hidden):
l1a = tf.nn.relu(
tf.nn.conv2d(
X, w,
strides=[1, 1, 1, 1],
padding='SAME'
)
+ b1
)
l1 = tf.nn.max_pool(
l1a,
ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1],
padding='SAME'
)
l1 = tf.nn.dropout(l1, p_keep_conv)
l3a = tf.nn.relu(
tf.nn.conv2d(
l1, w3,
strides=[1, 1, 1, 1],
padding='SAME'
)
+ b3
)
l3 = tf.nn.max_pool(
l3a,
ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1],
padding='SAME'
)
# Reshaping for dense layer
l3 = tf.reshape(l3, [-1, w4.get_shape().as_list()[0]])
l3 = tf.nn.dropout(l3, p_keep_conv)
l4 = tf.nn.relu(tf.matmul(l3, w4) + b4)
l4 = tf.nn.dropout(l4, p_keep_hidden)
pyx = tf.matmul(l4, w_o) + b5
return pyx
tf.reset_default_graph()
# Define variables
init_op = tf.global_variables_initializer()
X = tf.placeholder("float", [None, 28, 28, 1])
Y = tf.placeholder("float", [None, 10])
w = tf.get_variable("w", shape=[4, 4, 1, 16],
initializer=tf.contrib.layers.xavier_initializer())
b1 = tf.get_variable(name="b1", shape=[16],
initializer=tf.zeros_initializer())
w3 = tf.get_variable("w3", shape=[4, 4, 16, 32],
initializer=tf.contrib.layers.xavier_initializer())
b3 = tf.get_variable(name="b3", shape=[32],
initializer=tf.zeros_initializer())
w4 = tf.get_variable("w4", shape=[32 * 7 * 7, 625],
initializer=tf.contrib.layers.xavier_initializer())
b4 = tf.get_variable(name="b4", shape=[625],
initializer=tf.zeros_initializer())
w_o = tf.get_variable("w_o", shape=[625, 10],
initializer=tf.contrib.layers.xavier_initializer())
b5 = tf.get_variable(name="b5", shape=[10],
initializer=tf.zeros_initializer())
# Dropout rate
p_keep_conv = tf.placeholder("float")
p_keep_hidden = tf.placeholder("float")
py_x = model(X, w, w3, w4, w_o, p_keep_conv, p_keep_hidden)
reg_losses = tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)
reg_constant = 0.01
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=py_x, labels=Y) + reg_constant * sum(reg_losses))
train_op = tf.train.RMSPropOptimizer(0.0001, 0.9).minimize(cost)
predict_op = tf.argmax(py_x, 1)
#Training
train_acc = []
val_acc = []
test_acc = []
train_loss = []
val_loss = []
test_loss = []
with tf.Session() as sess:
tf.global_variables_initializer().run()
# Training iterations
for i in range(256):
# Mini-batch
training_batch = zip(range(0, len(trX), batch_size),
range(batch_size, len(trX)+1, batch_size))
for start, end in training_batch:
sess.run(train_op, feed_dict={X: trX[start:end],
Y: trY[start:end],
p_keep_conv: 0.8,
p_keep_hidden: 0.5})
# Comparing labels with predicted values
train_acc = np.mean(np.argmax(trY, axis=1) ==
sess.run(predict_op, feed_dict={X: trX,
Y: trY,
p_keep_conv: 1.0,
p_keep_hidden: 1.0}))
train_acc.append(train_acc)
val_acc = np.mean(np.argmax(teY, axis=1) ==
sess.run(predict_op, feed_dict={X: teX,
Y: teY,
p_keep_conv: 1.0,
p_keep_hidden: 1.0}))
val_acc.append(val_acc)
test_acc = np.mean(np.argmax(mnist.test.labels, axis=1) ==
sess.run(predict_op, feed_dict={X: mnist_test_images,
Y: mnist.test.labels,
p_keep_conv: 1.0,
p_keep_hidden: 1.0}))
test_acc.append(test_acc)
print('Step {0}. Train accuracy: {3}. Validation accuracy: {1}. \
Test accuracy: {2}.'.format(i, val_acc, test_acc, train_acc))
_, loss_train = sess.run([predict_op, cost],
feed_dict={X: trX,
Y: trY,
p_keep_conv: 1.0,
p_keep_hidden: 1.0})
train_loss.append(loss_train)
_, loss_val = sess.run([predict_op, cost],
feed_dict={X: teX,
Y: teY,
p_keep_conv: 1.0,
p_keep_hidden: 1.0})
val_loss.append(loss_val)
_, loss_test = sess.run([predict_op, cost],
feed_dict={X: mnist_test_images,
Y: mnist.test.labels,
p_keep_conv: 1.0,
p_keep_hidden: 1.0})
test_loss.append(loss_test)
print('Train loss: {0}. Validation loss: {1}. \
Test loss: {2}.'.format(loss_train, loss_val, loss_test))
# Saving model
all_saver = tf.train.Saver()
all_saver.save(sess, '/resources/data.chkp')
#Predicting
with tf.Session() as sess:
# Restoring model
saver = tf.train.Saver()
saver.restore(sess, "./data.chkp")
# Prediction
pr = sess.run(predict_op, feed_dict={X: mnist_test_images,
Y: mnist.test.labels,
p_keep_conv: 1.0,
p_keep_hidden: 1.0})
print(np.mean(np.argmax(mnist.test.labels, axis=1) ==
sess.run(predict_op, feed_dict={X: mnist_test_images,
Y: mnist.test.labels,
p_keep_conv: 1.0,
p_keep_hidden: 1.0})))
Как работает CNN
CNN имеют некоторые сходства с FNN в том плане, что они тоже состоят из нейронов и используют веса и биасы. Но архитектура CNN построена на другом принципе — она заточена на работу с изображениями, что позволяет по-другому работать с данными.
Первый слой всегда свёрточный. На вход приходит многомерное изображение (в нашём случае N x 28 x 28 x 1), мы «смотрим» на небольшой участок изображения и применяем к нему фильтр (то есть матрицу весов), а затем функцию активации. Затем фильтр сдвигается и операция повторяется для следующего участка изображения. В результате мы получаем так называемую карту признаков. Исходя из этой карты можно сказать какие участки изображения являются важными для модели. Важным является понятие каналов: это можно назвать разными взглядами на изображение. Например, три канала могут соответствовать RGB. Здесь есть хороший вариант визуализации этого слоя.

Обычно карта признаков имеет меньшее измерение, чем входящие данные, особенно если сдвиг фильтра больше 1, но есть способ избежать этого и оставить оригинальные измерения. Для этого существует способ под названием zero-padding, которые добавляет 0 по краям изображения так, чтобы применение фильтра с учетом сдвига давало матрицу с оригинальными измерениями. Для этого существует целый ряд причин:
Следующим слоем обычно является max pooling (есть разные вариации, но max встречается чаще). Этот слой предназначен для уплотнения карты признаков, что позволяет уменьшить пространственный объём изображения. Интерпретировать это можно так: свёрточный слой дал подробную карту признаков, но для дальнейшей работы можно использовать менее подробные данные. Пример визуализации из cs231n.

Max pooling берёт определенную группу пикселей (обычно 2 х 2) и выбирает пиксель с максимальным значением. Далее операция повторяется со сдвигом для остальных участков изображения. Часть используется больше одной пары из свёртки и пулинга; в моей модели их 2.
По итогам этих слоёв получается некое абстрактное представления изображения к которому можно присоединить полносвязный слой. Этих слоёв опять же может быть больше одного. Можно сказать, что полносвязные слой находят свойства, которые связаны с тем или иным классом.
Теперь посмотрим, что происходит в моей модели.
На вход подаётся изображение N x 28 x 28 x 1. К нему применяется фильтр 4 х 4 х 16, но благодаря zero-padding (
Замечу, что все слои кроме последнего также используют дропаут. Напомню, что дропаут подразумевает «отбрасывание» определенного процента нейронов для борьбы с переобучением.
Первый слой всегда свёрточный. На вход приходит многомерное изображение (в нашём случае N x 28 x 28 x 1), мы «смотрим» на небольшой участок изображения и применяем к нему фильтр (то есть матрицу весов), а затем функцию активации. Затем фильтр сдвигается и операция повторяется для следующего участка изображения. В результате мы получаем так называемую карту признаков. Исходя из этой карты можно сказать какие участки изображения являются важными для модели. Важным является понятие каналов: это можно назвать разными взглядами на изображение. Например, три канала могут соответствовать RGB. Здесь есть хороший вариант визуализации этого слоя.
Обычно карта признаков имеет меньшее измерение, чем входящие данные, особенно если сдвиг фильтра больше 1, но есть способ избежать этого и оставить оригинальные измерения. Для этого существует способ под названием zero-padding, которые добавляет 0 по краям изображения так, чтобы применение фильтра с учетом сдвига давало матрицу с оригинальными измерениями. Для этого существует целый ряд причин:
- это проще, поскольку нужно меньше думать о том, какие измерения получаются в результате;
- можно делать более глубокие сети, поскольку измерения данных уменьшаются с меньшей скоростью;
- это может вообще приводить у улучшению модели благодаря тому, что сохраняется информация у краёв модели;
- если делать сложные разветвлённые модели, которые применяют к данным разные фильтры, а потом объединяют результаты, то без zero-padding может получиться ситуация, когда получившиеся измерения окажутся несовместимыми;
Следующим слоем обычно является max pooling (есть разные вариации, но max встречается чаще). Этот слой предназначен для уплотнения карты признаков, что позволяет уменьшить пространственный объём изображения. Интерпретировать это можно так: свёрточный слой дал подробную карту признаков, но для дальнейшей работы можно использовать менее подробные данные. Пример визуализации из cs231n.
Max pooling берёт определенную группу пикселей (обычно 2 х 2) и выбирает пиксель с максимальным значением. Далее операция повторяется со сдвигом для остальных участков изображения. Часть используется больше одной пары из свёртки и пулинга; в моей модели их 2.
По итогам этих слоёв получается некое абстрактное представления изображения к которому можно присоединить полносвязный слой. Этих слоёв опять же может быть больше одного. Можно сказать, что полносвязные слой находят свойства, которые связаны с тем или иным классом.
Теперь посмотрим, что происходит в моей модели.
На вход подаётся изображение N x 28 x 28 x 1. К нему применяется фильтр 4 х 4 х 16, но благодаря zero-padding (
padding='SAME' в Tensorflow) основные измерения не уменьшаются, так что получаем N x 28 x 28 x 16. Далее идёт max pooling 2 х 2 со сдвигом 2, что даёт N x 14 x 14 x 16. Следующий свёрточный слой использует фильтр 4 х 4 х 32 и zero-padding, что даёт N x 14 x 14 x 32. После max pooling (с такими же параметрами как и прошлый) имеем N x 7 x 7 x 32. После этого начинаются полносвязные слои. У первого из них веса имеют измерения 32 * 7 * 7 х 625 или 1568 х 625, что даёт N х 625. И последний слой с весами 625 х 10 даёт вероятности принадлежности изображения к 10 классам.Замечу, что все слои кроме последнего также используют дропаут. Напомню, что дропаут подразумевает «отбрасывание» определенного процента нейронов для борьбы с переобучением.
Код работает следующим образом:
- Вначале задаётся структура нейронной сети, для удобства это делается в отдельной функции;
- Затем задаются параметры инициализации весов: нули для биасов и инициализация Ксавьера для самих весов;
- X, y и значения dropout являются входными параметрами;
- Cost считается как softmax_cross_entropy_with_logits с регуляризацией L2;
- Оптимизатор — RMSPropOptimizer;
- Я прямо задаю количество эпох (256), при желании можно это количество изменить или реализовать раннюю остановку;
- При каждой эпохе модель тренируется на тренировочных данных с dropout 0.2 для convolutional слоёв и 0.5 для полносвязных. Кроме того считаются точность и лосс для тренировочных, валидационных и «тестовых» (MNIST) данных;
- По завершению тренировки модель сохраняется в файл, чтобы её можно загрузить и использовать для предсказаний/тренировки. Отмечу, что для этого необходимо сохранить модель с указанием имени, а потом загружать, используя это имя;
Загрузка MNIST для TF реализована просто и удобно:
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
mnist_test_images = mnist.test.images.reshape(-1, 28, 28, 1)
Тренировочные и валидационные данные подготавливаются также, как и для FNN, лишь с небольшим нюансом из-за того, что модель предполагает другие измерения у данных:
trX = X_train.reshape(-1, 28, 28, 1) # 28x28x1
teX = X_val.reshape(-1, 28, 28, 1)
enc = OneHotEncoder()
enc.fit(y.reshape(-1, 1), 10).toarray() # 10x1
trY = enc.fit_transform(y_train.reshape(-1, 1)).toarray()
teY = enc.fit_transform(y_val.reshape(-1, 1)).toarray()
Тренировка и подбор параметров
Параметры CNN такие же как и в FNN, просто задаются немного по-другому. Из-за того, что CNN тренируется дольше, я пробовал меньше комбинаций параметров. Некоторые из комбинаций давали нестабильные решения, например такие:
Оптимальный же вариант был таким:
Очевидно, что нет смысла тренировать модель так долго, поэтому я перезапустил тренировку и остановился на ~100 эпохах.
Дообучение
Изменения в коде для дотренировки CNN были примерно такими же, как и для дотренировки FNN: передача весов в модель, 1 шаг, метод предсказания возвращает топ-3 предсказания и их вероятности.
Обновлённый код CNN
import numpy as np
import boto
import boto3
from boto.s3.key import Key
from boto.s3.connection import S3Connection
import tensorflow as tf
import os
class CNN(object):
"""
Convolutional neural network with several levels. The architecture is
the following:
input - conv - relu - pool - dropout - conv - relu - pool - dropout -
fully connected layer - dropout - fully connected layer
The outputs of the second fully-connected layer are the scores
for each class.
"""
def __init__(self):
"""
Initialize the model. Weights are passed into the class.
"""
self.params = {}
def train(self, image, digit):
"""
Train this neural network. 1 step of gradient descent.
Inputs:
- X: A numpy array of shape (N, 784) giving training data.
- y: A numpy array f shape (N,) giving training labels;
y[i] = c means that X[i] has label c, where 0 <= c < C.
"""
tf.reset_default_graph()
init_op = tf.global_variables_initializer()
X = tf.placeholder("float", [None, 28, 28, 1])
Y = tf.placeholder("float", [None, 10])
w = tf.get_variable("w", shape=[4, 4, 1, 16],
initializer=tf.contrib.layers.xavier_initializer())
b1 = tf.get_variable(name="b1", shape=[16],
initializer=tf.zeros_initializer())
w3 = tf.get_variable("w3", shape=[4, 4, 16, 32],
initializer=tf.contrib.layers.xavier_initializer())
b3 = tf.get_variable(name="b3", shape=[32],
initializer=tf.zeros_initializer())
w4 = tf.get_variable("w4", shape=[32 * 7 * 7, 625],
initializer=tf.contrib.layers.xavier_initializer())
b4 = tf.get_variable(name="b4", shape=[625],
initializer=tf.zeros_initializer())
w_o = tf.get_variable("w_o", shape=[625, 10],
initializer=tf.contrib.layers.xavier_initializer())
b5 = tf.get_variable(name="b5", shape=[10],
initializer=tf.zeros_initializer())
p_keep_conv = tf.placeholder("float")
p_keep_hidden = tf.placeholder("float")
l1a = tf.nn.relu(
tf.nn.conv2d(
X, w,
strides=[1, 1, 1, 1],
padding='SAME'
)
+ b1
)
l1 = tf.nn.max_pool(
l1a,
ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1],
padding='SAME')
l1 = tf.nn.dropout(l1, p_keep_conv)
l3a = tf.nn.relu(
tf.nn.conv2d(
l1, w3,
strides=[1, 1, 1, 1],
padding='SAME'
)
+ b3
)
l3 = tf.nn.max_pool(
l3a,
ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1],
padding='SAME')
#Reshape for matmul
l3 = tf.reshape(l3, [-1, w4.get_shape().as_list()[0]])
l3 = tf.nn.dropout(l3, p_keep_conv)
l4 = tf.nn.relu(tf.matmul(l3, w4) + b4)
l4 = tf.nn.dropout(l4, p_keep_hidden)
py_x = tf.matmul(l4, w_o) + b5
# Cost with L2
reg_losses = tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)
reg_constant = 0.01
cost = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(logits=py_x, labels=Y)
+ reg_constant * sum(reg_losses)
)
train_op = tf.train.RMSPropOptimizer(0.00001).minimize(cost)
predict_op = tf.argmax(py_x, 1)
with tf.Session() as sess:
# Load weights
saver = tf.train.Saver()
saver.restore(sess, "./tmp/data-all_2_updated.chkp")
trX = image.reshape(-1, 28, 28, 1)
trY = np.eye(10)[digit]
sess.run(train_op, feed_dict={X: trX,
Y: trY,
p_keep_conv: 1,
p_keep_hidden: 1})
# Save updated weights
all_saver = tf.train.Saver()
all_saver.save(sess, './tmp/data-all_2_updated.chkp')
def predict(self, image, weights='original'):
"""
Generate prediction for one or several digits. Weights are
downloaded from Amazon.
Returns:
- top_3: a list of 3 top most probable predictions with their
probabilities as tuples.
"""
s3 = boto3.client(
's3',
aws_access_key_id=os.environ['AWS_ACCESS_KEY_ID'],
aws_secret_access_key=os.environ['AWS_SECRET_ACCESS_KEY']
)
# Choose weights to load
if weights == 'original':
f = 'data-all_2.chkp'
else:
f = 'data-all_2_updated.chkp'
fn = f + '.meta'
s3.download_file('digit_draw_recognize',fn,os.path.join('tmp/',fn))
fn = f + '.index'
s3.download_file('digit_draw_recognize',fn,os.path.join('tmp/',fn))
fn = f + '.data-00000-of-00001'
s3.download_file('digit_draw_recognize',fn,os.path.join('tmp/',fn))
tf.reset_default_graph()
init_op = tf.global_variables_initializer()
sess = tf.Session()
# Define model architecture
X = tf.placeholder("float", [None, 28, 28, 1])
Y = tf.placeholder("float", [None, 10])
w = tf.get_variable("w", shape=[4, 4, 1, 16],
initializer=tf.contrib.layers.xavier_initializer())
b1 = tf.get_variable(name="b1", shape=[16],
initializer=tf.zeros_initializer())
w3 = tf.get_variable("w3", shape=[4, 4, 16, 32],
initializer=tf.contrib.layers.xavier_initializer())
b3 = tf.get_variable(name="b3", shape=[32],
initializer=tf.zeros_initializer())
w4 = tf.get_variable("w4", shape=[32 * 7 * 7, 625],
initializer=tf.contrib.layers.xavier_initializer())
w_o = tf.get_variable("w_o", shape=[625, 10],
initializer=tf.contrib.layers.xavier_initializer())
b4 = tf.get_variable(name="b4", shape=[625],
initializer=tf.zeros_initializer())
p_keep_conv = tf.placeholder("float")
p_keep_hidden = tf.placeholder("float")
b5 = tf.get_variable(name="b5", shape=[10],
initializer=tf.zeros_initializer())
l1a = tf.nn.relu(
tf.nn.conv2d(
X, w,
strides=[1, 1, 1, 1],
padding='SAME'
)
+ b1
)
l1 = tf.nn.max_pool(
l1a,
ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1],
padding='SAME')
l1 = tf.nn.dropout(l1, p_keep_conv)
l3a = tf.nn.relu(
tf.nn.conv2d(
l1, w3,
strides=[1, 1, 1, 1],
padding='SAME'
)
+ b3
)
l3 = tf.nn.max_pool(
l3a,
ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1],
padding='SAME')
l3 = tf.reshape(l3, [-1, w4.get_shape().as_list()[0]])
l3 = tf.nn.dropout(l3, p_keep_conv)
l4 = tf.nn.relu(tf.matmul(l3, w4) + b4)
l4 = tf.nn.dropout(l4, p_keep_hidden)
py_x = tf.matmul(l4, w_o) + b5
# Cost with L2
reg_losses = tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)
reg_constant = 0.01
cost = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(logits=py_x, labels=Y) +
reg_constant * sum(reg_losses)
)
train_op = tf.train.RMSPropOptimizer(0.00001).minimize(cost)
predict_op = tf.argmax(py_x, 1)
probs = tf.nn.softmax(py_x)
# Load model and predict
saver = tf.train.Saver()
saver.restore(sess, "./tmp/" + f)
y_pred = sess.run(probs, feed_dict={X: image.reshape(-1, 28, 28, 1),
p_keep_conv: 1.0,
p_keep_hidden: 1.0})
probs = y_pred
# Create list with top3 predictions and their probabilities
top_3 = list(zip(np.argsort(probs)[0][::-1][:3],
np.round(probs[0][np.argsort(probs)[0][::-1][:3]] * 100, 2)))
sess.close()
return top_3
Некоторое время опять же ушло на подбор learning rate. В итоге я остановился на 0.00001, что в 100 раз меньше оригинального значения. Впрочем, проверить успешность этого значения было проблематично. Надеюсь, что время покажет корректность или ошибку такого решения.
Дизайн и функционал сайта
Наконец пришло время сделать сам сайт (первичный вариант с рисованием картинок не считается). Во-первых, нужен был приличный дизайн, для этого я взял один из шаблонов bootstrap. Использовать эти шаблоны просто: в архиве есть html с примером страницы и css, js для верстки. Кроме того, мне нужна была таблица для отображения результатов предсказания, впрочем это было несложно.
После этого нужно было прикрутить основную функциональность. Предварительная схема выглядела вот так:
Скрипт main.py остался неизменным, зато в functions.py было много добавлений.
functions.py
__author__ = 'Artgor'
import base64
import os
import uuid
import random
import numpy as np
import boto
import boto3
from boto.s3.key import Key
from boto.s3.connection import S3Connection
from codecs import open
from PIL import Image
from scipy.ndimage.interpolation import rotate, shift
from skimage import transform
from two_layer_net import FNN
from conv_net import CNN
class Model(object):
def __init__(self):
"""
Load weights for FNN here. Original weights are loaded from
local folder, updated - from Amazon.
"""
self.params_original = np.load('models/original_weights.npy')[()]
self.params = self.load_weights_amazon('updated_weights.npy')
def process_image(self, image):
"""
Processing image for prediction. Saving in temproral folder so
that it could be opened by PIL. Cropping and scaling so that
the longest side it 20. Then putting it in a center of 28x28 blank
image. Returning array of normalized data.
"""
filename = 'digit' + '__' + str(uuid.uuid1()) + '.jpg'
with open('tmp/' + filename, 'wb') as f:
f.write(image)
img = Image.open('tmp/' + filename)
bbox = Image.eval(img, lambda px: 255-px).getbbox()
if bbox == None:
return None
widthlen = bbox[2] - bbox[0]
heightlen = bbox[3] - bbox[1]
if heightlen > widthlen:
widthlen = int(20.0 * widthlen/heightlen)
heightlen = 20
else:
heightlen = int(20.0 * widthlen/heightlen)
widthlen = 20
hstart = int((28 - heightlen) / 2)
wstart = int((28 - widthlen) / 2)
img_temp = img.crop(bbox).resize((widthlen, heightlen),
Image.NEAREST)
new_img = Image.new('L', (28,28), 255)
new_img.paste(img_temp, (wstart, hstart))
imgdata = list(new_img.getdata())
img_array = np.array([(255.0 - x) / 255.0 for x in imgdata])
return img_array
def augment(self, image, label):
"""
Augmenting image for training. Saving in temporal folder so that
it could be opened by PIL. Cropping and scaling so that the
longest side it 20. The width and height of the scaled image are
used to resize it again so that there would be 4 images with
different combinations of weight and height. Then putting it in a
center of 28x28 blank image. 12 possible angles are defined and
each image is randomly rotated by 6 of these angles. Images
converted to arrays and normalized.
Returning these arrays and labels.
"""
filename = 'digit' + '__' + str(uuid.uuid1()) + '.jpg'
with open('tmp/' + filename, 'wb') as f:
f.write(image)
image = Image.open('tmp/' + filename)
ims_add = []
labs_add = []
angles = np.arange(-30, 30, 5)
bbox = Image.eval(image, lambda px: 255-px).getbbox()
widthlen = bbox[2] - bbox[0]
heightlen = bbox[3] - bbox[1]
if heightlen > widthlen:
widthlen = int(20.0 * widthlen/heightlen)
heightlen = 20
else:
heightlen = int(20.0 * widthlen/heightlen)
widthlen = 20
hstart = int((28 - heightlen) / 2)
wstart = int((28 - widthlen) / 2)
for i in [min(widthlen, heightlen), max(widthlen, heightlen)]:
for j in [min(widthlen, heightlen), max(widthlen, heightlen)]:
resized_img = image.crop(bbox).resize((i, j), Image.NEAREST)
resized_image = Image.new('L', (28,28), 255)
resized_image.paste(resized_img, (wstart, hstart))
angles_ = random.sample(set(angles), 6)
for angle in angles_:
transformed_image = transform.rotate(np.array(resized_image),
angle, cval=255, preserve_range=True).astype(np.uint8)
labs_add.append(int(label))
img_temp = Image.fromarray(np.uint8(transformed_image))
imgdata = list(img_temp.getdata())
normalized_img = [(255.0 - x) / 255.0 for x in imgdata]
ims_add.append(normalized_img)
image_array = np.array(ims_add)
label_array = np.array(labs_add)
return image_array, label_array
def load_weights_amazon(self, filename):
"""
Load weights from Amazon. This is npy. file,
which needs to be read with np.load.
"""
s3 = boto3.client(
's3',
aws_access_key_id=os.environ['AWS_ACCESS_KEY_ID'],
aws_secret_access_key=os.environ['AWS_SECRET_ACCESS_KEY']
)
s3.download_file('digit_draw_recognize',
filename, os.path.join('tmp/', filename))
return np.load(os.path.join('tmp/', filename))[()]
def save_weights_amazon(self, filename, file):
"""
Save weights to Amazon.
"""
REGION_HOST = 's3-external-1.amazonaws.com'
conn = S3Connection(os.environ['AWS_ACCESS_KEY_ID'],
os.environ['AWS_SECRET_ACCESS_KEY'],
host=REGION_HOST)
bucket = conn.get_bucket('digit_draw_recognize')
k = Key(bucket)
k.key = filename
k.set_contents_from_filename('tmp/' + filename)
return ('Weights saved')
def save_image(self, drawn_digit, image):
"""
Save image on Amazon. Only existing files can be uploaded, so
the image is saved in a temporary folder.
"""
filename = 'digit' + str(drawn_digit) + '__' + \
str(uuid.uuid1()) + '.jpg'
with open('tmp/' + filename, 'wb') as f:
f.write(image)
REGION_HOST = 's3-external-1.amazonaws.com'
conn = S3Connection(os.environ['AWS_ACCESS_KEY_ID'],
os.environ['AWS_SECRET_ACCESS_KEY'], host=REGION_HOST)
bucket = conn.get_bucket('digit_draw_recognize')
k = Key(bucket)
k.key = filename
k.set_contents_from_filename('tmp/' + filename)
return ('Image saved successfully with the \
name {0}'.format(filename))
def predict(self, image):
"""
Predicting image. If nothing is drawn, returns a message;
otherwise 4 models are initialized and they make predictions.
They return a list of tuples with 3 top predictions and their
probabilities. These lists are sent to "select_answer" method
to select the best answer. Also tuples are converted into strings
for easier processing in JS. The answer and lists with predictions
and probabilities are returned.
"""
img_array = self.process_image(image)
if img_array is None:
return "Can't predict, when nothing is drawn"
net = FNN(self.params)
net_original = FNN(self.params_original)
cnn = CNN()
cnn_original = CNN()
top_3 = net.predict_single(img_array)
top_3_original = net_original.predict_single(img_array)
top_3_cnn = cnn.predict(img_array, weights='updated')
top_3_cnn_original = cnn_original.predict(img_array,
weights='original')
answer, top_3, top_3_original, top_3_cnn, top_3_cnn_original = self.select_answer(top_3, top_3_original, top_3_cnn, top_3_cnn_original)
answers_dict = {'answer': str(answer),
'fnn_t': top_3,
'fnn': top_3_original,
'cnn_t': top_3_cnn,
'cnn': top_3_cnn_original}
return answers_dict
def train(self, image, digit):
"""
Models are trained. Weights on Amazon are updated.
"""
r = self.save_image(digit, image)
print(r)
# Start models and train them
net = FNN(self.params)
X, y = self.augment(image, digit)
net.train(X, y)
cnn = CNN()
cnn.train(X, y)
# Save updated weights.
np.save('tmp/updated_weights.npy', net.params)
response = self.save_weights_amazon(
'updated_weights.npy',
'./tmp/updated_weights.npy'
)
response = self.save_weights_amazon(
'data-all_2_updated.chkp.meta',
'./tmp/data-all_2_updated.chkp'
)
response = self.save_weights_amazon(
'data-all_2_updated.chkp.index',
'./tmp/data-all_2_updated.chkp'
)
response = self.save_weights_amazon(
'data-all_2_updated.chkp.data-00000-of-00001',
'./tmp/data-all_2_updated.chkp'
)
return response
def select_answer(self,top_3,top_3_original,top_3_cnn,top_3_cnn_original):
"""
Selects best answer from all. In fact only from the trained models,
as they are considered to be better than untrained.
"""
answer = ''
# If answers are the same, show this answer.
if int(top_3[0][0]) == int(top_3_cnn[0][0]):
answer = str(top_3[0][0])
# If answers' probabilities are low, show fail message.
elif int(top_3[0][1]) < 50 and int(top_3_cnn[0][1]) < 50:
answer = "Can't recognize this as a digit"
# Otherwise show answer with highest probability
elif int(top_3[0][0]) != int(top_3_cnn[0][0]):
if int(top_3[0][1]) > int(top_3_cnn[0][1]):
answer = str(top_3[0][0])
else:
answer = str(top_3_cnn[0][0])
top_3 = ['{0} ({1})%'.format(i[0], i[1]) for i in top_3]
top_3_original = ['{0} ({1})%'.format(i[0], i[1]
for i in top_3_original]
top_3_cnn = ['{} ({:2.4})%'.format(i[0], i[1]) for i in top_3_cnn]
top_3_cnn_original = ['{} ({:2.4})%'.format(i[0], i[1])
for i in top_3_cnn_original]
return answer, top_3, top_3_original, top_3_cnn, top_3_cnn_original
При начальной загрузке сайта стоит сразу «запустить» модели, чтобы можно было сразу делать предсказания. Для FNN это проще — веса прямо можно передать в модель, поэтому в
init загружаются оригинальные веса и веса для модели, которая может дообучаться.Оригинальные веса не меняются, поэтому они лежат в папке tmp и грузятся напрямую (так как они лежат в папке и не изменяются, система их не трогает при завершении сессии). Веса для второй модели необходимо обновлять, поэтому они находятся в облаке Amazon. Загружаются они, используя метод load_weights_amazon
Код для получения файлов с Amazon отличается от кода для загрузки: регион не нужен, а ключи надо задавать явно (то есть нельзя, например, написать просто
os.environ['AWS_ACCESS_KEY_ID'], нужно указывать, что это за ключ: aws_access_key_id=os.environ['AWS_ACCESS_KEY_ID']). Ну а дальше указываем из какого bucket скачивается файл, его имя и куда его сохранять.В Tensorflow мне не удалось реализовать загрузку весов подобным образом, поэтому они грузятся в момент предсказания. В первый раз это занимает больше времени, при следующих предсказаниям Tensorflow работает быстрее.
При нажатии кнопки предсказания нарисованная цифра отправляется из JS в Python и идёт в метод
predict. Первое, что происходит с ней — обработка для приведения к виду, описанному выше. Если обнаруживается, что ничего не нарисовано, то процесс прерывается и выдаётся соответствующее сообщение. Вначале я хотел делать проверку на уровне JS, но не смог, поэтому она реализована здесь.После этого инициализируются все 4 модели. Веса для FNN уже загружены, поэтому они могут быстро сделать предсказания.
В CNN помимо обработанного изображения передаётся параметр для определения того, какую модель использовать — оригинальную или нет. Модели используют соответствующие веса и делают предсказания.
Теперь есть 4 модели и их предсказания. Что же показывать пользователю? Для этого есть отдельный метод
select_answer. Он сравнивает топ предсказания дотренированных FNN и CNN: если они одинаковы, то эта цифра и будет ответом; если обе модели дали предсказание с вероятностью меньше 50%, то будет сказано, что предсказать не получилось; наконец, если предсказания разные, то выбирается предсказание, которое было сделано с более высокой уверенностью (то есть вероятностью). Кроме того, ответы всех четырёх моделей округляются (точнее округляются вероятности) и превращаются в текст, для удобства обработки в JS. После этого ответы отправляются обратно в JS.JS отображает основное предсказание в соответствующем поле, а более подробные предсказания от каждой модели — в таблице.
При тренировке модели происходит следующее:
- нарисованная цифра и её лейбл (как он получается описано ниже) отправляются в Python;
- изображение аугментируется (принцип описан выше) и передаётся в модели для тренировки, которые инициализируются с актуальными весами;
- в обеих моделях есть метод train, который делает 1 шаг и возвращает обновлённые веса;
- веса сохраняются в облаке;
Теперь стоит подробнее поговорить об интерфейсе. Основные активные элементы следующие:
- сам canvas — собственно говоря, на нем рисуется цифра;
- кнопка «Predict» — при нажатии на неё модели генерят предсказание, отображается само предсказание и таблица с подробными предсказаниями для каждой модели, а также кнопки для оценки правильности предсказания;
- чекбокс «Allow to use the drawn digit for model training» — в принципе можно было бы обойтись без него, но я решил добавить. Он позволяет/запрещает тренировать модели на нарисованном изображении;
- кнопка «Yes» — в зависимости от значения чекбокса либо просто появляется сообщение, либо появляется немного другое сообщение и модели тренируются (лейблом считается предсказанное значение);
- кнопка «No» — в зависимости от значения чекбокса либо просто появляется сообщение, либо пользователю предлагается выбрать правильную цифру в выпадающем списке и подтвердить выбор (лейблом будет указанная цифра);
- кнопка «Clear» — при нажатии очищается canvas и скрываются остальные элементы интерфейса;
- кнопка для скрытия/отображения таблицы с подробными предсказаниями;
В файле JS можно увидеть как при нажатии тех или иных кнопок появляются/скрываются релевантные элементы интерфейса: для этого
document.getElementById().style.display принимает значение «none» или «block».Подготовка к запуску
На этом основная часть работы над проектом была завершена, оставалось сделать ряд улучшений, которые были необязательны, но желательны.
- Работа на мобильных устройствах. Не то чтобы целью было сделать полноценный вариант для телефонов, но хотелось иметь возможность запустить сайт в любой момент для демонстрации, а значит хоть как-то работать он должен. Благодаря bootstrap сайт уже сразу выглядел вполне прилично, оставалось лишь внести небольшие изменения. Самой большой проблемой было реализовать возможность рисовать с помощью пальцев, а не мышки. В итоге я взял код с официального сайта mozilla и модифицировал под свои нужды. Основное отличие в том, что используются другие события: ontouchstart, ontouchmove, ontouchend. После некоторых мучений я не стал внимательно изучать код, лишь убедился, что он работает;
- Мне хотелось каким-нибудь образом показывать точность моих моделей. Качество предсказаний на MNIST просто напрашивалось, так что я решил отображать общую точность и точность предсказаний для цифры, которая предсказывается хуже всего. Я также хотел обновлять эти значения после каждого предсказания… но оказалось, что бесплатный план Heroku не может сделать предсказание на таком объёме данных, после некоторых раздумий я решил несколько раз обновить эти числа вручную, а потом так и оставить;
- Ещё одним важным делом была чистка кода: уменьшение кода, переименование переменных и прочее. Здесь возникла одна проблема: первоначально я пробовал разное количество слоёв в CNN и в итоге удалил один из них. Я собирался в дальнейшем переименовать использованные переменные… и совсем забыл, что названия переменных являются частью сохраненной модели. Конечно, можно было бы перетренировать модели заново, но они была дотренированы на паре сотен изображений, и мне не хотелось терять это. После некоторых раздумий я оставил названия весов как есть и запомнил этот урок.
- Наконец, я добавил несколько страниц с описаниями: общее описание процесса работы над проектом, чуть более техническое описание работы сайта и описание моделей. Хотел бы обратить внимание на то, как реализованы ссылки для перехода между страницами. Они выглядят таким образом:
Models. Такой вид ссылок возможен благодаря Flask. Достаточно в основном скрипте python корректно определить отображения страниц и можно делать подобные ссылки, в которых указывается название страницы;
Запуск проекта
23 июля я «официально запустил» свой сайт и выложил ссылку на нескольких ресурсах. Было много положительных отзывов. Кроме того я получил несколько интересных идей и вообще понял, что не все люди смотрят на сайт так, как я предполагал (что неудивительно). На основе этих отзывов я слегка модифицировал интерфейс и при предсказании добавил возможность указать, что нарисованное изображение не является цифрой, ибо многие пробовали рисовать не цифры или спрашивали о том, может ли модель определять, что нарисована «не цифра». Об этом в следующем разделе.
Работа проекта на телефонах была с одной стороны вполне успешна — это работало. Но были 2 проблемы: иногда при рисовании экран прокручивается, побороть это пока не получается; и в коде с mozilla начало и завершение линии отмечалось кружками и квадратами. Я не сразу понял, что это может мешать предсказаниям, благо, что эту проблему было легко устранить.
Ещё один интересный момент — люди часто рисуют цифры, но не нажимают кнопки для подтверждения/опровержения предсказания (многие их тех, кому я показывал, поступали так), наверное, это уменьшает количество «положительных» примеров.
Ну а теперь немного забавного: что именно рисуют люди. К сожалению, я не сразу стал сразу собирать нарисованные картинки, но за последние 2,5 недели их было больше тысячи (это только те, которые сохранялись при дотренировке моделей). Вот примеры самых необычных цифр… или вообще не цифр:
Скорее всего тренировка на подобных изображениях приносит больше вреда чем пользы.
Возможные направления развития проекта
По итогам ~месяца работы сайта, а также обсуждений проекта (в том числе в slack ODS) появился ряд идей по улучшению проекта. Скорее всего этот проект останется в том виде, в каком он есть, но можно сделать новый с учётом этих идей.
- Хотелось бы найти возможность отфильтровывать «не-цифры». Многие об этом говорили, да и картинка выше показывает, что мусорные картинки могут мешать. Один из вариантов — взять какой-нибудь датасет типа google quickdraw и тренировать модели, присвоив этому датасету новый класс. Другой вариант — добавить SVM и делать дополнительное предсказание вида цифра или не цифра. Наконец, можно предлагать пользователю указывать, что рисунок — не цифра (уже сделано), а потом дотренировывать модели на этих данных;
- Сегментация изображения. Можно сделать возможность распознавания нескольких цифр: для этого надо научиться находить цифры на рисунке и распознавать их по-отдельности;
- Улучшить работу на телефонах — как минимум заблокировать прокрутку экрана при рисовании цифр;
- Сделать счётчик предсказаний и/или дотренировок;
- Найти/придумать адекватную метрику для оценки точности модели в целом. Может быть просто на основе того, сколько раз пользователи нажимали кнопки «Yes» и «No»;
- Возможно сделать отдельные модели для PC и для мобильных устройств — для оценки целесообразности этого надо проверить насколько различаются цифры, нарисованные на разных устройствах;
Заключение
В целом я очень доволен получившимся проектом. Изучил много нового и приобрёл полезные навыки. Смог осуществить полный процесс от создания плана и сбора данных до запуска. Получил хорошие идеи на будущее. И вообще это было весьма интересно. Считаю, что для тех, кто решил начать карьеру в data science и машинном обучении, подобные самостоятельные проекты являются одним из лучших способов освоения материала.
