
Нейронная сеть может опознать котика на фотографии, найти диван, улучшить видеозапись, нарисовать картинку из щенят или простого наброска. К этому мы уже привыкли. Новости о нейросетях появляются почти каждый день и стали обыденными. Компании Grid Dynamics поставили задачу не обыденную, а сложную — научить нейросеть находить специфический шуруп или болт в огромном каталоге интернет-магазина по одной фотографии. Задачка сложнее, чем найти котика.

Проблема интернет-магазина шурупов — в ассортименте. Тысячи или десятки тысяч моделей. У каждого шурупа свое описание и характеристики, поэтому на фильтры нет надежды. Что делать? Искать вручную или искать в гипермаркете на полках? В обоих случаях это потеря времени. В итоге клиент устанет и пойдет забивать гвоздь. Чтобы помочь ему, воспользуемся нейросетью. Если она может находить котиков или диваны, то пусть занимается чем-то полезным — подбирает шурупы и болты. Как научить нейросеть подбирать для пользователя шурупы быстро и точно, расскажем в расшифровке доклада Марии Мацкевичус, которая в компании Grid Dynamics занимается анализом данных и машинным обучением.
Представьте — мы купили стол, но потерялся один маленький шуруп, и стол без него не собрать. Мы идем в интернет-магазин в поисках, и видим 15 000 уникальных позиций, каждая из которых — возможно, наш шуруп.
Мы идем в фильтры — их около 10, у каждого из которых от 5 до 100 атрибутов. Выбираем тип шляпки и цвет: плоская шляпка — Flat и желтая медь — Brass. Получаем выдачу.
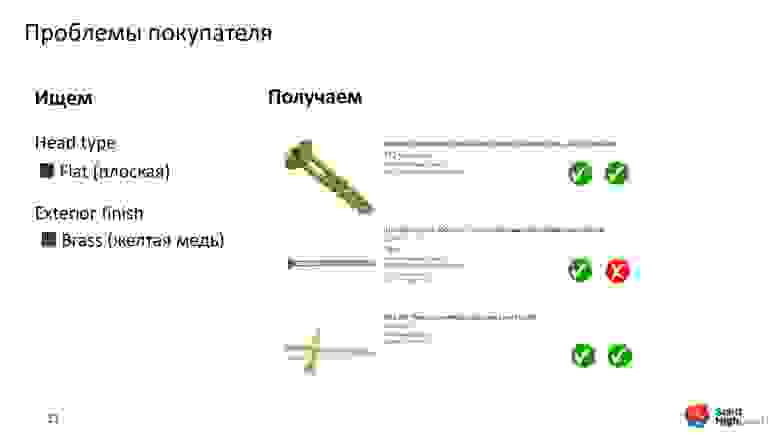
Что это? Мы не это искали. Увольте человека, который отвечает за выдачу!
Спустя время все-таки выбираем 2 подходящих шурупа для стола.

Осталось самое простое — расшифровать описание и характеристики. Каждый производитель описывает шурупы по-своему. Для описания параметров определенной модели нет конкретных требований.
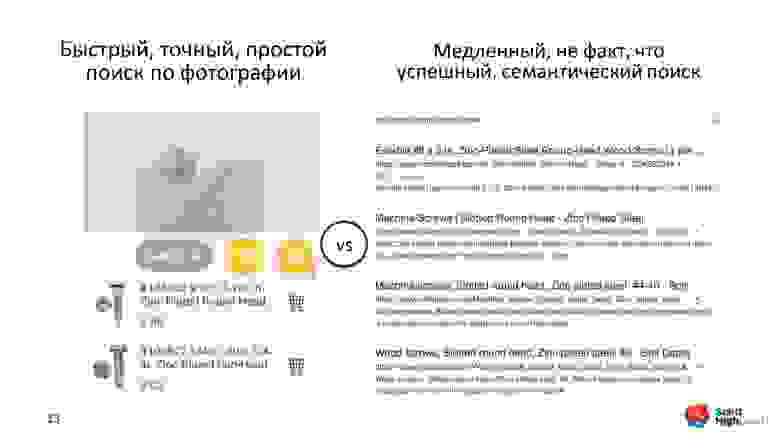
Все что создает сложности для клиента. Потерянное время, нервы и труд технической поддержки, которая помогает клиенту искать требуемую модель. Осознав эти проблемы покупателя, наш заказчик — крупная американская компания — решил предоставить клиенту быстрый, точный и простой поиск по фотографии, вместо медленного и не всегда успешного семантического поиска.
Мы взялись за задачу и поняли, что есть несколько проблем.
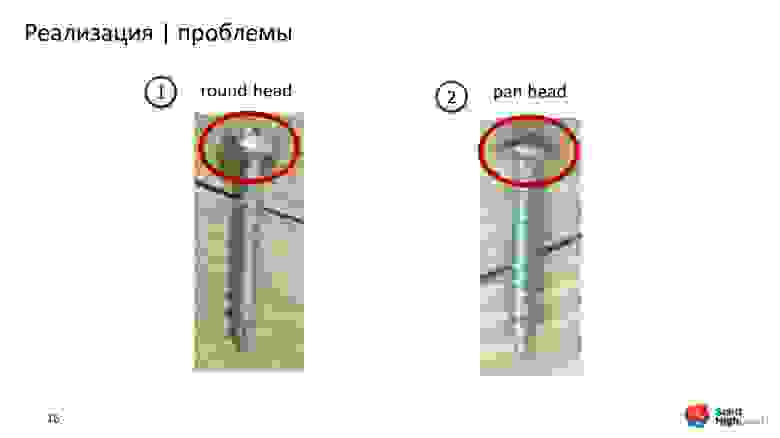
Шурупы похожи друг на друга. Посмотрите на фотографии.

Это разные шурупы. Если перевернуть фотографии, то видно, что отличается важная характеристика — head.
А на этой фотографии?

Здесь модели одинаковые. Освещение разное, но на обеих фотографиях одна модель шурупа.
Есть редкие разновидности, которые требуют классификации. Например, с «ушками» или кольцом.

Минимум требований к использованию приложения. Пользователь может загрузить фотографию с любым фоном, с посторонними объектами, с тенями, с плохим освещением, и приложение обязано выдать результат. Шуруп или болт на белом фоне — большая редкость.

Приложение должно работать в реальном времени. Пользователь ждет результат здесь и сейчас.
Конкуренты. Недавно Amazon — конкурент нашего заказчика — запустил свой Part Finder. Это приложение, которое ищет шурупы и болты по фотографии.

Кроме Amazona, у нас было два конкурента-стартапа со своими решениями для заказчика. Нам нужно было побить не только Amazon, но и стартапы, что было не сложно. Один из конкурентов предложил идею взять 20 самых популярных болтов и натренировать object detection на них. Но на вопрос, что будет, когда нейросети дадут 100, 1000 или все 15 000 шурупов с сайта заказчика, как будет работать object detection и где взять так много данных, конкурент не нашел, что ответить.
Должно быть масштабируемым и не зависеть от количества разновидностей шурупов и размера каталога. Чтобы решить задачу, мы решили рассмотреть шуруп как набор характеристик или признаков. Каждый признак — это набор атрибутов.
Выбрали следующие характеристики:
Изучили карту всех признаков и поняли — чтобы описать 15 000 разных шурупов, их требуется всего 50. Они будут составлять комбинацию различных признаков с различными атрибутами. Требуется 50 шурупов и одна монетка, для измерения масштаба шурупа на фотографии.
Так и решили. С идеей определились. Дальше требуются данные.
Мы получили данные от заказчика и немного расстроились. Каталожные данные — фотографии объектов на белом фоне.

Но они не совсем соответствуют данным, которые приложение будет обрабатывать. Пользователь захочет использовать любые фоны, будет фотографировать на ладони или держать болтик пальцами. Данные на которых обучается сеть, не будут совпадать с реальной картинкой.
Тогда мы решили последовать совету Ричарда Сокера.
Так мы и сделали — распечатали на принтере много цветных фонов, купили эти 50 болтов и сфотографировали на фонах данные для обучения. Так мы получили все возможные варианты поверхностей столов и ковров.

После сбора данных следующий этап — понять, в каком месте на картинке находится болт, если вообще присутствует.
Мы рассмотрели два подхода к локализации: object detection и семантическая сегментация.

Object detection возвращает бокс минимальной площади вокруг объекта. Семантическая сегментация возвращает маску. В нашем случае маска больше подходит. Она сохраняет форму, убирает фон, лишние тени и позволяет в дальнейшем классифицировать шурупы лучше, чем object detection.
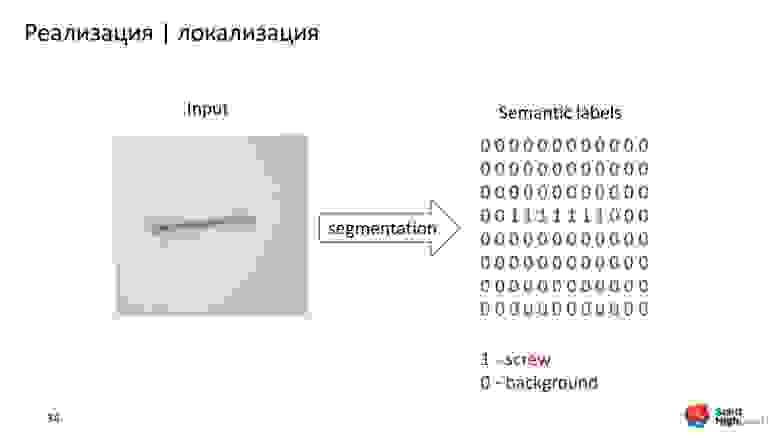
Задача семантической сегментации — вернуть на каждый пиксель вероятность принадлежности его к классу. Чтобы обучить такую модель, требуются размеченные данные. Мы воспользовались приложением «labelme», с помощью которого разметили выборку. Получили около тысячи масок с монеткой и шурупом.

Мы взяли U-Net. Эту сеть очень любят на Kaggle и мы теперь тоже.

U-Net — это успешная реализация encoder-decoder.
С моделью определились. Теперь выбираем функцию потерь, значение которой будем минимизировать в процессе обучения.
Классический вариант для сегментации — Dice coefficient:
Это гармоническое среднее между precision и recall. Гармоническое среднее значит, что мы одинаково взвешиваем ошибку первого рода и ошибку второго рода. Наши данные не сбалансированы, и это нам не очень подходит.

Фона всегда много, а самого объекта мало. Поэтому модель будет всегда отдавать очень высокий precision и очень низкий recall. Чтобы по-разному взвешивать ошибки первого и второго рода, мы решили взять Tversky index:
У Tversky index два коэффициента, α и β по-разному взвешивает эти две ошибки. Если взять α=β=0,5, получаем тот же самый Dice coefficient. Если выбрать другие параметры, получим Jaccard index — одна из мер схожести объектов. При α=β=1 — Tversky index равен Jaccard index.
Также можно получить Fβ-score. При α+β=1 Tversky index соответствует Fβ-score.
Чтобы подобрать α и β, мы провели несколько экспериментов. Выдвинули гипотезу — сильнее штрафовать модель за ошибки второго рода. Не так страшно, когда модель классифицирует пиксель фона, как пиксель объекта. Если вокруг объекта будет небольшая рамочка фона — это нормально. Но когда модель классифицирует пиксель шурупа, как пиксель фона — на шурупе появляются дырки, он становится неровным, и это мешает нашей классификации.
Поэтому мы решили повысить параметр β и приблизить его к 1, а параметр α — к 0.

На картинке видно, что лучшая маска получилась при β=0,7 и α=0,3. На этом решили остановиться, и обучить модель на всех наших данных.
Стратегия обучения довольно хитрая. Так как данные мы размечали вручную в личное время, то решили воспользоваться одной особенностью U-Net. Каждый новый класс она сегментирует на новом канале — добавляет новый канал и на нем локализуется объект.
Поэтому у нас в обучении не было ни одной картинки, которая содержит одновременно и монетку, и болт. Все картинки содержали один класс: 10% — монетки, 90% — шурупы.

Это позволило правильно распределить усилия и сэкономить время на монетку — она одна, а форма простая. Мы легко научились ее сегментировать, что позволило перекинуть 90% усилий именно на шурупы. Они имеют разные формы и цвета, и важно научиться их сегментировать.
Наша сеть научилась сегментировать даже те экземпляры, которых не было в нашей выборке. Например, болты необычной формы отсутствовали, но модель их тоже хорошо сегментировала. Она научилась обобщать признаки шурупов и болтов и использовать это для новых данных, что здорово.

Это следующий этап после локализации объекта. Мало кто обучает сверточные нейронные сети для классификации объектов, чаще используют Transfer learning. Посмотрим на архитектуру сверточной нейронной сети, а потом кратко напомню, что такое Transfer learning.
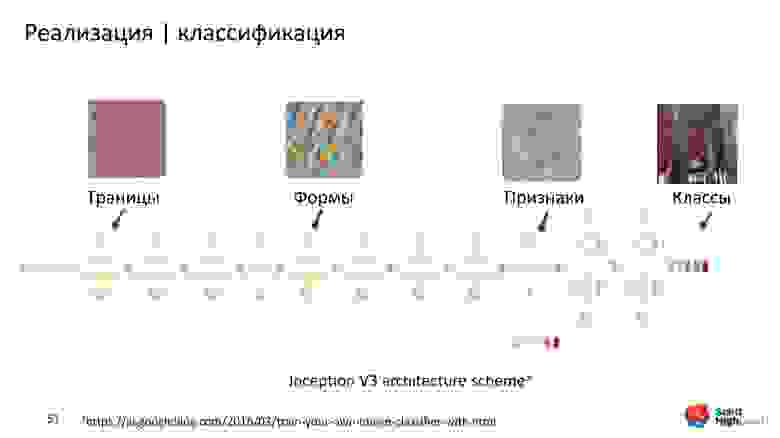
На ранних слоях сеть учится распознавать границы и углы. Позже распознает простые формы: прямоугольники, круги, квадраты. Чем ближе к топу, тем больше распознает характерные признаки данных, на которых она обучается. На самом верху модель распознает классы.
Большинство предметов окружающего мира состоят из простых форм и имеют общие признаки. Можно взять часть сеть, которая обучена на огромном количестве данных и использовать эти признаки для нашей классификации. Сеть будет обучаться на небольшом наборе данных без больших затрат ресурсов. Это мы и сделали.

После того, как определились с общей технологией Transfer learning, нужно выбрать заранее натренированную модель.
Наше приложение работает в режиме реального времени. Модель должна быть легкой и мобильной — иметь мало параметров, но быть точной. Чтобы учесть эти два фактора, мы пожертвовали небольшой точностью в пользу легкости. Поэтому выбрали не самую точную, но зато легкую модель — Xception.

В Xception вместо обыкновенной свёртки — Convolution — используется Separable Convolution. Поэтому Xception легче остальных сетей, например, с VGG.
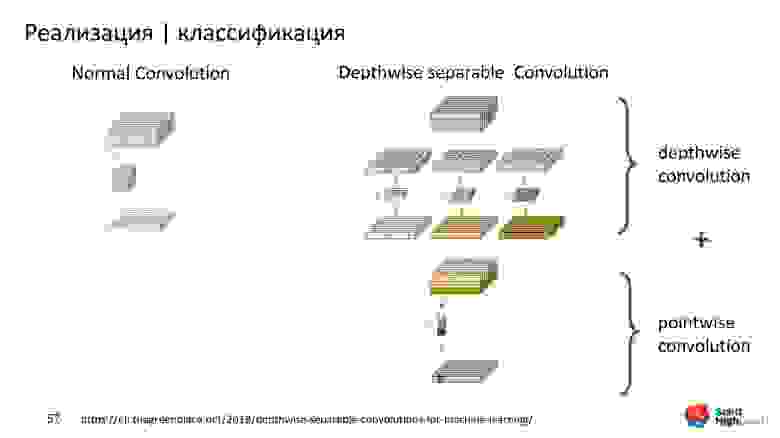
Обыкновенный Convolution делает одновременно межканальную и межпространственную свёртку. А Separable Convolution разделяет: сначала межпространственная свёртка — Depthwise, а потом межканальная. Результаты объединяет.
Xception выполняет separable Convolution, при этом выдает такой же хороший результат, как и обыкновенный Convolution, но параметров меньше.
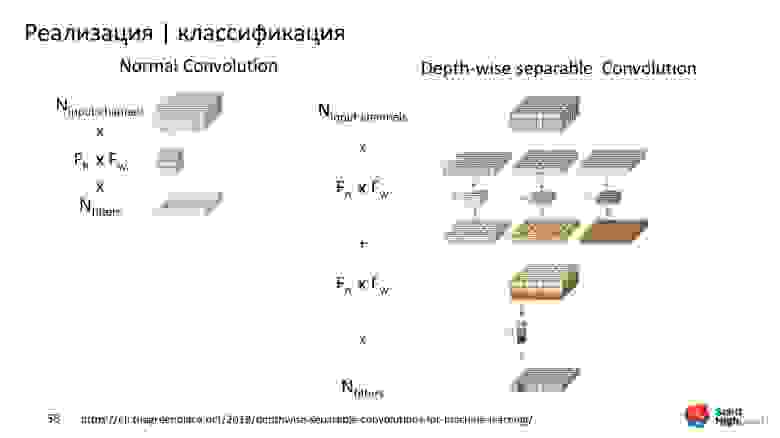
Подставим в формулы расчёта параметров значения, например, для 16 фильтров. Для обыкновенного Convolution нужно рассчитать параметров в 7 раз больше, чем для Separable Convolution. За счет этого Xception получается точнее и меньше.

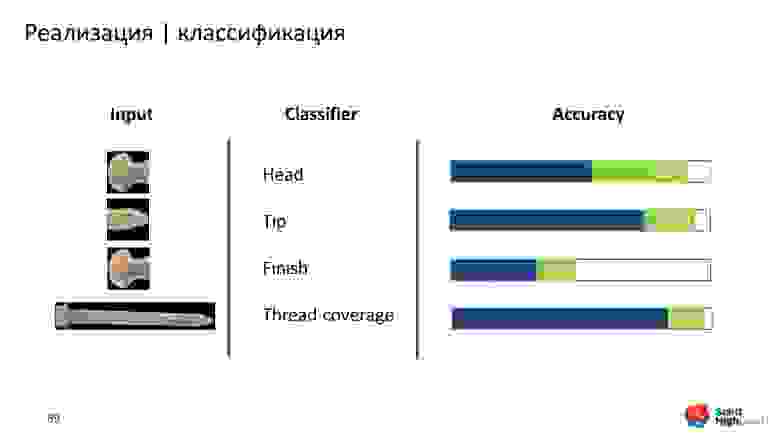
Сначала решили построить некоторый baseline и обучили модель на исходной картинке. У нас было 4 классификатора и каждый отвечал за конкретный признак. Результат получился неудовлетворительным.

Потом обучили модель на боксе, который вернул object detection. Получили хороший прирост точности для Thread coverage. Но для остальных классификаторов результат также неудовлетворительный.

После решили отдавать классификаторам только ту часть шурупа, которую они хотят и будут классифицировать. Head отдавать только шляпки, Tip — только острие. Для этого мы взяли маски, получили контур, вокруг которого обвели прямоугольник минимальной площади, и посчитали угол поворота.

В этот момент мы еще не знаем, с какой стороны у шурупа head и tip. Чтобы узнать — распилили бокс пополам и посмотрели на площади.

Площадь, которая содержит head, всегда больше, чем та, которая содержит tip. Сравнивая площади, определяем в какой части, какая из частей шурупа. Это сработало, но не для всех случаев.

Когда длина шурупа сравнима с диаметром шляпки, вместо прямоугольника получается квадрат. Когда его поворачиваем, получаем картинку, как под номером 3. Модель такой вариант плохо классифицирует.
Тогда мы взяли все длинные шурупы, посчитали для них углы поворота, и построили неглубокую нейронную сеть Rotation Net, которая берет шуруп и предсказывает угол поворота.
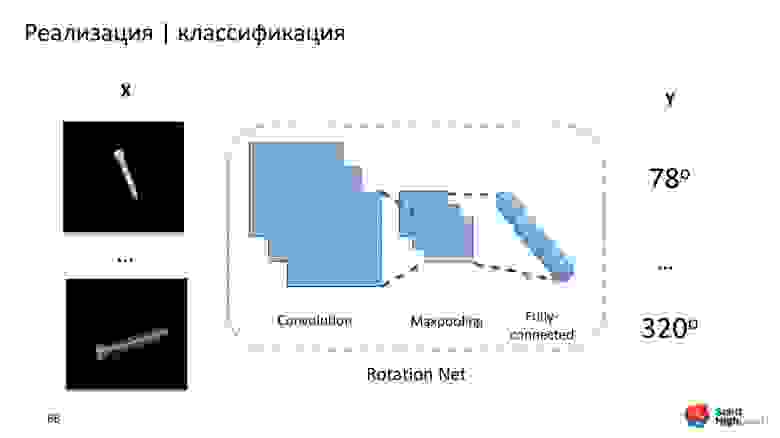
Потом эту вспомогательную модель применили для маленьких коротких шурупов и болтиков. Получили хороший результат — все работает, маленькие шурупы тоже ротируются. На этом этапе ошибка практически сведена к нулю. Взяли эти данные, обучили классификаторы и увидели, что по каждому из классификаторов, кроме Finish, сильно выросла точность. Это здорово — работаем дальше.
Но с Finish почему-то не взлетело. Изучили ошибки и увидели картинку.

Одинаковые пары шурупов при разных условиях освещения и разных настройках камеры отличаются цветом. Это может смущать не только модель, но и человека. Серый может стать розовым, желтый — оранжевым. Вспомним сине-золотое платье — та же история. Отражающая поверхность шурупа вводит в заблуждение.
Изучили подобные случаи в интернете и нашли китайских ученых, которые пытались классифицировать машины по цветам и столкнулись с такой же проблемой для автомобилей.

В качестве решения китайские ученые создали неглубокую сеть. Ее особенность в двух ветках, которые конкатенируются в конце. Такая архитектура называется ColorNet.

Мы реализовали решение для своей задачи, и получили прирост точности почти в 2 раза. С такими результатами и моделями можно работать и искать тот самый шуруп от стола в каталоге интернет-магазина.

У нас было всего 4 классификатора на 4 признака, а есть еще много других. Значит, необходимо создать какой-то фильтр, который будет брать данные каталога и фильтровать их определенным образом.
Каждый классификатор возвращает soft-метку и класс. Мы взяли значения soft-меток и нашу базу данных, посчитали некоторый score — перемножение всех меток для каждого признака.
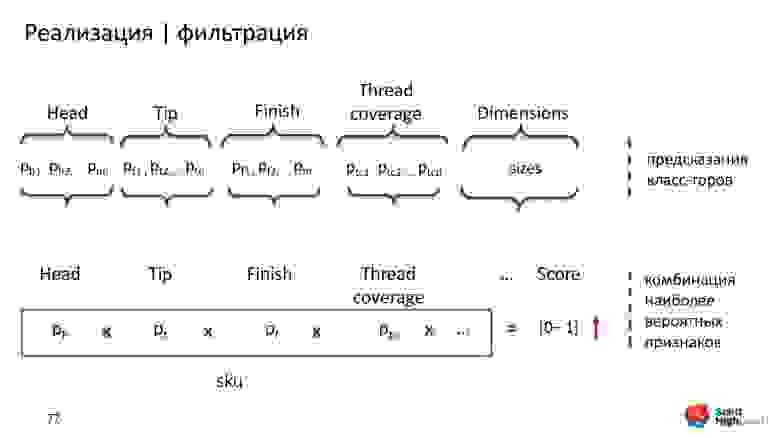
Score показывает уверенность всех классификаторов в том, что данная комбинация признаков появится вероятнее всего. Чем больше score, тем вероятнее, что шуруп из каталога и шуруп на картинке похожи.
Получилось такое приложение.
Ешьте слона по частям. Разделите большую проблему на части.
Разметьте данные, которые будут отражать реальность. Не бойтесь разметки данных — это самый безопасный способ, который обеспечит максимальное качество модели быстро. Методы синтезирования данных обычно дают результаты хуже, чем при использовании реальных данных.
Тестируйте. Прежде чем строить много моделей, мы брали маленькие порции данных, размечали руками и проверяли работу каждой гипотезы. Только после этого обучали U-Net, классификаторы, Rotation.
Не изобретайте велосипед. Часто у проблемы, с которой вы столкнулись, уже существует решение. Поищите в интернете, почитайте статьи — обязательно что-нибудь найдете!
Рассказ о нашем Visual Search приложении не только про классификацию шурупов. Он о том, как сделать сложный проект, у которого нет аналогов, но даже если есть — они не удовлетворяют требованиям, которые мы предъявляем к приложению.
Подробнее о проектах Grid Dynamics и других вызовах, с которыми сталкивается команда Data Science, смотрите в техноблоге компании.

Проблема интернет-магазина шурупов — в ассортименте. Тысячи или десятки тысяч моделей. У каждого шурупа свое описание и характеристики, поэтому на фильтры нет надежды. Что делать? Искать вручную или искать в гипермаркете на полках? В обоих случаях это потеря времени. В итоге клиент устанет и пойдет забивать гвоздь. Чтобы помочь ему, воспользуемся нейросетью. Если она может находить котиков или диваны, то пусть занимается чем-то полезным — подбирает шурупы и болты. Как научить нейросеть подбирать для пользователя шурупы быстро и точно, расскажем в расшифровке доклада Марии Мацкевичус, которая в компании Grid Dynamics занимается анализом данных и машинным обучением.
Короткая демоверсия того, что получилось
Проблемы покупателя
Представьте — мы купили стол, но потерялся один маленький шуруп, и стол без него не собрать. Мы идем в интернет-магазин в поисках, и видим 15 000 уникальных позиций, каждая из которых — возможно, наш шуруп.
Мы идем в фильтры — их около 10, у каждого из которых от 5 до 100 атрибутов. Выбираем тип шляпки и цвет: плоская шляпка — Flat и желтая медь — Brass. Получаем выдачу.

Что это? Мы не это искали. Увольте человека, который отвечает за выдачу!
Спустя время все-таки выбираем 2 подходящих шурупа для стола.

Осталось самое простое — расшифровать описание и характеристики. Каждый производитель описывает шурупы по-своему. Для описания параметров определенной модели нет конкретных требований.
Все что создает сложности для клиента. Потерянное время, нервы и труд технической поддержки, которая помогает клиенту искать требуемую модель. Осознав эти проблемы покупателя, наш заказчик — крупная американская компания — решил предоставить клиенту быстрый, точный и простой поиск по фотографии, вместо медленного и не всегда успешного семантического поиска.

Сложности реализации
Мы взялись за задачу и поняли, что есть несколько проблем.
Шурупы похожи друг на друга. Посмотрите на фотографии.

Это разные шурупы. Если перевернуть фотографии, то видно, что отличается важная характеристика — head.

А на этой фотографии?

Здесь модели одинаковые. Освещение разное, но на обеих фотографиях одна модель шурупа.
Есть редкие разновидности, которые требуют классификации. Например, с «ушками» или кольцом.

Минимум требований к использованию приложения. Пользователь может загрузить фотографию с любым фоном, с посторонними объектами, с тенями, с плохим освещением, и приложение обязано выдать результат. Шуруп или болт на белом фоне — большая редкость.

Приложение должно работать в реальном времени. Пользователь ждет результат здесь и сейчас.
Конкуренты. Недавно Amazon — конкурент нашего заказчика — запустил свой Part Finder. Это приложение, которое ищет шурупы и болты по фотографии.

Кроме Amazona, у нас было два конкурента-стартапа со своими решениями для заказчика. Нам нужно было побить не только Amazon, но и стартапы, что было не сложно. Один из конкурентов предложил идею взять 20 самых популярных болтов и натренировать object detection на них. Но на вопрос, что будет, когда нейросети дадут 100, 1000 или все 15 000 шурупов с сайта заказчика, как будет работать object detection и где взять так много данных, конкурент не нашел, что ответить.
Решение
Должно быть масштабируемым и не зависеть от количества разновидностей шурупов и размера каталога. Чтобы решить задачу, мы решили рассмотреть шуруп как набор характеристик или признаков. Каждый признак — это набор атрибутов.

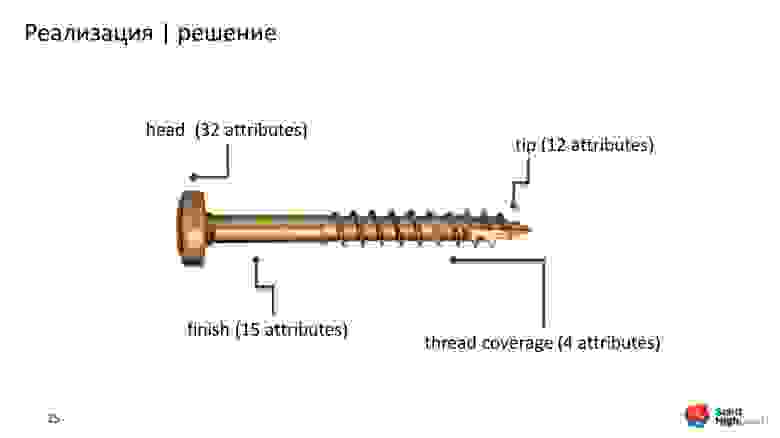
Выбрали следующие характеристики:
- шляпка — head (32 атрибута);
- внешнее покрытие — finish (15 атрибутов);
- острие — tip (12 атрибутов);
- покрытие резьбы — thread coverage (4 атрибутов).
Изучили карту всех признаков и поняли — чтобы описать 15 000 разных шурупов, их требуется всего 50. Они будут составлять комбинацию различных признаков с различными атрибутами. Требуется 50 шурупов и одна монетка, для измерения масштаба шурупа на фотографии.
Так и решили. С идеей определились. Дальше требуются данные.
Данные
Мы получили данные от заказчика и немного расстроились. Каталожные данные — фотографии объектов на белом фоне.

Но они не совсем соответствуют данным, которые приложение будет обрабатывать. Пользователь захочет использовать любые фоны, будет фотографировать на ладони или держать болтик пальцами. Данные на которых обучается сеть, не будут совпадать с реальной картинкой.
Тогда мы решили последовать совету Ричарда Сокера.
Вместо месяца изучения метода обучения без учителя, проще взять неделю, разметить данные и обучить классификатор.
Так мы и сделали — распечатали на принтере много цветных фонов, купили эти 50 болтов и сфотографировали на фонах данные для обучения. Так мы получили все возможные варианты поверхностей столов и ковров.

После сбора данных следующий этап — понять, в каком месте на картинке находится болт, если вообще присутствует.
Локализация
Мы рассмотрели два подхода к локализации: object detection и семантическая сегментация.

Object detection возвращает бокс минимальной площади вокруг объекта. Семантическая сегментация возвращает маску. В нашем случае маска больше подходит. Она сохраняет форму, убирает фон, лишние тени и позволяет в дальнейшем классифицировать шурупы лучше, чем object detection.

Задача семантической сегментации — вернуть на каждый пиксель вероятность принадлежности его к классу. Чтобы обучить такую модель, требуются размеченные данные. Мы воспользовались приложением «labelme», с помощью которого разметили выборку. Получили около тысячи масок с монеткой и шурупом.

Модель
Мы взяли U-Net. Эту сеть очень любят на Kaggle и мы теперь тоже.

U-Net — это успешная реализация encoder-decoder.
- Конструирующий путь или encoder. Это та часть U-Net, которая пытается всю совокупность данных, представить в виде векторного представления в более сжатом пространстве. Она выучивает эти признаки и находит наиболее существенные.
- Расширяющийся путь или decoder. Пытается декодировать карту признаков и понять, в каком месте находится объект на картинке.
С моделью определились. Теперь выбираем функцию потерь, значение которой будем минимизировать в процессе обучения.
Loss-функция
Классический вариант для сегментации — Dice coefficient:

Это гармоническое среднее между precision и recall. Гармоническое среднее значит, что мы одинаково взвешиваем ошибку первого рода и ошибку второго рода. Наши данные не сбалансированы, и это нам не очень подходит.

Фона всегда много, а самого объекта мало. Поэтому модель будет всегда отдавать очень высокий precision и очень низкий recall. Чтобы по-разному взвешивать ошибки первого и второго рода, мы решили взять Tversky index:

У Tversky index два коэффициента, α и β по-разному взвешивает эти две ошибки. Если взять α=β=0,5, получаем тот же самый Dice coefficient. Если выбрать другие параметры, получим Jaccard index — одна из мер схожести объектов. При α=β=1 — Tversky index равен Jaccard index.
Также можно получить Fβ-score. При α+β=1 Tversky index соответствует Fβ-score.
Чтобы подобрать α и β, мы провели несколько экспериментов. Выдвинули гипотезу — сильнее штрафовать модель за ошибки второго рода. Не так страшно, когда модель классифицирует пиксель фона, как пиксель объекта. Если вокруг объекта будет небольшая рамочка фона — это нормально. Но когда модель классифицирует пиксель шурупа, как пиксель фона — на шурупе появляются дырки, он становится неровным, и это мешает нашей классификации.
Поэтому мы решили повысить параметр β и приблизить его к 1, а параметр α — к 0.

На картинке видно, что лучшая маска получилась при β=0,7 и α=0,3. На этом решили остановиться, и обучить модель на всех наших данных.
Обучение
Стратегия обучения довольно хитрая. Так как данные мы размечали вручную в личное время, то решили воспользоваться одной особенностью U-Net. Каждый новый класс она сегментирует на новом канале — добавляет новый канал и на нем локализуется объект.
Поэтому у нас в обучении не было ни одной картинки, которая содержит одновременно и монетку, и болт. Все картинки содержали один класс: 10% — монетки, 90% — шурупы.

Это позволило правильно распределить усилия и сэкономить время на монетку — она одна, а форма простая. Мы легко научились ее сегментировать, что позволило перекинуть 90% усилий именно на шурупы. Они имеют разные формы и цвета, и важно научиться их сегментировать.
Наша сеть научилась сегментировать даже те экземпляры, которых не было в нашей выборке. Например, болты необычной формы отсутствовали, но модель их тоже хорошо сегментировала. Она научилась обобщать признаки шурупов и болтов и использовать это для новых данных, что здорово.

Классификация
Это следующий этап после локализации объекта. Мало кто обучает сверточные нейронные сети для классификации объектов, чаще используют Transfer learning. Посмотрим на архитектуру сверточной нейронной сети, а потом кратко напомню, что такое Transfer learning.

На ранних слоях сеть учится распознавать границы и углы. Позже распознает простые формы: прямоугольники, круги, квадраты. Чем ближе к топу, тем больше распознает характерные признаки данных, на которых она обучается. На самом верху модель распознает классы.
Большинство предметов окружающего мира состоят из простых форм и имеют общие признаки. Можно взять часть сеть, которая обучена на огромном количестве данных и использовать эти признаки для нашей классификации. Сеть будет обучаться на небольшом наборе данных без больших затрат ресурсов. Это мы и сделали.

После того, как определились с общей технологией Transfer learning, нужно выбрать заранее натренированную модель.
Выбор модели
Наше приложение работает в режиме реального времени. Модель должна быть легкой и мобильной — иметь мало параметров, но быть точной. Чтобы учесть эти два фактора, мы пожертвовали небольшой точностью в пользу легкости. Поэтому выбрали не самую точную, но зато легкую модель — Xception.

В Xception вместо обыкновенной свёртки — Convolution — используется Separable Convolution. Поэтому Xception легче остальных сетей, например, с VGG.

Обыкновенный Convolution делает одновременно межканальную и межпространственную свёртку. А Separable Convolution разделяет: сначала межпространственная свёртка — Depthwise, а потом межканальная. Результаты объединяет.
Xception выполняет separable Convolution, при этом выдает такой же хороший результат, как и обыкновенный Convolution, но параметров меньше.

Подставим в формулы расчёта параметров значения, например, для 16 фильтров. Для обыкновенного Convolution нужно рассчитать параметров в 7 раз больше, чем для Separable Convolution. За счет этого Xception получается точнее и меньше.

Обучение
Сначала решили построить некоторый baseline и обучили модель на исходной картинке. У нас было 4 классификатора и каждый отвечал за конкретный признак. Результат получился неудовлетворительным.

Потом обучили модель на боксе, который вернул object detection. Получили хороший прирост точности для Thread coverage. Но для остальных классификаторов результат также неудовлетворительный.

После решили отдавать классификаторам только ту часть шурупа, которую они хотят и будут классифицировать. Head отдавать только шляпки, Tip — только острие. Для этого мы взяли маски, получили контур, вокруг которого обвели прямоугольник минимальной площади, и посчитали угол поворота.

В этот момент мы еще не знаем, с какой стороны у шурупа head и tip. Чтобы узнать — распилили бокс пополам и посмотрели на площади.

Площадь, которая содержит head, всегда больше, чем та, которая содержит tip. Сравнивая площади, определяем в какой части, какая из частей шурупа. Это сработало, но не для всех случаев.

Когда длина шурупа сравнима с диаметром шляпки, вместо прямоугольника получается квадрат. Когда его поворачиваем, получаем картинку, как под номером 3. Модель такой вариант плохо классифицирует.
Тогда мы взяли все длинные шурупы, посчитали для них углы поворота, и построили неглубокую нейронную сеть Rotation Net, которая берет шуруп и предсказывает угол поворота.

Потом эту вспомогательную модель применили для маленьких коротких шурупов и болтиков. Получили хороший результат — все работает, маленькие шурупы тоже ротируются. На этом этапе ошибка практически сведена к нулю. Взяли эти данные, обучили классификаторы и увидели, что по каждому из классификаторов, кроме Finish, сильно выросла точность. Это здорово — работаем дальше.

Но с Finish почему-то не взлетело. Изучили ошибки и увидели картинку.

Одинаковые пары шурупов при разных условиях освещения и разных настройках камеры отличаются цветом. Это может смущать не только модель, но и человека. Серый может стать розовым, желтый — оранжевым. Вспомним сине-золотое платье — та же история. Отражающая поверхность шурупа вводит в заблуждение.
Изучили подобные случаи в интернете и нашли китайских ученых, которые пытались классифицировать машины по цветам и столкнулись с такой же проблемой для автомобилей.

В качестве решения китайские ученые создали неглубокую сеть. Ее особенность в двух ветках, которые конкатенируются в конце. Такая архитектура называется ColorNet.

Мы реализовали решение для своей задачи, и получили прирост точности почти в 2 раза. С такими результатами и моделями можно работать и искать тот самый шуруп от стола в каталоге интернет-магазина.

У нас было всего 4 классификатора на 4 признака, а есть еще много других. Значит, необходимо создать какой-то фильтр, который будет брать данные каталога и фильтровать их определенным образом.
Фильтрация
Каждый классификатор возвращает soft-метку и класс. Мы взяли значения soft-меток и нашу базу данных, посчитали некоторый score — перемножение всех меток для каждого признака.

Score показывает уверенность всех классификаторов в том, что данная комбинация признаков появится вероятнее всего. Чем больше score, тем вероятнее, что шуруп из каталога и шуруп на картинке похожи.
Pipeline
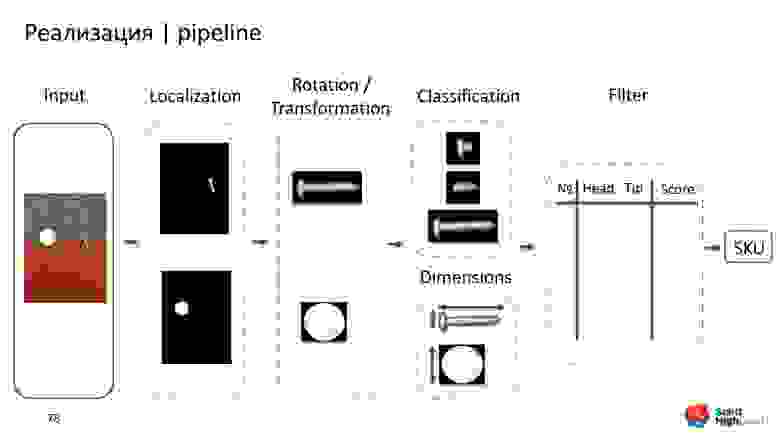
Получилось такое приложение.

- Input: начинаем с сырой картинки.
- Локализация: определяем, где находится болт или шуруп, а где монетка.
- Трансформация и ротация.
- Классификация: все аккуратно обрезаем, классифицируем и определяем размеры.
- Фильтрация.
- Выход на конкретную позицию SKU.
Как реализовать сложный проект
Ешьте слона по частям. Разделите большую проблему на части.
Разметьте данные, которые будут отражать реальность. Не бойтесь разметки данных — это самый безопасный способ, который обеспечит максимальное качество модели быстро. Методы синтезирования данных обычно дают результаты хуже, чем при использовании реальных данных.
Тестируйте. Прежде чем строить много моделей, мы брали маленькие порции данных, размечали руками и проверяли работу каждой гипотезы. Только после этого обучали U-Net, классификаторы, Rotation.
Не изобретайте велосипед. Часто у проблемы, с которой вы столкнулись, уже существует решение. Поищите в интернете, почитайте статьи — обязательно что-нибудь найдете!
Рассказ о нашем Visual Search приложении не только про классификацию шурупов. Он о том, как сделать сложный проект, у которого нет аналогов, но даже если есть — они не удовлетворяют требованиям, которые мы предъявляем к приложению.
Подробнее о проектах Grid Dynamics и других вызовах, с которыми сталкивается команда Data Science, смотрите в техноблоге компании.
Доклады с таким уклоном — применение алгоритмов машинного обучения в реальных нестандартных проектах — мы как раз и ищем для UseData Conf. Здесь подробнее о том, какие сферы нам интереснее всего.
Присылайте заявки, если знаете, как подшаманить модели, чтобы они полетели. Если знаете, что сходимость не гарантирует скорости работы, и готовы рассказать, на что важнее обратить внимание — ждем вас 16 сентября.
