
Одна из самых популярных задач прогнозирования временных рядов — это прогнозы продаж для торговли. Чтобы построить базовую модель, можно подключить несколько библиотек и написать под них свою обертку, а можно работать с уже готовым фреймворком. Здесь я расскажу, как использовать одно из таких решений.
Здравствуй, Хабр! Меня зовут Когай Алексей, я работаю руководителем отдела машинного обучения в СберМегаМаркете. В зону нашей ответственности входит внедрение машинного обучения во все процессы компании.
Нам в СберМегаМаркете очень важно понимать спрос на товары как на этапе заведения карточек, чтобы оперативнее завести на платформу товары, на которые есть высокий спрос, так и на этапе активных продаж, чтобы мы и наши любимые продавцы могли удобно и гибко планировать поставки на склады. Также модель прогнозирования спроса помогает оценивать эффект от уже проведенных промоакций и планировать нагрузку и численность курьеров в случае доставки товаров курьерами.
Как-то раз половину нашего склада заселили роботы-пылесосы. Собирались ли они в ближайшее время разъезжаться по домам, — никто не знал. Точный и простой инструмент прогнозирования спроса тут очень бы пригодился. Понимание объемов будущих продаж важно и для наших нужд, и для многочисленных продавцов маркетплейса — склады гарантируют им только 60 дней бесплатного хранения товара.
Сразу после запуска площадки прогнозирование в СберМегаМаркете работало на оценках экспертов. Все планировалось исходя из «завтра будет то же, что и вчера». Это в то время, как для таких прогнозов создают сложные модели, которые требуют учета нескольких сотен факторов и огромных вычислительных ресурсов.
Мы решили, что для начала сделаем проще и быстрее. Зачастую, все эти сложные вычисления увеличивают качество моделей всего на пару процентов по сравнению с базовыми. Поэтому я стал искать готовый фреймфорк и нашел его на github — это библиотека sktime.
Здесь я хочу рассказать, как ее использовать: в русскоязычном интернете информации по sktime ничтожно мало. На Хабре есть статья, но это перевод, а не мануал на основе личного опыта.
Я разбирался с библиотекой несколько дней, а по инструкции ниже вы сможете сделать то же самое за 15 минут. Для работы со sktime нужны только базовые навыки программирования на Python.
Уверен, что использование sktime сэкономит время тем, кто, как и мы, ищет простой и надежный инструмент прогнозирования спроса и при этом не готов писать свою обертку поверх библиотек.
Добавлю, что я нашел несколько решений. Аналогичные фреймворки – Merlion или Etna от Tinkoff, – вероятно, делают все то же самое. Я остановился на sktime просто потому, что у нее было больше звездочек на github.
Для начала установим все необходимое:
import pandas as pd
import pyodbc
import numpy as np
import warnings
warnings.filterwarnings("ignore")
%matplotlib inlineЗагрузка данных
Чем больше у вас данных, тем лучше. Как минимум нужно, чтобы модель видела сезонность: если у вас недельная сезонность, нужны несколько недель, месячная сезонность — несколько месяцев. Считается, что для корректной работы подобных моделей требуется полтора года наблюдений, чтобы увидеть все сезоны не один раз.
def load(file, good="Продукты питания"):
data = pd.read_csv(file)
data.columns = ["ts", "good", "cnt"]
data = data.sort_values("ts")
data["ts"] = pd.to_datetime(data["ts"]).dt.to_period("d")
y = data.loc[data.good == good, ["ts", "cnt"]].set_index("ts").squeeze()
return y
my_df = load()Форматы данных
На вход sktime необходимо подать pandas датафрейм:
pd.Series для простых последовательностей;
pd.DataFrame для нескольких последовательностей.
При этом время должно быть в индексе Series.index и DataFrame.index.
Например:
data["ts"] = pd.to_datetime(data["ts"]).dt.to_period("d")
y = my_data.loc[my_data.good == good, ["ts", "cnt"]].set_index("ts").squeeze()Для простого прогноза необходимо только указать горизонт прогнозирования и передать его алгоритму прогнозирования.
Есть два основных способа задать горизонт прогноза:
использование numpy.array, состоящего из целых чисел. Например, «1» означает прогноз на следующий период, «2» второй следующий период и так далее;
использование объекта ForecastingHorizon. Его можно использовать для определения горизонтов прогноза, используя в качестве аргумента любой поддерживаемый тип индекса.
Горизонты прогнозирования могут быть абсолютными, то есть привязанными к конкретным временным точкам в будущем, или относительными — привязанными к разнице во времени в настоящем. По умолчанию настоящее — это последняя точка времени, видимая в любом «y», переданном модели прогноза.
Горизонты прогнозирования на основе numpy.array всегда относительны. В то время как объекты ForecastingHorizon могут быть как относительными, так и абсолютными. В частности, абсолютные горизонты прогнозирования могут быть заданы только с помощью ForecastingHorizon.
Первый способ с numpy.array
fh = np.arange(1, 7) # неделя
fh
Out:
array([1, 2, 3, 4, 5, 6])Второй способ на основе ForecastingHorizon
Объект ForecastingHorizon принимает абсолютные индексы в качестве входных данных, но считает входные данные абсолютными или относительными в зависимости от флага is_relative.
from sktime.forecasting.base import ForecastingHorizon
fh = ForecastingHorizon(
pd.PeriodIndex(pd.date_range("2021-10-01", periods=30, freq="D")), is_relative=False
)
fh
ForecastingHorizon(['2021-10-01', '2021-10-02', '2021-10-03', '2021-10-04',
'2021-10-05', '2021-10-06', '2021-10-07', '2021-10-08',
'2021-10-09', '2021-10-10', '2021-10-11', '2021-10-12',
'2021-10-13', '2021-10-14', '2021-10-15', '2021-10-16',
'2021-10-17', '2021-10-18', '2021-10-19', '2021-10-20',
'2021-10-21', '2021-10-22', '2021-10-23', '2021-10-24',
'2021-10-25', '2021-10-26', '2021-10-27', '2021-10-28',
'2021-10-29', '2021-10-30'],
dtype='period[D]', is_relative=False)Определение алгоритма прогнозирования
Для составления прогнозов необходимо указать алгоритм прогнозирования. Все модели sktime используют один и тот же интерфейс, поэтому шаги будут одинаковы независимо от выбранной модели.
Для первого примера берем наивный метод прогнозирования, предсказывающий последнее увиденное значение.
from sktime.forecasting.naive import NaiveForecaster
forecaster = NaiveForecaster(strategy="last")Теперь модель нужно обучить на наших данных:
forecaster.fit(y)Наконец, мы запрашиваем прогнозы для указанного горизонта прогнозирования. Это необходимо сделать после обучения модели:
y_pred = forecaster.predict(fh)
plot_series(y.tail(60), y_pred, labels=["y", "y_pred"])

Собираем все в одном месте с другой моделью
from sktime.forecasting.base import ForecastingHorizon
from sktime.forecasting.naive import NaiveForecastey = load_df()
fh = np.arange(1, 7) # горизонт прогноза
forecaster = NaiveForecaster(strategy="last", sp=7) # sp=7 отвечает за период сезонности
forecaster.fit(y) # обучение
y_pred = forecaster.predict(fh) #предсказание
plot_series(y.tail(30), y_pred, labels=["y", "y_pred"]) #отрисовка предсказаний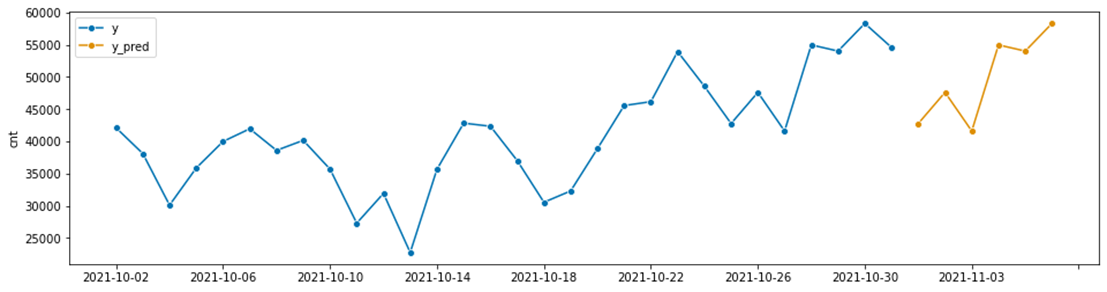
Оценка качества модели на тестовом множестве
Хорошей практикой является оценка качества модели перед внедрением. Процесс оценки для базовой задачи прогнозирования основан на сравнении факта с прогнозом на отложенной выборке.
Деление на train и test в sktime происходит функцией temporal_train_test_split
from sktime.forecasting.model_selection import temporal_train_test_split
y = load_df()
y_train, y_test = temporal_train_test_split(y, test_size=7)Чтобы сделать прогноз на тесте — надо передать их в fh
fh = ForecastingHorizon(y_test.index, is_relative=False)
forecaster = NaiveForecaster(strategy="last", sp=7)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)Выбираем и считаем ds метрику качества, чтобы оценить качество модели
Метрики могут быть вызваны двумя способами:
при помощи функции: например, mean_absolute_percentage_error, которая является функцией python (y_true : pd.Series, y_pred : pd.Series) -> float.
с использованием класса: например, MeanAbsolutePercentageError, который является классом python.
Для моих целей хватает функции, но для создания своей кастомной метрики проще использовать интерфейс класса.
from sktime.performance_metrics.forecasting import mean_absolute_percentage_error
mean_absolute_percentage_error(y_test, y_pred)
Out:
0.1891887216729895
from sktime.performance_metrics.forecasting import MeanAbsolutePercentageError
mape = MeanAbsolutePercentageError(symmetric=False)
mape(y_test, y_pred)
Out:
0.16798576229936724Оцениваем качество не на одном отрезке, а на кросс-валидации
Чтобы оценить эффективность модели, необходимо протестировать ее в условиях, имитирующих скользящее прогнозирование, то есть на прошлых данных. Для этого мы делаем прогнозы каждые N дней и сравниваем с фактическими значениями нужное нам число раз.
Кросс-валидация временных рядов вызывается функцией evaluate. Функция evalute принимает в качестве аргументов:
forecaster — модель, которая будет оцениваться;
тип кросс-валидации — ExpandingWindowSplitter — расширяющееся окно или SlidingWindowSplitter — скользящее окно;
strategy: должна ли модель переобучаться или нет.
from sktime.forecasting.arima import AutoARIMA
from sktime.forecasting.model_evaluation import evaluate
from sktime.forecasting.model_selection import ExpandingWindowSplitter
forecaster = AutoARIMA(sp=7, suppress_warnings=True)cv = ExpandingWindowSplitter(step_length=1, fh=[1, 2, 3, 4, 5, 6, 7], initial_window=31)
df = evaluate(forecaster=forecaster, y=y, cv=cv, strategy="refit", return_data=True)
df.iloc[:, :5].head()Как видим, на выходе получаем оценку качества для каждой точки прогноза и прочие данные, залогированные в процессе обучения.
Модели sktime
Основные модели, которые в настоящее время стабильно поддерживаются и достойны внимания:
autoETS (экспоненциальное сглаживание) – автоподбор параметров на основе пакета из R;
ThetaForecaster (Двойное экспоненциальное сглаживание) – с учетом тренда;
ExponentialSmoothing (Holt Winter's Exponential Smoothing из statsmodels) (Тройное экспоненциальное сглаживание) – учитывается тренд и сезонность;
autoARIMA из pmdarima.arima (подход тюнинга из R пакета);
BATS и TBATS из tbats;
PolynomialTrend (Полиномиальная регрессия);
Prophet (Facebook) <-- не удалось запустить из этого пакета
Метод экспоненциального сглаживания или метод Брауна используются в задачах сглаживания и краткосрочного прогнозирования временных рядов. С его помощью удобно определять параметры, основанные на предварительных предположениях, например, сезонности. Прогноз строится на основе экспоненциально взвешенного среднего значения прошлых наблюдений. Наибольший вес имеет текущее наблюдение, меньший — непосредственно предшествующее, еще меньший — предшествующее и так далее (экспоненциальный спад влияния прошлых данных).
Метод ThetaForecaster эквивалентен простому экспоненциальному сглаживанию со сдвигом. AutoETS — это модель ETS с возможностью автоматической и ручной подгонки.
from sktime.forecasting.exp_smoothing import ExponentialSmoothing
forecaster = ExponentialSmoothing(trend="add", seasonal="additive", sp=7)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_series(y_train.tail(60), y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
mean_absolute_percentage_error(y_pred, y_test)
Out:
0.053853603447200867
Экспоненциальное сглаживание:
from sktime.forecasting.ets import AutoETS
forecaster = AutoETS(auto=True, sp=7, n_jobs=-1)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_series(y_train.tail(60), y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
mean_absolute_percentage_error(y_pred, y_test)ARIMA и autoARIMA
Очень популярный статистический метод для прогнозирования временных рядов — ARIMA или модель Бокса-Дженкинса, показывает временной ряд на основе его предыдущих значений. Ее ошибки в прогнозе и их выравнивание можно использовать при прогнозировании будущих значений. С помощью ARIMA можно моделировать любые временные ряды, которые не являются сезонными, но демонстрируют закономерности, а не случайный белый шум.
from sktime.forecasting.arima import ARIMA
forecaster = ARIMA(
order=(1, 1, 0), seasonal_order=(0, 1, 0, 12), suppress_warnings=True
)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_series(y_train.tail(60), y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
mean_absolute_percentage_error(y_pred, y_test)
Out:
0.13533986188456024Auto ARIMA — это автоматически настроенный вариант ARIMA, который автоматически тюнит оптимальные параметры pdq:
from sktime.forecasting.arima import AutoARIMA
forecaster = AutoARIMA(sp=7, suppress_warnings=True)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_series(y_train.tail(60), y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
mean_absolute_percentage_error(y_pred, y_test)
Out:
0.17885134346968692Код вывода параметров:
forecaster.get_fitted_params()
Out:
{'ma.L1': -0.2038453053903969,
'ma.L2': -0.1441666812511294,
'ma.L3': -0.23627171390104673,
'ma.L4': -0.3026076973570091,
'ma.L5': 0.224013743590569,
'ar.S.L7': -0.018592736391196907,
'ar.S.L14': 0.935502948183107,
'ma.S.L7': 0.15199580326139103,
'ma.S.L14': -0.5445850041741789,
'sigma2': 4097899.2621635236,
'order': (0, 1, 5),
'seasonal_order': (2, 0, 2, 7),
'aic': 5359.428005725823,
'aicc': 5360.202653613147,
'bic': 5396.297759289221,
'hqic': 5374.1915764254845}BATS и TBATS
Модель TBATS
Trigonometric
Box-Cox transformation
ARMA
Trend
Seasonality
TBATS модели разработаны De Livera, Hyndman, Snyder (2011). Данный подход использует комбинацию из рядов Фурье, модель пространства состояний с экспоненциальным сглаживанием, а также преобразование Бокса-Кокса. Причем выбор параметров осуществляется полностью автоматизированным образом.
from sktime.forecasting.bats import BATS
forecaster = BATS(sp=7, use_trend=True, use_box_cox=False)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_series(y_train.tail(60), y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
mean_absolute_percentage_error(y_pred, y_test)
Out:
0.14246762153645254
from sktime.forecasting.tbats import TBATS
forecaster = TBATS(sp=7, use_trend=True, use_box_cox=False)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_series(y_train.tail(60), y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
mean_absolute_percentage_error(y_pred, y_test)
Out:
0.12760278368723751Запускаем расчет ряда моделей с кросс-валидацией по времени
from sktime.forecasting.arima import AutoARIMA
from sktime.forecasting.model_evaluation import evaluate
from sktime.forecasting.model_selection import ExpandingWindowSplitter
forecaster = AutoARIMA(sp=7, suppress_warnings=True)
cv = ExpandingWindowSplitter(step_length=1, fh=[1, 2, 3, 4, 5, 6, 7], initial_window=31)
df_arima = evaluate(
forecaster=forecaster, y=y, cv=cv, strategy="refit", return_data=True
)
forecaster = ExponentialSmoothing(trend="add", seasonal="additive", sp=7)
cv = ExpandingWindowSplitter(step_length=1, fh=[1, 2, 3, 4, 5, 6, 7], initial_window=31)
df_ExponentialSmoothing = evaluate(forecaster=forecaster, y=y, cv=cv, strategy="refit", return_data=True)
forecaster = UnobservedComponents(
level="local linear trend", freq_seasonal=[{"period": 7, "harmonics": 14}]
)
cv = ExpandingWindowSplitter(step_length=1, fh=[1, 2, 3, 4, 5, 6, 7], initial_window=31)
df_unobserved_components = evaluate(forecaster=forecaster, y=y, cv=cv, strategy="refit", return_d
forecaster = TBATS(sp=7, use_trend=True, use_box_cox=True)
cv = ExpandingWindowSplitter(step_length=1, fh=[1, 2, 3, 4, 5, 6, 7], initial_window=31)
df_TBATS = evaluate(forecaster=forecaster, y=y, cv=cv, strategy="refit", return_data=True)
forecaster = AutoETS(auto=True, sp=7, n_jobs=-1)
cv = ExpandingWindowSplitter(step_length=1, fh=[1, 2, 3, 4, 5, 6, 7], initial_window=31)
df_AutoETS = evaluate(forecaster=forecaster, y=y, cv=cv, strategy="refit", return_data=True)
from sklearn.neighbors import KNeighborsRegressor
from sktime.forecasting.compose import make_reduction
regressor = KNeighborsRegressor(n_neighbors=1)
forecaster = make_reduction(regressor, window_length=15, strategy="recursive")
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_series(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"])
mean_absolute_percentage_error(y_pred, y_test)
Out:
0.3029077745456426Можно вывести на экран параметры с помощью функции scikit-learn, совместимой с функцией get_params (и установленной с помощью set_params).
forecaster.get_params()
{'estimator__algorithm': 'auto',
'estimator__leaf_size': 30,
'estimator__metric': 'minkowski',
'estimator__metric_params': None,
'estimator__n_jobs': None,
'estimator__n_neighbors': 1,
'estimator__p': 2,
'estimator__weights': 'uniform',
'estimator': KNeighborsRegressor(n_neighbors=1),
'window_length': 15}Плюсы и минусы sktime
Основных преимуществ два — простота использования и, как следствие, экономия времени. Разработчики sktime объединили все в один флакон: то, что раньше требовало подключения 8-10 библиотек, можно сделать, установив только одну. Вместо десятка форматов достаточно разобраться только с одним.
С опорой на мануал установить все необходимое можно за 5 минут, плюс 10-15 минут на каждый фреймворк. В общем, это классное готовое решение на начальном этапе, которое дает возможность не кодить каждый элемент по отдельности.
Основной минус sktime — с ней нужно разбираться.
В будущем, на основе полученных значений от sktime, мы планируем строить более сложные модели: ее прогнозы будут использованы как признаки в большом и тяжелом решении.
