
Есть ли способ оптимизировать рабочий процесс проекта Data Science всего в несколько строк кода? Да. Это Prefect. Делимся кратким руководством по работе с этим инструментом, пока у нас начинается флагманский курс Data Science.
Зачем это нужно?
Почему вас как специалиста по анализу данных должна волновать оптимизация рабочего процесса? Начнём с примера базового проекта в области науки о данных. Представьте, что вы работаете с набором данных Iris и начали с функций обработки данных.
from typing import Any, Dict, List
import pandas as pd
def load_data(path: str) -> pd.DataFrame:
...
def get_classes(data: pd.DataFrame, target_col: str) -> List[str]:
"""Task for getting the classes from the Iris data set."""
...
def encode_categorical_columns(data: pd.DataFrame, target_col: str) -> pd.DataFrame:
"""Task for encoding the categorical columns in the Iris data set."""
...
def split_data(data: pd.DataFrame, test_data_ratio: float, classes: list) -> Dict[str, Any]:
"""Task for splitting the classical Iris data set into training and test
sets, each split into features and labels.
"""
...Определив функции, вы выполняете их.
# Define parameters
target_col = 'species'
test_data_ratio = 0.2
# Run functions
data = load_data(path="data/raw/iris.csv")
categorical_columns = encode_categorical_columns(data=data, target_col=target_col)
classes = get_classes(data=data, target_col=target_col)
train_test_dict = split_data(data=categorical_columns,
test_data_ratio=test_data_ratio,
classes=classes)Код отработал нормально, и вы не увидели ничего плохого в выводе, поэтому считаете, что рабочий процесс достаточно хорош. Однако линейный рабочий процесс, как ниже, может иметь множество недостатков.

Вот эти недостатки:
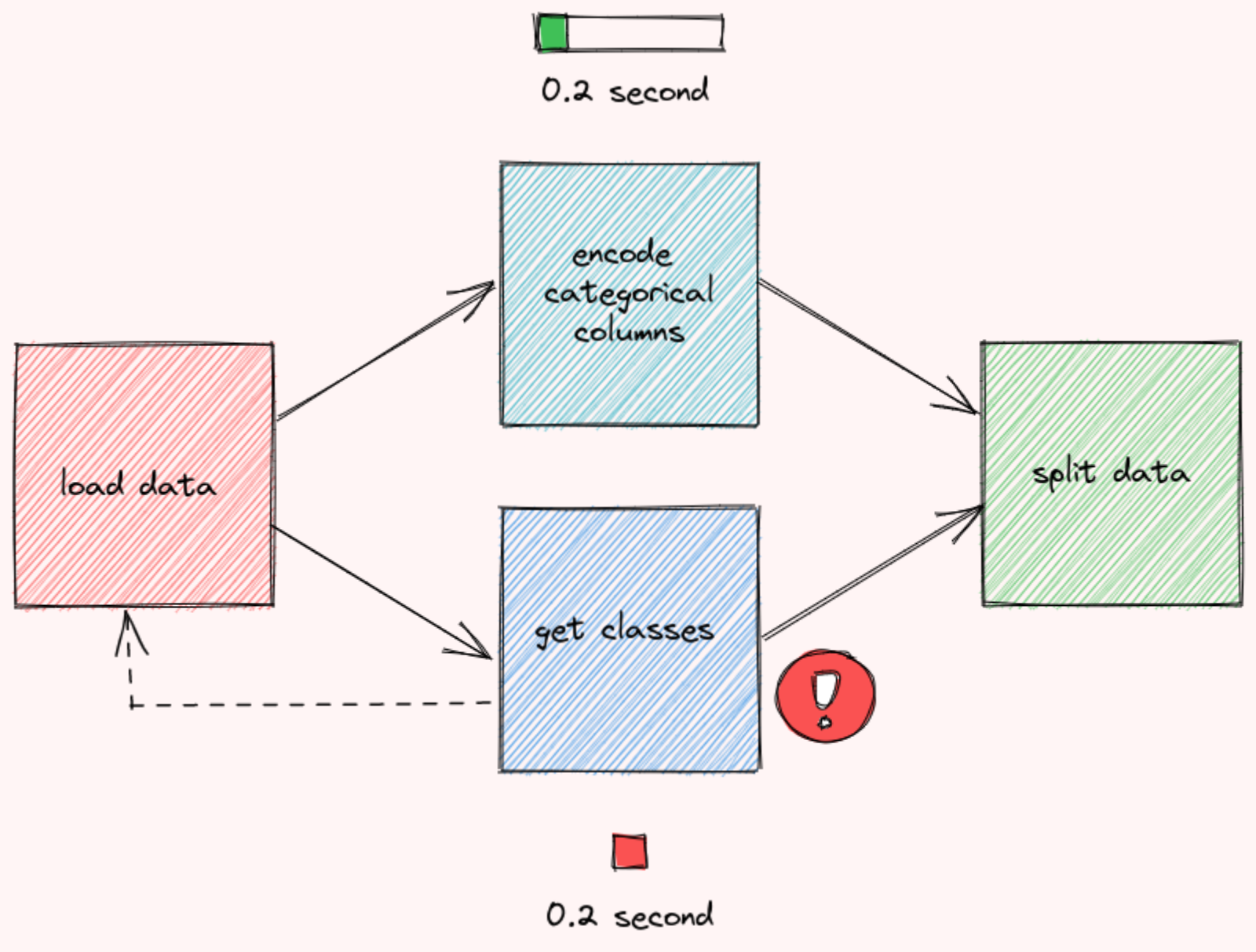
Если в функции get_classes произошла ошибка, вывод encode_categorical_columns будет потерян и рабочий процесс придётся начинать с начала. Это может быть неприятно, если выполнение функции encode_categorical_columns занимает много времени.

Поскольку функции encode_categorical_columns и get_classes не зависят друг от друга, их можно выполнять одновременно:

Запуск функций таким образом может предотвратить трату времени на неработающие функции. Если в get_classes произошла ошибка, рабочий процесс перезапустится сразу, не дожидаясь завершения encode_categorical_columns.
Что такое Prefect?
Prefect — это фреймворк с открытым исходным кодом для построения рабочих процессов на Python. Он позволяет легко создавать, запускать и контролировать конвейеры данных различного масштаба. Чтобы установить его, выполните эту команду:
pip install prefectСтроим рабочий процесс с Prefect
Чтобы узнать, как работает Prefect, давайте инкапсулируем рабочий процесс в начале статьи с его помощью.
1. Создаём задачи
Задача — это отдельное действие в Prefect. Начните с превращения определённых выше функций в задачи с помощью декоратора prefect.task:
from prefect import task
from typing import Any, Dict, List
import pandas as pd
@task
def load_data(path: str) -> pd.DataFrame:
...
@task
def get_classes(data: pd.DataFrame, target_col: str) -> List[str]:
"""Task for getting the classes from the Iris data set."""
...
@task
def encode_categorical_columns(data: pd.DataFrame, target_col: str) -> pd.DataFrame:
"""Task for encoding the categorical columns in the Iris data set."""
...
@task
def split_data(data: pd.DataFrame, test_data_ratio: float, classes: list) -> Dict[str, Any]:
"""Task for splitting the classical Iris data set into training and test
sets, each split into features and labels.
"""
... 2. Создаём поток
Поток Flow представляет весь рабочий процесс, управляя зависимостями между задачами. Чтобы создать поток, просто вставьте код запуска ваших функций внутри контекстного менеджера with Flow(...).
from prefect import task, Flow
with Flow("data-engineer") as flow:
# Define parameters
target_col = 'species'
test_data_ratio = 0.2
# Define tasks
data = load_data(path="data/raw/iris.csv")
classes = get_classes(data=data, target_col=target_col)
categorical_columns = encode_categorical_columns(data=data, target_col=target_col)
train_test_dict = split_data(data=categorical_columns, test_data_ratio=test_data_ratio, classes=classes)Обратите внимание, что ни одна из этих задач не выполняется при выполнении приведённого выше кода. Prefect позволяет вам либо запустить поток сразу, либо запланировать его. Давайте попробуем сразу же выполнить поток при помощи flow.run():
with Flow("data-engineer") as flow:
# Define your flow here
...
flow.run()Выполнив приведённый выше код, вы получите результат, подобный этому:
└── 15:49:46 | INFO | Beginning Flow run for 'data-engineer'
└── 15:49:46 | INFO | Task 'target_col': Starting task run...
└── 15:49:46 | INFO | Task 'target_col': Finished task run for task with final state: 'Success'
└── 15:49:46 | INFO | Task 'test_data_ratio': Starting task run...
└── 15:49:47 | INFO | Task 'test_data_ratio': Finished task run for task with final state: 'Success'
└── 15:49:47 | INFO | Task 'load_data': Starting task run...
└── 15:49:47 | INFO | Task 'load_data': Finished task run for task with final state: 'Success'
└── 15:49:47 | INFO | Task 'encode_categorical_columns': Starting task run...
└── 15:49:47 | INFO | Task 'encode_categorical_columns': Finished task run for task with final state: 'Success'
└── 15:49:47 | INFO | Task 'get_classes': Starting task run...
└── 15:49:47 | INFO | Task 'get_classes': Finished task run for task with final state: 'Success'
└── 15:49:47 | INFO | Task 'split_data': Starting task run...
└── 15:49:47 | INFO | Task 'split_data': Finished task run for task with final state: 'Success'
└── 15:49:47 | INFO | Flow run SUCCESS: all reference tasks succeeded
Flow run succeeded!Чтобы понять рабочий процесс Prefect, полностью визуализируем его. Начните с установки prefect[viz]:
pip install "prefect[viz]"Затем добавьте в код метод visualize:
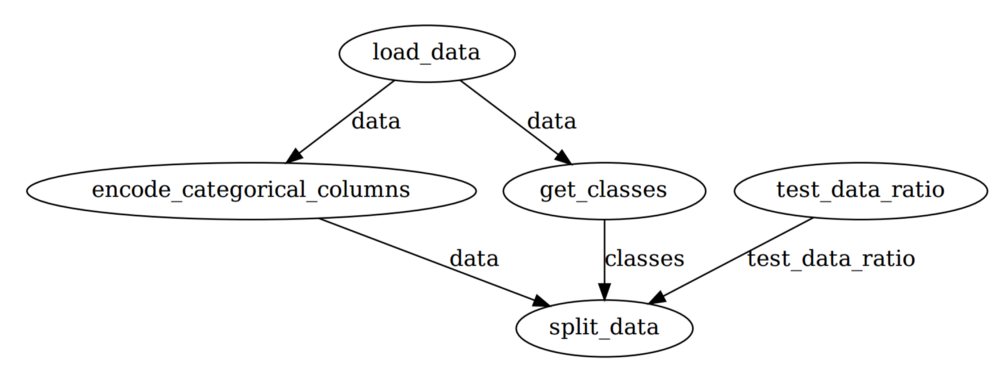
flow.visualize()И вы должны увидеть визуализацию рабочего процесса data-engineer:

Обратите внимание, что Prefect автоматически управляет порядком выполнения задач, чтобы оптимизировать рабочий процесс. Это довольно круто в смысле дополнительных частей кода!
3. Добавляем параметры
Если вы часто экспериментируете с различными значениями одной переменной, идеальным вариантом будет превратить эту переменную в Parameter.
test_data_ratio = 0.2
train_test_dict = split_data(data=categorical_columns,
test_data_ratio=test_data_ratio,
classes=classes)Рассматривать Parameter можно как Task, за исключением того, что он может получать пользовательские данные при каждом запуске потока. Чтобы превратить переменную в параметр, воспользуйтесь task.Parameter.
from prefect import task, Flow, Parameter
test_data_ratio = Parameter("test_data_ratio", default=0.2)
train_test_dict = split_data(data=categorical_columns,
test_data_ratio=test_data_ratio,
classes=classes)Первый аргумент Parameter задает имя параметра. default — необязательный аргумент, это значение параметра по умолчанию. Повторный запуск flow.visualize даст такой результат:
Перезаписать параметр по умолчанию можно для каждого запуска:
Добавим аргумент parameters в функцию flow.run():
flow.run(parameters={'test_data_ratio': 0.3})или воспользуемся CLI Prefect:
$ prefect run -p data_engineering.py --param test_data_ratio=0.2 ещё вариант — файл JSON:
$ prefect run -p data_engineering.py --param-file='params.json'Файл JSON должен выглядеть примерно так:
{"test_data_ratio": 0.3}Вы также можете изменять параметры каждого прогона с помощью программы Prefect Cloud. О ней поговорим ниже.
Мониторинг рабочего процесса
Обзор
Prefect также позволяет контролировать рабочий процесс в Prefect Cloud. Чтобы установить зависимости Prefect Cloud, следуйте этой инструкции. После установки и настройки всех зависимостей начните с создания проекта:
prefect create project "Iris Project"Затем запустите локальный агент, чтобы развернуть потоки локально на одной машине:
prefect agent local startДобавьте строку:
flow.register(project_name="Iris Project")… в конце вашего файла вы должны увидеть что-то похожее на это:
Flow URL: https://cloud.prefect.io/khuyentran1476-gmail-com-s-account/flow/dba26bea-8827-4db4-9988-3289f6cb662f
└── ID: 2944dc36-cdac-4079-8497-be4ec5594785
└── Project: Iris Project
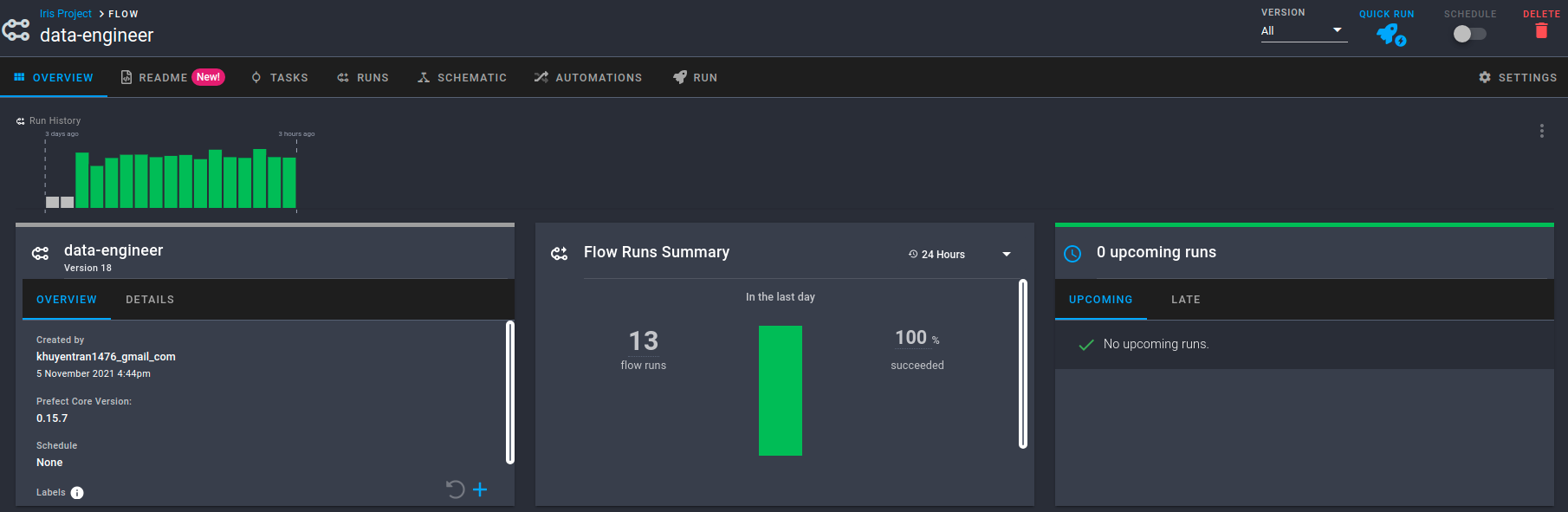
└── Labels: ['khuyen-Precision-7740']Нажмите на URL-адрес в выводе, и вы будете перенаправлены на страницу обзора. На этой странице отображаются версия потока, время его создания, история выполнения потока и сводка выполнения.
Вы также можете просмотреть сводку других запусков, время их выполнения и их конфигурацию.
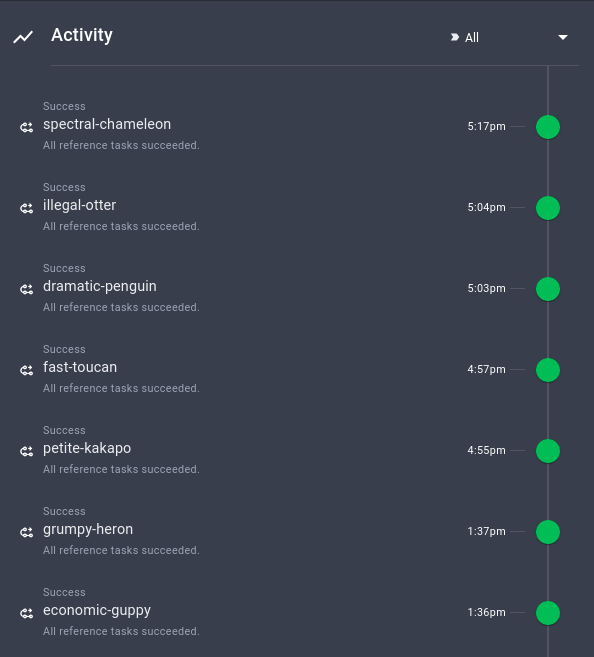
Очень здорово, что эта информация автоматически отслеживаются Prefect!
Запуск рабочего процесса с параметрами по умолчанию
Обратите внимание, что рабочий процесс зарегистрирован в Prefect Cloud, но ещё не выполняется. Чтобы выполнить рабочий процесс с параметрами по умолчанию, нажмите Quick Run в правом верхнем углу.

Щёлкните созданный прогон. Теперь вы увидите активность для вашего нового потока в режиме реального времени!
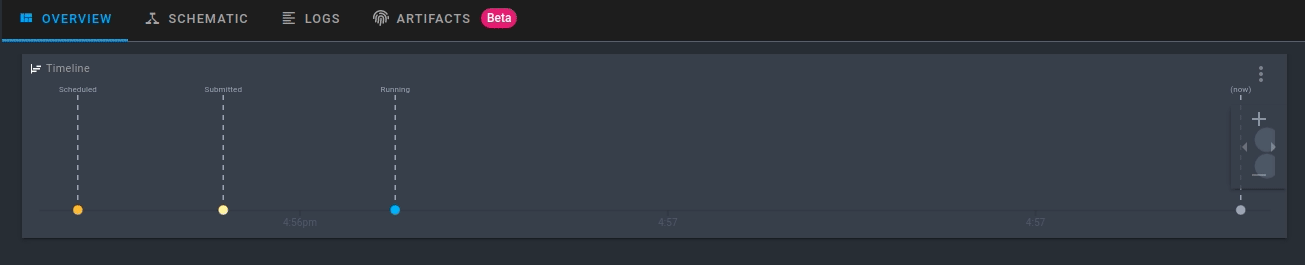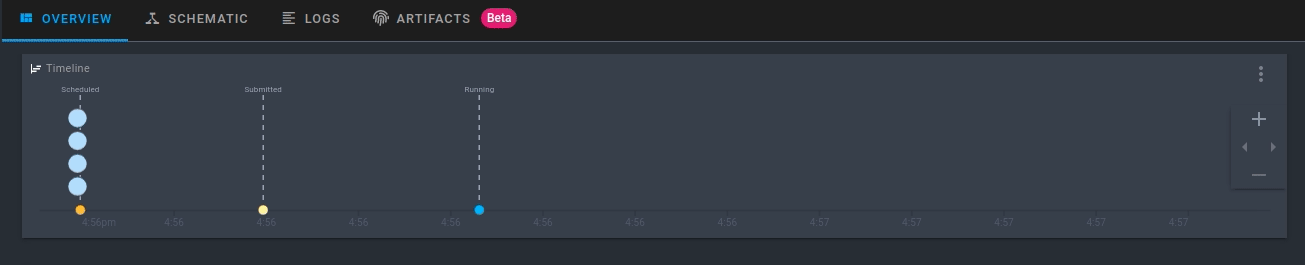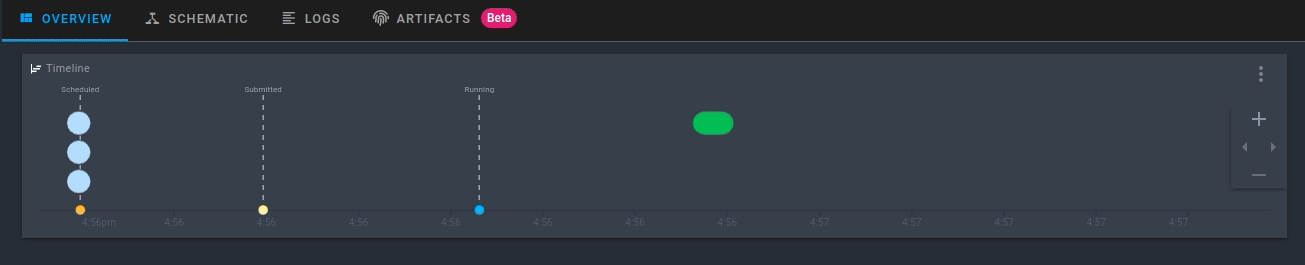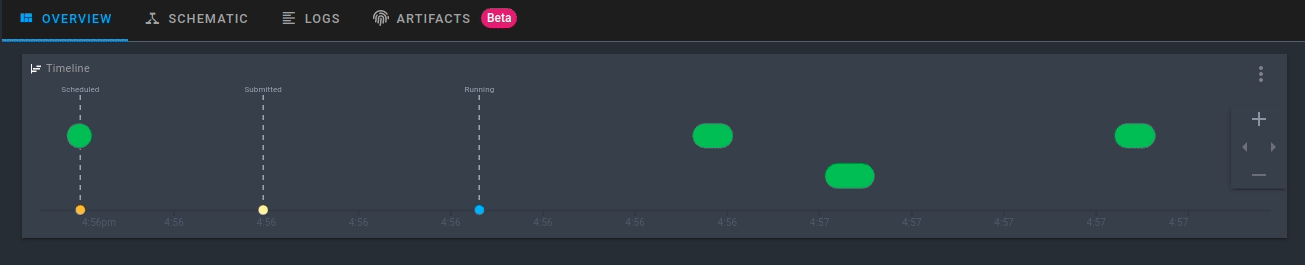
Запуск рабочего процесса с пользовательскими параметрами
Чтобы запустить рабочий процесс с пользовательскими параметрами, перейдите на вкладку Run, а затем измените параметры в разделе Inputs.

Настроив параметры, просто нажмите кнопку Run, чтобы запустить прогон.
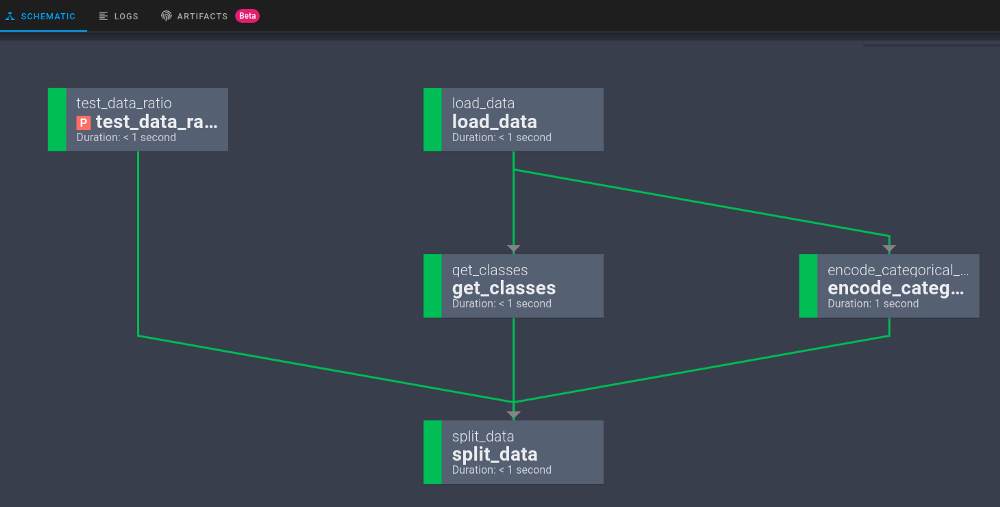
Просмотр графа рабочего процесса
Нажав кнопку Schematic, вы увидите граф всего рабочего процесса.
Другие функции
Prefect также предоставляет другие возможности, которые значительно повышают эффективность рабочего процесса.
Кеширование ввода
Помните проблему, о которой мы упоминали в начале статьи? Обычно, если функция get_classes завершится неудачей, то данные, созданные функцией encode_categorical_columns, будут отброшены, и весь рабочий процесс придётся начинать с самого начала.
Однако в Prefect сохраняется вывод encode_categorical_columns. В следующий раз при повторном запуске рабочего процесса вывод encode_categorical_columns будет использован следующей задачей без повторного запуска encode_categorical_columns.

Это может привести к значительному сокращению времени выполнения рабочего процесса.
Сохранение вывода
Иногда вам может понадобиться экспортировать данные задачи. Это можно сделать, вставив код сохранения данных в функцию Task.
def split_data(data: pd.DataFrame, test_data_ratio: float, classes: list) -> Dict[str, Any]:
X_train, X_test, y_train, y_test = ...
import pickle
pickle.save(...)Однако это затруднит тестирование функции. Prefect позволяет легко сохранять результаты выполнения задачи на каждом запуске. Вот что нужно для этого сделать:
Установите контрольную точку в True:
export PREFECT__FLOWS__CHECKPOINTING=trueДобавьте строку result = LocalResult(dir=...)) к декоратору @task .
from prefect.engine.results import LocalResult
@task(result = LocalResult(dir='data/processed'))
def split_data(data: pd.DataFrame, test_data_ratio: float, classes: list) -> Dict[str, Any]:
"""Task for splitting the classical Iris data set into training and test
sets, each split into features and labels.
"""
X_train, X_test, y_train, y_test = ...
return dict(
train_x=X_train,
train_y=y_train,
test_x=X_test,
test_y=y_test,Теперь вывод задачи split_data сохранится в директории data/processed:
prefect-result-2021-11-06t15-37-29-605869-00-00Если вы хотите настроить имя вашего файла, добавьте к @task аргумент target:
from prefect.engine.results import LocalResult
@task(target="{date:%a %b %d %H:%M:%S %Y}/{task_name}_output",
result = LocalResult(dir='data/processed'))
def split_data(data: pd.DataFrame, test_data_ratio: float, classes: list) -> Dict[str, Any]:
"""Task for splitting the classical Iris data set into training and test
sets, each split into features and labels.
"""
...Prefect также предоставляет другие классы Result, такие как GCSResult и S3Result. Результаты вывода API можно проверить здесь.
Вывод других потоков в текущий поток
Если вы работаете с несколькими потоками, например с потоками data-engineer и data-science, вы, возможно, захотите использовать вывод data-engineer для data-science.

После сохранения вывода data-engineer вы можете прочитать их с помощью метода read.
from prefect.engine.results import LocalResult
train_test_dict = LocalResult(dir=...).read(location=...).valueПодключение зависимых потоков
Представьте ситуацию: вы создали два потока, которые зависят друг от друга. Поток data-engineer должен быть выполнен до потока data-science. Кто-то не понял взаимосвязи между этими двумя потоками. Потоки data-science и data-engineer были выполнены одновременно, и произошла ошибка!

Чтобы этого не произошло, мы должны определить взаимосвязь между потоками. К счастью, Prefect облегчает нам эту задачу. Начните с захвата двух различных потоков с помощью StartFlowRun. Добавьте wait=True к аргументу, чтобы нисходящий поток выполнялся только после завершения восходящего потока.
from prefect import Flow
from prefect.tasks.prefect import StartFlowRun
data_engineering_flow = StartFlowRun(flow_name="data-engineer",
project_name='Iris Project',
wait=True)
data_science_flow = StartFlowRun(flow_name="data-science",
project_name='Iris Project',
wait=True)Вызовем data_science_flow с with Flow(...). Используйте upstream_tasks для указания задач/потоков, которые будут выполняться перед выполнением data-science.
with Flow("main-flow") as flow:
result = data_science_flow(upstream_tasks=[data_engineering_flow])
flow.run()Теперь два потока соединены:

Очень круто!
Планируйте свой поток
Prefect также позволяет легко выполнить поток в определённое время или с определённым интервалом. К примеру, чтобы запускать поток каждую минуту, вы можете создать экземпляр класса IntervalSchedule и добавить schedule к with Flow(...):
from prefect.schedules import IntervalSchedule
schedule = IntervalSchedule(
start_date=datetime.utcnow() + timedelta(seconds=1),
interval=timedelta(minutes=1),
)
data_engineering_flow = ...
data_science_flow = ...
with Flow("main-flow", schedule=schedule) as flow:
data_science = data_science_flow(upstream_tasks=[data_engineering_flow])Теперь ваш поток будет повторяться каждую минуту! Узнать об этом больше вы можете узнать здесь.
Логирование
Логировать печать внутри задачи вы сможете, просто добавив log_stdout=True в @task :
@task(log_stdout=True)
def report_accuracy(predictions: np.ndarray, test_y: pd.DataFrame) -> None:
target = ...
accuracy = ...
print(f"Model accuracy on test set: {round(accuracy * 100, 2)}")Вывод будет примерно таким:
[2021-11-06 11:41:16-0500] INFO - prefect.TaskRunner | Model accuracy on test set: 93.33Заключение
Поздравляю! Мы только что разобрались, как Prefect с помощью нескольких строк кода оптимизирует ваш рабочий процесс Data Science. Небольшая оптимизация в коде может привести к огромному повышению эффективности в долгосрочной перспективе. Свободно форкайте исходный код из этой статьи:
Код на Github.
Попробовать Prefect в деле вы сможете на наших курсах:

Узнать подробности акции.
Профессии и курсы
Data Science и Machine Learning
Python, веб-разработка
Мобильная разработка
Java и C#
От основ — в глубину
А также:
