Привет, Хабр! Сегодня мы хотим поговорить о том, что происходит сейчас с бизнесом наших клиентов и как мы стараемся помочь им. Дело в том, что нынешняя ситуация не может не отражаться на деятельности любой компании, все важнее становится гибкость и реакция на изменяющиеся факторы экономики. Руководителям необходимо понимать и прогнозировать финансовые результаты уже при новых вводных. Важно знать, как распределяются затраты и выручка в ходе деятельности компании, какая при этом маржинальность продукта, услуги, направления, процесса, сегмента и любых других разрезов.
Кроме этого, нужно уметь моделировать различные прогнозы: что будет, если перевести продажи в онлайн или сократить затраты на офис, помогут ли инвестиции в ИТ увеличить продажи, повысив эффективность работы персонала. К тому же есть отрасли, где доля прямых расходов в общем объеме затрат небольшая, поэтому общепринятые подходы к распределению косвенных затрат могут привести к принятию неверных управленческих решений.
Обычно, в результате внедрения продвинутых методов разнесения затрат удается выявить 30—40% в общем объеме расходов, которых можно избежать. Это позволяет получить дополнительную прибыль. При этом ИТ расходы на системы аллокации должны обеспечивать быстрый возврат инвестиций, а значит срок реализации проекта будет небольшой. Именно в анализе и реализации таких сложных моделей и помогает SAP Profitability and Performance Management (в прошлом SAP FS-PER), который уже достаточно давно перестал быть решением только для управления затратами. Теперь это широкий набор инструментов работы с данными и расширенного моделирования. Это подтверждается разнообразными сценариями, которые реализуют сейчас наши заказчики в разных отраслях: производство, медиа, ритейл, банки, добыча и др.
Давайте рассмотрим основные новинки функционала, появившиеся в последних обновлениях решения, и как можно использовать ML в SAP PAPM для создания прогнозов.
Новый интерфейс отчетности содержит возможность строить аналитику не только по количественным значениям и результатам расчета, но и описательную аналитику. Это полезно для многих сценариев использования продукта, где требуется обширная документация, например, финансовое моделирование, трансфертное ценообразование, устойчивость и налоговая отчетность.
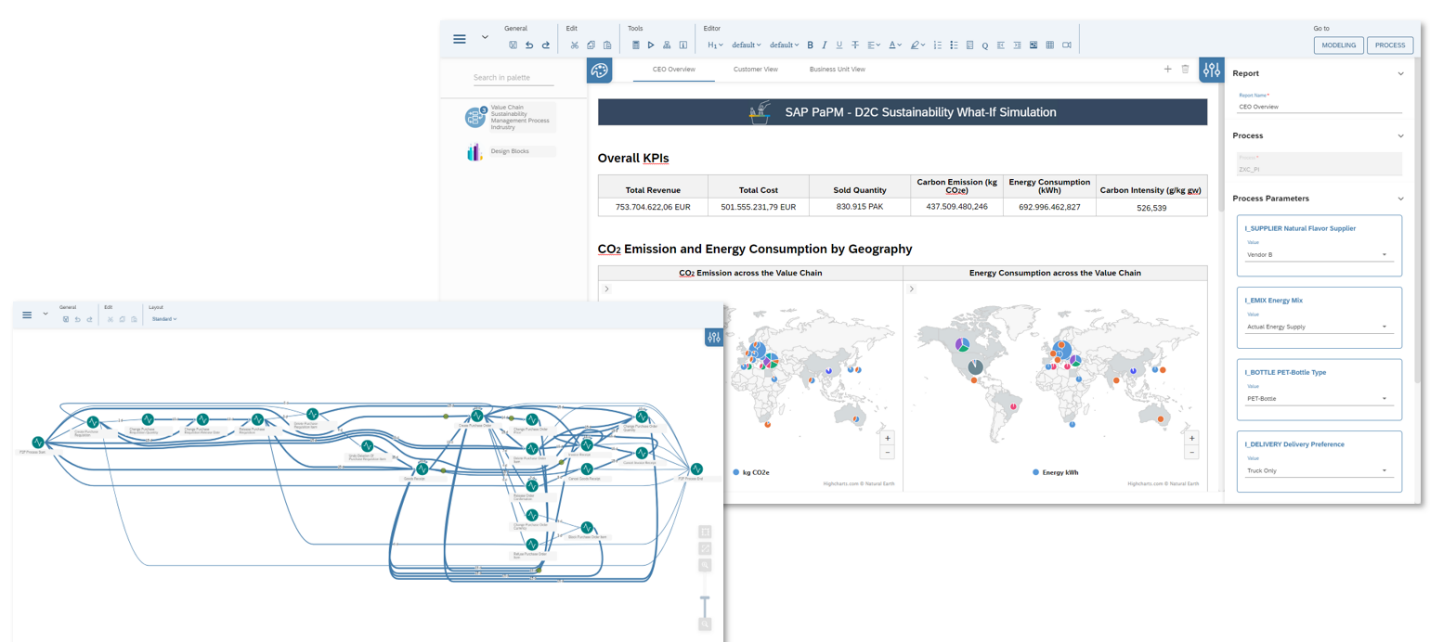
В этот интерфейс включен WYSIWYG (what-you-see-is-what-you-get) редактор документов, обеспечивающий редактирование текста, позволяющий включать таблицы, ссылки, изображения и видео, а также визуализировать входные данные и данные результатов.

Ранее уже было доступно моделирование результатов путем изменения входных параметров, например, смена цены входящего на переделе материала в производстве или тарифа обслуживания группы клиентов для B2C сегмента, увеличение/уменьшение затрат на ИТ или на топливо. В новом интерфейсе появилось моделирование параметров процесса расчета: период, процесс, место возникновения затрат, регион, тип транспортного средства, тип установки и т.д. После завершения расчета на сервере, результаты отразятся в отчете.
Все то же самое, что и в версии с сервером, только моделирование на стороне клиента может запускать скрипты на основе данных, выведенных на отчет.
Входные данные и результаты могут быть визуализированы с использованием различных типов диаграмм и графиков, например, столбчатые, временные ряды, тепловые карты, цепочки создания стоимости и другие. Эти визуализации встраиваются в отчет и являются интерактивными. Это означает, что они зависят от фильтров и конфигурации, которые позволяют выполнять детализацию данных.
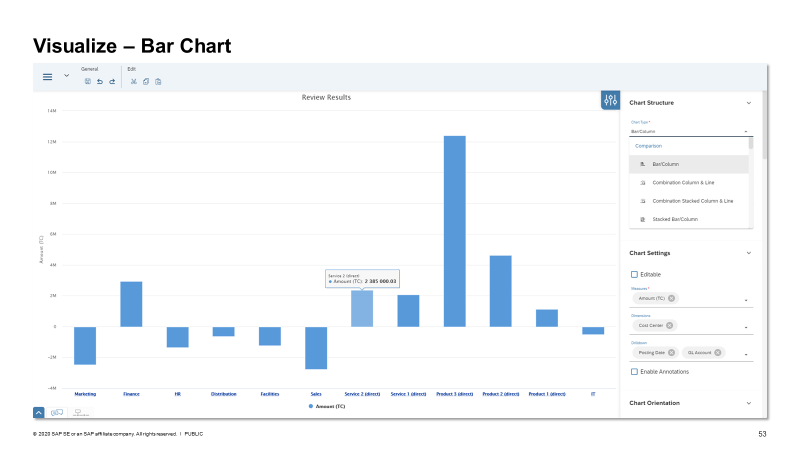
Новые типы моделей «Кластеризация» и «Классификация», в дополнение к уже существовавшим «Регрессия» и «Прогноз» (временный ряды), появились в функции машинного обучения с использованием автоматизированной прогнозной библиотеки HANA (APL).
Пререквизитом для использования является установленная SAP HANA Automated Predictive Library (APL) 1904 (minimum).
Рассмотрим пример использования правила «Прогноз».
Допустим, что у нас есть задача спрогнозировать исходные данные по затратам департаментов на следующий год на основе данных в разрезе даты, счета, МВЗ и т.д.

Период прогноза установлен равным 12. Это означает, что мы получим 12 спрогнозированных значений. Функция рассчитывает значения в столбце «Сумма прогноза» на основе алгоритма, примененного APL. Функция автоматизированной библиотеки запускает несколько моделей (например, линейная регрессия или экспоненциальное сглаживание) на исторических данных. Это нужно для определения лучшей модели, обученной на входном наборе данных. Далее строится прогноз. Предиктивные значения могут быть использованы позже в других функциях.
Таким образом, результат прогноза в нашем случае будет выглядеть следующим образом.

Машинное обучение также показывает входные данные, предназначенные для учетных счетов BEN и COM. Прогноз выявляет тенденцию к росту для счета BEN и положительную динамику для счета COM. Поскольку период был указан как 12 месяцев, машинное обучение прогнозировало сумму на следующие 12 месяцев для каждого из указанных типов счета.
Но часто бывает, что требуется более детальный прогноз или написание собственных функций. Для этого может использоваться создание кода на R script, для его вызова должен быть активирован SAP HANA R Server. Далее, через функцию вызова внешних процедур Remote Function Adapter, пользователь может выбрать тип SAP HANA R Script, позволяющий вызвать внешний R скрипт. При этом PaPM покажет сам код, написанный вовне, или предоставит интерфейс по его написанию и редактированию.
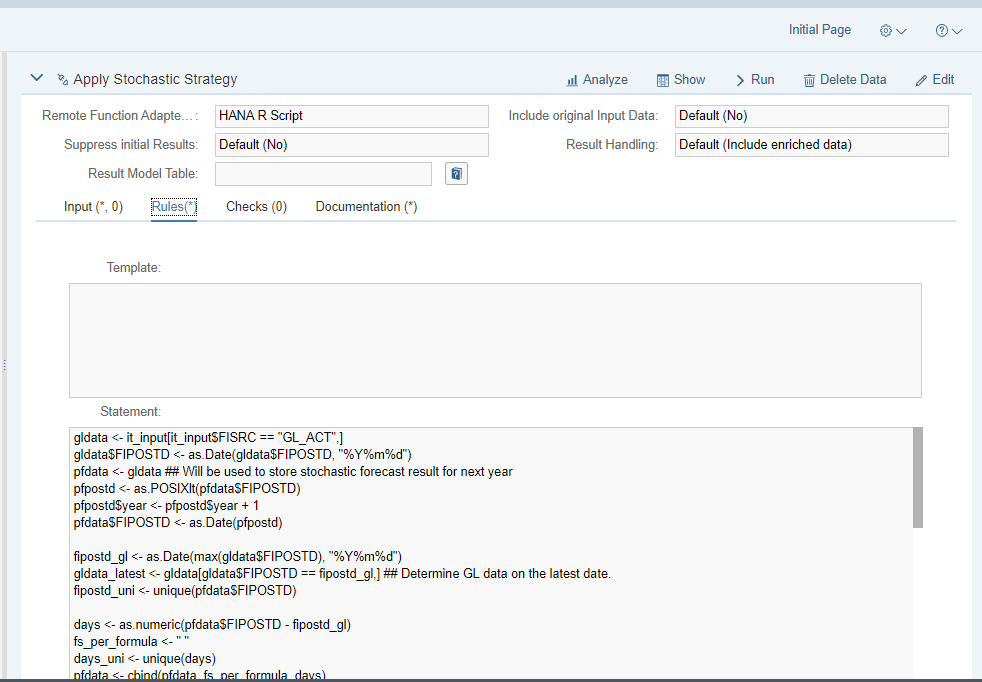
Такой подход может использоваться для сценариев, где требуются сложные прогнозные модели, например, в финансовом моделировании или для расчета рисков в банковской отрасли.
Решение должно уметь работать с большим объемом данных и при этом обеспечивать высокую производительность расчетов вне зависимости от сценария. Для обеспечения этого появляется все больше возможностей для параллелизации расчетов и scale -out функциональности. Это облегчает работу с наборами данных от 2 и более миллиардов записей и позволяет активно управлять загрузкой CPU и RAM.
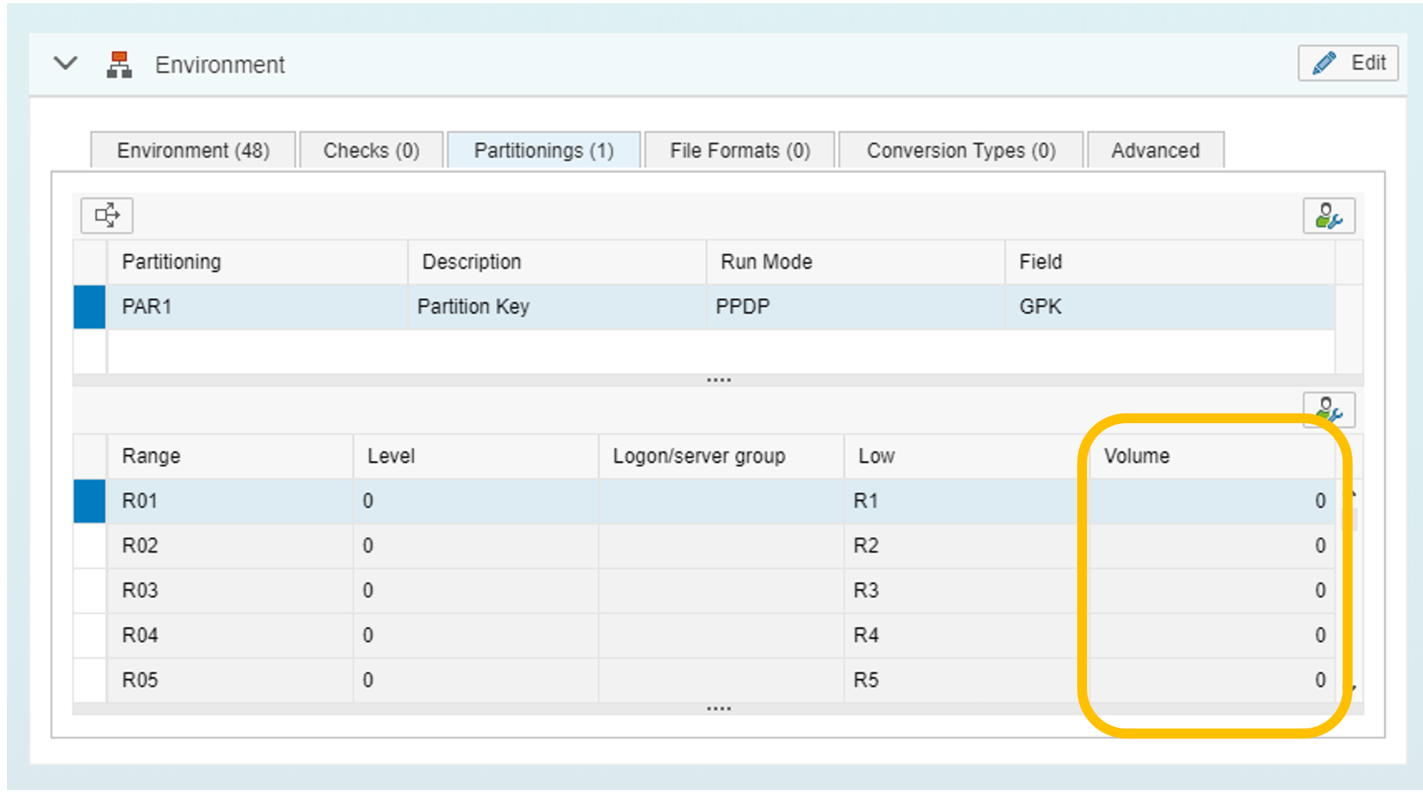
В приложении моделирования, выбрав среда -> партицирование (Partitioning), теперь для каждого диапазона партицирования, можно определять, где должен выполняться этот пакет работ. Это может быть полезно для достижения равномерного распределения нагрузки в системном ландшафте с горизонтальным масштабированием. В данном случае количество записей в пакетах работ очень неравномерное, а автоматическое распределение SAP HANA неоптимальное.
Более детально с параметрами настройки и последующего запуска можно ознакомиться тут.
В заключение хотелось бы напомнить, что SAP PaPM поставляется со стандартным контентом для упрощения начала работы с решением. Сейчас в нем уже более 40 моделей для разных индустрий и сценариев от распределения затрат до анализа устойчивости работы предприятия. Контент постоянно обогащается и пополняется, одна из новинок PCM to PaPM Activity based Costing. Она предоставляет редактор правил, схожий с тем, что был в SAP Profitability and Cost Management. А так как у решения закончился срок поддержки, новый контент существенно упростит импорт правил из SAP PCM, сократив сроки миграции.
Решение продолжает активно развиваться, предоставляя пользователям целую платформу для автоматизации различных сценариев через удобный интерфейс, не требующий программирования. В следующих статьях мы расскажем о других встроенных сценариях, которые наиболее востребованы среди наших мировых и российских заказчиков, например, «Управление устойчивостью» и «Аллокация ИТ затрат» по методологии Technology business management.
Автор – Ирина Шефтелевич, старший архитектор бизнес-решений SAP CIS
Кроме этого, нужно уметь моделировать различные прогнозы: что будет, если перевести продажи в онлайн или сократить затраты на офис, помогут ли инвестиции в ИТ увеличить продажи, повысив эффективность работы персонала. К тому же есть отрасли, где доля прямых расходов в общем объеме затрат небольшая, поэтому общепринятые подходы к распределению косвенных затрат могут привести к принятию неверных управленческих решений.
Обычно, в результате внедрения продвинутых методов разнесения затрат удается выявить 30—40% в общем объеме расходов, которых можно избежать. Это позволяет получить дополнительную прибыль. При этом ИТ расходы на системы аллокации должны обеспечивать быстрый возврат инвестиций, а значит срок реализации проекта будет небольшой. Именно в анализе и реализации таких сложных моделей и помогает SAP Profitability and Performance Management (в прошлом SAP FS-PER), который уже достаточно давно перестал быть решением только для управления затратами. Теперь это широкий набор инструментов работы с данными и расширенного моделирования. Это подтверждается разнообразными сценариями, которые реализуют сейчас наши заказчики в разных отраслях: производство, медиа, ритейл, банки, добыча и др.
Давайте рассмотрим основные новинки функционала, появившиеся в последних обновлениях решения, и как можно использовать ML в SAP PAPM для создания прогнозов.
1. Новый интерфейс моделирования и отчетности
Новый интерфейс отчетности содержит возможность строить аналитику не только по количественным значениям и результатам расчета, но и описательную аналитику. Это полезно для многих сценариев использования продукта, где требуется обширная документация, например, финансовое моделирование, трансфертное ценообразование, устойчивость и налоговая отчетность.

В этот интерфейс включен WYSIWYG (what-you-see-is-what-you-get) редактор документов, обеспечивающий редактирование текста, позволяющий включать таблицы, ссылки, изображения и видео, а также визуализировать входные данные и данные результатов.

Моделирование «что-если» (server-side)
Ранее уже было доступно моделирование результатов путем изменения входных параметров, например, смена цены входящего на переделе материала в производстве или тарифа обслуживания группы клиентов для B2C сегмента, увеличение/уменьшение затрат на ИТ или на топливо. В новом интерфейсе появилось моделирование параметров процесса расчета: период, процесс, место возникновения затрат, регион, тип транспортного средства, тип установки и т.д. После завершения расчета на сервере, результаты отразятся в отчете.
Моделирование на стороне клиента
Все то же самое, что и в версии с сервером, только моделирование на стороне клиента может запускать скрипты на основе данных, выведенных на отчет.
Визуализация исходных данных и результатов расчета
Входные данные и результаты могут быть визуализированы с использованием различных типов диаграмм и графиков, например, столбчатые, временные ряды, тепловые карты, цепочки создания стоимости и другие. Эти визуализации встраиваются в отчет и являются интерактивными. Это означает, что они зависят от фильтров и конфигурации, которые позволяют выполнять детализацию данных.
2. Машинное обучение
Новые типы моделей «Кластеризация» и «Классификация», в дополнение к уже существовавшим «Регрессия» и «Прогноз» (временный ряды), появились в функции машинного обучения с использованием автоматизированной прогнозной библиотеки HANA (APL).

Пререквизитом для использования является установленная SAP HANA Automated Predictive Library (APL) 1904 (minimum).
Рассмотрим пример использования правила «Прогноз».
Допустим, что у нас есть задача спрогнозировать исходные данные по затратам департаментов на следующий год на основе данных в разрезе даты, счета, МВЗ и т.д.

Период прогноза установлен равным 12. Это означает, что мы получим 12 спрогнозированных значений. Функция рассчитывает значения в столбце «Сумма прогноза» на основе алгоритма, примененного APL. Функция автоматизированной библиотеки запускает несколько моделей (например, линейная регрессия или экспоненциальное сглаживание) на исторических данных. Это нужно для определения лучшей модели, обученной на входном наборе данных. Далее строится прогноз. Предиктивные значения могут быть использованы позже в других функциях.
Таким образом, результат прогноза в нашем случае будет выглядеть следующим образом.

Машинное обучение также показывает входные данные, предназначенные для учетных счетов BEN и COM. Прогноз выявляет тенденцию к росту для счета BEN и положительную динамику для счета COM. Поскольку период был указан как 12 месяцев, машинное обучение прогнозировало сумму на следующие 12 месяцев для каждого из указанных типов счета.
Но часто бывает, что требуется более детальный прогноз или написание собственных функций. Для этого может использоваться создание кода на R script, для его вызова должен быть активирован SAP HANA R Server. Далее, через функцию вызова внешних процедур Remote Function Adapter, пользователь может выбрать тип SAP HANA R Script, позволяющий вызвать внешний R скрипт. При этом PaPM покажет сам код, написанный вовне, или предоставит интерфейс по его написанию и редактированию.

Такой подход может использоваться для сценариев, где требуются сложные прогнозные модели, например, в финансовом моделировании или для расчета рисков в банковской отрасли.
3. Параллелизация и scale-out
Решение должно уметь работать с большим объемом данных и при этом обеспечивать высокую производительность расчетов вне зависимости от сценария. Для обеспечения этого появляется все больше возможностей для параллелизации расчетов и scale -out функциональности. Это облегчает работу с наборами данных от 2 и более миллиардов записей и позволяет активно управлять загрузкой CPU и RAM.
В приложении моделирования, выбрав среда -> партицирование (Partitioning), теперь для каждого диапазона партицирования, можно определять, где должен выполняться этот пакет работ. Это может быть полезно для достижения равномерного распределения нагрузки в системном ландшафте с горизонтальным масштабированием. В данном случае количество записей в пакетах работ очень неравномерное, а автоматическое распределение SAP HANA неоптимальное.

Более детально с параметрами настройки и последующего запуска можно ознакомиться тут.
В заключение хотелось бы напомнить, что SAP PaPM поставляется со стандартным контентом для упрощения начала работы с решением. Сейчас в нем уже более 40 моделей для разных индустрий и сценариев от распределения затрат до анализа устойчивости работы предприятия. Контент постоянно обогащается и пополняется, одна из новинок PCM to PaPM Activity based Costing. Она предоставляет редактор правил, схожий с тем, что был в SAP Profitability and Cost Management. А так как у решения закончился срок поддержки, новый контент существенно упростит импорт правил из SAP PCM, сократив сроки миграции.
Решение продолжает активно развиваться, предоставляя пользователям целую платформу для автоматизации различных сценариев через удобный интерфейс, не требующий программирования. В следующих статьях мы расскажем о других встроенных сценариях, которые наиболее востребованы среди наших мировых и российских заказчиков, например, «Управление устойчивостью» и «Аллокация ИТ затрат» по методологии Technology business management.
Автор – Ирина Шефтелевич, старший архитектор бизнес-решений SAP CIS
