
В материале, перевод которого мы сегодня публикуем, речь пойдёт о том, что делать в ситуации, когда данные, получаемые с сервера, выглядят не так, как нужно клиенту. А именно, сначала мы рассмотрим типичную проблему такого рода, а потом разберём несколько путей её решения.

Рассмотрим условный пример, в основе которого лежат несколько реальных проектов. Предположим, мы занимаемся разработкой нового веб-сайта для некоей, уже какое-то время существующей, организации. У неё уже есть конечные точки REST, однако они не вполне рассчитаны на то, что мы собираемся создать. Здесь нам нужно обращаться к серверу только для аутентификации пользователя, для получения сведений о нём и для загрузки списка непросмотренных уведомлений этого пользователя. Как результат, нам интересные следующие конечные точки серверного API:
Представим, что нашему приложения все эти данные всегда нужно получать единым блоком, то есть, в идеале, хорошо было бы, если бы вместо трёх конечных точек у нас была бы всего одна.
Однако перед нами встаёт гораздо больше проблем, нежели слишком большое количество конечных точек. В частности, речь идёт о том, что данные, которые мы получаем, выглядят не лучшим образом.
Например, конечная точка
В общем — ничего хорошего.
Правда, если посмотреть на то, что выдаёт конечная точка
Тут список сообщений является объектом, а не массивом. Далее, здесь имеются и данные пользователя, так же неудобно устроенные, как и в случае с конечной точкой
Если бы мне пришлось нарисовать схему архитектуры той адски неудобной системы, о которой мы только что говорили, выглядела бы она так, как показано на рисунке ниже. Красный цвет используется для тех частей этой схемы, которые соответствуют плохо подготовленным к дальнейшей работе данным.
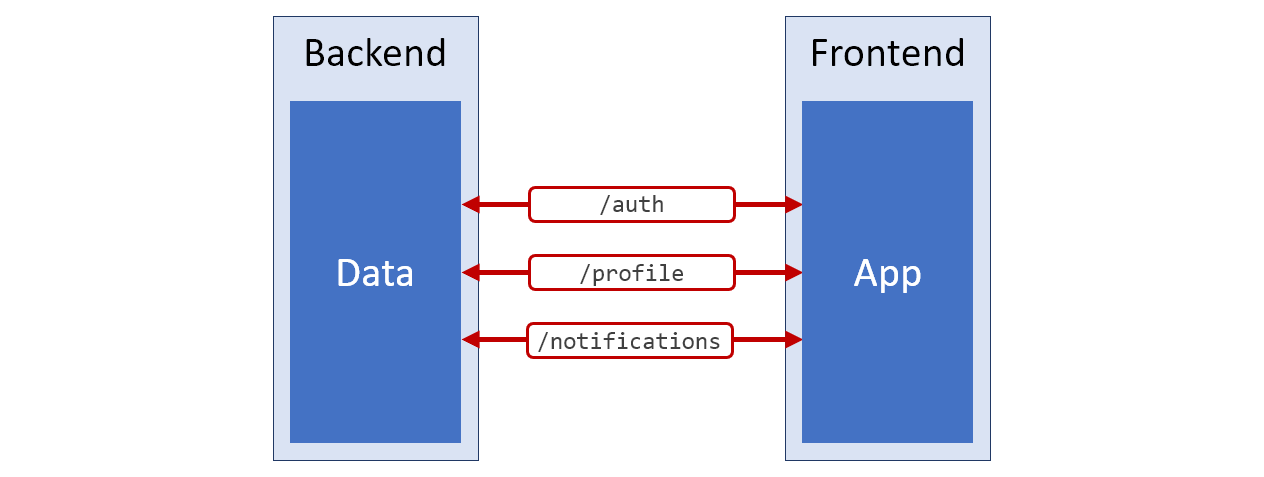
Схема системы
Мы, в данных обстоятельствах, можем не стремиться к тому, чтобы исправить архитектуру этой системы. Можно просто загрузить данные из этих трёх API и использовать эти данные в приложении. Например, если понадобится вывести на странице полное имя пользователя, нам надо будет скомбинировать свойства
Тут хотелось бы сделать одно замечание, касающееся имён. Идея разделения полного имени человека на личное имя и фамилию, характерна для западных стран. Если вы разрабатываете нечто, рассчитанное на международное использование, постарайтесь рассматривать полное имя человека в виде неделимой строки, и не делайте предположений о том, как разбить эту строку на более мелкие части для того, чтобы использовать то, что получилось, в тех местах, где нужна краткость или хочется обратиться к пользователю в неофициальном стиле.
Вернёмся к нашим неидеальным структурам данных. Первая очевидная проблема, которую тут можно увидеть, выражается в необходимости объединения разрозненных данных в коде пользовательского интерфейса. Она заключается в том, что нам может понадобиться повторять это действие в нескольких местах. Если делать это надо лишь изредка — проблема не так уж и серьёзна, но вот если такое нужно часто — это уже куда хуже. Как результат, тут происходят нежелательные явления, вызываемые несоответствием того, как устроены данные, получаемые с сервера, и того, как они используются в приложении.
Вторая проблема заключается в усложнении кода, используемого для формирования пользовательского интерфейса. Я считаю, что такой код должен быть, во-первых, как можно более простым, во-вторых — как можно более понятным. Чем больше внутренних преобразований данных приходится делать на клиенте — тем выше его сложность, а сложный код — это то место, где обычно скрываются ошибки.
Третья проблема касается типов данных. Из вышеприведённых фрагментов кода можно видеть, что, например идентификаторы сообщений — это строки, а идентификаторы пользователей — числа. С технической точки зрения всё нормально, но подобные вещи способны запутать программиста. Кроме того, посмотрите на представление дат! А как вам беспорядок в той части данных, которая относится к изображению профиля? Ведь всё, что нам нужно — это URL, ведущий к соответствующему файлу, а не нечто такое, из чего придётся создавать этот URL самостоятельно, пробираясь сквозь дебри вложенных структур данных.
Если мы будем обрабатывать эти данные, передавая их в код пользовательского интерфейса, тогда, анализируя модули, нельзя будет сходу точно понять, с чем именно мы там работаем. Преобразование внутренней структуры данных и их типа при работе с ними создаёт дополнительную нагрузку на программиста. А ведь без всех этих сложностей вполне можно обойтись.
На самом деле, как вариант, можно было бы реализовать статическую систему типов для решения этой проблемы, но строгая типизация не способна, лишь фактом своего наличия, сделать плохой код хорошим.
Теперь, когда вы смогли убедиться в серьёзности стоящей перед нами проблемы, поговорим о способах её решения.
Если неудобное устройство существующего API не продиктовано какими-то важными причинами, в таком случае ничто не мешает создать его новую версию, лучше удовлетворяющую потребностям проекта, и расположить эту новую версию, скажем, по адресу
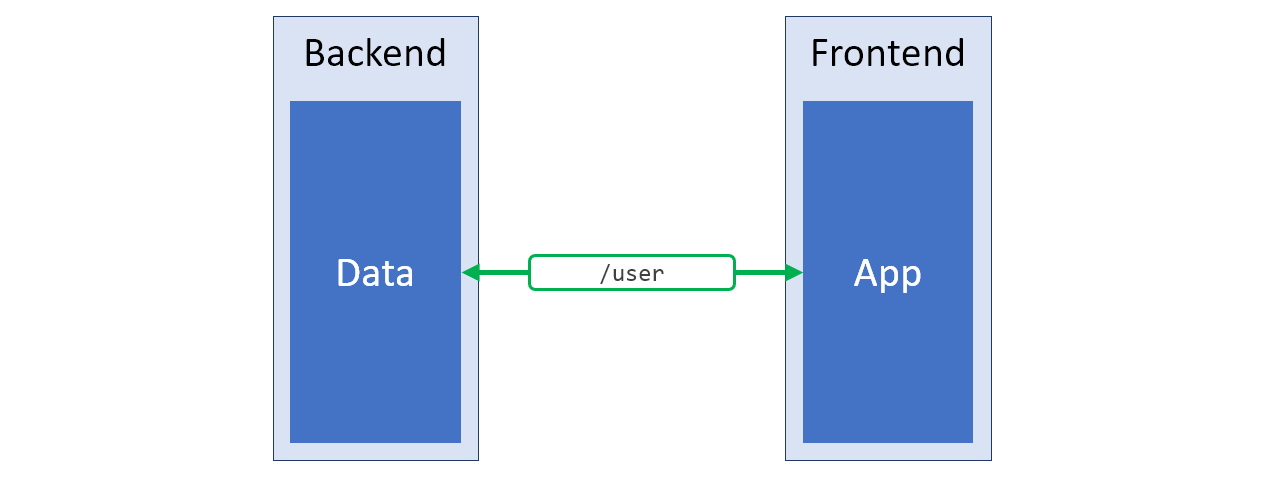
Новое серверное API, выдающее именно то, что нужно клиентской части системы
Приступая к разработке нового проекта, API которого оставляет желать лучшего, я всегда интересуюсь возможности внедрения только что описанного подхода. Однако, иногда устройство API, пусть и неудобное, преследует некие важные цели, или изменение серверного API попросту невозможно. В таком случае я прибегаю к следующему подходу.
Речь идёт о старом добром паттерне BFF (Backend-For-the-Frontend). С использованием этого паттерна можно абстрагироваться от запутанных универсальных конечных точек REST и отдавать фронтенду именно то, что ему нужно. Вот как выглядит схематичное представление такого решения.

Применение паттерна BFF
Смысл существования BFF-слоя — удовлетворение потребностей фронтенда. Возможно, он будет использовать дополнительные конечные точки REST, или сервисы GraphQL, или веб-сокеты, или что угодно другое. Главная его цель — сделать всё возможное для удобства клиентской части приложения.
Моя любимая архитектура — это NodeJS BFF, используя которую фронтенд-разработчики могут делать то, что им нужно, создавая прекрасные API для разрабатываемых ими клиентских приложений. В идеале соответствующий код находится в том же репозитории, что и код самого фронтенда, что упрощает совместное использование кода, например, для проверки отправленных данных, и на клиенте, и на сервере.
Кроме того это означает, что выполнение задач, требующих изменения клиентской части приложения и его серверного API выполняется в одном репозитории. Мелочь, как говорится, а приятно.
Однако, BFF можно применять не всегда. И этот факт ведёт нас к ещё одному решению задачи удобного использования плохих серверных API.
Паттерн BIF (Backend In the Frontend) использует ту же логику, которая может применяться при использовании BFF (комбинирование нескольких API и очистка данных), но эта логика перемещается на сторону клиента. На самом деле, идея это не новая, такое можно было увидеть и лет двадцать назад, но такой подход способен помочь в деле работы с плохо организованными серверными API, поэтому мы о нём и говорим. Вот как это выглядит.

Применение паттерна BIF
Как можно судить из предыдущего раздела, BIF — это паттерн, то есть — подход к осмыслению кода и к его организации. Его использование не приводит к необходимости убирать какую-то логику из проекта. Он всего лишь отделяет логику одного типа (модификация структур данных) от логики другого типа (формирование пользовательского интерфейса). Это аналогично идее «разделения ответственности», которая у всех на слуху.
Тут мне хотелось бы отметить, что, хотя нельзя назвать это катастрофой, мне часто приходилось видеть неграмотные реализации BIF. Поэтому мне и кажется, что многим будет интересно услышать рассказ о том, как правильно реализовать этот паттерн.
BIF-код стоит рассматривать как код, который однажды можно взять и перенести на Node.js-сервер, после чего всё будет работать так же, как раньше. Или даже перенести его в приватный NPM-пакет, который будет использоваться в нескольких фронтенд-проектах в рамках одной компании, что просто восхитительно.
Вспомним о том, что выше мы обсуждали основные проблемы, возникающие при работе с неудачным серверным API. Среди них — слишком частое обращение к API и то, что возвращаемые ими данные не соответствуют нуждам фронтенда.
Решение каждой из этих проблем мы разобьём на отдельные блоки кода, каждый из которых будет размещён в собственном файле. В результате BIF-слой клиентской части приложения будет состоять из двух файлов. Кроме того, к ним будет прилагаться файл с тестом.
Выполнение множества обращения к серверным API в нашем клиентском коде — не такая уж и серьёзная проблема. Однако мне хотелось бы это абстрагировать, сделать так, чтобы можно было бы выполнить единственный «запрос» (от кода приложения к BIF-слою), и получить в ответ именно то, что нужно.
Конечно, в нашем случае от выполнения трёх HTTP-запросов к серверу никуда не деться, но приложению знать об этом необязательно.
API моего BIF-слоя представлено в виде функций. Поэтому, когда приложению нужны какие-то данные о пользователе, оно будет вызывать функцию
Здесь сначала выполняется запрос к сервису аутентификации для получения токена, который можно использовать для того, чтобы авторизовать пользователя (не будем тут говорить о механизмах аутентификации, всё же наша основная цель — BIF).
После получения токена можно, одновременно, выполнить два запроса, получающих данные профиля пользователя и сведения о непрочитанных уведомлениях.
Кстати, посмотрите на то, как красиво выглядит конструкция
Итак, это был первый шаг, здесь мы абстрагировались от того, что обращение к серверу включает в себя три запроса. Однако, дело пока ещё не сделано. А именно, обратите внимание на вызов функции
Хочу сразу дать одну рекомендацию, которая, как я полагаю, способна серьёзно повлиять на проект, в котором раньше не было BIF-слоя, в частности — на новый проект. Постарайтесь на какое-то время не думать о том, что именно вы получаете с сервера. Вместо этого сосредоточьтесь на том, какие данные нужны вашему приложению.
Кроме того, лучше всего не пытаться, при проектировании приложения, учитывать его возможные будущие потребности, скажем, относящиеся к 2021 году. Просто постарайтесь сделать так, чтобы сегодня приложение работало именно так, как нужно. Дело в том, что чрезмерное увлечение планированием и попытки предугадать будущее — это главная причина неоправданного усложнения программных проектов.
Итак, вернёмся к нашим делам. Сейчас нам известно, как выглядят данные, получаемые из трёх серверных API, и известно, во что они должны превратиться после разбора.
Похоже, что тут перед нами один из тех редких случаев, когда применение TDD действительно имеет смысл. Поэтому напишем большой длинный тест для функции
А вот код самой функции:
Мне хотелось бы отметить, что когда удаётся собрать в одном месте две сотни строк кода, ответственных за модификацию данных, разбросанных до этого по всему приложению, это вызывает просто замечательные ощущения. Теперь всё это находится в одном файле, для этого кода написаны модульные тесты, а все неоднозначные моменты снабжены комментариями.
Выше я говорил, что BFF — это мой любимый подход к комбинированию и очистке данных, но есть одна область, в которой BIF превосходит BFF. А именно, данные, пришедшие с сервера, могут включать в себя JavaScript-объекты, которые не поддерживает JSON, вроде объектов типа
Если вам кажется, что у вашего проекта есть что-то общее с тем, на котором мы рассматривали проблемы неудачных API, проанализируйте его код, задавая себе следующие вопросы об использовании на клиенте данных, пришедших с сервера:
Если вы можете положительно ответить на один-два вопроса из этого списка, то, пожалуй, вам не стоит ремонтировать то, что и так исправно работает.
Однако, если вы, читая эти вопросы, узнаёте в каждом из них проблемы вашего проекта, если устройство вашего кода от всего этого неоправданно усложняется, если его тяжело воспринимать и тестировать, если в нём кроются ошибки, которые сложно обнаруживать — присмотритесь к паттерну BIF.
В итоге хочется сказать, что при внедрении BIF-слоя в существующие приложения дело облегчается благодаря тому, что делать это можно поэтапно, маленькими шагами. Скажем, первая версия функции для подготовки данных, назовём её
Уважаемые читатели! Сталкивались ли вы с проблемами, для решения которых автор этого материала предлагает использовать паттерн BIF?


Проблема неудачного серверного API
Рассмотрим условный пример, в основе которого лежат несколько реальных проектов. Предположим, мы занимаемся разработкой нового веб-сайта для некоей, уже какое-то время существующей, организации. У неё уже есть конечные точки REST, однако они не вполне рассчитаны на то, что мы собираемся создать. Здесь нам нужно обращаться к серверу только для аутентификации пользователя, для получения сведений о нём и для загрузки списка непросмотренных уведомлений этого пользователя. Как результат, нам интересные следующие конечные точки серверного API:
/auth: авторизует пользователя и возвращает токен доступа./profile: возвращает основную информацию о пользователе./notifications: позволяет получить непрочитанные уведомления пользователя.
Представим, что нашему приложения все эти данные всегда нужно получать единым блоком, то есть, в идеале, хорошо было бы, если бы вместо трёх конечных точек у нас была бы всего одна.
Однако перед нами встаёт гораздо больше проблем, нежели слишком большое количество конечных точек. В частности, речь идёт о том, что данные, которые мы получаем, выглядят не лучшим образом.
Например, конечная точка
/profile была создана в давние времена, писали её не на JavaScript, в результате имена свойств в возвращаемых ей данных выглядят, для JS-приложения, непривычно:{
"Profiles": [
{
"id": 1234,
"Christian_Name": "David",
"Surname": "Gilbertson",
"Photographs": [
{
"Size": "Medium",
"URLS": [
"/images/david.png"
]
}
],
"Last_Login": "2018-01-01"
}
]
}В общем — ничего хорошего.
Правда, если посмотреть на то, что выдаёт конечная точка
/notifications, то вышерассмотренные данные из /profile покажутся прямо-таки симпатичными:{
"data": {
"msg-1234": {
"timestamp": "1529739612",
"user": {
"Christian_Name": "Alice",
"Surname": "Guthbertson",
"Enhanced": "True",
"Photographs": [
{
"Size": "Medium",
"URLS": [
"/images/alice.png"
]
}
]
},
"message_summary": "Hey I like your hair, it re",
"message": "Hey I like your hair, it really goes nice with your eyes"
},
"msg-5678": {
"timestamp": "1529731234",
"user": {
"Christian_Name": "Bob",
"Surname": "Smelthsen",
"Photographs": [
{
"Size": "Medium",
"URLS": [
"/images/smelth.png"
]
}
]
},
"message_summary": "I'm launching my own cryptocu",
"message": "I'm launching my own cryptocurrency soon and many thanks for you to look at and talk about"
}
}
}Тут список сообщений является объектом, а не массивом. Далее, здесь имеются и данные пользователя, так же неудобно устроенные, как и в случае с конечной точкой
/profile. И — вот уж сюрприз — свойство timestamp содержит количество секунд с начала 1970-го.Если бы мне пришлось нарисовать схему архитектуры той адски неудобной системы, о которой мы только что говорили, выглядела бы она так, как показано на рисунке ниже. Красный цвет используется для тех частей этой схемы, которые соответствуют плохо подготовленным к дальнейшей работе данным.
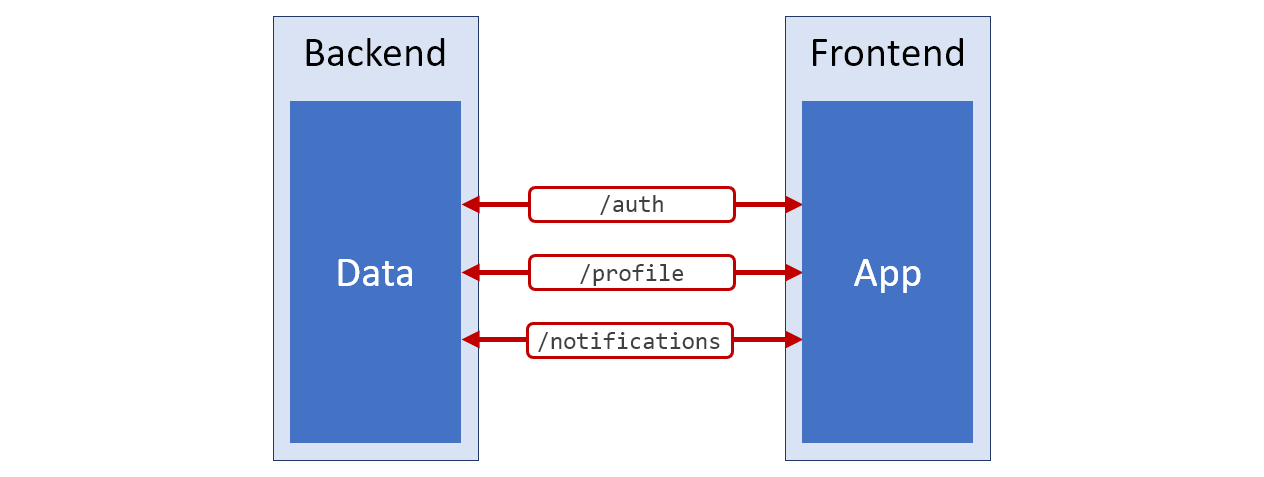
Схема системы
Мы, в данных обстоятельствах, можем не стремиться к тому, чтобы исправить архитектуру этой системы. Можно просто загрузить данные из этих трёх API и использовать эти данные в приложении. Например, если понадобится вывести на странице полное имя пользователя, нам надо будет скомбинировать свойства
Christian_Name и Surname.Тут хотелось бы сделать одно замечание, касающееся имён. Идея разделения полного имени человека на личное имя и фамилию, характерна для западных стран. Если вы разрабатываете нечто, рассчитанное на международное использование, постарайтесь рассматривать полное имя человека в виде неделимой строки, и не делайте предположений о том, как разбить эту строку на более мелкие части для того, чтобы использовать то, что получилось, в тех местах, где нужна краткость или хочется обратиться к пользователю в неофициальном стиле.
Вернёмся к нашим неидеальным структурам данных. Первая очевидная проблема, которую тут можно увидеть, выражается в необходимости объединения разрозненных данных в коде пользовательского интерфейса. Она заключается в том, что нам может понадобиться повторять это действие в нескольких местах. Если делать это надо лишь изредка — проблема не так уж и серьёзна, но вот если такое нужно часто — это уже куда хуже. Как результат, тут происходят нежелательные явления, вызываемые несоответствием того, как устроены данные, получаемые с сервера, и того, как они используются в приложении.
Вторая проблема заключается в усложнении кода, используемого для формирования пользовательского интерфейса. Я считаю, что такой код должен быть, во-первых, как можно более простым, во-вторых — как можно более понятным. Чем больше внутренних преобразований данных приходится делать на клиенте — тем выше его сложность, а сложный код — это то место, где обычно скрываются ошибки.
Третья проблема касается типов данных. Из вышеприведённых фрагментов кода можно видеть, что, например идентификаторы сообщений — это строки, а идентификаторы пользователей — числа. С технической точки зрения всё нормально, но подобные вещи способны запутать программиста. Кроме того, посмотрите на представление дат! А как вам беспорядок в той части данных, которая относится к изображению профиля? Ведь всё, что нам нужно — это URL, ведущий к соответствующему файлу, а не нечто такое, из чего придётся создавать этот URL самостоятельно, пробираясь сквозь дебри вложенных структур данных.
Если мы будем обрабатывать эти данные, передавая их в код пользовательского интерфейса, тогда, анализируя модули, нельзя будет сходу точно понять, с чем именно мы там работаем. Преобразование внутренней структуры данных и их типа при работе с ними создаёт дополнительную нагрузку на программиста. А ведь без всех этих сложностей вполне можно обойтись.
На самом деле, как вариант, можно было бы реализовать статическую систему типов для решения этой проблемы, но строгая типизация не способна, лишь фактом своего наличия, сделать плохой код хорошим.
Теперь, когда вы смогли убедиться в серьёзности стоящей перед нами проблемы, поговорим о способах её решения.
Решение №1: изменение серверного API
Если неудобное устройство существующего API не продиктовано какими-то важными причинами, в таком случае ничто не мешает создать его новую версию, лучше удовлетворяющую потребностям проекта, и расположить эту новую версию, скажем, по адресу
/v2. Пожалуй, такой подход можно назвать наиболее удачным решением вышеописанной проблемы. Схема такой системы представлена на рисунке ниже, зелёным цветом выделена структура данных, которая отлично соответствует нуждам клиента.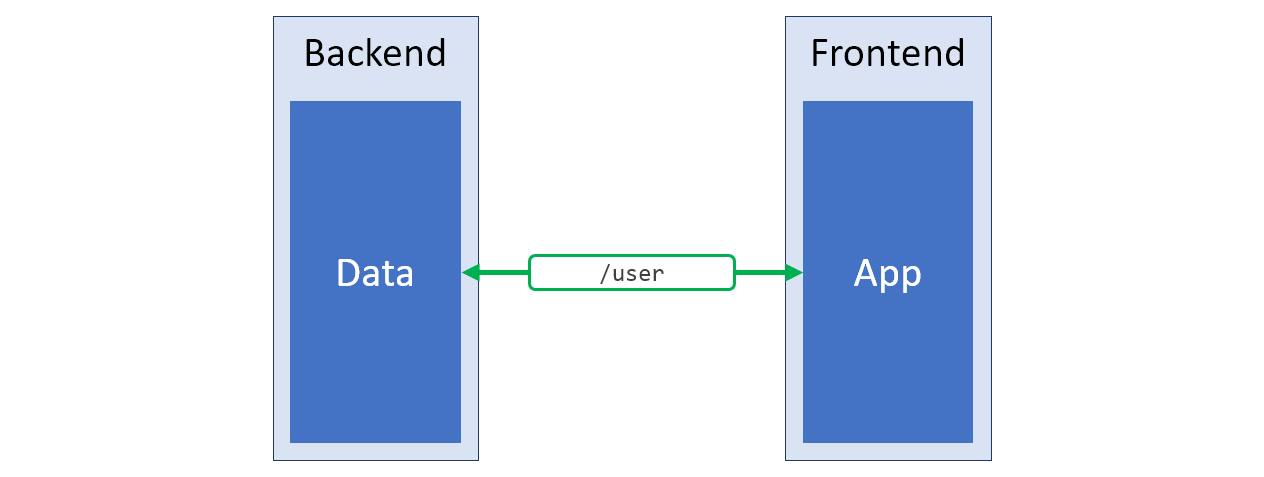
Новое серверное API, выдающее именно то, что нужно клиентской части системы
Приступая к разработке нового проекта, API которого оставляет желать лучшего, я всегда интересуюсь возможности внедрения только что описанного подхода. Однако, иногда устройство API, пусть и неудобное, преследует некие важные цели, или изменение серверного API попросту невозможно. В таком случае я прибегаю к следующему подходу.
Решение №2: паттерн BFF
Речь идёт о старом добром паттерне BFF (Backend-For-the-Frontend). С использованием этого паттерна можно абстрагироваться от запутанных универсальных конечных точек REST и отдавать фронтенду именно то, что ему нужно. Вот как выглядит схематичное представление такого решения.
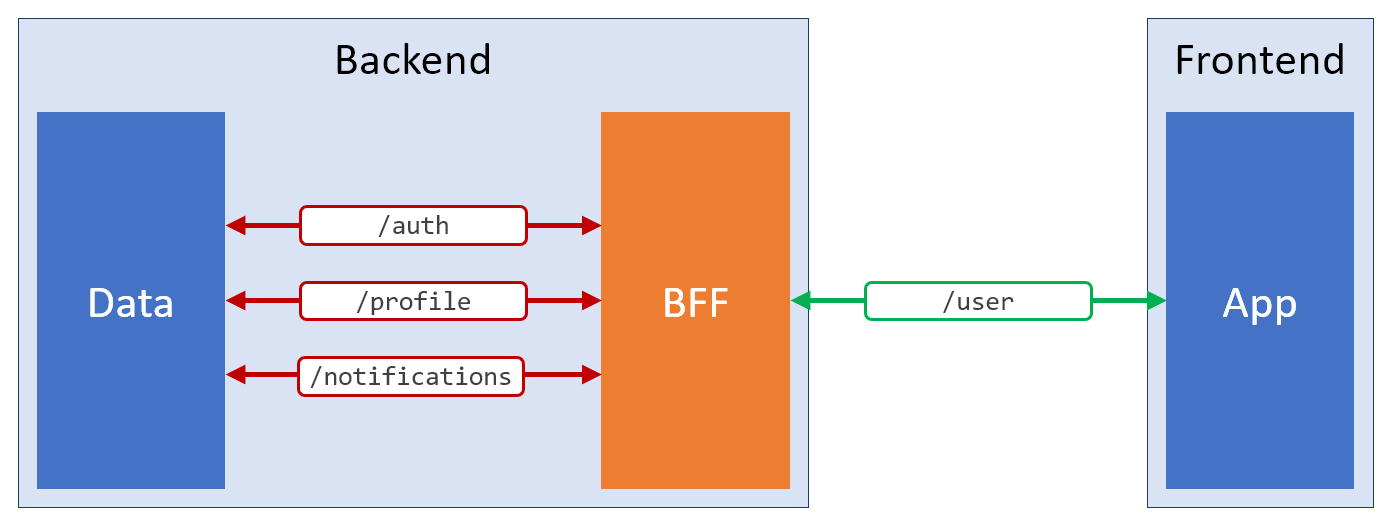
Применение паттерна BFF
Смысл существования BFF-слоя — удовлетворение потребностей фронтенда. Возможно, он будет использовать дополнительные конечные точки REST, или сервисы GraphQL, или веб-сокеты, или что угодно другое. Главная его цель — сделать всё возможное для удобства клиентской части приложения.
Моя любимая архитектура — это NodeJS BFF, используя которую фронтенд-разработчики могут делать то, что им нужно, создавая прекрасные API для разрабатываемых ими клиентских приложений. В идеале соответствующий код находится в том же репозитории, что и код самого фронтенда, что упрощает совместное использование кода, например, для проверки отправленных данных, и на клиенте, и на сервере.
Кроме того это означает, что выполнение задач, требующих изменения клиентской части приложения и его серверного API выполняется в одном репозитории. Мелочь, как говорится, а приятно.
Однако, BFF можно применять не всегда. И этот факт ведёт нас к ещё одному решению задачи удобного использования плохих серверных API.
Решение №3: паттерн BIF
Паттерн BIF (Backend In the Frontend) использует ту же логику, которая может применяться при использовании BFF (комбинирование нескольких API и очистка данных), но эта логика перемещается на сторону клиента. На самом деле, идея это не новая, такое можно было увидеть и лет двадцать назад, но такой подход способен помочь в деле работы с плохо организованными серверными API, поэтому мы о нём и говорим. Вот как это выглядит.

Применение паттерна BIF
▍Что такое BIF?
Как можно судить из предыдущего раздела, BIF — это паттерн, то есть — подход к осмыслению кода и к его организации. Его использование не приводит к необходимости убирать какую-то логику из проекта. Он всего лишь отделяет логику одного типа (модификация структур данных) от логики другого типа (формирование пользовательского интерфейса). Это аналогично идее «разделения ответственности», которая у всех на слуху.
Тут мне хотелось бы отметить, что, хотя нельзя назвать это катастрофой, мне часто приходилось видеть неграмотные реализации BIF. Поэтому мне и кажется, что многим будет интересно услышать рассказ о том, как правильно реализовать этот паттерн.
BIF-код стоит рассматривать как код, который однажды можно взять и перенести на Node.js-сервер, после чего всё будет работать так же, как раньше. Или даже перенести его в приватный NPM-пакет, который будет использоваться в нескольких фронтенд-проектах в рамках одной компании, что просто восхитительно.
Вспомним о том, что выше мы обсуждали основные проблемы, возникающие при работе с неудачным серверным API. Среди них — слишком частое обращение к API и то, что возвращаемые ими данные не соответствуют нуждам фронтенда.
Решение каждой из этих проблем мы разобьём на отдельные блоки кода, каждый из которых будет размещён в собственном файле. В результате BIF-слой клиентской части приложения будет состоять из двух файлов. Кроме того, к ним будет прилагаться файл с тестом.
▍Комбинирование обращений к API
Выполнение множества обращения к серверным API в нашем клиентском коде — не такая уж и серьёзная проблема. Однако мне хотелось бы это абстрагировать, сделать так, чтобы можно было бы выполнить единственный «запрос» (от кода приложения к BIF-слою), и получить в ответ именно то, что нужно.
Конечно, в нашем случае от выполнения трёх HTTP-запросов к серверу никуда не деться, но приложению знать об этом необязательно.
API моего BIF-слоя представлено в виде функций. Поэтому, когда приложению нужны какие-то данные о пользователе, оно будет вызывать функцию
getUser(), которая вернёт ему эти данные. Вот как выглядит эта функция:import parseUserData from './parseUserData';
import fetchJson from './fetchJson';
export const getUser = async () => {
const auth = await fetchJson('/auth');
const [ profile, notifications ] = await Promise.all([
fetchJson(`/profile/${auth.userId}`, auth.jwt),
fetchJson(`/notifications/${auth.userId}`, auth.jwt),
]);
return parseUserData(auth, profile, notifications);
};Здесь сначала выполняется запрос к сервису аутентификации для получения токена, который можно использовать для того, чтобы авторизовать пользователя (не будем тут говорить о механизмах аутентификации, всё же наша основная цель — BIF).
После получения токена можно, одновременно, выполнить два запроса, получающих данные профиля пользователя и сведения о непрочитанных уведомлениях.
Кстати, посмотрите на то, как красиво выглядит конструкция
async/await, когда с ней работают, используя Promise.all и применяют деструктурирующее присваивание.Итак, это был первый шаг, здесь мы абстрагировались от того, что обращение к серверу включает в себя три запроса. Однако, дело пока ещё не сделано. А именно, обратите внимание на вызов функции
parseUserData(), которая, как можно судить из её имени, приводит в порядок данные, полученные с сервера. Поговорим о ней.▍Очистка данных
Хочу сразу дать одну рекомендацию, которая, как я полагаю, способна серьёзно повлиять на проект, в котором раньше не было BIF-слоя, в частности — на новый проект. Постарайтесь на какое-то время не думать о том, что именно вы получаете с сервера. Вместо этого сосредоточьтесь на том, какие данные нужны вашему приложению.
Кроме того, лучше всего не пытаться, при проектировании приложения, учитывать его возможные будущие потребности, скажем, относящиеся к 2021 году. Просто постарайтесь сделать так, чтобы сегодня приложение работало именно так, как нужно. Дело в том, что чрезмерное увлечение планированием и попытки предугадать будущее — это главная причина неоправданного усложнения программных проектов.
Итак, вернёмся к нашим делам. Сейчас нам известно, как выглядят данные, получаемые из трёх серверных API, и известно, во что они должны превратиться после разбора.
Похоже, что тут перед нами один из тех редких случаев, когда применение TDD действительно имеет смысл. Поэтому напишем большой длинный тест для функции
parseUserData():import parseUserData from './parseUserData';
it('should parse the data', () => {
const authApiData = {
userId: 1234,
jwt: 'the jwt',
};
const profileApiData = {
Profiles: [
{
id: 1234,
Christian_Name: 'David',
Surname: 'Gilbertson',
Photographs: [
{
Size: 'Medium',
URLS: [
'/images/david.png',
],
},
],
Last_Login: '2018-01-01'
},
],
};
const notificationsApiData = {
data: {
'msg-1234': {
timestamp: '1529739612',
user: {
Christian_Name: 'Alice',
Surname: 'Guthbertson',
Enhanced: 'True',
Photographs: [
{
Size: 'Medium',
URLS: [
'/images/alice.png'
]
}
]
},
message_summary: 'Hey I like your hair, it re',
message: 'Hey I like your hair, it really goes nice with your eyes'
},
'msg-5678': {
timestamp: '1529731234',
user: {
Christian_Name: 'Bob',
Surname: 'Smelthsen',
},
message_summary: 'I\'m launching my own cryptocu',
message: 'I\'m launching my own cryptocurrency soon and many thanks for you to look at and talk about'
},
},
};
const parsedData = parseUserData(authApiData, profileApiData, notificationsApiData);
expect(parsedData).toEqual({
jwt: 'the jwt',
id: '1234',
name: 'David Gilbertson',
photoUrl: '/images/david.png',
notifications: [
{
id: 'msg-1234',
dateTime: expect.any(Date),
name: 'Alice Guthbertson',
premiumMember: true,
photoUrl: '/images/alice.png',
message: 'Hey I like your hair, it really goes nice with your eyes'
},
{
id: 'msg-5678',
dateTime: expect.any(Date),
name: 'Bob Smelthsen',
premiumMember: false,
photoUrl: '/images/placeholder.jpg',
message: 'I\'m launching my own cryptocurrency soon and many thanks for you to look at and talk about'
},
],
});
});А вот код самой функции:
const getPhotoFromProfile = profile => {
try {
return profile.Photographs[0].URLS[0];
} catch (err) {
return '/images/placeholder.jpg'; // стандартное изображение
}
};
const getFullNameFromProfile = profile => `${profile.Christian_Name} ${profile.Surname}`;
export default function parseUserData(authApiData, profileApiData, notificationsApiData) {
const profile = profileApiData.Profiles[0];
const result = {
jwt: authApiData.jwt,
id: authApiData.userId.toString(), // ID всегда должны иметь строковой тип
name: getFullNameFromProfile(profile),
photoUrl: getPhotoFromProfile(profile),
notifications: [], // Массив с уведомлениями должен присутствовать всегда, даже если он пуст
};
Object.entries(notificationsApiData.data).forEach(([id, notification]) => {
result.notifications.push({
id,
dateTime: new Date(Number(notification.timestamp) * 1000), // дата, полученная с сервера, выражена в секундах, прошедших с начала эпохи Unix, а не в миллисекундах
name: getFullNameFromProfile(notification.user),
photoUrl: getPhotoFromProfile(notification.user),
message: notification.message,
premiumMember: notification.user.Enhanced === 'True',
})
});
return result;
}Мне хотелось бы отметить, что когда удаётся собрать в одном месте две сотни строк кода, ответственных за модификацию данных, разбросанных до этого по всему приложению, это вызывает просто замечательные ощущения. Теперь всё это находится в одном файле, для этого кода написаны модульные тесты, а все неоднозначные моменты снабжены комментариями.
Выше я говорил, что BFF — это мой любимый подход к комбинированию и очистке данных, но есть одна область, в которой BIF превосходит BFF. А именно, данные, пришедшие с сервера, могут включать в себя JavaScript-объекты, которые не поддерживает JSON, вроде объектов типа
Date или Map (пожалуй, это — одна из самых недостаточно используемых возможностей JavaScript). Например, в нашем случае приходится конвертировать дату, пришедшую с сервера (выраженную в секундах, а не в миллисекундах) в JS-объект типа Date.Итоги
Если вам кажется, что у вашего проекта есть что-то общее с тем, на котором мы рассматривали проблемы неудачных API, проанализируйте его код, задавая себе следующие вопросы об использовании на клиенте данных, пришедших с сервера:
- Приходится ли вам объединять свойства, которые никогда не используются раздельно (например, имя и фамилию пользователя)?
- Приходится ли в JS-коде работать с именами свойств, сформированных так, как в JS не принято (нечто вроде PascalCase)?
- Каковы типы данных различных идентификаторов? Может быть, иногда это — строки, иногда — числа?
- Как в вашем проекте представлены даты? Может быть, иногда это — JS-объекты
Date, готовые к использованию в интерфейсе, а иногда — числа, или даже строки? - Часто ли приходится проверять свойства на предмет их существования, или проверять, является ли некая сущность массивом, прежде чем начать перебор элементов этой сущности для формирования на её основе какого-нибудь фрагмента пользовательского интерфейса? Может ли случиться так, что эта сущность не будет массивом, хотя бы и пустым?
- Приходится ли, при формировании интерфейса, сортировать или фильтровать массивы, которые, в идеале, должны уже быть правильно отсортированы и отфильтрованы?
- Если оказывается, что, при проверке свойств на предмет их существования, искомых свойств нет, приходится ли переходить к использованию неких значений, применяемых по умолчанию (например — использовать стандартную картинку в тех случаях, когда в данных, полученных с сервера нет фотографии пользователя)?
- Единообразно ли именуются свойства? Случается ли так, что одна и та же сущность может иметь разные имена, что, возможно, вызвано совместным использованием, условно говоря, «старых» и «новых» серверных API?
- Приходится ли, наряду с полезными данными, передавать куда-либо и данные, которые никогда не используются, делая это лишь из-за того что они поступают из серверного API? Мешают ли эти неиспользуемые данные при отладке?
Если вы можете положительно ответить на один-два вопроса из этого списка, то, пожалуй, вам не стоит ремонтировать то, что и так исправно работает.
Однако, если вы, читая эти вопросы, узнаёте в каждом из них проблемы вашего проекта, если устройство вашего кода от всего этого неоправданно усложняется, если его тяжело воспринимать и тестировать, если в нём кроются ошибки, которые сложно обнаруживать — присмотритесь к паттерну BIF.
В итоге хочется сказать, что при внедрении BIF-слоя в существующие приложения дело облегчается благодаря тому, что делать это можно поэтапно, маленькими шагами. Скажем, первая версия функции для подготовки данных, назовём её
parseData(), может просто, без изменений, возвращать то, что поступает на её вход. Затем можно постепенно перемещать логику из кода, ответственного за формирование пользовательского интерфейса, в эту функцию.Уважаемые читатели! Сталкивались ли вы с проблемами, для решения которых автор этого материала предлагает использовать паттерн BIF?

