 Привет, Хаброжители! Python и spaCy помогут вам быстро и легко создавать NLP-приложения: чат-боты, сценарии для сокращения текста или инструменты принятия заказов. Вы научитесь использовать spaCy для интеллектуального анализа текста, определять синтаксические связи между словами, идентифицировать части речи, а также определять категории для имен собственных. Ваши приложения даже смогут поддерживать беседу, создавая собственные вопросы на основе разговора.
Привет, Хаброжители! Python и spaCy помогут вам быстро и легко создавать NLP-приложения: чат-боты, сценарии для сокращения текста или инструменты принятия заказов. Вы научитесь использовать spaCy для интеллектуального анализа текста, определять синтаксические связи между словами, идентифицировать части речи, а также определять категории для имен собственных. Ваши приложения даже смогут поддерживать беседу, создавая собственные вопросы на основе разговора.Вы научитесь:
- Работать с векторами слов, чтобы находить синонимы (глава 5).
- Выявлять закономерности в данных с помощью displaCy — встроенного средства визуализации библиотеки spaCy (глава 7).
- Автоматически извлекать ключевые слова из пользовательского ввода и сохранять их в реляционной базе данных (глава 9).
- Развертывать приложения на примере чат-бота для взаимодействия с пользователями (глава 11).
Прочитав эту книгу, вы можете сами расширить приведенные в ней сценарии, чтобы обрабатывать разнообразные варианты ввода и создавать приложения профессионального уровня.
Использование меток синтаксических зависимостей при обработке текста
Как вы узнали из раздела «Выделение и генерация текста с помощью тегов частей речи» на с. 81, теги частей речи — весьма мощный инструмент для интеллектуальной обработки текста. Но на практике для этого может понадобиться больше информации о токенах предложения.
Например, часто необходимо знать, чем является личное местоимение в предложении: подлежащим или дополнением. Иногда это несложно определить. Личные местоимения I, he, she, they и we практически всегда выступают в роли подлежащего. При использовании в качестве дополнения I превращается в me, как в предложении A postman brought me a letter.
Но с некоторыми другими личными местоимениями, например you или it, которые выглядят одинаково и в роли подлежащего и в роли дополнения, не всегда все очевидно. Рассмотрим два предложения: I know you. You know me. В первом предложении you является прямым дополнением глагола know. Во втором же you является подлежащим.
Попробуем решить эту задачу с помощью меток синтаксических зависимостей и тегов частей речи, после чего, опять же с помощью меток синтаксических зависимостей, создадим усовершенствованную версию нашего чат-бота, отвечающего на вопросы.
Различаем подлежащие и дополнения
Чтобы определить программным образом, чем в заданном предложении являются такие местоимения, как you или it, необходимо посмотреть на присвоенную им метку зависимости. Теги частей речи в сочетании с метками зависимостей позволяют получить гораздо больше информации о роли токена в предложении.
Вернемся к предложению из предыдущего примера и взглянем на результаты разбора зависимостей в нем:
>>> doc = nlp(u"I can promise it is worth your time.")
>>> for token in doc:
... print(token.text, token.pos_, token.tag_, token.dep_, spacy.explain(token.dep_))Для токенов предложения были извлечены теги частей речи, метки зависимостей и их описание:
I PRON PRP nsubj nominal subject
can VERB MD aux auxiliary
promise VERB VB ROOT None
it PRON PRP nsubj nominal subject
is VERB VBZ ccomp clausal complement
worth ADJ JJ acomp adjectival complement
your ADJ PRP$ poss possession modifier
time NOUN NN npadvmod noun phrase as adverbial modifier
. PUNCT . punct punctuationВторой и третий столбцы содержат теги общих и уточненных частей речи соответственно. Четвертый столбец содержит метки зависимостей, а пятый — описания этих меток.
Сочетание тегов частей речи с метками зависимостей демонстрирует более ясную, чем теги частей речи или метки зависимости по отдельности, картину грамматической роли каждого из токенов в предложении. В данном примере тег части речи VBZ, присвоенный токену is, означает глагол третьего лица единственного числа настоящего времени, в то время как присвоенная тому же токену метка зависимости ccomp указывает, что is — это клаузальное дополнение (зависимое придаточное предложение с внутренним подлежащим). Здесь is представляет собой клаузальное дополнение глагола promise с внутренним подлежащим it.
Чтобы определить роль you в I know you. You know me, взглянем на следующий список тегов частей речи и меток зависимостей, присвоенных токенам:
I PRON PRP nsubj nominal subject
know VERB VBP ROOT None
you PRON PRP dobj direct object
. PUNCT . punct punctuation
You PRON PRP nsubj nominal subject
know VERB VBP ROOT None
me PRON PRP dobj direct object
. PUNCT . Punct punctuationВ обоих случаях токену you присвоены одни и те же теги частей речи: PRON и PRP (общий и уточненный соответственно). Но метки зависимости в этих двух случаях различны: dobj в первом предложении и nsubj — во втором.
Выясняем, какой вопрос должен задать чат-бот
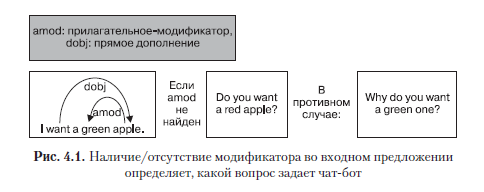
Иногда для извлечения необходимой информации приходится обходить дерево зависимостей предложения. Рассмотрим следующий диалог между чат-ботом и пользователем:
User: I want an apple.
Bot: Do you want a red apple?
User: I want a green apple.
Bot: Why do you want a green one?Чат-бот способен продолжать разговор, просто задавая вопросы. Но обратите внимание, что в выяснении того, какой вопрос ему следует задать, ключевую роль играет наличие/отсутствие прилагательного-модификатора.
В английском языке существует два основных типа вопросов: вопросы типа «да/нет» и информационные вопросы. Возможных ответов на вопросы типа «да/нет» (наподобие сгенерированного в примере из подраздела «Преобразование утвердительных высказываний в вопросительные» на с. 85) может быть только два: да или нет. Чтобы сформулировать подобный вопрос, необходимо поставить вспомогательный модальный глагол перед подлежащим, а смысловой глагол — после подлежащего. Например: Could you modify it?
Информационные вопросы предполагают развернутый ответ, а не только да/нет. Они начинаются с вопросительного слова, например с what, where, when, why или how. Далее процесс формирования информационного вопроса не отличается от процесса с вопросом типа «да/нет». Например: What do you think about it?
В первом случае в предыдущем примере с apple чат-бот задает вопрос типа «да/нет». Во втором случае, когда пользователь добавляет к слову apple модификатор green, чат-бот формулирует информационный вопрос.
Краткая сводка этого подхода приведена на рис. 4.1.
Следующий сценарий анализирует введенное предложение, выбирая, какой вид вопроса задать, после чего формирует соответствующий вопрос. Код этого сценария мы рассмотрим по частям в различных разделах, но программу целиком я рекомендую сохранить в одном файле с названием question.py.
Начнем с импорта модуля sys, который позволяет получить предложение в виде аргумента для дальнейшей обработки:
import spacy
import sysЭто шаг вперед по сравнению с предыдущими сценариями, в которых мы жестко «зашивали» анализируемое предложение. Теперь пользователи могут подавать на вход собственные предложения.
Далее опишем функцию для распознавания и извлечения произвольного именного фрагмента — прямого дополнения из входного документа. Например, если вы ввели документ, содержащий предложение I want a green apple., то будет возвращен фрагмент a green apple:

Проходим в цикле по токенам введенного предложения 1 и, проверяя теги зависимостей на равенство dobj 2, ищем такой токен, который выступал бы в роли прямого дополнения. В предложении I want a green apple. прямым дополнением является существительное apple. После обнаружения прямого дополнения необходимо определить элементы, являющиеся для него синтаксически дочерними 3, поскольку именно из них состоит фрагмент, на основе которого будет определяться тип задаваемого вопроса. В целях отладки полезно вывести на экран дочерние элементы этого прямого дополнения 4.
Для выделения нужного фрагмента производим срез объекта Doc, вычисляя начальный и конечный индексы. Начальный индекс равен индексу найденного прямого дополнения минус число его синтаксических дочерних элементов: как вы, возможно, догадались, он представляет собой индекс крайнего слева дочернего элемента. Конечный индекс равен индексу прямого дополнения плюс один, так что последним включаемым в искомый фрагмент токеном и является это прямое дополнение 5.
Проще говоря, реализованный в сценарии алгоритм предполагает, что у прямого дополнения есть только левосторонние дочерние элементы. В действительности это не всегда так. Например, в предложении I want to touch a wall painted green. необходимо проверять и левосторонние, и правосторонние дочерние элементы прямого дополнения wall. Кроме того, поскольку green не является прямым дочерним элементом wall, необходимо обойти дерево зависимостей, чтобы определить, является ли green модификатором wall.
Следующая функция просматривает фрагмент и определяет, какой тип вопроса должен задать чат-бот:

Сначала задаем начальное значение переменной question_type равным 'yesno', что соответствует вопросу типа «да/нет» 1. Далее в переданном в функцию chunk ищем токен с тегом amod, который означает прилагательное-модификатор 2. Если таковое находится, меняем значение переменной question_type на 'info', соответствующее информационному типу вопроса 3.
Определив, какой тип вопроса нам нужен, генерируем в следующей функции вопрос на основе входного предложения:

В серии циклов for превращаем входное утверждение в вопрос, производя инверсию и замену личных местоимений. Для формирования вопроса перед личным местоимением добавляем глагол do, поскольку в утверждении отсутствует вспомогательный модальный глагол. (Напомню, что такой алгоритм годится лишь для определенных предложений; в более полной реализации необходимо программным образом определять, какой подход к обработке использовать.)
Если значение переменной question_type равно 'info', добавляем слово why в начало вопроса 1. Если значение переменной question_type равно 'yesno' 2, вставляем прилагательное для модификации прямого дополнения в вопросе. В данном примере ради простоты мы жестко «зашили» прилагательное в код, выбрав для этого прилагательное red 3, которое в некоторых предложениях будет выглядеть странно. Например, можно сказать Do you want a red orange?, но никак не Do you want a red idea?. В более совершенной реализации такого чат-бота необходимо определить программным образом подходящее прилагательное для модификации прямого дополнения. Этот вопрос будет рассмотрен в главе 6.
Обратите внимание: используемый алгоритм предполагает, что входное предложение оканчивается знаком препинания, например. или!..
После описания всех функций посмотрим на основной блок сценария:

Прежде всего проверяем, передал ли пользователь предложение в виде аргумента командной строки 1. Если да, то применяем к аргументу конвейер spaCy, создавая экземпляр объекта Doc 2.
Далее передаем этот doc в функцию find_chunk, которая должна вернуть содержащий прямое дополнение именной фрагмент, например a green apple, для дальнейшей обработки 3. Если же во входном предложении такого именного фрагмента нет 4, мы получим сообщение The sentence does not contain a direct object.
Затем передаем только что выделенный фрагмент в функцию determine_question_type, которая, проанализировав его структуру, определяет, какой вопрос задать 5.
Наконец, передаем входное предложение и определенный нами тип вопроса в функцию generate_question, генерирующую соответствующий вопрос и возвращающую его в виде строки 6.
Выводимый сценарием результат зависит от введенного предложения. Вот несколько возможных вариантов:

Если в качестве аргумента командной строки передать предложение, содержащее прилагательное-модификатор (например, green для прямого дополнения наподобие apple), сценарий должен сгенерировать информационный вопрос 1.
Если предложение содержит прямое дополнение без прилагательного-модификатора, сценарий должен ответить вопросом типа «да/нет» 2.
Если же ввести предложение без прямого дополнения, сценарий должен сразу это заметить и предложить повторный ввод 3.
Наконец, если вы забыли передать предложение, сценарий также должен вернуть соответствующее сообщение 4.
Попробуйте сами
Как отмечалось ранее, сценарий, о котором шла речь в предыдущем разделе, годится не для всех предложений. Для формирования вопроса он добавляет глагол do, что подходит только для предложений без вспомогательного модального глагола.
Попробуйте расширить функциональность этого сценария для работы с утверждениями, содержащими вспомогательные модальные глаголы. Например, получив на входе утверждение I might want a green apple., сценарий должен вернуть Why might you want a green one?. Подробнее о том, как преобразовать в вопрос утвердительное высказывание, содержащее вспомогательный модальный глагол, вы прочитали в разделе «Преобразование утвердительных высказываний в вопросительные» на с. 85.
Более подробно с книгой можно ознакомиться на сайте издательства
» Оглавление
» Отрывок
Для Хаброжителей скидка 25% по купону — spaCy
По факту оплаты бумажной версии книги на e-mail высылается электронная книга.
