

Планирование процессов в операционных системах — это как умение акробата балансировать на тонкой нити. Этот незаметный сложный механизм определяет, как ваш компьютер управляет своими ресурсами. На первый взгляд все кажется просто: переключайте задачи на процессоре как можно быстрее, чтобы минимизировать время простоя и максимизировать общую производительность. Но в реальности это глубокий исследовательский вопрос, который требует учета множества факторов: приоритетов задач, доступности ресурсов и оптимизации. Давайте разбираться вместе!
Используйте навигацию, если не хотите читать текст полностью:
→ Потоки и процессы
→ Описание алгоритмов планирования
→ FIFO
→ RR
→ SJF
→ Метрики оценки производительности
→ Описание прикладной задачи
→ Реализация и симуляция алгоритмов
→ Результаты симуляций и их анализ
→ Заключение
Потоки и процессы
Главная задача операционной системы — отдавать программам необходимые ресурсы: дисковое пространство, оперативную память, ядра процессора, устройства ввода-вывода и т. д. Крутится все вокруг центрального процессора (он же ЦП, или CPU). В подробности мы уйдем чуть позже, а пока сведем все к простому тезису: если ЦП успевает оперативно переключаться между потоками, производительность компьютера в целом повышается. Современные операционные системы фактически планируют именно потоки уровня ядра, а не сами процессы.
Однако термины «планирование процессов» и «планирование потоков» часто используются как синонимы. Для простоты я буду использовать термин «планирование процессов» при упоминании общих концепций планирования, а «планирование потоков» — для обозначения идей, специфичных для потоков.

Описание алгоритмов планирования
Итак, ядро — базовая вычислительная единица ЦП, на которой выполняется процесс. То есть под «запуском на ЦП» обычно подразумевается выполнение процесса именно на ядре ЦП.
Источник.
В системе с одним ядром одновременно может выполняться только один процесс. Остальные в это время ждут, когда оно освободится. Если процессов в данный момент нет, ЦП простаивает.
Это противоречит идее мультипрограммирования, в котором мы стараемся использовать все время работы ЦП продуктивно. Идея проста: процесс выполняется по кругу до завершения запроса ввода-вывода. То есть, если есть несколько процессов, они встают в очередь и выполняются друг за другом. Если процесс один, он крутится до тех пор, пока не появится новый. Когда это происходит, операционная система дожидается завершения процесса, забирает у него ЦП и передает новому.
В многоядерной системе концепция загрузки ЦП распространяется на все процессорные ядра системы. Такое планирование — фундаментальная функция операционной системы, которой уделяется наибольшее внимание.
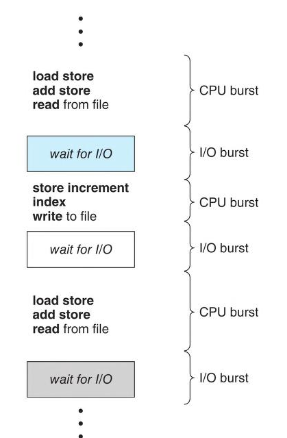
Выполнение процесса начинается с загрузки процессора. За этим следует цепочка пакетов ввода-вывода и, наконец, последний всплеск частоты ЦП заканчивается системным запросом на прекращение выполнения. Речь не о повышении тактовой частоты процессора, а о периодах его активности при выполнении процессов. Длительность этого всплеска заметно различается от процесса к процессу и от компьютера к компьютеру. Но, как правило, график изменения частоты ЦП имеет вид, как на рисунке ниже.
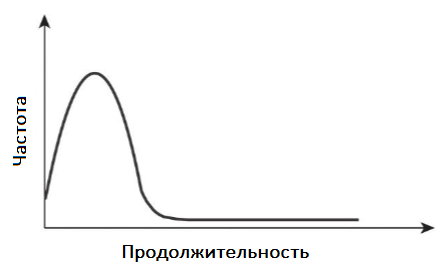
Кривая обычно характеризуется как экспоненциальная или гиперэкспоненциальная, с большим количеством коротких и небольшим — длинных всплесков частоты ЦП.
Важно, что графики будут разными для программ, связанных с вводом-выводом, и программ, привязанным к ЦП. Первые обычно имеют много коротких всплесков частоты процессора. Вторые — несколько длительных. Такое распределение может быть важным при реализации алгоритма планирования.
Каждый раз, когда ЦП простаивает, операционная система должна выбрать один из процессов в очереди готовности для выполнения. За это отвечает планировщик: он выбирает из памяти процесс, готовый к выполнению, и выделяет ему ЦП. Концептуально можно сказать, что все процессы выстраиваются в очередь, чтобы запуститься на процессоре. Записи в очередях обычно представляют собой блоки управления процессами — PCB, или process control block.
Решения по планированию ЦП могут приниматься при следующих обстоятельствах.
- Процесс переключается из состояния выполнения в состояние ожидания (например, в результате запроса ввода-вывода или вызова wait() для завершения дочернего процесса).
- Процесс переходит из состояния выполнения в состояние готовности (например, при возникновении прерывания).
- Процесс переходит из состояния ожидания в состояние готовности (например, при завершении ввода-вывода).
- Процесс завершается.
Для первой и последней ситуаций выбора планирования нет. Новый процесс, если он существует в очереди готовности, должен быть выбран для выполнения. В этих ситуациях говорим, что схема планирования является невытесняющей, или кооперативной. В противном случае это упреждающее действие. При невытесняющем планировании процесс сохраняет ЦП до тех пор, пока либо не завершится, либо не переключится в состояние ожидания. При упреждающем планировании ОС может временно приостановить выполнение текущего процесса, чтобы переключить ЦП на выполнение другого, более приоритетного.
Практически все современные операционные системы, включая Windows, macOS, Linux и UNIX, используют алгоритмы упреждающего планирования. К сожалению, оно может привести к состояниям гонки, когда данные распределяются между несколькими процессами.
Предлагаю рассмотреть случай двух процессов, которые совместно используют данные. Пока один обновляет их, он вытесняется, чтобы второй мог работать. Затем второй процесс пытается прочитать данные, которые находятся в противоречивом состоянии.
Вытеснение также влияет на структуру ядра операционной системы. Во время обработки системного вызова ядро может быть занято какой-либо деятельностью от имени процесса. Такие действия могут включать изменение важных данных ядра (например, очередей ввода-вывода).
Что произойдет, если процесс будет вытеснен в середине этих изменений и ядру (или драйверу устройства) потребуется прочитать или изменить ту же структуру? Наступит хаос. Ядра операционной системы могут быть спроектированы как с вытесняющим, так и с невытесняющим режимом. Невытесняющее ядро будет ждать завершения системного вызова или блокировки процесса, ожидая завершения ввода-вывода, прежде чем выполнять переключение контекста.
Эта схема гарантирует простоту структуры ядра, поскольку оно не будет вытеснять процесс, пока структуры его данных находятся в несогласованном состоянии. К сожалению, эта модель плохо подходит для поддержки вычислений в реальном времени. Большинство современных операционных систем теперь полностью вытесняют работу в режиме ядра.
Хотя большинство современных архитектур ЦП имеют несколько процессорных ядер, я рассказываю о планировании в контексте только одного. То есть ниже я опишу ситуации, когда нам доступен один процессор с одним ядром. Следовательно, воображаемая система способна одновременно запускать только один процесс.
FIFO
FIFO (First In, First Out), также известный как FCFS (First Come, First Serve), является простейшим алгоритмом составления расписания. Он просто ставит процессы в очередь выполнения в том порядке, в котором они поступают.
Принцип работы
Когда процесс попадает в очередь готовности, его блок управления процессом привязывается к хвосту. Когда процессор освобождается, он выделяется процессу, а после завершения удаляет его из очереди.
Стоит сказать, что код планирования FIFO прост в написании и понимании. Вместе с тем, среднее время ожидания в соответствии с политикой этого алгоритма часто бывает довольно продолжительным. Сейчас разберем это подробнее.
Рассмотрим следующий набор процессов, пребывающих в момент времени 0, с продолжительностью загрузки ЦП, заданной в миллисекундах:

Если процессы поступают в последовательности P1, P2, P3 и обслуживаются в порядке FIFO, получаем результат, показанный на диаграмме Ганта. Это гистограмма, которая иллюстрирует конкретный график, включая время начала и окончания каждого из участвующих процессов:

Источник.
Мы видим, что время ожидания составляет 0 мс для процесса P1, 24 миллисекунды для P2 и 27 мс для P3. Таким образом, среднее время ожидания составляет (0 + 24 + 27)/3 = 17 мс. Однако если процессы поступают в порядке P2, P3, P1, результаты будут другими:

Источник.
Среднее время ожидания теперь составляет (6 + 0 + 3)/3 = 3 мс. Это существенное сокращение. Пример наглядно показывает, что среднее время ожидания в соответствии с политикой FIFO обычно не минимально и может существенно меняться, если время загрузки процессов на ЦП сильно различается.
Теперь рассмотрим производительность планирования FIFO в динамической ситуации. Предположим, у нас есть процесс, привязанный к процессору (назовем его P1), и множество процессов, связанных с вводом-выводом. Поскольку они протекают вокруг системы, может возникнуть следующий сценарий.
P1 получит и удержит ЦП. За это время все остальные процессы завершат ввод-вывод и перейдут в очередь готовности. Пока они ждут, операции ввода-вывода устройства простаивают. В конце концов, P1 завершит нагрузку на ЦП и перейдет к устройству ввода-вывода.
Все процессы, связанные с вводом-выводом, которые имеют короткие нагрузки на ЦП, выполняются быстро и возвращаются в очереди ввода-вывода. В этот момент процессор простаивает. P1 затем вернется в очередь готовности, и ему будет выделен ЦП. Опять же, все процессы ввода-вывода в конечном итоге ждут в очереди готовности, пока не завершится P1. Возникает эффект конвоя, поскольку все остальные процессы ждут, пока один большой процесс выйдет из ЦП. Этот эффект приводит к более низкой загрузке ЦП и устройств, чем это было бы возможно, если бы более коротким процессам разрешалось запускаться первыми.
Алгоритм FIFO не является вытесняющим. Забрав ЦП, процесс сохраняет его либо до своего завершения, либо до появления запроса ввода-вывода. То есть FIFO особенно неприятен для интерактивных систем, где важно, чтобы каждый процесс получал долю ресурсов ЦП через определенные промежутки времени. Было бы катастрофой позволить одному процессу удерживать процессор в течение длительного периода времени.
Преимущества и недостатки
Преимущества FIFO
- Простота реализации и понимания.
- Минимальные накладные расходы на планирование, так как переключение контекста происходит только при завершении процесса.
- Отсутствие стагнации (starvation) процессов, так как каждый процесс гарантированно получит возможность выполнения.
- Справедливость по отношению ко всем процессам, независимо от их длительности или приоритета.
Недостатки FIFO
- Низкая пропускная способность системы, особенно если длительные процессы блокируют короткие (эффект конвоя).
- Высокое среднее время ожидания и время отклика, особенно для коротких процессов, если они находятся в конце очереди.
- Отсутствие приоритизации процессов, что может привести к проблемам с выполнением срочных задач.
- Неэффективное использование ресурсов процессора, особенно в системах с процессами различной длительности.
- Сложности с соблюдением дедлайнов процессов из-за отсутствия механизма приоритетов.
RR
RR (Round Robin Scheduling) — это алгоритм циклического планирования с вытеснением, при котором процессор выдает процессы по очереди на фиксированный квант времени. Если процесс не успевает завершиться за отведенное ему время, он прерывается и помещается в конец очереди готовности.
Принцип работы
Начинается все, как в FIFO: процессы встают в очередь в том порядке, в котором приходят. Затем определяется небольшая единица времени, называемая квантом или интервалом. Обычно до 100 мс. Планировщик ЦП обходит очередь готовности и выделяет каждому процессу ЦП на интервал до одного кванта времени.
Планировщик ЦП выбирает первый процесс из очереди готовности, устанавливает таймер на прерывание через один квант времени и направляет процесс. Затем происходит одно из двух.
- Если процесс успевает выполниться за один квант времени, он добровольно освобождает процессор. Затем планировщик переходит к следующему процессу в очереди готовности.
- Если не успевает, срабатывает таймер, который вызывает прерывание для операционной системы. Оно не является критическим или аварийным, а лишь сигнализирует операционной системе, что нужно переключить процесс, чтобы поддерживать работу алгоритма. Соответственно, будет выполнено переключение контекста, а процесс будет помещен в конец очереди готовности.
В любом сценарии планировщик ЦП выберет следующий процесс в очереди готовности. Среднее время ожидания в соответствии с политикой RR часто бывает большим. Рассмотрим следующий набор процессов, которые прибывают в момент времени 0, с продолжительностью загрузки ЦП, заданной в миллисекундах:
Мы используем временной квант в 4 мс, и процесс P1 получит его полностью. Однако по условию для выполнения ему нужно еще 20 мс. Следовательно, он вытесняется по истечении первого кванта времени, а ЦП передается следующему процессу в очереди, P2. Ему нужно всего 3 мс, поэтому он завершается до истечения своего кванта времени. Затем процессор передается следующему процессу, P3. С ним повторяется предыдущий сценарий. Затем ЦП возвращается процессу P1, который будет удерживать его циклами по 4 мс, пока не завершится. В результате график RR выглядит следующим образом:

Источник.
Давайте посчитаем среднее время ожидания для этого расписания. P1 ждет 6 мс (суммарное время выполнения процессов P2 и P3). P2 ждет 4 мс, пока выполняется P1. P3 ждет 7 мс, пока выполняются P1 и P2. Таким образом, среднее время ожидания составляет 17/3 = 5,66 мс. В алгоритме планирования RR ЦП не выделяется ни одному процессу более чем на один квант времени подряд (если только это не единственный работающий процесс).
Если загрузка ЦП процесса превышает один квант времени, этот процесс вытесняется и помещается обратно в очередь готовности. Таким образом, алгоритм планирования RR является упреждающим. Если в очереди готовности находится n процессов и квант времени равен q, то каждый процесс получает 1/n процессорного времени порциями максимум по q единиц времени.
Каждый процесс должен ждать не более (n — 1) * q единиц времени до своего следующего кванта. Например, есть пять процессов и временной квант 20 мс. Значит, каждый процесс будет получать ЦП в свое распоряжение через каждые 100 мс.
Производительность алгоритма RR сильно зависит от размера временного кванта. С одной стороны, если он чрезвычайно велик, политика RR будет схожа с политикой FIFO. С другой, если он чрезвычайно мал (скажем, одна миллисекунда), подход RR может привести к большому количеству переключений контекста.
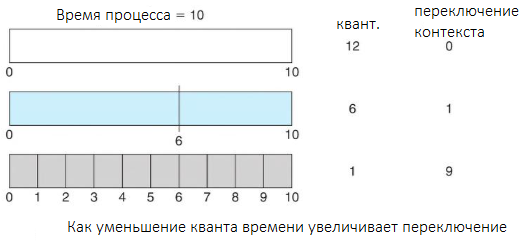
Источник.
Предположим, у нас есть только один процесс продолжительностью 10 мс и квант времени, равный 12 мс. В этом случае процесс завершится менее чем за один квант без каких-либо дополнительных затрат. Однако если квант равен шести миллисекундам, то процессу потребуется два кванта, что приведет к переключению контекста. Если квант времени равен одной миллисекунде, произойдет девять переключений контекста, что замедлит выполнение процесса (рис. выше).
Таким образом, мы хотим, чтобы квант времени был большим по сравнению со временем переключения контекста. Если последнее составляет примерно 10% кванта времени, то на переключение контекста будет потрачено около 10% времени процессора. На практике большинство современных ОС имеют кванты от 10 до 100 миллисекунд. Время, необходимое для переключения контекста, обычно составляет менее 10 микросекунд (0,01 мс). Таким образом, время переключения контекста составляет небольшую часть кванта времени.
Выбор кванта времени
Время выполнения также зависит от размера кванта времени.
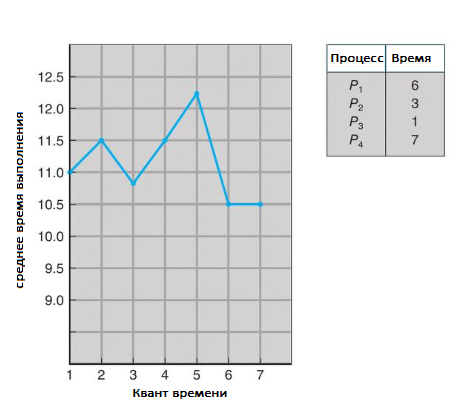
Источник.
Как мы можем видеть на рисунке выше, среднее время выполнения набора процессов не обязательно улучшается по мере увеличения размера кванта времени. В общем, среднее время обработки можно улучшить, если большинство процессов завершат следующий цикл загрузки ЦП за один квант времени. Например, для трех процессов по 10 мс каждый и при кванте времени в 1 мс среднее время выполнения равно 29 мс. Однако если квант времени равен 10, то среднее время выполнения падает до 20. Если добавить время переключения контекста, в среднем время выполнения увеличивается еще больше. И это при меньшем временном интервале, поскольку нужно больше переключений контекста.
Временной интервал должен быть большим по сравнению со временем переключения контекста, но в то же время не превышать его слишком сильно. Как указано выше, если квант времени слишком велик, планирование RR перерождается в политику FIFO. Эмпирическое правило заключается в том, что 80% пакетов процессорного времени должны быть короче кванта времени.
Преимущества и недостатки
Преимущества RR
- Справедливое распределение процессорного времени.
- Отсутствие блокировки системы одним процессом.
- Низкое время отклика для интерактивных процессов.
Недостатки
- Необходимость выбора оптимального кванта времени.
- Накладные расходы на переключение контекста.
- Неэффективность для процессов с очень короткими или очень длинными временами выполнения.
SJF
SJF (Shortest Job First) — это алгоритм, который выбирает в первую очередь процесс с минимальным ожидаемым временем выполнения. Он может работать как с вытеснением (тогда это будет SRTF — Shortest Remaining Time First), так и без него.
Принцип работы
Алгоритм сортирует процессы в очереди по ожидаемому времени выполнения от меньшего к большему. После назначает ЦП сначала процессам с коротким временем выполнения, а затем все более и более длинным.
Если следующие пакеты ЦП двух процессов одинаковы, для разрыва связи используется планирование FIFO. Обратите внимание, что более подходящим термином для этого метода планирования был бы алгоритм «самый короткий следующий пакет ЦП».Это потому, что планирование зависит от длины следующего пакета ЦП процесса, а не от его общей длины.
Я использую термин термин SJF, потому что большинство людей применяют его, и он часто встречается в учебниках для обозначения этого типа планирования. В качестве примера планирования SJF рассмотрим следующий набор процессов с продолжительностью загрузки ЦП, заданной в миллисекундах:

Используя планирование SJF, запланировали бы эти процессы в соответствии со следующей диаграммой Ганта:

Время ожидания — 3 миллисекунды для процесса P1,16 — для P2, 9 — для P3 и 0 — для P4. Таким образом, среднее время ожидания будет (3 + 16 + 9 + 0)/4 = 7 миллисекунд. Для сравнения: если бы использовали схему планирования FIFO, среднее время ожидания составило бы 10,25 миллисекунды.
SJF является доказуемо оптимальным, поскольку обеспечивает минимальное среднее время ожидания для данного набора процессов. Постановка короткого процесса перед длинным уменьшает среднее время ожидания.
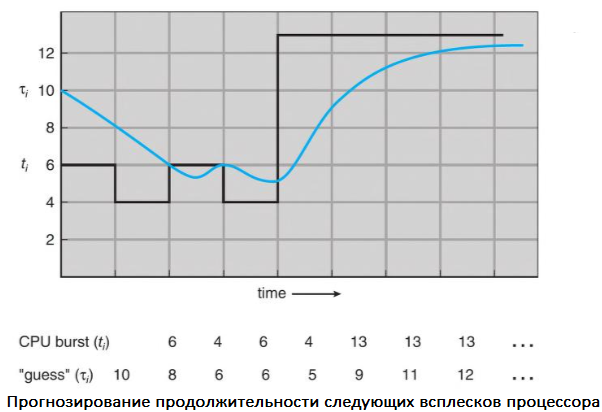
Несмотря на это, SJF нельзя реализовать на уровне планирования ЦП, поскольку нет способа узнать длину следующего пакета. Один из подходов к этой проблеме — попытаться аппроксимировать планирование SJF. Мы можем не знать продолжительность следующего пакета процессора, но можем предсказать его значение. Ожидаемо, что следующий пакет будет аналогичен по длине предыдущим. Вычислив приблизительную длину следующего пакета ЦП, можем выбрать процесс с самым коротким прогнозируемым пакетом ЦП.
Следующий пакет ЦП обычно прогнозируется как экспоненциальное среднее измеренных длин предыдущих пакетов. Можем определить это значение с помощью следующей формулы:
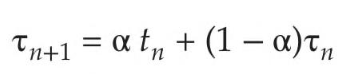
Здесь tn — длина n-го пакета ЦП, а 𝛕n + 1 — наше прогнозируемое значение для следующего пакета ЦП. Переменная α находится в диапазоне от 0 до 1.
Значение tn содержит нашу самую свежую информацию, а 𝛕n хранит прошлую историю. Параметр α контролирует относительный вес недавней и прошлой истории в нашем прогнозе. Если α = 0, то 𝛕n+1 = 𝛕n и недавняя история не оказывает влияния (текущие условия считаются переходными).
Если α = 1, то 𝛕n+1 = tn и имеет значение только самый последний пакет процессора (предполагается, что история устарела и не имеет значения). Чаще всего α = 1/2, поэтому недавняя и прошлая история имеют одинаковый вес. Начальное значение 𝛕0 может быть определено как константа или среднее значение всей системы. На рисунке показано экспоненциальное среднее при α = 1/2 и 𝛕0 = 10.
Источник.
Чтобы понять поведение экспоненциального среднего, мы можем расширить формулу для 𝛕n + 1, заменив 𝛕n и найдя:
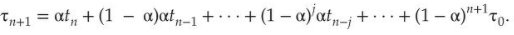
Обычно α < 1. В результате (1 — α) также меньше 1, и каждый последующий термин имеет меньший вес, чем его предшественник.
Алгоритм SJF может быть вытесняющим и невытесняющим. Выбор возникает, когда новый процесс поступает в очередь готовности, в то время как предыдущий все еще выполняется. Следующий пакет ЦП вновь прибывшего процесса может быть короче, чем то, что осталось от текущего. SJF с вытеснением, соответственно, вытесняет выполняющийся в данный момент процесс, тогда как SJF без вытеснения позволяет ему завершить пакетную нагрузку ЦП. Вытесняющее планирование SJF иногда называют планированием с наименьшим оставшимся временем. В качестве примера рассмотрим следующие четыре процесса с продолжительностью загрузки ЦП, заданной в миллисекундах:

Вот как в таких условиях будет выглядеть результирующий график упреждающего SJF:

Источник.
P1 запускается в момент времени 0, поскольку это единственный процесс в очереди. P2 прибывает в момент 1. Оставшееся время для процесса P1 (7 миллисекунд) больше, чем время, необходимое для P2 (4 миллисекунды), поэтому P1 вытесняется, а P2 планируется. Среднее время ожидания для этого примера составляет [(10 – 1) + (1 – 1) + (17 – 2) + (5 – 3)]/4 = 26/4 = 6,5 миллисекунд. Невытесняющее планирование SJF приведет к тому, что среднее время ожидания составит 7,75 миллисекунды.
Преимущества и недостатки
Преимущества SJF
- Минимизация среднего времени ожидания процессов.
- Эффективное использование процессора.
Недостатки
- Необходимость знать или прогнозировать время выполнения процессов.
- Возможность голодания длинных процессов.
- Сложность реализации алгоритма прогнозирования времен выполнения.
Метрики оценки производительности
Среднее время ожидания
Среднее время ожидания (Average Waiting Time, AWT) определяется как среднее время, которое процессы проводят в очереди готовности перед их выполнением на процессоре. Оно рассчитывается как сумма всех времен ожидания процессов, поделенная на количество процессов:
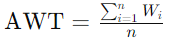
Здесь Wi — время ожидания i-го процесса, n — общее количество процессов.
Среднее время выполнения
Среднее время выполнения (Average Turnaround Time, ATT) определяется как время от момента поступления процесса в систему до его завершения. Оно включает время ожидания и время выполнения на процессоре:
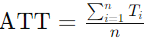
Здесь Ti — время выполнения i-го процесса, n — общее количество процессов.
Среднее время отклика
Среднее время отклика (Average Response Time, ART) — это время от поступления запроса до начала его обработки процессором. Время отклика не включает время, необходимое для выполнения процесса, только время ожидания до первого выполнения:
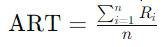
Здесь Ri — время отклика i-го процесса, n — общее количество процессов.
Описание прикладной задачи
Определение наборов процессов для тестирования
Для тестирования производительности алгоритмов планирования я выбрал несколько наборов процессов, которые характеризуются различным временем выполнения и поступления.
- Набор 1. Процессы с равномерным распределением времени выполнения.
- Набор 2. Процессы с переменным временем выполнения, имитирующие рабочую нагрузку на сервере.
- Набор 3. Процессы с коротким временем выполнения, чередующиеся с длительными процессами, чтобы проверить алгоритмы на предмет устойчивости к эффекту конвоя.
Каждый набор был разработан таким образом, чтобы обеспечить разнообразие сценариев для тщательного тестирования алгоритмов FIFO, Round Robin и SJF.
Реализация и симуляция алгоритмов
Краткое описание реализации алгоритмов
Подходы, которые я использовал для реализации алгоритмов планирования процессов:
- FIFO (First-In First-Out) — процессы обрабатываются в порядке их поступления;
- Round Robin — процессы получают процессорное время по очереди с фиксированным квантом времени;
- SJF (Shortest Job First) — процессы обрабатываются в порядке возрастания их ожидаемого времени выполнения.
Проведение симуляции для каждого алгоритма
Для проведения симуляций написан скрипт на Python, который моделирует выполнение процессов в операционной системе Linux:
# Определение процессов для симуляции
processes = [
{'id': 1, 'burst_time': 10},
{'id': 2, 'burst_time': 5},
{'id': 3, 'burst_time': 8}
]
time_quantum = 4
Симуляция FIFO:
# FIFO Scheduling
def fifo_scheduling(processes):
waiting_time = 0
total_waiting_time = 0
total_turnaround_time = 0
response_time = 0
total_response_time = 0
for i, process in enumerate(processes):
if i == 0:
response_time = 0
else:
response_time = waiting_time
total_response_time += response_time
total_waiting_time += waiting_time
waiting_time += process['burst_time']
total_turnaround_time += waiting_time
avg_waiting_time = total_waiting_time / len(processes)
avg_turnaround_time = total_turnaround_time / len(processes)
avg_response_time = total_response_time / len(processes)
return avg_waiting_time, avg_turnaround_time, avg_response_time
Симуляция Round Robin:
# Round Robin Scheduling
def round_robin_scheduling(processes, time_quantum):
from collections import deque
q = deque(processes)
current_time = 0
waiting_time = {process['id']: 0 for process in processes}
remaining_time = {process['id']: process['burst_time'] for process in processes}
response_time = {process['id']: -1 for process in processes}
completed_processes = 0
total_waiting_time = 0
total_turnaround_time = 0
total_response_time = 0
while completed_processes < len(processes):
process = q.popleft()
if response_time[process['id']] == -1:
response_time[process['id']] = current_time
if remaining_time[process['id']] > time_quantum:
current_time += time_quantum
remaining_time[process['id']] -= time_quantum
q.append(process)
else:
current_time += remaining_time[process['id']]
waiting_time[process['id']] = current_time - process['burst_time']
total_turnaround_time += current_time
total_waiting_time += waiting_time[process['id']]
total_response_time += response_time[process['id']]
remaining_time[process['id']] = 0
completed_processes += 1
avg_waiting_time = total_waiting_time / len(processes)
avg_turnaround_time = total_turnaround_time / len(processes)
avg_response_time = total_response_time / len(processes)
return avg_waiting_time, avg_turnaround_time, avg_response_time
Симуляция SJF:
# SJF Scheduling
def sjf_scheduling(processes):
sorted_processes = sorted(processes, key=lambda x: x['burst_time'])
waiting_time = 0
total_waiting_time = 0
total_turnaround_time = 0
response_time = 0
total_response_time = 0
for i, process in enumerate(sorted_processes):
if i == 0:
response_time = 0
else:
response_time = waiting_time
total_response_time += response_time
total_waiting_time += waiting_time
waiting_time += process['burst_time']
total_turnaround_time += waiting_time
avg_waiting_time = total_waiting_time / len(processes)
avg_turnaround_time = total_turnaround_time / len(processes)
avg_response_time = total_response_time / len(processes)
return avg_waiting_time, avg_turnaround_time, avg_response_time
Выполнение симуляций:
# Выполнение симуляций
fifo_results = fifo_scheduling(processes)
rr_results = round_robin_scheduling(processes, time_quantum)
sjf_results = sjf_scheduling(processes)
print("FIFO Results: ", fifo_results)
print("Round Robin Results: ", rr_results)
print("SJF Results: ", sjf_results)
Результаты симуляций и их анализ
| Алгоритм |
Среднее время ожидания |
Среднее время выполнения |
Среднее время отклика |
| FIFO |
8.333333333333334 |
16.0 |
8.333333333333334 |
| Round Robin |
12.666666666666667 |
20.333333333333332 |
4.0 |
| SJF (Shortest Job First) |
6.0 |
13.666666666666667 |
6.0 |
Выводы
Для систем с равномерной нагрузкой лучше использовать алгоритм FIFO, так как он проще в реализации и предполагает минимальные управленческие расходы. Это затраты системы на выполнение задач, связанных с управлением процессами. В контексте планирования процессов в операционных системах, такие расходы включают время процессора, память, код и данные ОС.
Для интерактивных систем и систем реального времени, где важна справедливость и быстрота отклика, лучше всего подходит алгоритм Round Robin. Он гарантирует равномерное распределение процессорного времени и быструю реакцию системы на запросы пользователей.
Для вычислительных задач, требующих минимизации общего времени выполнения, наиболее эффективным является алгоритм SJF. Однако следует учитывать риск голодания для длительных процессов, поэтому можно рассмотреть использование модифицированных версий алгоритма.
Заключение
Анализ и симуляции показали, что у каждого алгоритма планирования есть сильные и слабые стороны. FIFO подходит для простых систем с однородной нагрузкой. Round Robin справедливо распределяет процессорное время, но требует точной настройки. SJF обеспечивает наименьшее среднее время ожидания и выполнения, однако может вызвать голодание долгих процессов и требует точной оценки времени выполнения.
Выбор подходящего алгоритма зависит от специфики задач и требований системы и оптимальный выбор может варьироваться в зависимости от контекста использования.
