
Каждый пятый житель США владеет умной колонкой, а это 47 000 000 человек. Помощник может создать напоминание, список дел, будильник, таймер, прочитать новости, включить музыку, подкаст, заказать доставку, купить билеты в кино и вызвать такси. Все это «навыки» или «skills» помощников. Еще их называют голосовыми приложениями. Для Alexa и Google Assistant таких приложений на 2018 год разработано 70 000.
В 2017 году Starbucks запустил функцию по заказу кофе домой для Amazon Alexa. Кроме того, что выросли заказы на доставку, об этом написали все возможные СМИ, создав классный PR. Примеру Starbucks последовали Uber, Domino’s, MacDonald’s, и даже у стирального порошка Tide появился свой skill для Alexa.
Как у Starbucks, голосовое приложение выполняет одну-две функции: заказывает кофе, ставит будильник или вызывает курьера. Чтобы спроектировать нечто подобное, не обязательно быть межконтинентальной корпорацией. Идея, проектирование, тестирование, разработка и релиз похожи на аналогичные этапы в мире мобильной разработки, но с особенностями для голоса. Подробно о процессе рассказал Павел Гвай: от идеи до публикации, с примерами реальной игры, с историческими вставками и разбором мира голосовой разработки.
О спикере: Павел Гвай (pavelgvay) — проектирует голосовые интерфейсы в студии мобильной разработки KODE. Студия разрабатывает мобильные приложения, например, для Utair, Победа, РосЕвроБанк, BlueOrange Bank и Whiskas, но в KODE существует подразделение, которое занимается голосовыми приложениями для Яндекс.Алисы и Google Assistant. Павел участвовал в нескольких реальных проектах, обменивается опытом с разработчиками и дизайнерами в этой сфере, в том числе из США и выступает на тематических конференциях. Кроме того Павел основатель стартапа tortu.io — инструмента для дизайна голосовых приложений.
Что такое разговорное приложение
В разговорном приложении канал взаимодействия с пользователем строится через разговор: устный — с умной колонкой, или через письменный, например, с Google Assistant. Кроме колонки, устройством взаимодействия может быть экран, поэтому разговорные приложения еще и графические.
У голосовых приложений есть важное преимущество перед мобильными: их не надо скачивать и устанавливать. Достаточно знать название, и ассистент сам все запустит.
Все потому, что нечего скачивать — и распознавание речи, и бизнес-логика — все приложение живет в облаке. Это огромное преимущество перед мобильными приложениями.
Немного истории
История голосовых помощников началась с Interactive Voice Response — интерактивной системы записанных голосовых ответов. Возможно, никто не слышал этот термин, но все сталкивались, когда звонили в техподдержку и слышали робота: «Нажмите 1, чтобы попасть в главное меню. Нажмите 2, чтобы узнать подробней» — это и есть IVR система. Отчасти, IVR можно назвать первым поколением голосовых приложений. Хотя они уже часть истории, но кое-чему могут нас научить.
Большинство людей при взаимодействии с IVR-системой стараются связаться с оператором. Это происходит из-за плохого UX, когда взаимодействие основано на жестких командах, что просто неудобно.
Это подводит нас к основному правилу хорошего разговорного приложения.
Разговор с приложением должен быть больше похож на звонок в пиццерию для заказа, чем на общение командами с чат-ботом. Достичь такой же гибкости, как в разговоре между людьми, не получится, но говорить с приложением комфортно и естественным языком — вполне.
В этом тоже преимущество голоса перед графическими приложениями: не нужно учиться пользоваться. Моя бабушка не умеет заходить на сайты или заказывать пиццу через приложение, но вызвать доставку через колонку сможет. Мы должны использовать это преимущество и подстраиваться под то, как говорят люди, а не учить их говорить с нашим приложением.
От IVR-систем перейдем к настоящему — к виртуальным помощникам.
Виртуальные помощники
Голосовой мир крутится вокруг виртуальных помощников: Google Assistant, Amazon Alexa и Алиса.
Все устроено почти как в мобильном мире, только вместо платформ iOS и Android здесь Алиса, Google Assistant и Alexa, вместо графических приложений — голосовые, с собственными названиями или именами, и у каждого помощника свой внутренний магазин голосовых приложений. Опять же, говорить «приложение» неправильно, так как у каждой платформы свой термин: у Алисы — «навыки», у Алексы — «skills», а у Google — «actions».
Чтобы запустить skill, я прошу ассистента: «Алекса, передай Starbucks, что я хочу кофе!», Алекса найдет приложение кофейни в своем магазине и передаст ему разговор. Дальше разговор идет не между Алексой и пользователем, а между пользователем и приложением. Многие путаются и думают, что с ними продолжает говорить ассистент, хотя у приложения уже другой голос.
Так выглядят магазины приложений. Интерфейс напоминает App Store и Google Play.

Этапы разработки разговорного приложения
Для пользователя у приложения нет никакой графической части — все выглядит как набор диалога. Внешне может показаться, что приложение — это простая вещь, создать его просто, но это не так. Этапы разработки такие же, как и у мобильных приложений.
Два первых этапа специфичны, так как приложения разговорные, а два последних — стандартны.
Пройдем каждый из этапов на примере игры «Угадай цену», которая запущена под Google Assistant. Механика простая: приложение показывает пользователю карточку с товаром, а он должен угадать цену.
Начнем погружение с первого этапа: мы определились с идеей, провели аналитику, поняли, что у пользователя есть потребность и приступаем к созданию голосового приложения.
Проектирование
Главная цель — спроектировать взаимодействие между пользователем и приложением. В мобильном мире этот этап называется дизайном. Если дизайнер графических приложений рисует карты экранов, кнопки, формы и подбирает цвета, то VUI-дизайнер прорабатывает диалог между пользователем и приложением: прописывает различные ветки диалога, думает о развилках и побочных сценариях, выбирает варианты фраз.
Проектирование ведется в три этапа.
Примеры диалогов
Первое, что надо сделать — это понять, как будет работать приложение. Понимание и видение потребуется транслировать на всех остальных, особенно, если вы аутсорс-компания, и вам придется объяснять заказчику, что он в итоге получит.
Мощный инструмент в помощь — примеры диалогов: разговор между пользователем и приложением по ролям, как в пьесе.
Пример диалога для нашей игры.

Приложение здоровается, рассказывает пользователю о правилах, предлагает сыграть, и, если человек соглашается, показывает карточку с товаром, чтобы пользователь угадал цену.
Сценарий помогает быстро понять, как будет работать приложение, что оно сможет сделать, но, помимо этого, примеры диалогов помогают отсеять главную ошибку в мире голосовых интерфейсов — работу над неправильными сценариями.
Голос и графика существенно отличаются, и не все, что работает на графических интерфейсах, хорошо работает на голосе. Почти в каждом мобильном приложении есть регистрация, но я не могу представить, как можно зарегистрироваться голосом? Как диктовать умной колонке пароль: «Большая буква, маленькая буква, эс как доллар...» — и все это вслух. А если я не один, а на работе? Это пример ошибочного сценария. Если вы начнете разработку сценария с ошибкой, то с ним возникнут проблемы: вы не поймете, как его выполнить, пользователи не поймут как им пользоваться.
Примеры диалогов помогут найти подобные моменты. Чтобы найти ошибки в сценариях, запишите диалог, выберете коллегу, посадите напротив и отыграйте роли: вы — пользователь, коллега — приложение. После ролевого зачитывания диалога станет ясно, звучит приложение или нет, и будет ли пользователю удобно.
Такая проблема будет появляться постоянно. Если у вас in-house разработка, то возникнет соблазн: «У нас уже есть сайт, давайте просто сконвертируем его в голос и все будет хорошо!» Либо придет заказчик и скажет: «Вот мобильное приложение. Сделайте то же самое, только голосом!» Но так делать нельзя. Вы, как специалист, должны быстро находить сценарии, над которыми не стоит работать, и объяснять заказчику почему. Примеры диалогов здесь помогут.
Для прописывания диалогов подойдет абсолютно любой текстовый редактор, к которому вы привыкли. Главное — запишите текст и зачитайте его по ролям.
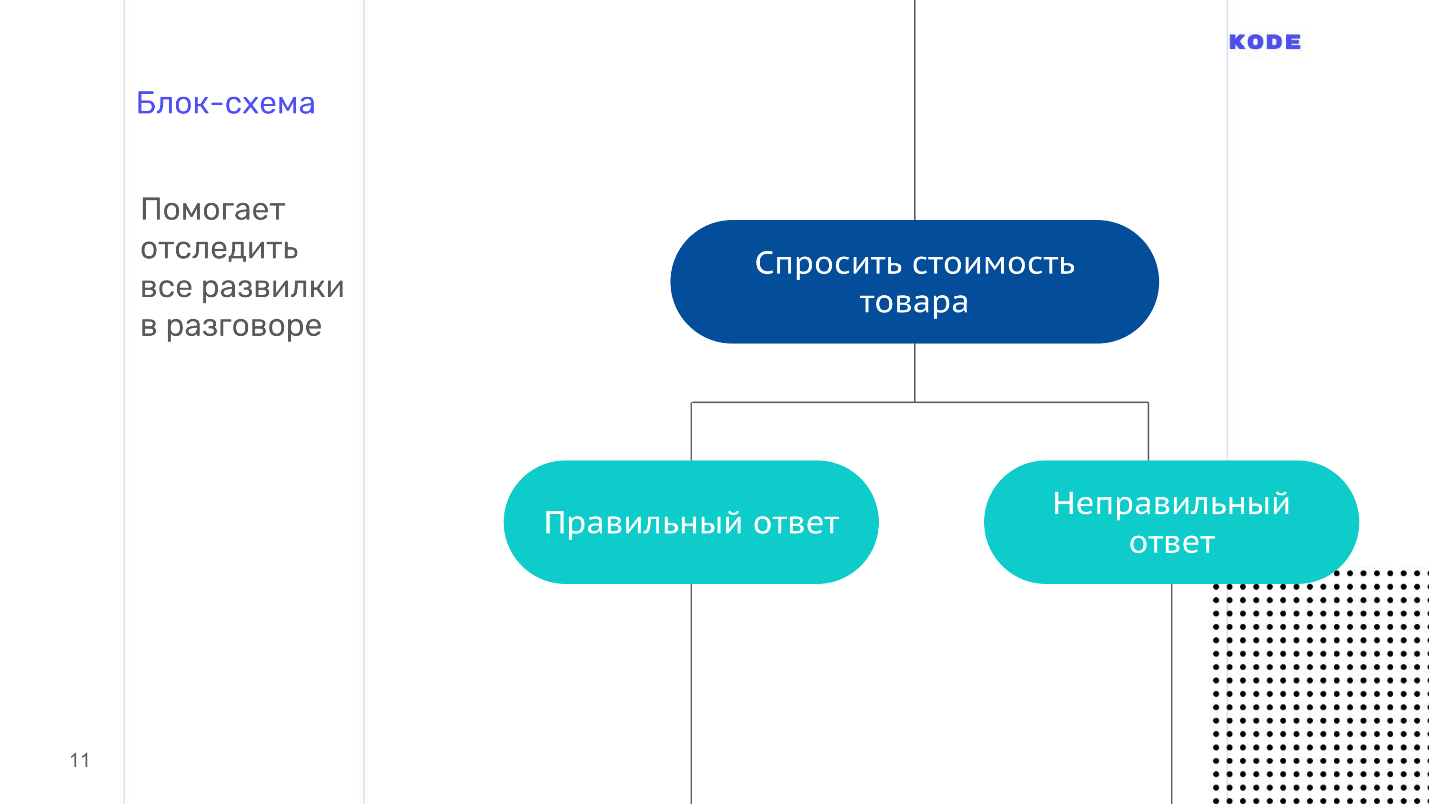
Блок-схема
Примеры диалогов — это мощный, быстрый и дешевый инструмент, но они описывают только линейное развитие событий, а разговоры всегда нелинейны. Например, в нашей игре «Угадай цену», пользователь может ответить на вопрос правильно или неправильно — это первая развилка из множества тех, что будут встречаться дальше.
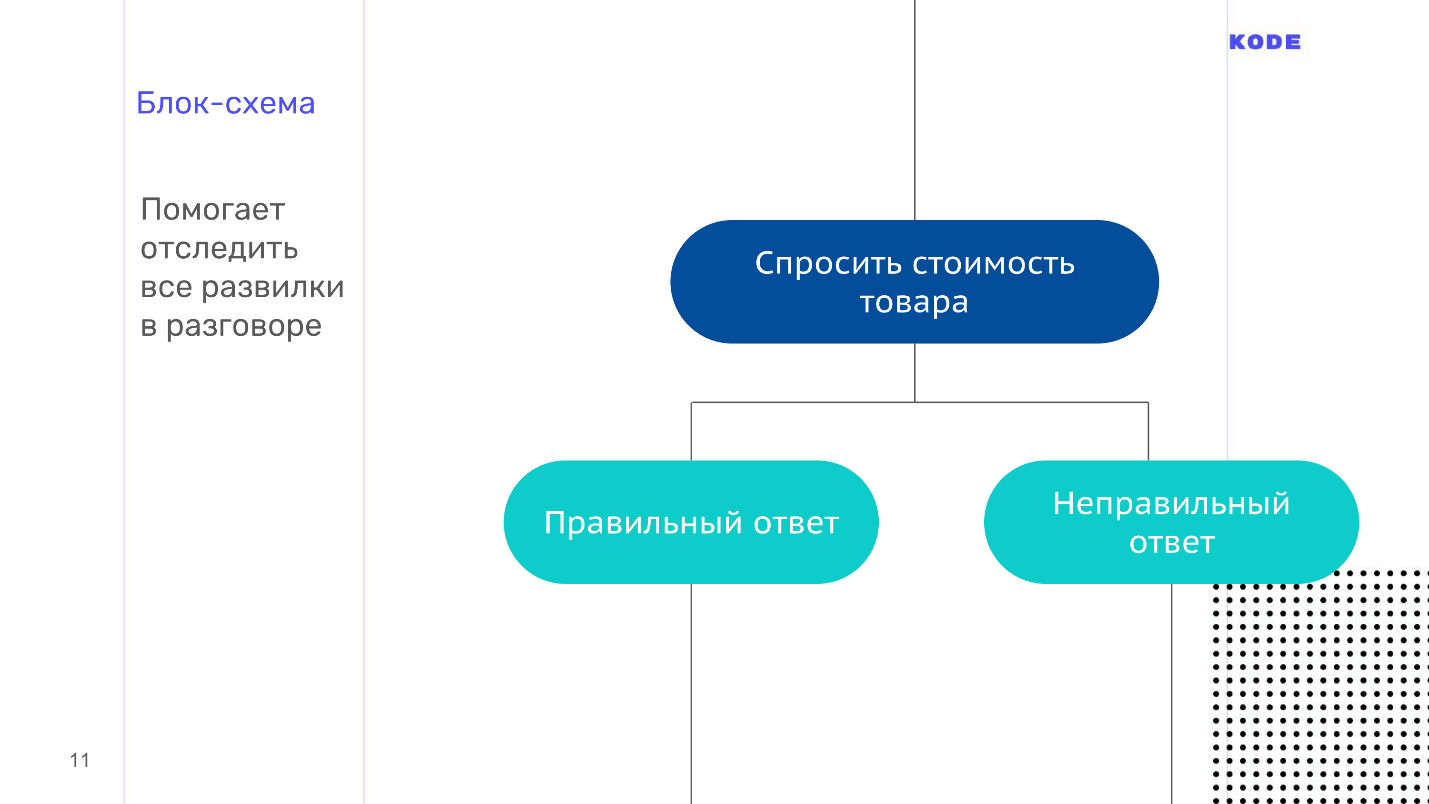
Чтобы не запутаться во всех ветках диалога вашего приложения, составьте блок-схему — визуализацию диалога. Она состоит всего из двух элементов:
Блок-схема — это карта нашего приложения, но с одним неприятным свойством — она сильно разрастается, становится нечитаемой и визуально непонятной. Вот, например, скриншот с частью блок-схемы из сценария, где пользователь угадывает цену, с несколькими развилками.
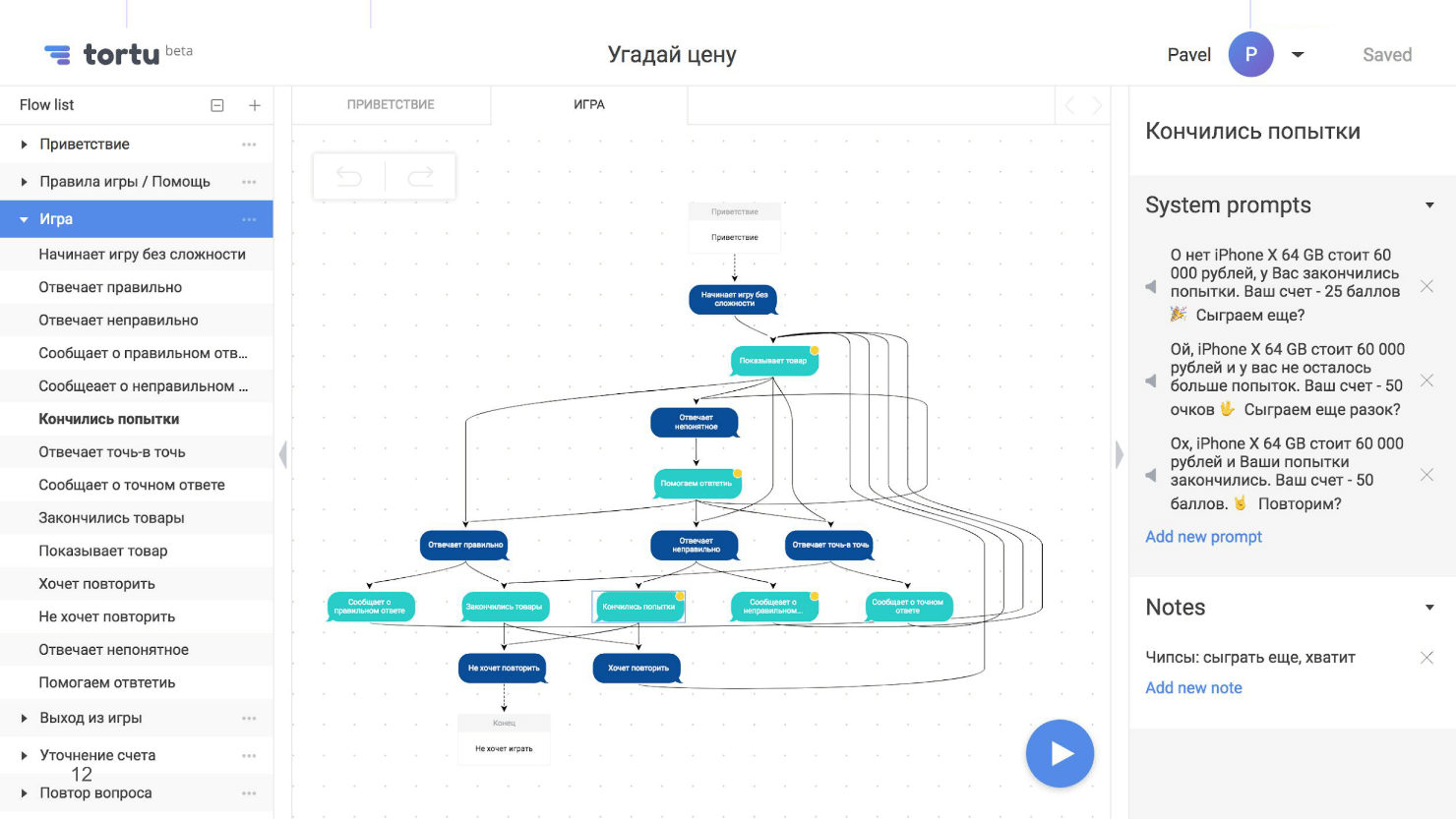
Несколько развилок — еще не предел, их может быть десятки или сотни. Мы задавали себе вопросы: «Что произойдет, если человек ответит правильно? А если нет? Что будет, если закончатся попытки? Что если кончатся товары? А если он угадает цену точно? Что если интернет пропадет на этом шаге или на другом?» В итоге мы создали огромную нечитаемую схему.
В этом мы не одиноки. Я общался с дизайнером из США, которая работала над серьезным проектом. В проекте был и IVR, и банк, и skill одновременно, и все это раздуло блок-схему до 600 листов. До конца схему никто не понимал, а когда дизайнер ее увидела, то просто ужаснулась.
У меня есть совет, как этого не допустить. Схема всегда будет разрастаться, но никогда не пытайтесь построить одну большую блок-схему на все приложение — она будет громоздкой, и никто кроме вас в ней не разберется. Идите от обратного и разбейте схему на логические части: отдельно сценарий угадывания цены, отдельно сценарий помощи. По необходимости разбейте и эти сценарии на подсценарии. В итоге получится не одна большая карта с непонятными связями, а много маленьких, читабельных, хорошо связанных между собой схем, в которых всем удобно ориентироваться.
Для блок-схем подойдет любой инструмент. Раньше я использовал RealtimeBoard, а еще естьDraw.io и даже XMind. В итоге разработал свой, потому что просто удобнее. На картинке как раз он и представлен. Этот инструмент поддерживает, в том числе, разбивку на подсценарии.
prompt lists
Последний артефакт, который мы сформируем на этапе проектирования. prompt list — это список всех возможных фраз, которые может произнести приложение.
Здесь есть одна тонкость. Разговор с приложением должен быть гибким и похожим на разговор с человеком. Это означает не только возможность пройти разными ветками, что мы делали на этапе блок-схемы, а звучание разговора в целом. Человек никогда не будет отвечать одной и той же фразой, если вы будете задавать один и тот же вопрос. Ответ всегда будет перефразирован и звучать как-то иначе. Приложение должно поступать так же, поэтому на каждый шаг диалога от лица приложения напишите не один вариант ответа, а как минимум пять.

По prompt листам есть еще важная вещь. Общение должно быть не только живым и гибким, но и консистентным в плане стиля речи и общего ощущения общения пользователя с вашим приложением. Для этого дизайнеры используют отличный прием — создание персонажа. Когда я звоню своему другу, то не вижу его, но подсознательно представляю собеседника. У пользователя при общении с умной колонкой то же самое. Это называется парейдалия.
На этапе prompt листов вы создаете персонажа, от лица которого приложение будет разговаривать. С персонажем ваши пользователи будут ассоциировать бренд и приложение — это может быть реальный человек или вымышленный. Проработайте для него внешность, биографию, характер и юмор, но если времени нет, то просто приведите все ваши фразы в prompt листах к единому стилю. Если вы начали обращаться к пользователю на «Вы», то не обращайтесь в других местах на «Ты». Если у вас неформальный стиль общения, то придерживайтесь его везде.
Обычно для создания prompt листов используют Excel или Google-таблицы, но при с ними возникают огромные временные потери на рутинную работу. Блок-схема и табличка с фразами никак не связаны друг с другом, любые правки приходится переносить вручную, что выливается в постоянную и долгую рутину.
Я использую не Excel, а свой инструмент, потому что в нем все фразы пишутся прямо в блок-схеме, они закреплены за шагом диалога. Это избавляет от рутины.
Кажется, что теперь все готово и можно дать задание разработчикам и приниматься за код, но остался еще один важный этап — тестирование. Мы должны удостовериться, что как дизайнеры все сделали правильно, что приложение будет работать как мы хотим, что все фразы в одном стиле, что мы покрыли все побочные ветки и обработали все ошибки.
Тестирование
Тестирование на таком раннем этапе особенно важно для голосовых приложений. В мире графических интерфейсов пользователь ограничен тем, что нарисовал дизайнер: он не зайдет за пределы экрана, не найдет кнопку, которой не существует, а будет нажимать только на то, что есть…
В мире голоса все не так: пользователь волен говорить все, что угодно, и вы не знаете, как он начнет работать с вашим приложением, пока это не увидите. Лучше это сделать на раннем этапе проектирования и подготовиться к неожиданностям, пока не началась дорогая разработка.
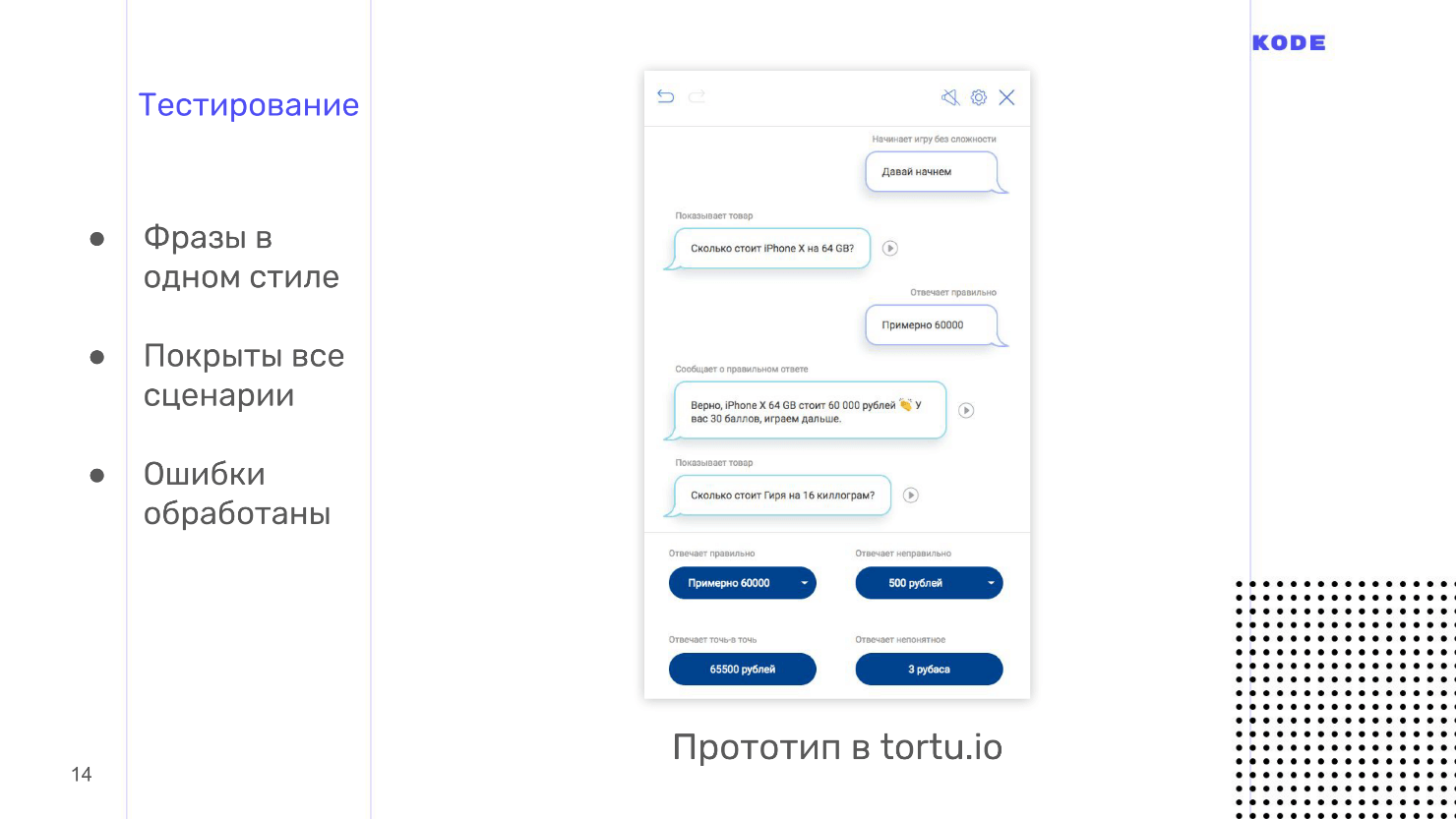
Приложения тестируются с помощью методологии Wizard of Oz. Она используется и в графических приложениях, но реже, а в голосе это must have. Это метод, когда пользователь взаимодействует с системой, предполагая, что она существует и работает сама по себе, но всем процессом управляете вы.
Тестирование производится с помощью интерактивных прототипов. Обычно дизайнеру приходится просить разработчиков создать прототип, но лично я использую свой инструмент, потому что в нем все делается в один клик и не надо никого ждать. Еще нам нужен пользователь. Мы зовем человека, который никак не вовлечен в разработку, ничего не знает о приложении и, в идеале, входит в вашу ЦА. Вы приглашаете человека, объясняете, что это за приложение, как им пользоваться, сажаете в комнате, включаете интерактивный прототип и пользователь начинает с ним разговаривать. Прототип не распознает речь, а это вы слышите, что говорит человек, и выбираете вариант ответа, которым приложение отвечает на каждую фразу.
Если пользователь не видит экран, то ему кажется, что приложение работает само по себе, но процессом управляете вы. Это и есть тестирование Wizard of Oz. С его помощью вы не только услышите, как звучит приложение, но и увидите, как люди его используют. Гарантирую, что вы найдете много непокрытых сценариев.
Когда я тестировал игру, то позвал своего друга. Он начал угадывать цену и сказал, что какая-то мазь стоит «пятихат». Я не ожидал такого слова, думал, что будут варианты в 500 рублей, тысячу рублей, а не «пятихат» или «косарь». Это мелочь, которая вскрылась на тестировании. Люди пользуются приложением иначе, чем вы представляете, и тестирование вскрывает подобные мелочи и нерабочие сценарии.
На этом этап проектирования заканчивается и у нас на руках есть примеры диалогов, блок схема — логическое описание работы приложения, и prompt-листы — то, что приложение говорит. Все это мы отдадим разработчикам. Перед тем, как я расскажу как разработчики создают приложения, поделюсь советами по проектированию.
Советы
Используйте язык разметки SSML — как HTML, только для речи. SSML позволяет проставить паузы, выставить уровень эмпатии, ударение, прописать, что прочитать по буквам и где сделать акцент.

Размеченная речь звучит намного лучше, чем роботическая, а чем лучше звучит приложение, тем приятнее им пользоваться. Поэтому используйте SSML — он не такой уж и сложный.
Думайте о моментах, в которых пользователи обращаются к вашему приложению за помощью. Для голоса это особенно важно. Человек может разговаривать с колонкой в одиночестве в комнате, а может ехать в автобусе и общаться со смартфоном. Это два принципиально разных сценария поведения для голосового приложения. Подобная ситуация у нас была с банковским приложением. В приложении был сценарий, когда пользователь получает информацию о счете, а это приватная информация. Я подумал — если человек разговаривает дома, то все нормально, но, если он едет в автобусе, а приложение начнет озвучивать баланс карты вслух — будет некрасиво.
Подумав о таких моментах, вы можете определить, что если пользователь разговаривает со смартфоном, пусть даже голосом, то приватную информацию лучше не зачитывать вслух, а показать на экране.
Это дизайн под разные поверхности и платформы. Голосовые устройства очень разные по своей фактуре. В мобильном мире устройства различаются только платформой и размером экрана — форм-фактором. С голосом все иначе. Например, у колонки вообще нет экрана — только голос. У смартфона есть экран, и его можно тапать пальцем. У телевизора экран огромный, но к нему бесполезно прикасаться. Подумайте, как ваше приложение будет работать на каждой из таких поверхностей.
Например, пользователь совершил покупку и мы хотим показать чек. Зачитывать чек вслух — плохая идея, потому что информации много и никто ее не запомнит, так как голосовая информация воспринимается сложно и тяжело.

Используя принцип мультимодального дизайна, мы понимаем, что если есть экран, то чек лучше показать, вместо того, чтобы читать. Если экрана нет, то мы вынуждены проговорить вслух основные данные чека.
На этом проектирование закончено. То, что я рассказал — это основы, верхушка айсберга. Для самостоятельного изучения проектирования, я собрал много материала по проектированию, в конце статьи будут ссылки.
Разработка
Разговор начнем с универсальной схемы работы приложения под любой платформой. Схема работает и с Алисой, и с Amazon Alexa, и с Google Assistant.
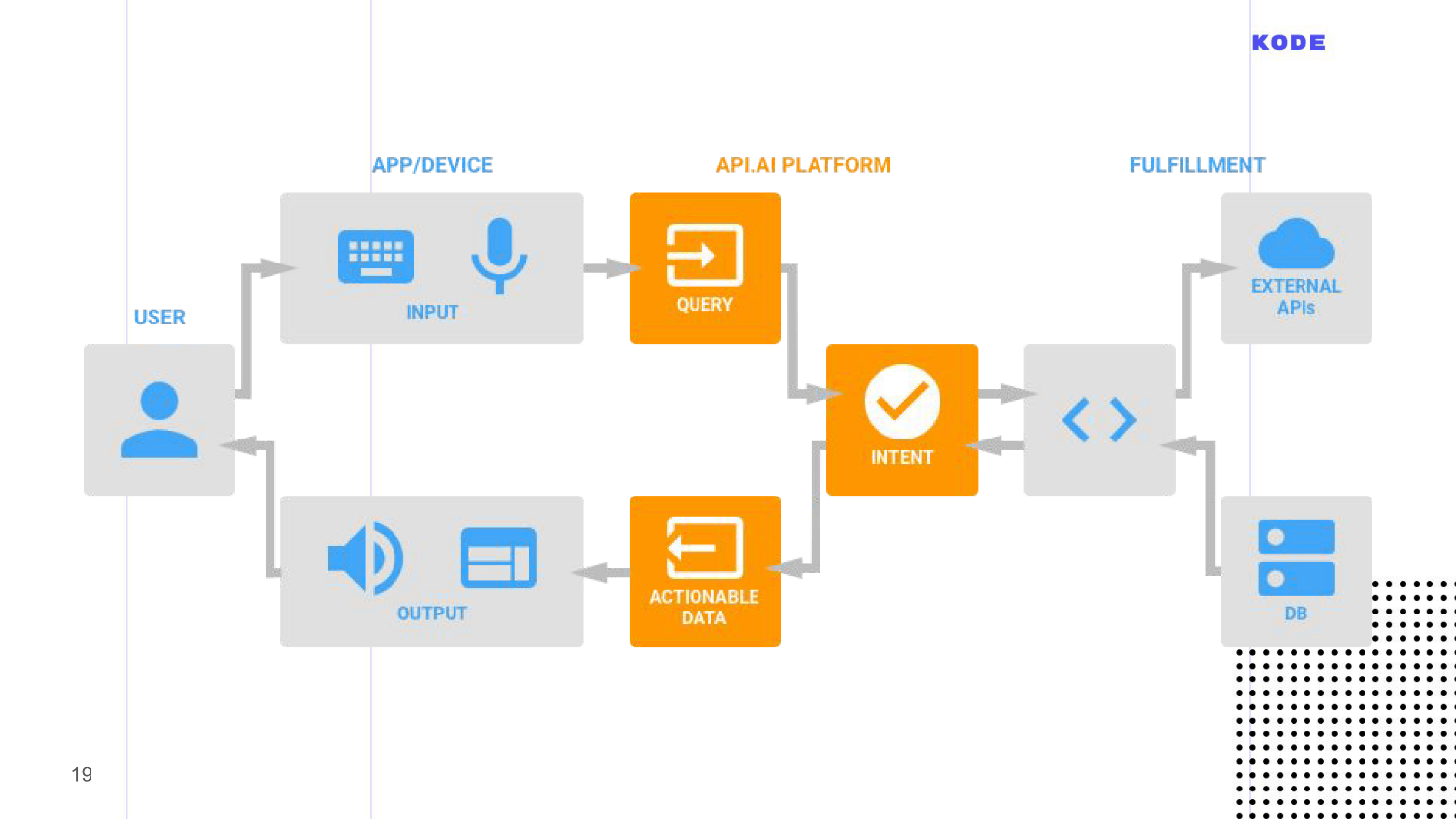
Когда пользователь просит запустить наше приложение, ассистент это делает и передает приложению контроль за разговором. Пользователь что-то говорит и в приложение попадает сырой текст, который проходит обработку системой распознавания речи.
Для обработки мы используем Dialogflow, его структура абсолютно такая же, как и у других систем понимания речи, и разработку будем рассматривать на его примере.
Мы переходим к первому звену — к системе понимания человеческой речи или Natural Language Understanding — NLU.
Dialogflow
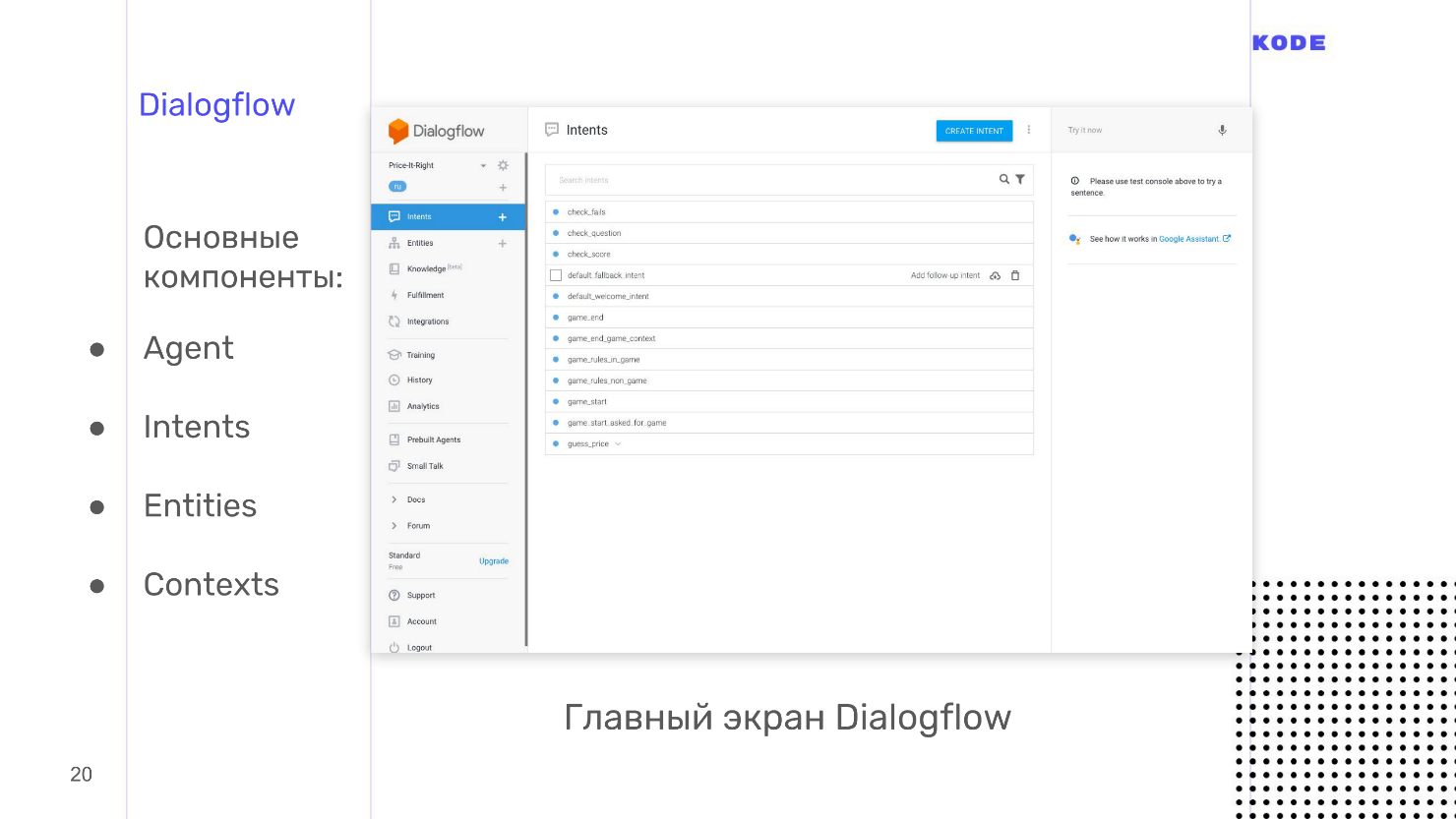
Мы используем Dialogflow, потому что у него богатые возможности, хорошая документация, живая поддержка и его просто и быстро освоить. Dialogflow кроссплатформенный инструмент: основная квалификация — приложения для Google Assistant, но для Яндекс-Алисы, Amazon Alexa и создания ботов в Telegram его тоже можно использовать. Отдельный плюс — открытое API. Вы можете использовать систему, чтобы разработать голосовое управление для сайта или уже существующего мобильного приложения.
Основные компоненты Dialogflow.
Пройдемся по всем компонентам, но начнем с главного — это Intents.
Intents
Это пользовательское намерение, то, что пользователь хочет совершить. Намерение выражается фразами. Например, в игре пользователь хочет узнать правила игры и говорит: «Расскажи правила игры», «Скажи, как играть?», «Помоги мне — я запутался» или что-нибудь в таком духе. Соответственно, мы создаем отдельный Intent для правил игры, и на вход пишем все эти фразы, которые ожидаем от пользователя.
Я советую писать 10 и больше вариантов фраз. В таком случае распознавание речи будет работать лучше, потому что в Dialogflow используется нейронная сеть, которая принимает эти 10 фраз на вход, и генерирует из них кучу других, похожих. Чем больше вариантов, тем лучше, но не переборщите.
У Intent должен быть ответ на любой вопрос пользователя. В Dialogflow ответ можно сформировать без применения логики, а если логика нужна, то передаем ответ из webhook. Ответы могут быть разные, но стандартный — это текст: озвучивается на колонках, показывается или проговаривается на смартфонах.
В зависимости от платформы доступны дополнительные «плюшки» — графические элементы. Например, для Google Assistant это кнопки, карточки, списки, карусели. Они показываются только если человек говорит с Google Assistant на смартфоне, телевизоре или другом подобном устройстве.
Entities
Intent запускается, когда пользователь что-то говорит. В этот момент передается информация — параметры, которые называются слотами, а тип данных параметров — Entities. Например, для нашей игры, это примеры фраз, которые говорит пользователь, когда угадывает цену. Здесь есть два параметра: сумма и валюта.

Параметры могут быть обязательными и необязательными. Если пользователь ответит «две тысячи», то фразы будет достаточно. По умолчанию мы возьмем рубли, поэтому валюта — необязательный параметр. Но без суммы мы не сможем понять ответ, потому что пользователь может ответить на вопрос не конкретно:
— Сколько стоит?
— Много!
Для таких случаев в Dialogflow есть понятие re-prompt — это фраза, которая будет произнесена, когда пользователь не назвал обязательный параметр. Для каждого параметра фраза задается отдельно. Для суммы это может быть что-то вроде: «Назовите точную цифру, сколько стоит ...»
У каждого параметра обязательно должен быть тип данных — Entities. В Dialogflow много стандартных типов данных — города, имена, и это спасает. Система сама определяет, что есть имя, что есть число, а что город, но можно задавать и свои кастомные типы. Валюта в Dialogflow — кастомный тип. Мы создали ее сами^ описали техническое системное название, которым будем пользоваться, и синонимы, которые отвечают этому параметру. Для валюты это рубль, доллар, евро. Когда пользователь говорит: «Евро», то Dialogflow подсвечивает, что это наш параметр «валюта»
Context
Воспринимайте это слово буквально: context — это контекст того, о чем вы говорите с пользователем. Например, у ассистента можно спросить: «Кто написал Муму?» и он ответит, что это Тургенев. Вдогонку можно спросить, когда он родился. Обращаю внимание, что мы спрашиваем: «Когда он родился», не уточняя кто. Google поймет, потому что помнит — в контексте разговора Тургенев.
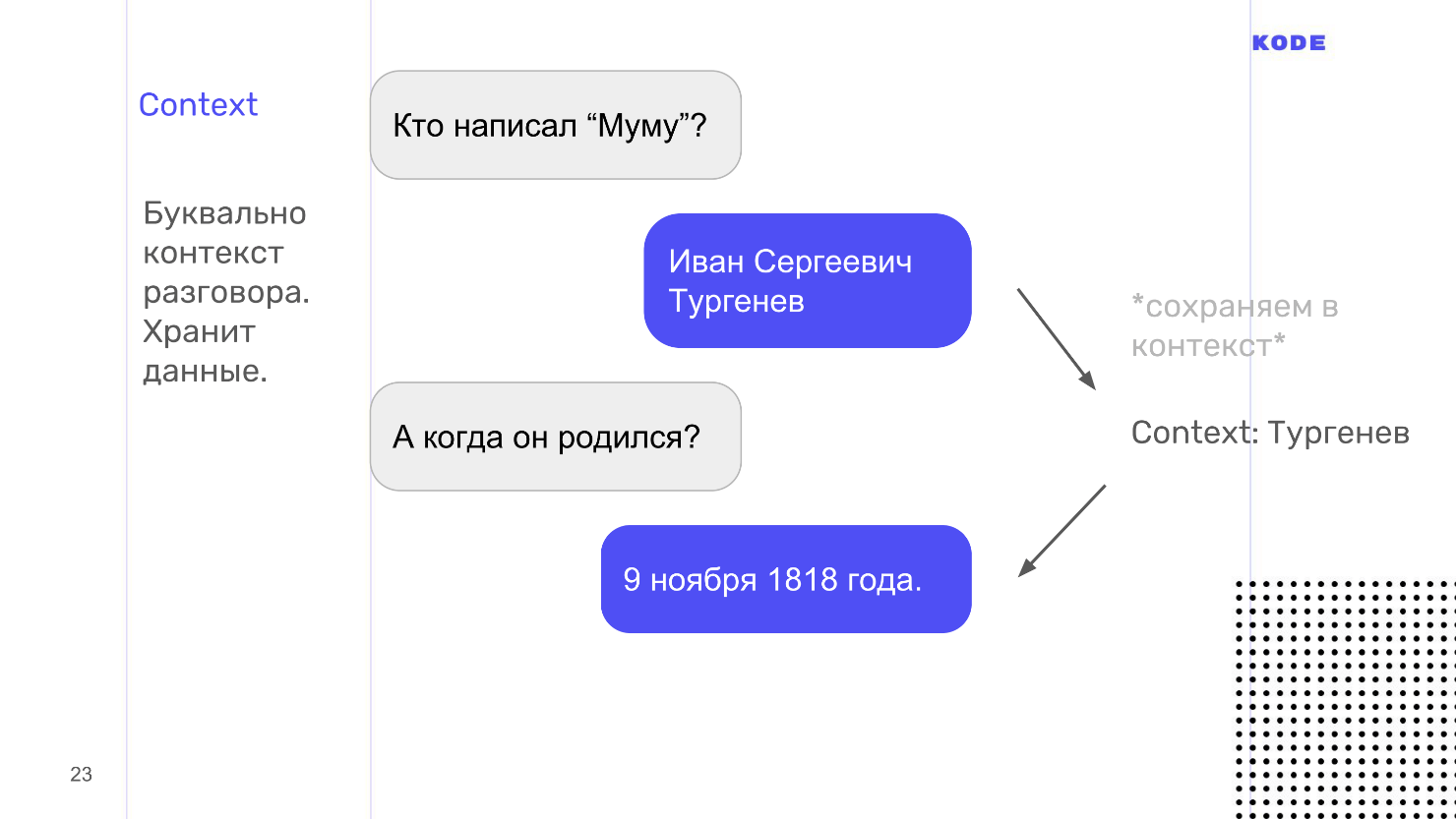
С технической точки зрения context — это хранилище типа «ключ — значение», в которое складывается информация. Intent может либо испускать context из себя, складывая в него что-то, либо принимать на вход и доставать информацию оттуда. У context есть время жизни. Оно определяется количеством шагов диалога от последнего упоминания: например, через 5 шагов диалога забыть, что мы говорили про Тургенева.
У context есть еще одна важная функция — он может помочь нам разбить приложение на логические зоны: на авторизованную и неавторизованную, на игровую сессию или нет. Разбивка строится так, что Intent, который принимает context на вход, не может быть запущен без контекста и требует предыдущего запуска другого Intent. Так мы можем логически связывать и строить наше приложение.

Я упоминал webhook.У Dialogflow есть библиотеки под абсолютно разные языки, мы использовали JS. У Google Assistant для webhook есть ограничение — ответ с него должен прийти не позднее, чем через 5 секунд, иначе выпадет ошибка и приложение сработает в fallback. Для Алисы, время ответа — 1,5 или 3 секунды.
Публикация

Публикация стандартна, почти как с мобильными приложениями, но с парой нюансов.
Обратите отдельное, особое и очень пристальное внимание на название приложения. Пользователь будет его произносить вслух каждый раз при запуске. Поэтому название должно быть простым для произношения и простым для распознавания ассистентом, потому что с этим иногда бывают проблемы.
У названия есть два правила:
В Google Assistant стандартная фраза, которая запускает любое приложение — «ОК, Google, поговори с...». Вы можете воспользоваться этой фичей, например, сказать: «ОК, Google, поговори с Uber» — и он запустит приложение на главном экране, на стартовой точке. Но можно сделать так, чтобы пользователь сказал: «ОК, Google, скажи Uber забрать меня отсюда и отвезти туда!» мы сокращаем одну итерацию, и пользователь попадет в нужное действие.
Сценарий определяется фразами, которыми запускается приложение. Они устанавливаются при публикации, но часто работают некорректно — на русском языке точно. Например, в нашей игре фраза «Давай сыграем» работала, а «Давай поиграем» не работала. Я не знаю, в чем принципиальная разница между «сыграем» и «поиграем» для Google Assistant. Он распознавал обе фразы корректно, но приложение не работало, хотя с английским языком у нас проблем не возникало.
В остальном публикация проходит гладко, без лишних вопросов. Поддержка у Google Assistant очень живая, отвечает быстро, и документация хорошая.
Также хочу отметить разные виды релизов.
Казалось бы, на этом все, но мы говорим про голос, поэтому здесь есть еще один важный момент — это аналитика.
Аналитика
Особенно важна для голоса. Если для мобильных приложений аналитика показывает косяки, баги и системные ошибки, то в мире голоса аналитика раскрывает нам упущенные возможности — то, как люди хотели использовать наше приложение, но не смогли.
Это обязательный этап. Именно поэтому, в Dialogflow есть стандартные инструменты для анализа приложений со следующими режимами:
Они показываются списком и выглядят, как на картинке. Пользователь отгадывал цену какого-то мотора и сказал: «4 штуки». Про «косари» я вспомнил на тестировании, а про «штуки» забыл — поэтому придется чинить.
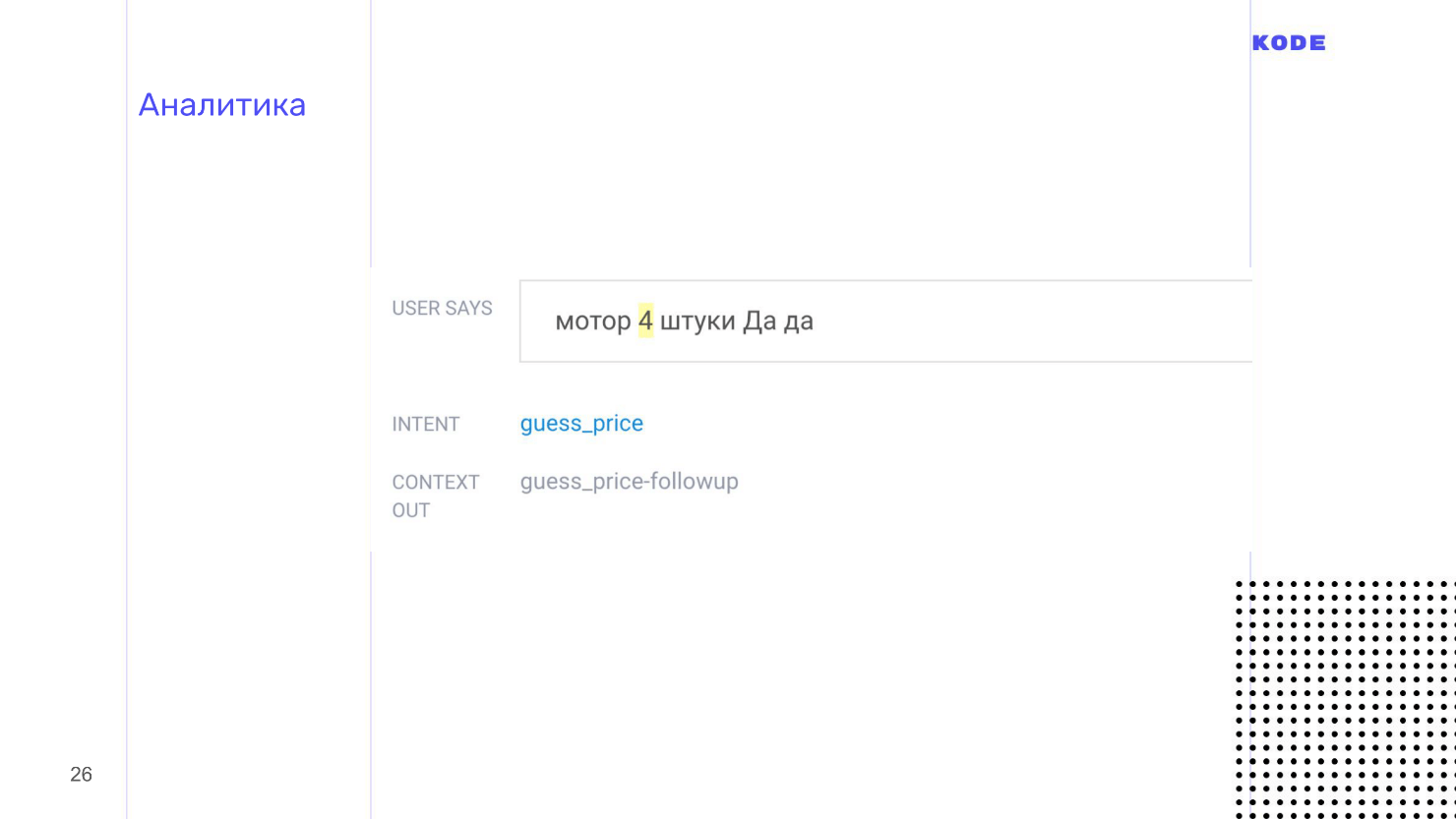
Аналитика помогает найти недоработки, поэтому обязательно смотрите в логи и проверяйте, что происходит с вашим приложением и что с ним делают пользователи.
На этом все про голосовые приложения. Надеюсь, что у вас появилось хотя бы минимальное понимание как они разрабатываются. Доклад был общим, но все дополнительные материалы про разработку, проектирование и бизнес-часть собраны по ссылкам.
Полезные ссылки и контакты
Телеграм-чат разработчиков голосовых интерфейсов
Телеграм-чат Яндекс.Диалоги
Slack-чат разработчиков Amazon Alexa
Slack-чат разработчиков Google Assistant
Гайдлайны Google Assistant
Гайдлайны Amazon Alexa
Книга «Designing VUI» Cathy Pearl
Книга «VUX best practices, Voicebot»
Конспект от меня по книге выше на Medium
Документация Google Assistant
Документация Amazon Alexa
Документация Яндекс.Алиса
Новости, аналитика
Контакты спикера Павла Гвая: профили в Twitter и Linkedin, и блог на Medium.
В 2017 году Starbucks запустил функцию по заказу кофе домой для Amazon Alexa. Кроме того, что выросли заказы на доставку, об этом написали все возможные СМИ, создав классный PR. Примеру Starbucks последовали Uber, Domino’s, MacDonald’s, и даже у стирального порошка Tide появился свой skill для Alexa.
Как у Starbucks, голосовое приложение выполняет одну-две функции: заказывает кофе, ставит будильник или вызывает курьера. Чтобы спроектировать нечто подобное, не обязательно быть межконтинентальной корпорацией. Идея, проектирование, тестирование, разработка и релиз похожи на аналогичные этапы в мире мобильной разработки, но с особенностями для голоса. Подробно о процессе рассказал Павел Гвай: от идеи до публикации, с примерами реальной игры, с историческими вставками и разбором мира голосовой разработки.
О спикере: Павел Гвай (pavelgvay) — проектирует голосовые интерфейсы в студии мобильной разработки KODE. Студия разрабатывает мобильные приложения, например, для Utair, Победа, РосЕвроБанк, BlueOrange Bank и Whiskas, но в KODE существует подразделение, которое занимается голосовыми приложениями для Яндекс.Алисы и Google Assistant. Павел участвовал в нескольких реальных проектах, обменивается опытом с разработчиками и дизайнерами в этой сфере, в том числе из США и выступает на тематических конференциях. Кроме того Павел основатель стартапа tortu.io — инструмента для дизайна голосовых приложений.
Что такое разговорное приложение
В разговорном приложении канал взаимодействия с пользователем строится через разговор: устный — с умной колонкой, или через письменный, например, с Google Assistant. Кроме колонки, устройством взаимодействия может быть экран, поэтому разговорные приложения еще и графические.
Правильно говорить разговорное приложение, а не голосовое, но это уже устоявшийся термин, и я тоже буду его использовать.
У голосовых приложений есть важное преимущество перед мобильными: их не надо скачивать и устанавливать. Достаточно знать название, и ассистент сам все запустит.
Все потому, что нечего скачивать — и распознавание речи, и бизнес-логика — все приложение живет в облаке. Это огромное преимущество перед мобильными приложениями.
Немного истории
История голосовых помощников началась с Interactive Voice Response — интерактивной системы записанных голосовых ответов. Возможно, никто не слышал этот термин, но все сталкивались, когда звонили в техподдержку и слышали робота: «Нажмите 1, чтобы попасть в главное меню. Нажмите 2, чтобы узнать подробней» — это и есть IVR система. Отчасти, IVR можно назвать первым поколением голосовых приложений. Хотя они уже часть истории, но кое-чему могут нас научить.
Большинство людей при взаимодействии с IVR-системой стараются связаться с оператором. Это происходит из-за плохого UX, когда взаимодействие основано на жестких командах, что просто неудобно.
Это подводит нас к основному правилу хорошего разговорного приложения.
Хорошее разговорное приложение взаимодействует с пользователем не через строгие команды, а через живой, естественный разговор, похожий на общение между людьми.
Разговор с приложением должен быть больше похож на звонок в пиццерию для заказа, чем на общение командами с чат-ботом. Достичь такой же гибкости, как в разговоре между людьми, не получится, но говорить с приложением комфортно и естественным языком — вполне.
В этом тоже преимущество голоса перед графическими приложениями: не нужно учиться пользоваться. Моя бабушка не умеет заходить на сайты или заказывать пиццу через приложение, но вызвать доставку через колонку сможет. Мы должны использовать это преимущество и подстраиваться под то, как говорят люди, а не учить их говорить с нашим приложением.
От IVR-систем перейдем к настоящему — к виртуальным помощникам.
Виртуальные помощники
Голосовой мир крутится вокруг виртуальных помощников: Google Assistant, Amazon Alexa и Алиса.
Все устроено почти как в мобильном мире, только вместо платформ iOS и Android здесь Алиса, Google Assistant и Alexa, вместо графических приложений — голосовые, с собственными названиями или именами, и у каждого помощника свой внутренний магазин голосовых приложений. Опять же, говорить «приложение» неправильно, так как у каждой платформы свой термин: у Алисы — «навыки», у Алексы — «skills», а у Google — «actions».
Чтобы запустить skill, я прошу ассистента: «Алекса, передай Starbucks, что я хочу кофе!», Алекса найдет приложение кофейни в своем магазине и передаст ему разговор. Дальше разговор идет не между Алексой и пользователем, а между пользователем и приложением. Многие путаются и думают, что с ними продолжает говорить ассистент, хотя у приложения уже другой голос.
Так выглядят магазины приложений. Интерфейс напоминает App Store и Google Play.
Этапы разработки разговорного приложения
Для пользователя у приложения нет никакой графической части — все выглядит как набор диалога. Внешне может показаться, что приложение — это простая вещь, создать его просто, но это не так. Этапы разработки такие же, как и у мобильных приложений.
- Дизайн. В случае голоса не отрисовка экранов, а проработка диалогов.
- Разработка делится на две части: разработка системы понимания речи и написание логики.
- Тестирование.
- Публикация.
Два первых этапа специфичны, так как приложения разговорные, а два последних — стандартны.
Пройдем каждый из этапов на примере игры «Угадай цену», которая запущена под Google Assistant. Механика простая: приложение показывает пользователю карточку с товаром, а он должен угадать цену.
Начнем погружение с первого этапа: мы определились с идеей, провели аналитику, поняли, что у пользователя есть потребность и приступаем к созданию голосового приложения.
Проектирование
Главная цель — спроектировать взаимодействие между пользователем и приложением. В мобильном мире этот этап называется дизайном. Если дизайнер графических приложений рисует карты экранов, кнопки, формы и подбирает цвета, то VUI-дизайнер прорабатывает диалог между пользователем и приложением: прописывает различные ветки диалога, думает о развилках и побочных сценариях, выбирает варианты фраз.
Проектирование ведется в три этапа.
- Примеры диалогов.
- Отрисовка блок-схемы.
- Составление prompt lists.
Примеры диалогов
Первое, что надо сделать — это понять, как будет работать приложение. Понимание и видение потребуется транслировать на всех остальных, особенно, если вы аутсорс-компания, и вам придется объяснять заказчику, что он в итоге получит.
Мощный инструмент в помощь — примеры диалогов: разговор между пользователем и приложением по ролям, как в пьесе.
Пример диалога для нашей игры.

Приложение здоровается, рассказывает пользователю о правилах, предлагает сыграть, и, если человек соглашается, показывает карточку с товаром, чтобы пользователь угадал цену.
Сценарий помогает быстро понять, как будет работать приложение, что оно сможет сделать, но, помимо этого, примеры диалогов помогают отсеять главную ошибку в мире голосовых интерфейсов — работу над неправильными сценариями.
Есть простое правило: если не можешь представить, как ты проговариваешь сценарий с другим человеком, то не стоит над ним работать.
Голос и графика существенно отличаются, и не все, что работает на графических интерфейсах, хорошо работает на голосе. Почти в каждом мобильном приложении есть регистрация, но я не могу представить, как можно зарегистрироваться голосом? Как диктовать умной колонке пароль: «Большая буква, маленькая буква, эс как доллар...» — и все это вслух. А если я не один, а на работе? Это пример ошибочного сценария. Если вы начнете разработку сценария с ошибкой, то с ним возникнут проблемы: вы не поймете, как его выполнить, пользователи не поймут как им пользоваться.
Примеры диалогов помогут найти подобные моменты. Чтобы найти ошибки в сценариях, запишите диалог, выберете коллегу, посадите напротив и отыграйте роли: вы — пользователь, коллега — приложение. После ролевого зачитывания диалога станет ясно, звучит приложение или нет, и будет ли пользователю удобно.
Такая проблема будет появляться постоянно. Если у вас in-house разработка, то возникнет соблазн: «У нас уже есть сайт, давайте просто сконвертируем его в голос и все будет хорошо!» Либо придет заказчик и скажет: «Вот мобильное приложение. Сделайте то же самое, только голосом!» Но так делать нельзя. Вы, как специалист, должны быстро находить сценарии, над которыми не стоит работать, и объяснять заказчику почему. Примеры диалогов здесь помогут.
Для прописывания диалогов подойдет абсолютно любой текстовый редактор, к которому вы привыкли. Главное — запишите текст и зачитайте его по ролям.
Блок-схема
Примеры диалогов — это мощный, быстрый и дешевый инструмент, но они описывают только линейное развитие событий, а разговоры всегда нелинейны. Например, в нашей игре «Угадай цену», пользователь может ответить на вопрос правильно или неправильно — это первая развилка из множества тех, что будут встречаться дальше.
Чтобы не запутаться во всех ветках диалога вашего приложения, составьте блок-схему — визуализацию диалога. Она состоит всего из двух элементов:
- Шаг диалога от лица пользователя.
- Шаг диалога от лица приложения.
Блок-схема — это карта нашего приложения, но с одним неприятным свойством — она сильно разрастается, становится нечитаемой и визуально непонятной. Вот, например, скриншот с частью блок-схемы из сценария, где пользователь угадывает цену, с несколькими развилками.
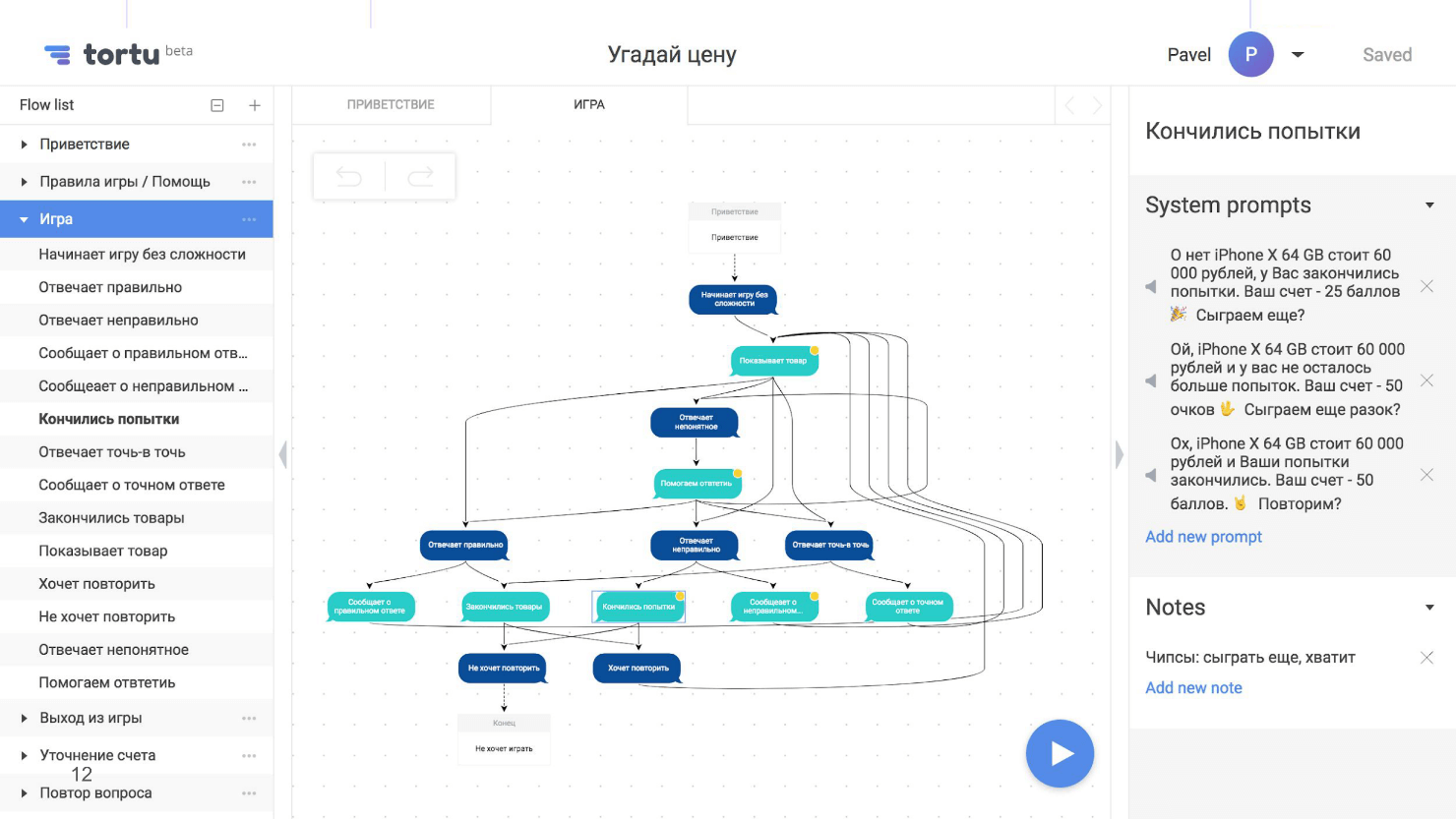
Несколько развилок — еще не предел, их может быть десятки или сотни. Мы задавали себе вопросы: «Что произойдет, если человек ответит правильно? А если нет? Что будет, если закончатся попытки? Что если кончатся товары? А если он угадает цену точно? Что если интернет пропадет на этом шаге или на другом?» В итоге мы создали огромную нечитаемую схему.
В этом мы не одиноки. Я общался с дизайнером из США, которая работала над серьезным проектом. В проекте был и IVR, и банк, и skill одновременно, и все это раздуло блок-схему до 600 листов. До конца схему никто не понимал, а когда дизайнер ее увидела, то просто ужаснулась.
У меня есть совет, как этого не допустить. Схема всегда будет разрастаться, но никогда не пытайтесь построить одну большую блок-схему на все приложение — она будет громоздкой, и никто кроме вас в ней не разберется. Идите от обратного и разбейте схему на логические части: отдельно сценарий угадывания цены, отдельно сценарий помощи. По необходимости разбейте и эти сценарии на подсценарии. В итоге получится не одна большая карта с непонятными связями, а много маленьких, читабельных, хорошо связанных между собой схем, в которых всем удобно ориентироваться.
Для блок-схем подойдет любой инструмент. Раньше я использовал RealtimeBoard, а еще естьDraw.io и даже XMind. В итоге разработал свой, потому что просто удобнее. На картинке как раз он и представлен. Этот инструмент поддерживает, в том числе, разбивку на подсценарии.
prompt lists
Последний артефакт, который мы сформируем на этапе проектирования. prompt list — это список всех возможных фраз, которые может произнести приложение.
Здесь есть одна тонкость. Разговор с приложением должен быть гибким и похожим на разговор с человеком. Это означает не только возможность пройти разными ветками, что мы делали на этапе блок-схемы, а звучание разговора в целом. Человек никогда не будет отвечать одной и той же фразой, если вы будете задавать один и тот же вопрос. Ответ всегда будет перефразирован и звучать как-то иначе. Приложение должно поступать так же, поэтому на каждый шаг диалога от лица приложения напишите не один вариант ответа, а как минимум пять.

По prompt листам есть еще важная вещь. Общение должно быть не только живым и гибким, но и консистентным в плане стиля речи и общего ощущения общения пользователя с вашим приложением. Для этого дизайнеры используют отличный прием — создание персонажа. Когда я звоню своему другу, то не вижу его, но подсознательно представляю собеседника. У пользователя при общении с умной колонкой то же самое. Это называется парейдалия.
На этапе prompt листов вы создаете персонажа, от лица которого приложение будет разговаривать. С персонажем ваши пользователи будут ассоциировать бренд и приложение — это может быть реальный человек или вымышленный. Проработайте для него внешность, биографию, характер и юмор, но если времени нет, то просто приведите все ваши фразы в prompt листах к единому стилю. Если вы начали обращаться к пользователю на «Вы», то не обращайтесь в других местах на «Ты». Если у вас неформальный стиль общения, то придерживайтесь его везде.
Обычно для создания prompt листов используют Excel или Google-таблицы, но при с ними возникают огромные временные потери на рутинную работу. Блок-схема и табличка с фразами никак не связаны друг с другом, любые правки приходится переносить вручную, что выливается в постоянную и долгую рутину.
Я использую не Excel, а свой инструмент, потому что в нем все фразы пишутся прямо в блок-схеме, они закреплены за шагом диалога. Это избавляет от рутины.
В проектировании мы прорабатываем каждый сценарий: пишем пример диалога, находим побочные ветки, ошибки, покрываем это блок-схемой, а потом работаем над стилем речи и фразами.
Кажется, что теперь все готово и можно дать задание разработчикам и приниматься за код, но остался еще один важный этап — тестирование. Мы должны удостовериться, что как дизайнеры все сделали правильно, что приложение будет работать как мы хотим, что все фразы в одном стиле, что мы покрыли все побочные ветки и обработали все ошибки.
Тестирование
Тестирование на таком раннем этапе особенно важно для голосовых приложений. В мире графических интерфейсов пользователь ограничен тем, что нарисовал дизайнер: он не зайдет за пределы экрана, не найдет кнопку, которой не существует, а будет нажимать только на то, что есть…
В мире голоса все не так: пользователь волен говорить все, что угодно, и вы не знаете, как он начнет работать с вашим приложением, пока это не увидите. Лучше это сделать на раннем этапе проектирования и подготовиться к неожиданностям, пока не началась дорогая разработка.
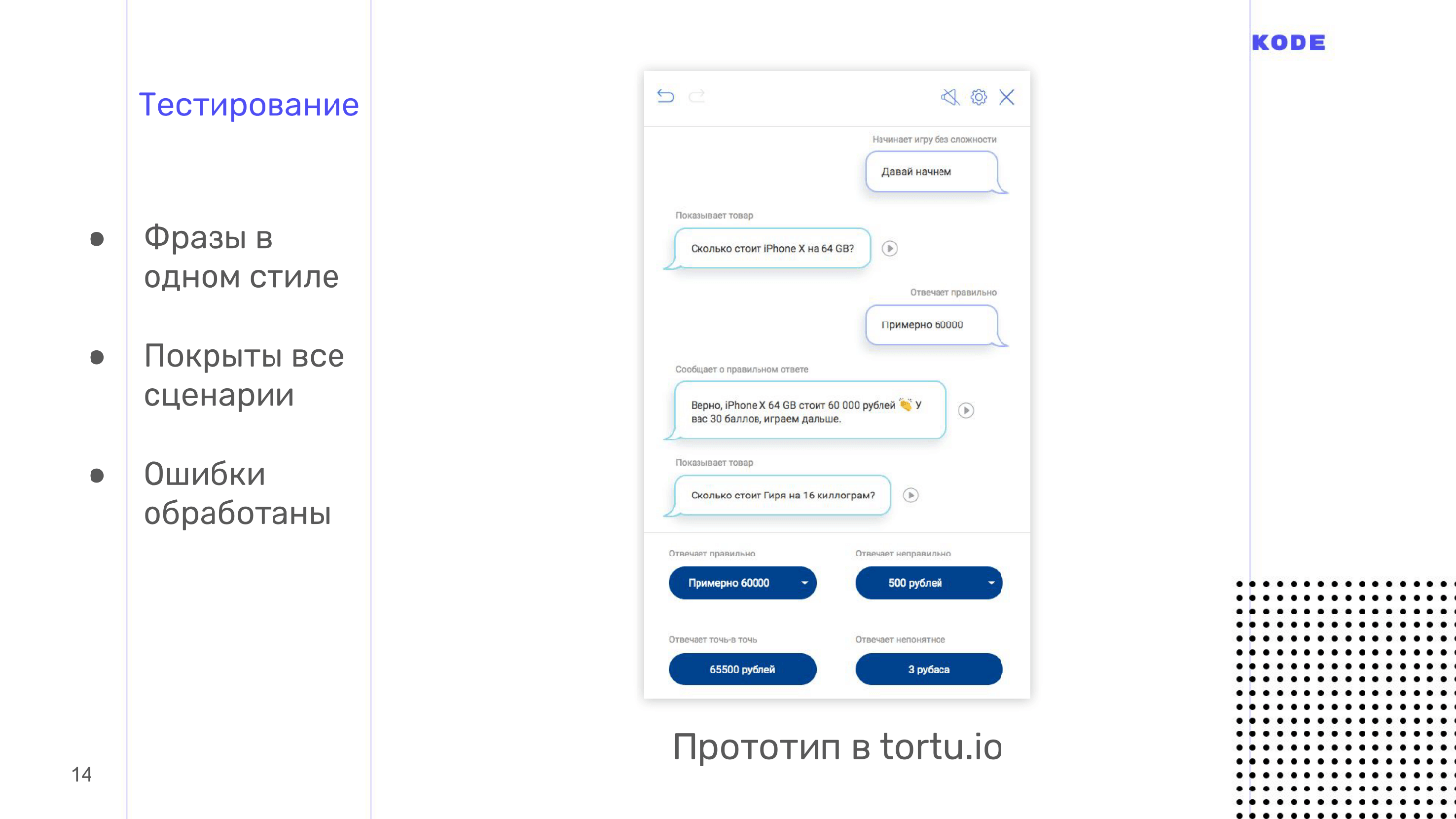
Приложения тестируются с помощью методологии Wizard of Oz. Она используется и в графических приложениях, но реже, а в голосе это must have. Это метод, когда пользователь взаимодействует с системой, предполагая, что она существует и работает сама по себе, но всем процессом управляете вы.
Тестирование производится с помощью интерактивных прототипов. Обычно дизайнеру приходится просить разработчиков создать прототип, но лично я использую свой инструмент, потому что в нем все делается в один клик и не надо никого ждать. Еще нам нужен пользователь. Мы зовем человека, который никак не вовлечен в разработку, ничего не знает о приложении и, в идеале, входит в вашу ЦА. Вы приглашаете человека, объясняете, что это за приложение, как им пользоваться, сажаете в комнате, включаете интерактивный прототип и пользователь начинает с ним разговаривать. Прототип не распознает речь, а это вы слышите, что говорит человек, и выбираете вариант ответа, которым приложение отвечает на каждую фразу.
Если пользователь не видит экран, то ему кажется, что приложение работает само по себе, но процессом управляете вы. Это и есть тестирование Wizard of Oz. С его помощью вы не только услышите, как звучит приложение, но и увидите, как люди его используют. Гарантирую, что вы найдете много непокрытых сценариев.
Когда я тестировал игру, то позвал своего друга. Он начал угадывать цену и сказал, что какая-то мазь стоит «пятихат». Я не ожидал такого слова, думал, что будут варианты в 500 рублей, тысячу рублей, а не «пятихат» или «косарь». Это мелочь, которая вскрылась на тестировании. Люди пользуются приложением иначе, чем вы представляете, и тестирование вскрывает подобные мелочи и нерабочие сценарии.
Много и долго тестируйте до разработки, пока не будете уверены в том, что приложение работает и пользователи взаимодействуют с ним так, как вы ожидаете.
На этом этап проектирования заканчивается и у нас на руках есть примеры диалогов, блок схема — логическое описание работы приложения, и prompt-листы — то, что приложение говорит. Все это мы отдадим разработчикам. Перед тем, как я расскажу как разработчики создают приложения, поделюсь советами по проектированию.
Советы
Используйте язык разметки SSML — как HTML, только для речи. SSML позволяет проставить паузы, выставить уровень эмпатии, ударение, прописать, что прочитать по буквам и где сделать акцент.

Размеченная речь звучит намного лучше, чем роботическая, а чем лучше звучит приложение, тем приятнее им пользоваться. Поэтому используйте SSML — он не такой уж и сложный.
Думайте о моментах, в которых пользователи обращаются к вашему приложению за помощью. Для голоса это особенно важно. Человек может разговаривать с колонкой в одиночестве в комнате, а может ехать в автобусе и общаться со смартфоном. Это два принципиально разных сценария поведения для голосового приложения. Подобная ситуация у нас была с банковским приложением. В приложении был сценарий, когда пользователь получает информацию о счете, а это приватная информация. Я подумал — если человек разговаривает дома, то все нормально, но, если он едет в автобусе, а приложение начнет озвучивать баланс карты вслух — будет некрасиво.
Подумав о таких моментах, вы можете определить, что если пользователь разговаривает со смартфоном, пусть даже голосом, то приватную информацию лучше не зачитывать вслух, а показать на экране.
Используйте мультимодальный дизайн.
Это дизайн под разные поверхности и платформы. Голосовые устройства очень разные по своей фактуре. В мобильном мире устройства различаются только платформой и размером экрана — форм-фактором. С голосом все иначе. Например, у колонки вообще нет экрана — только голос. У смартфона есть экран, и его можно тапать пальцем. У телевизора экран огромный, но к нему бесполезно прикасаться. Подумайте, как ваше приложение будет работать на каждой из таких поверхностей.
Например, пользователь совершил покупку и мы хотим показать чек. Зачитывать чек вслух — плохая идея, потому что информации много и никто ее не запомнит, так как голосовая информация воспринимается сложно и тяжело.

Используя принцип мультимодального дизайна, мы понимаем, что если есть экран, то чек лучше показать, вместо того, чтобы читать. Если экрана нет, то мы вынуждены проговорить вслух основные данные чека.
На этом проектирование закончено. То, что я рассказал — это основы, верхушка айсберга. Для самостоятельного изучения проектирования, я собрал много материала по проектированию, в конце статьи будут ссылки.
Разработка
Разговор начнем с универсальной схемы работы приложения под любой платформой. Схема работает и с Алисой, и с Amazon Alexa, и с Google Assistant.

Когда пользователь просит запустить наше приложение, ассистент это делает и передает приложению контроль за разговором. Пользователь что-то говорит и в приложение попадает сырой текст, который проходит обработку системой распознавания речи.
- Система из сырого текста определяет намерение пользователя — intent, его параметры — слоты, и формирует ответ: сразу, если не требуется никакой логики и дополнительной информации, и использует webhook, если логика необходима. Вся бизнес-логика в голосовых приложениях лежит в webhook, оттуда производятся запросы в базы данных, вызовы API.
- Ответ формируется и передается пользователю голосом или показывается на экране.
Для обработки мы используем Dialogflow, его структура абсолютно такая же, как и у других систем понимания речи, и разработку будем рассматривать на его примере.
Мы переходим к первому звену — к системе понимания человеческой речи или Natural Language Understanding — NLU.
Dialogflow
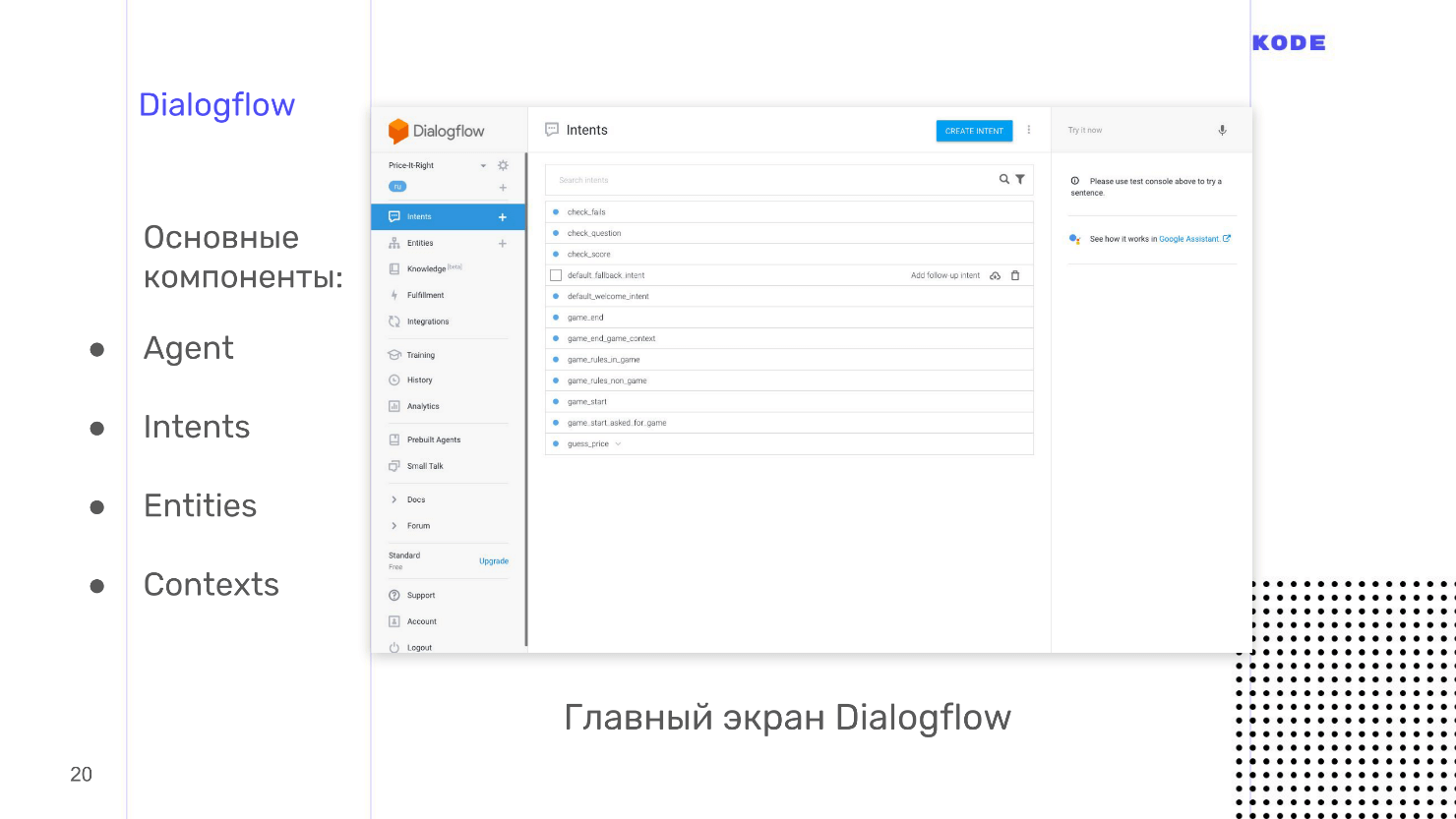
Мы используем Dialogflow, потому что у него богатые возможности, хорошая документация, живая поддержка и его просто и быстро освоить. Dialogflow кроссплатформенный инструмент: основная квалификация — приложения для Google Assistant, но для Яндекс-Алисы, Amazon Alexa и создания ботов в Telegram его тоже можно использовать. Отдельный плюс — открытое API. Вы можете использовать систему, чтобы разработать голосовое управление для сайта или уже существующего мобильного приложения.
Основные компоненты Dialogflow.
- Agent — ваш проект, то, что у него внутри.
- Intents — намерения пользователя.
- Entities — объекты данных.
- Contexts — контексты, хранилища для информации.
Пройдемся по всем компонентам, но начнем с главного — это Intents.
Intents
Это пользовательское намерение, то, что пользователь хочет совершить. Намерение выражается фразами. Например, в игре пользователь хочет узнать правила игры и говорит: «Расскажи правила игры», «Скажи, как играть?», «Помоги мне — я запутался» или что-нибудь в таком духе. Соответственно, мы создаем отдельный Intent для правил игры, и на вход пишем все эти фразы, которые ожидаем от пользователя.
Я советую писать 10 и больше вариантов фраз. В таком случае распознавание речи будет работать лучше, потому что в Dialogflow используется нейронная сеть, которая принимает эти 10 фраз на вход, и генерирует из них кучу других, похожих. Чем больше вариантов, тем лучше, но не переборщите.
У Intent должен быть ответ на любой вопрос пользователя. В Dialogflow ответ можно сформировать без применения логики, а если логика нужна, то передаем ответ из webhook. Ответы могут быть разные, но стандартный — это текст: озвучивается на колонках, показывается или проговаривается на смартфонах.
В зависимости от платформы доступны дополнительные «плюшки» — графические элементы. Например, для Google Assistant это кнопки, карточки, списки, карусели. Они показываются только если человек говорит с Google Assistant на смартфоне, телевизоре или другом подобном устройстве.
Entities
Intent запускается, когда пользователь что-то говорит. В этот момент передается информация — параметры, которые называются слотами, а тип данных параметров — Entities. Например, для нашей игры, это примеры фраз, которые говорит пользователь, когда угадывает цену. Здесь есть два параметра: сумма и валюта.

Параметры могут быть обязательными и необязательными. Если пользователь ответит «две тысячи», то фразы будет достаточно. По умолчанию мы возьмем рубли, поэтому валюта — необязательный параметр. Но без суммы мы не сможем понять ответ, потому что пользователь может ответить на вопрос не конкретно:
— Сколько стоит?
— Много!
Для таких случаев в Dialogflow есть понятие re-prompt — это фраза, которая будет произнесена, когда пользователь не назвал обязательный параметр. Для каждого параметра фраза задается отдельно. Для суммы это может быть что-то вроде: «Назовите точную цифру, сколько стоит ...»
У каждого параметра обязательно должен быть тип данных — Entities. В Dialogflow много стандартных типов данных — города, имена, и это спасает. Система сама определяет, что есть имя, что есть число, а что город, но можно задавать и свои кастомные типы. Валюта в Dialogflow — кастомный тип. Мы создали ее сами^ описали техническое системное название, которым будем пользоваться, и синонимы, которые отвечают этому параметру. Для валюты это рубль, доллар, евро. Когда пользователь говорит: «Евро», то Dialogflow подсвечивает, что это наш параметр «валюта»
Context
Воспринимайте это слово буквально: context — это контекст того, о чем вы говорите с пользователем. Например, у ассистента можно спросить: «Кто написал Муму?» и он ответит, что это Тургенев. Вдогонку можно спросить, когда он родился. Обращаю внимание, что мы спрашиваем: «Когда он родился», не уточняя кто. Google поймет, потому что помнит — в контексте разговора Тургенев.
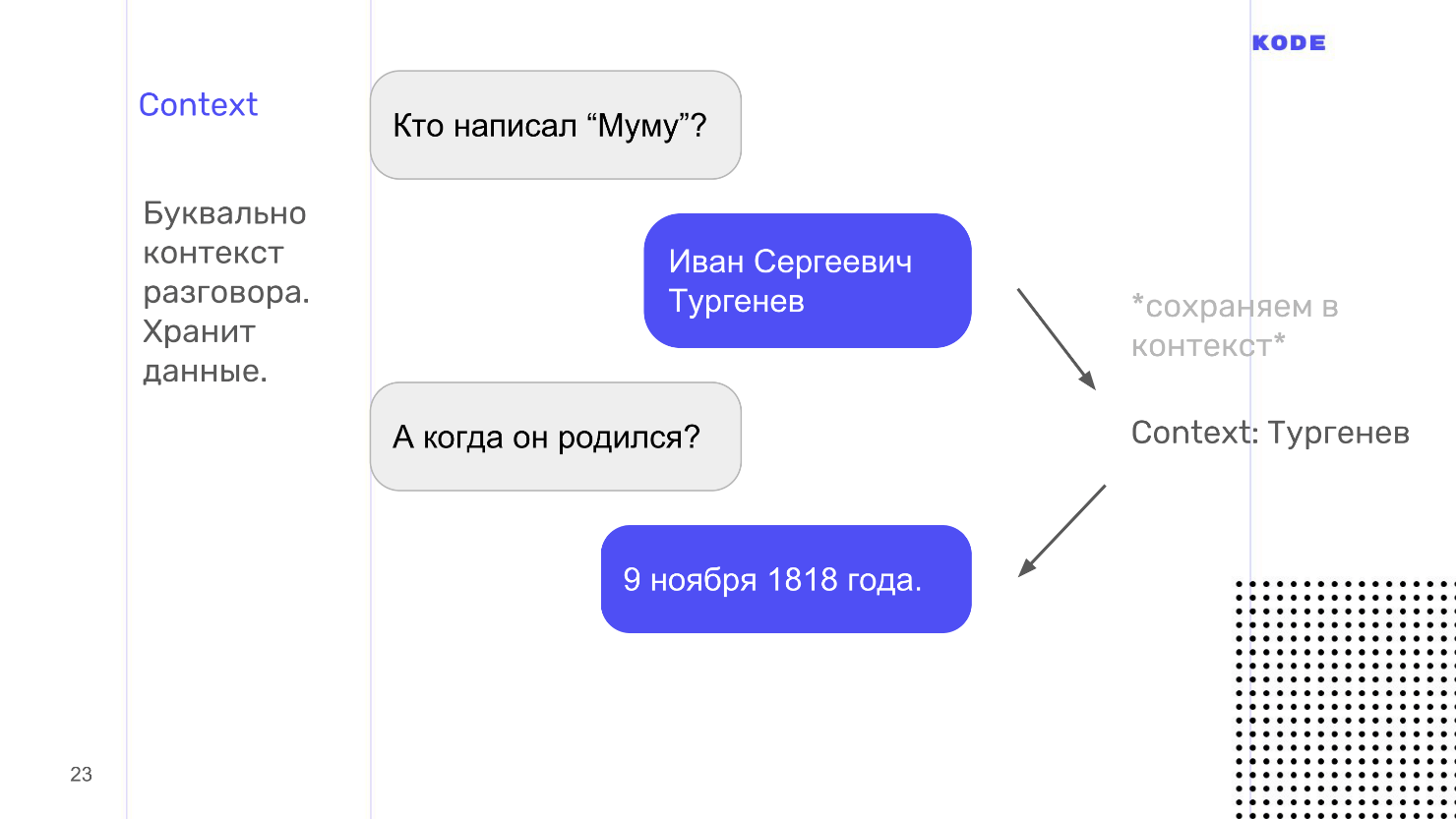
С технической точки зрения context — это хранилище типа «ключ — значение», в которое складывается информация. Intent может либо испускать context из себя, складывая в него что-то, либо принимать на вход и доставать информацию оттуда. У context есть время жизни. Оно определяется количеством шагов диалога от последнего упоминания: например, через 5 шагов диалога забыть, что мы говорили про Тургенева.
У context есть еще одна важная функция — он может помочь нам разбить приложение на логические зоны: на авторизованную и неавторизованную, на игровую сессию или нет. Разбивка строится так, что Intent, который принимает context на вход, не может быть запущен без контекста и требует предыдущего запуска другого Intent. Так мы можем логически связывать и строить наше приложение.

Я упоминал webhook.У Dialogflow есть библиотеки под абсолютно разные языки, мы использовали JS. У Google Assistant для webhook есть ограничение — ответ с него должен прийти не позднее, чем через 5 секунд, иначе выпадет ошибка и приложение сработает в fallback. Для Алисы, время ответа — 1,5 или 3 секунды.
Мы настроили систему понимания речи, написали webhook и у нас все работает, запустили QA, и теперь время для публикации.
Публикация
Публикация стандартна, почти как с мобильными приложениями, но с парой нюансов.
Обратите отдельное, особое и очень пристальное внимание на название приложения. Пользователь будет его произносить вслух каждый раз при запуске. Поэтому название должно быть простым для произношения и простым для распознавания ассистентом, потому что с этим иногда бывают проблемы.
У названия есть два правила:
- Нельзя использовать общие фразы. В Яндекс.Алисе, нельзя использовать глаголы. Например, вы не сможете взять название «Заказ такси», потому что это общая фраза, которую многие хотят использовать.
- Если захотите использовать название своей компании, то будьте готовы к тому, что вас попросят подтвердить права на пользование брендом.
В Google Assistant стандартная фраза, которая запускает любое приложение — «ОК, Google, поговори с...». Вы можете воспользоваться этой фичей, например, сказать: «ОК, Google, поговори с Uber» — и он запустит приложение на главном экране, на стартовой точке. Но можно сделать так, чтобы пользователь сказал: «ОК, Google, скажи Uber забрать меня отсюда и отвезти туда!» мы сокращаем одну итерацию, и пользователь попадет в нужное действие.
Сценарий определяется фразами, которыми запускается приложение. Они устанавливаются при публикации, но часто работают некорректно — на русском языке точно. Например, в нашей игре фраза «Давай сыграем» работала, а «Давай поиграем» не работала. Я не знаю, в чем принципиальная разница между «сыграем» и «поиграем» для Google Assistant. Он распознавал обе фразы корректно, но приложение не работало, хотя с английским языком у нас проблем не возникало.
В остальном публикация проходит гладко, без лишних вопросов. Поддержка у Google Assistant очень живая, отвечает быстро, и документация хорошая.
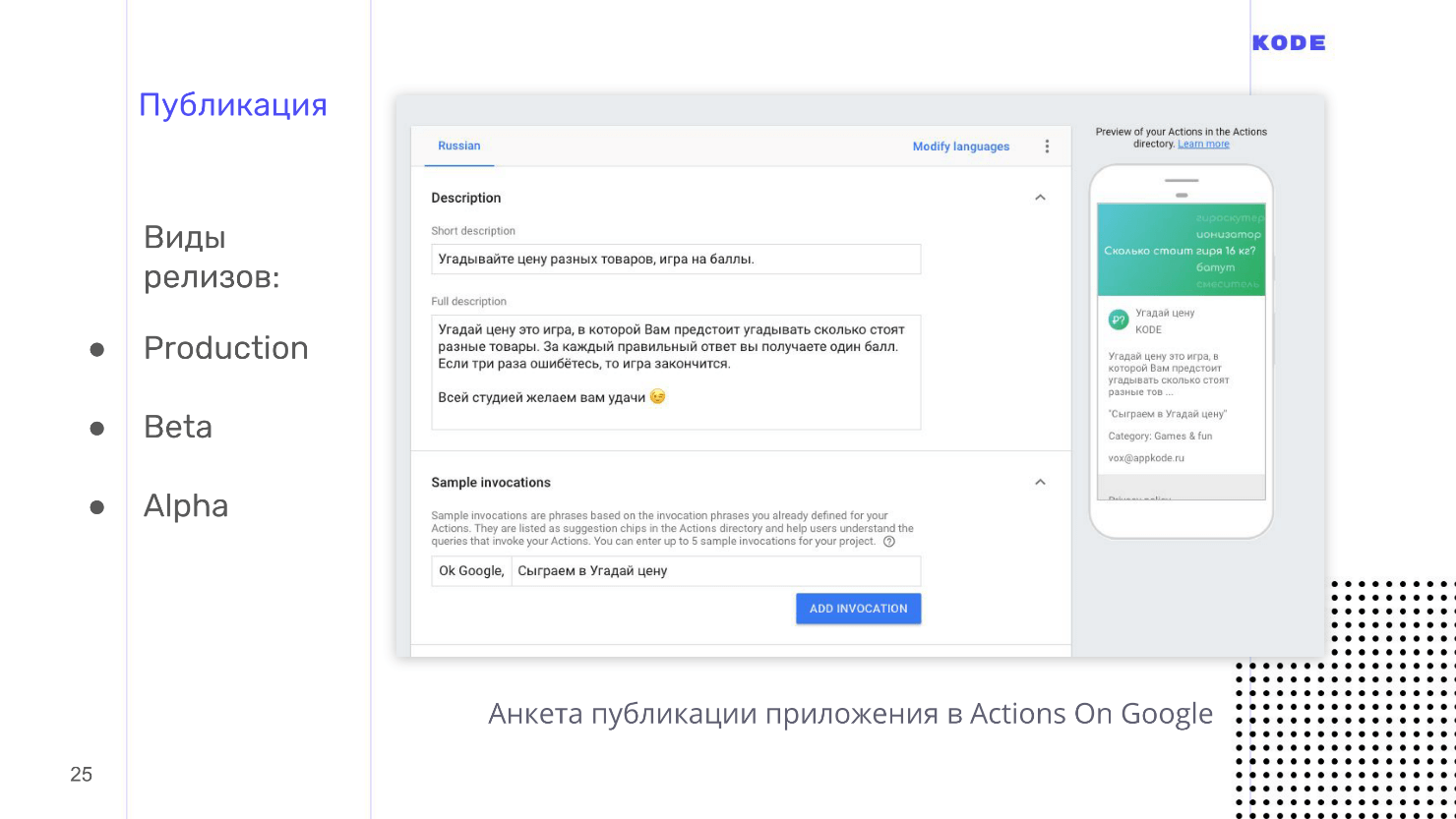
Также хочу отметить разные виды релизов.
- Alpha — для 20 человек и без прохождения ревью.
- Beta — для 200 человек.
- Production-релиз — когда приложение попадет в store. Если мы публикуем в Production, то должны обязательно пройти ревью. Люди из Google вручную проверяют, как работает приложение, и отсылают фидбэк. Если все хорошо, то приложение публикуется. Если нет, то вам приходит письмо с правками, что в вашем приложении не работает и что исправить.
Казалось бы, на этом все, но мы говорим про голос, поэтому здесь есть еще один важный момент — это аналитика.
Аналитика
Особенно важна для голоса. Если для мобильных приложений аналитика показывает косяки, баги и системные ошибки, то в мире голоса аналитика раскрывает нам упущенные возможности — то, как люди хотели использовать наше приложение, но не смогли.
Это обязательный этап. Именно поэтому, в Dialogflow есть стандартные инструменты для анализа приложений со следующими режимами:
- История — обезличенная история разговоров с вашим приложением.
- Обучение — интересный режим, который показывает все фразы, которые приложение распознало, но не было в состоянии обработать.
Они показываются списком и выглядят, как на картинке. Пользователь отгадывал цену какого-то мотора и сказал: «4 штуки». Про «косари» я вспомнил на тестировании, а про «штуки» забыл — поэтому придется чинить.
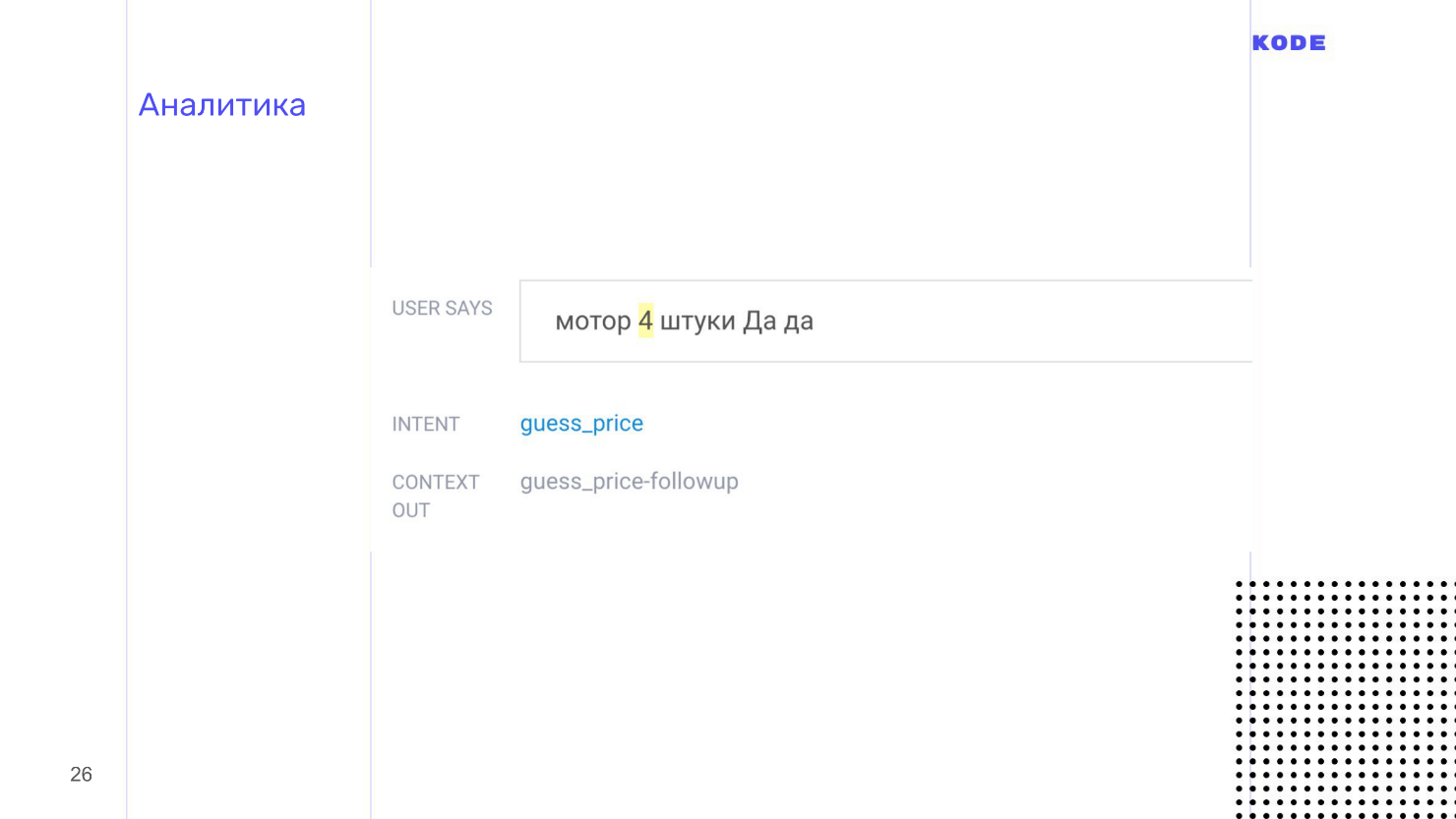
Аналитика помогает найти недоработки, поэтому обязательно смотрите в логи и проверяйте, что происходит с вашим приложением и что с ним делают пользователи.
На этом все про голосовые приложения. Надеюсь, что у вас появилось хотя бы минимальное понимание как они разрабатываются. Доклад был общим, но все дополнительные материалы про разработку, проектирование и бизнес-часть собраны по ссылкам.
Полезные ссылки и контакты
Телеграм-чат разработчиков голосовых интерфейсов
Телеграм-чат Яндекс.Диалоги
Slack-чат разработчиков Amazon Alexa
Slack-чат разработчиков Google Assistant
Гайдлайны Google Assistant
Гайдлайны Amazon Alexa
Книга «Designing VUI» Cathy Pearl
Книга «VUX best practices, Voicebot»
Конспект от меня по книге выше на Medium
Документация Google Assistant
Документация Amazon Alexa
Документация Яндекс.Алиса
Новости, аналитика
Контакты спикера Павла Гвая: профили в Twitter и Linkedin, и блог на Medium.
AppsConf 2019 пройдет в центре Москвы, в Инфопространстве 22 и 23 апреля. Обещаем еще больше полезностей по мобильной разработке, чем в прошлом году, поэтому бронируйте билет или оставляйте заявку на доклад.
Чтобы быть в курсе новостей и анонсов докладов — подписывайтесь на нашу рассылку и YouTube-канал по мобильной разработке.
Только AppsConf, только хардкор!
