

Эту статью я написал в противовес статье “For the love of god, stop using CPU limits on Kubernetes” (Ради всего святого, прекратите использовать в Kubernetes лимиты CPU).
Мне та статья понравилась, и я считаю её хорошим чтивом. Более того, я согласен с высказанными в ней рекомендациями относительно установки объёмов запрашиваемой памяти и её лимитов для контейнеров, а также с советом всегда устанавливать запросы на выделение CPU.
При этом моё несогласие, явно выраженное в противоположном по смыслу заголовке, связано с той категоричностью, с которой в итоге автор рекомендует не устанавливать лимиты потребления CPU.
Краткое обобщение по управлению в Kubernetes ресурсами для контейнеров: «запрос» CPU – это минимальный объём вычислительной мощности процессора, доступный контейнеру в процессе выполнения, а «лимит» CPU – это максимальный объём мощности процессора, который контейнер может использовать.
Для тех же, кто желает глубже разобраться в принципах работы Kubernetes, я рекомендую публикацию Стефани Лай “Layer-by-Layer Cgroup in Kubernetes” и подкреплённую данными серию из трёх статей (англ.), написанную Шоном Лев-Раном и Широм Монетером.
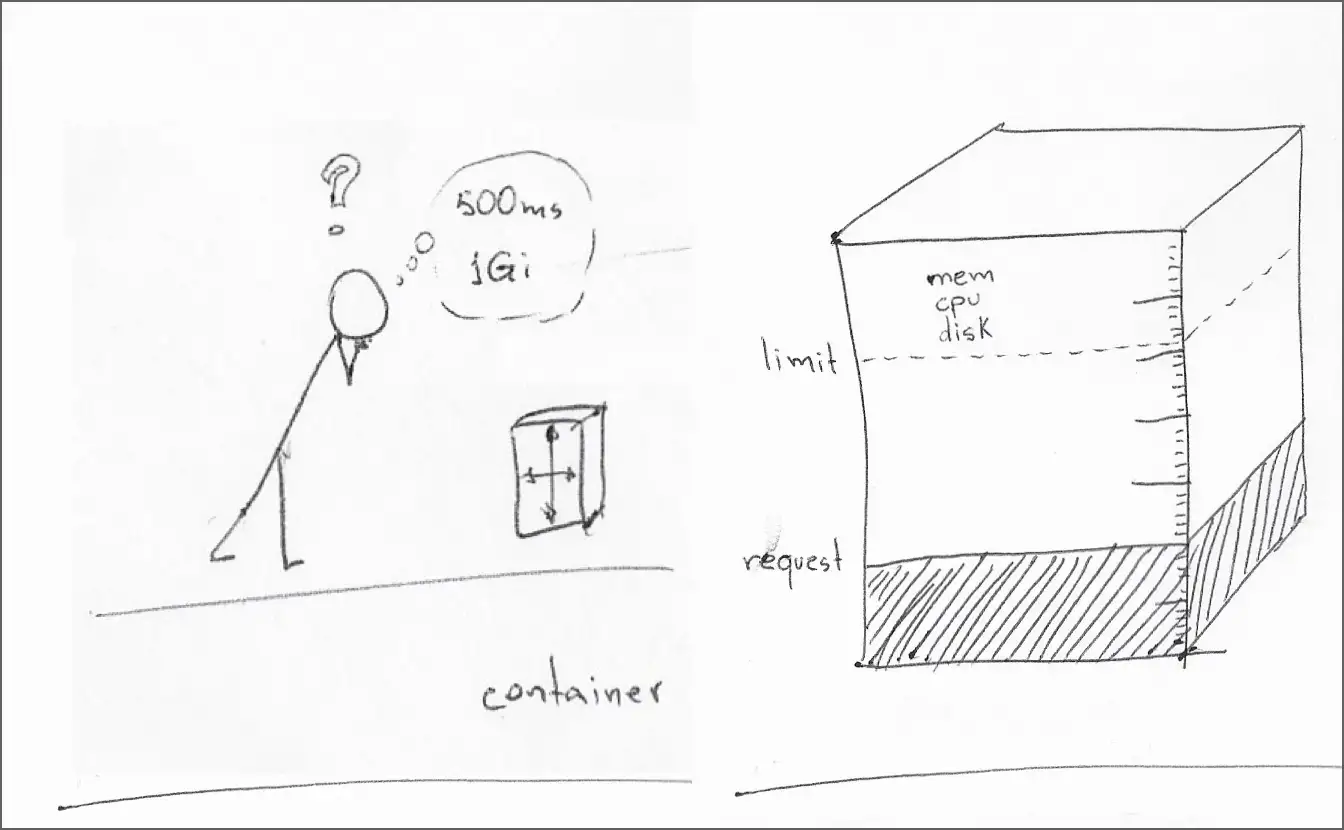
Kubernetes позволяет разработчикам ПО и системным администраторам взаимодействовать в плане настройки минимальных резервов и максимальных пределов использования таких ресурсов, как CPU, память и временное хранилище.
Идея отказа от лимитов CPU стоит на том, что установка такого лимита имеет негативный эффект, не позволяя контейнеру задействовать неиспользуемое (и незарезервированное) время CPU в узле и подвергая его ненужному и потенциально вредному троттлингу процессора.
Однако после обширного исследования в ходе написания “Infinite scaling with containers and Kubernetes” я обнаружил явные причины для того, чтобы в большинстве случаев все же лимиты потребления CPU устанавливать, и ниже опишу основания этой своей еретической идеи.
▍ Причина #1: отказоустойчивость во время троттлинга
Обновлено 9/30: изначально этот раздел назывался «Пробы контейнеров не поддаются сжатию», что размывало его основную суть: разработка контейнеров с установкой лимитов CPU делает их более устойчивыми, в том числе при троттлинге. Создание проб для проверки активности контейнеров (liveness probes), которые более устойчивы к троттлингу, и проб готовности (readiness probes), которые при троттлинге более точны, представляет лишь два из множества возможных положительных следствий создания контейнеров с лимитами CPU.
Когда контейнер пытается использовать больше CPU, чем доступно – игнорируя предварительные смягчающие меры, вроде перемещения подов между узлами – узел «троттлит» выделение CPU для контейнера, по сути, замедляя его выполнение. Именно поэтому в документации Kubernetes процессоры обозначены как «сжимаемые» ресурсы.
Из этого вытекает распространённое предположение, что контейнеры могут безопасно переживать события троттлинга. Однако это предположение натыкается на неизбежное следствие, связанное с пробами Kubernetes.
Когда kubelet троттлит контейнер, это может воздействовать на все потоки внутри данного контейнера, включая те, что обрабатывают пробы активности и готовности.
Даже если в контейнере установлен запрос CPU, его излишне высокая внутренняя нагрузка может потреблять непропорциональную долю этого выделения, замедляя реакцию проб.
Последующие сбои или таймауты пробы готовности приводят к тому, что kubelet перенаправляет трафик от этого контейнера. Если же сбои/таймауты касаются пробы активности, то kubelet завершает контейнер.
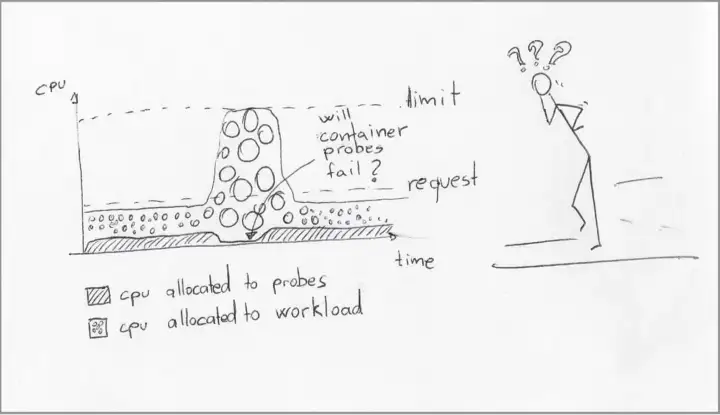
Сохранение контроля использования CPU также полезно для вашего контейнера. Когда он испытывает троттлинг, излишне активный поток может препятствовать выделению времени CPU для других потоков, ставя активность всего контейнера под угрозу.
Я обширно раскрыл тему хороших практик при проектировании проб контейнеров (англ.), которые увеличивают вероятность реагирования проб на kubelet, когда контейнер находится в «стрессовом» состоянии. Но эта вероятность уменьшается прямо пропорционально излишнему использованию контейнером мощности CPU поверх установленного запросом объёма.
[Если троттлинг для проб вреден, то установка лимитов CPU только всё ухудшит, поскольку число случаев троттлинга возрастёт].
Смысл не в том, что запуск в продакшен контейнеров с лимитами CPU сделает их более устойчивыми к событиям троттлинга. Естественно, этого не произойдёт. Ключевой аспект здесь заключается в изначальном создании контейнеров с лимитами CPU в течение всей стадии разработки.
Последующее наблюдение нежелательного поведения под троттлингом – предполагая систематический запуск контейнера под высокой нагрузкой в ограниченных по ресурсам узлах – помогает принимать важные решения относительно дизайна и реализации.
Подобные наблюдения могут, например, предоставить возможность:
- задействовать больше внутреннего состояния контейнера в пробе готовности, и тем самым помочь kubelet перенаправлять трафик на другие, менее нагруженные, реплики;
- пересматривать дизайн и корректировать пулы внутренних потоков;
- представить дополнительные параметры настройки для системных администраторов.
С обратной же стороны, если создавать контейнеры без лимитов CPU, их поведение будет зависеть от наличия свободных циклов процессора в узле. Контейнер, который устойчиво хорошо работает в кластере разработки с низкой нагрузкой, может совсем иначе повести себя в условиях недоступности тех же объёмов свободного CPU.
Вывод: создавайте и тестируйте контейнеры с включённым лимитом потребления CPU, чтобы заставить их работать устойчиво в условиях троттлинга. Когда kubelet троттлит нагрузки, его не беспокоят возможные последствия для них.
▍ Причина #2: утрата статуса “Guaranteed“
Обновлено 9/28: этот раздел назывался «Повышенные штрафы для повышенных нагрузок» и ошибочно утверждал, что превышение установленного запроса CPU, влияет на алгоритм исключения подов для восполнения ресурсов узлов (node-pressure eviction).
Это косвенная причина, но её стоит упомянуть.
Настройка запросов и лимитов ресурсов для каждого контейнера в поде определяет класс качества обслуживания (QoS) этого пода:
- отсутствие запросов или лимитов классифицирует под как “BestEffort”. Этот QoS в данном случае исключается, поскольку мы изначально предположили, что для всех контейнеров запросы памяти и CPU установлены;
- если для контейнера определён только запрос CPU, но не лимит, тогда под классифицируется как “Burstable”;
- единственный способ получить для пода QoS “Guaranteed” – это установить идентичные значения запроса/лимита CPU и памяти для каждого контейнера пода.
Наиболее примечательный случай применения QoS – это “node-pressure eviction”, когда kubelet анализирует, какие поды нужно удалить из узла, чтобы освободить дополнительные ресурсы.
Guaranteed поды стоят в списке на удаление последними – при условии равных приоритетов подов – а Burstable, наоборот, исключаются первыми.
Имейте в виду, что анализ на предмет удаления подразумевает оценку только памяти, использования диска и индексных дескрипторов файловой системы. В этом плане технически может случиться так, что Burstable под превысит установленный запрос CPU, но в случае анализа на удаление всё равно будет оценён вровень с подами Guaranteed.
Менее распространённый (а может менее популярный) случай связан с использованием политик управления CPU, когда преимущества «политики Static» касаются только Guaranteed подов (использующих целочисленные запросы CPU). Рекомендую подробнее почитать о преимуществах использования CPU Manager, чтобы понять, как он содействует работе этих конкретных нагрузок.
Вывод: ещё раз скажу – стремитесь управлять использованием CPU внутри контейнера.
Отсутствие лимита CPU опускает под до QoS “Burstable”, лишая его привилегий в некоторых сценариях планирования и троттлинга.
▍ Причина #3: использование CPU и памяти связано
К лучшему это или к худшему, но CPU и память в вычислительной технике связаны неразрывно. Именно поэтому ни один облачный провайдер не предлагает виртуальные машины с непропорциональным соотношением мощностей CPU и объёма памяти, например, узел 16х2 (16 CPU и 2 гигабайта ОЗУ). Чаще всего соотношение этих ресурсов в вычислительных инстансах нацелено в обратном направлении, когда число процессоров составляет одну четвёртую или одну вторую от объёма памяти (в гигабайтах), например, 8х16, 16х64 или 32х64.
Для подобного правила есть множество практических причин, но, в общем, можно выделить две:
- для считывания и записи больших объёмов памяти требуется множество CPU;
- использование множества CPU означает использование множества потоков (сопровождающихся стеками потоков в памяти) и производство больших объёмов данных, которые должны помещаться в память (даже в случае их кэширования на пути в постоянное хранилище).
Кто-то может вообразить сценарии, в которых множество CPU передают вывод сразу на диск (без кэширования данных в памяти?). И всё же, если вы прилежно выполняли домашнюю работу в ходе разработки, сложно представить, как контейнер, запрашивающий 200m CPU и 256МБ ОЗУ, может эффективно использовать 2 CPU (в десять раз больше запрошенного количества), не требуя больше памяти (даже если не в 10 раз больше).
Вывод: исключение лимита на использование CPU (вплоть до лимита CPU всего узла) без позволения задействовать соответствующие дополнительные объёмы памяти не совпадает с паттерном использования большинства приложений. С точки зрения системы будет лучше последовать рекомендации следующего раздела.
▍ Причина #4: автоскейлы подов могут справляться лучше
Один из аргументов в пользу того, чтобы позволять контейнерам свободно превышать установленные лимиты CPU, гласит – если некоторая доля CPU узла не используется, можно дать подам возможность задействовать этот свободный ресурс.
Я с этим принципом согласен, но, как говорилось в предыдущем разделе, этот свободный ресурс CPU для поддержания какой-бы то ни было дополнительной работы, зачастую требует больше памяти.
Автоскейлеры подов прекрасно справляются с задачей расширения ресурсов подов — прогнозируемым и сбалансированным образом. Я подробно писал о них в статье “Infinite scaling with containers and Kubernetes”, так что здесь приведу лишь краткие тезисы:
- HPA и KPA могут увеличить число реплик пода, тем самым добавив больше агрегированных ресурсов CPU и памяти для всей рабочей нагрузки без побочного эффекта «гиперактивного» потока, выводящего пробы контейнера за рамки их операционного диапазона;
- VPA может увеличить общие лимиты для CPU и памяти, обеспечив для пода сбалансированную корректировку его запросов и лимитов ресурсов.
[Но автоскейлеры подов принимают решения на основе сопоставления использования ресурсов и запрошенных значений, а не лимитов].
Это так. Правда, к делу не относится.
Суть здесь в том, чтобы отвергнуть подход усиленного использования CPU в качестве механизма для выполнения большего объёма работы в пользу применения компонентов, специально для этой цели созданных.
Вывод: автоскейлеры подов предназначены для максимизации сбалансированного использования ресурсов. Несмотря на то, что предоставление контейнеру возможности превышать свой резерв CPU может в некоторых сценариях сыграть наруку, автоскейлинг подов в большинстве случаев справляется лучше, повышая лимиты ресурсов рациональным образом.
▍ Причина #5: гиперскейлеры требуют установки для контейнеров лимитов
Обновлено 9/30: изначально этот раздел назывался «Автоскейлеры кластеров не любят резких движений» и ошибочно утверждал, что использование CPU (сверх запросов CPU контейнерами) может запускать события автоскейлинга. Читатель Шир Монетер в разделе комментариев (см. в оригинале статьи) правильно указал, что это не так. В связи с этим я переписал раздел, чтобы оставить только часть об управляемых контейнерных службах.
Это лишь косвенная причина, но я всё же решил её сюда включить.
Если ваши рабочие нагрузки вдруг превысят возможности одного кластера, и вы решите использовать для запуска контейнеров управляемую контейнерную службу, например, Code Engine или ECS, то эти службы требуют установки лимитов CPU и памяти.
Данное требование помогает провайдерам реализовывать выделение ресурсов и работает в вашу пользу, поскольку вы платите за выделение ресурсов, а безграничное использование означает безграничную стоимость.
▍ Заключение
Преимущества использования свободных ресурсов CPU в узле кластера уменьшаются прямо пропорционально той степени, в которой вы на эти свободные ресурсы опираетесь.
Создание контейнеров без лимитов CPU зачастую ведёт к незримыми зависимостям от свободных циклов CPU, которые в некоторых средах могут оказаться недоступны. В результате пробы контейнеров вытесняются из жизненно важных циклов CPU, (слегка) возрастает вероятность удаления подов в случае недостатка ресурсов, а также происходит неравномерное выделение (неограниченного) объёма CPU для (ограниченного) объёма памяти.
Если цель исключения лимитов CPU состоит в том, чтобы максимизировать выделение его мощностей, а также ресурсов узла и кластера, то специально предназначенные для этих целей компоненты, такие как автоскейлеры подов и кластеров, зачастую справятся лучше, попутно повысив выделение памяти в соответствии с возрастанием потребления CPU.
Разработка контейнеров для сбалансированного использования ресурсов, когда все лимиты ресурсов контейнеров во время разработки установлены близко (или равными) к запросам ресурсов, является успешным подходом, особенно в сочетании с эффективным проектированием проб (англ.).
Грамотно продуманные лимиты контейнеров и пробы позволяют kubelet понять, когда нужно перенаправить траффик на другие реплики пода в кластере, позволяя при этом именно автоскейлерам определять, когда и как корректировать совокупный объём рабочей нагрузки пода.

