Всем привет! В этой статье я хочу упорядочить информацию и поделиться опытом создания и использования внутреннего кластера Kubernetes.
За последние несколько лет эта технология оркестровки контейнеров сделала большой шаг вперед и стала своего рода корпоративным стандартом для тысяч компаний. Некоторые используют ее в продакшене, другие просто тестируют на проектах, но страсти вокруг нее, как ни крути, пылают нешуточные. Если еще ни разу ее не использовали, самое время начать знакомство.
0. Вступление
Kubernetes — это масштабируемая технология оркестровки, которая может начинаться с установки на одной ноде и достигать размеров огромных НА-кластеров на основе нескольких сотен нод внутри. Большинство популярных облачных провайдеров представляют разные виды реализации Kubernetes — бери и пользуйся. Но ситуации бывают разные, и есть компании, которые облака не используют, а получить все преимущества современных технологий оркестровки хотят. И тут на сцену выходит инсталляция Kubernetes на «голое железо».

1. Введение
В этом примере мы создадим НА-кластер Kubernetes с топологией на несколько мастер-нод (multi masters), с внешним кластером etcd в качестве базового слоя и балансировщиком нагрузки MetalLB внутри. На всех рабочих нодах будем развертывать GlusterFS как простое внутреннее распределенное кластерное хранилище. Также попытаемся развернуть в нем несколько тестовых проектов, используя наш личный реестр Docker.
Вообще, есть несколько способов создать НА-кластер Kubernetes: трудный и углубленный путь, описанный в популярном документе kubernetes-the-hard-way, или более простой способ — с помощью утилиты kubeadm.
Kubeadm — это инструмент, созданный сообществом Kubernetes именно, чтобы упростить установку Kubernetes и облегчить процесс. Ранее Kubeadm рекомендовали только для создания небольших тестовых кластеров с одной мастер-нодой, для начала работы. Но за последний год многое улучшили, и теперь мы можем использовать его для создания HA-кластеров с несколькими мастер-нодами. Если верить новостям сообщества Kubernetes, в будущем Kubeadm будет рекомендоваться в качестве инструмента для установки Kubernetes.
Документация на Kubeadm предлагает два основных способа реализации кластера, со стековой и внешней etcd-топологией. Я выберу второй путь с внешними etcd нодами по причине отказоустойчивости НА-кластера.
Вот схема из документации Kubeadm, описывающая этот путь:
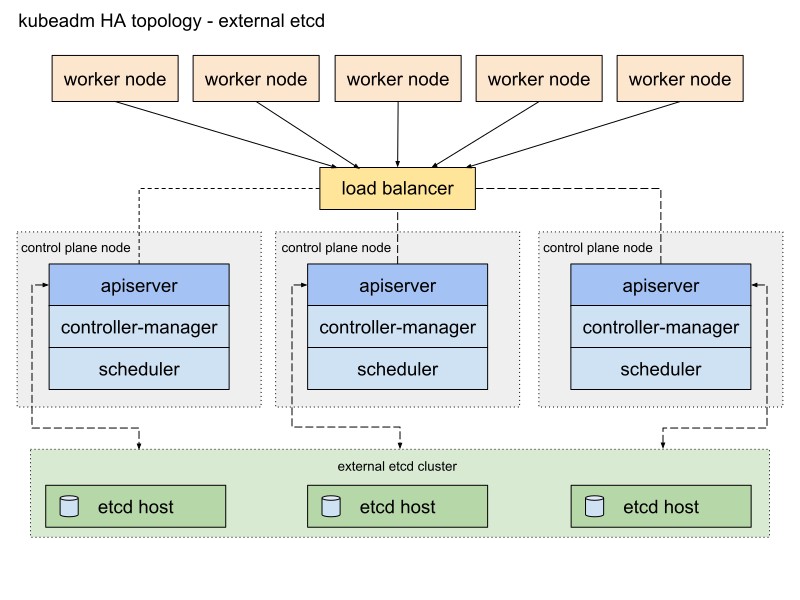
Я немного ее изменю. Во-первых, буду использовать пару серверов HAProxy в качестве балансировщиков нагрузки с пакетом Heartbeat, которые будут делить виртуальный IP-адрес. Heartbeat и HAProxy используют небольшое количество системных ресурсов, поэтому я размещу их на паре etcd нод, чтобы немного уменьшить число серверов для нашего кластера.
Для этой схемы кластера Kubernetes понадобится восемь нод. Три сервера для внешнего кластера etcd (LB-сервисы также будут использовать пару из их числа), два — для нод плоскости управления (мастер-ноды) и три — для рабочих нод. Это может быть как «голое железо», так и VM-сервер. В данном случае это не принципиально. Можно запросто изменить схему, добавив больше мастер-нод и разместив HAProxy с Heartbeat на отдельных нодах, если свободных серверов много. Хотя моего варианта для первой реализации кластера HA хватит за глаза.
А хотите — добавьте небольшой сервер с установленной утилитой kubectl для управления этим кластером или используйте для этого собственный рабочий стол Linux.
Схема для этого примера будет выглядеть примерно так:
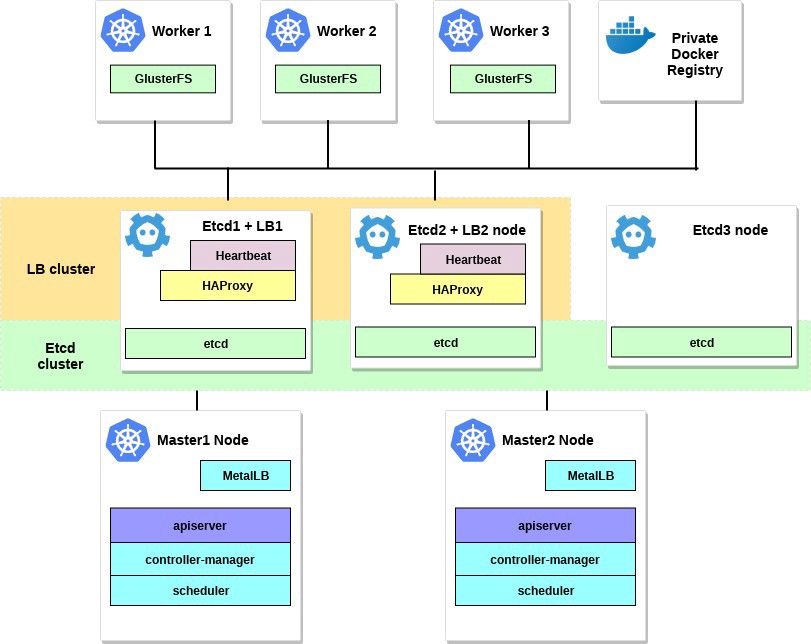
2. Требования
Понадобятся две мастер-ноды Kubernetes с минимальными рекомендованными системными требованиями: 2 ЦП и 2 ГБ ОЗУ в соответствии с документацией kubeadm. Для рабочих нод рекомендую использовать более мощные серверы, поскольку на них будем запускать все наши сервисы приложений. А для Etcd + LB мы также можем взять серверы с двумя ЦП и минимум 2 ГБ ОЗУ.
Выберите сеть общего пользования или частную сеть для этого кластера; IP-адреса значения не имеют; важно, чтобы все серверы были доступны друг для друга и, конечно, для вас. Позже внутри кластера Kubernetes мы настроим оверлейную сеть.
Минимальные требования для этого примера:
- 2 сервера с 2 процессорами и 2 ГБ оперативной памяти для мастер-нод
- 3 сервера с 4 процессорами и 4-8 ГБ оперативной памяти для рабочих нод
- 3 сервера с 2 процессорами и 2 ГБ оперативной памяти для Etcd и HAProxy
- 192.168.0.0/24 — подсеть.
192.168.0.1 — виртуальный IP-адрес HAProxy, 192.168.0.2 — 4 основных IP-адреса нод Etcd и HAProxy, 192.168.0.5 — 6 основных IP-адресов мастер-нод Kubernetes, 192.168.0.7 — 9 основных IP-адресов рабочих нод Kubernetes.
База Debian 9 установлена на всех серверах.
Также помните, что системные требования зависят от того, насколько большой и мощный кластер нужен. Дополнительную информацию можно получить в документации по Kubernetes.
3. Настройка HAProxy и Heartbeat.
У нас больше одной мастер-ноды Kubernetes, и поэтому необходимо настроить перед ними балансировщик нагрузки HAProxy — распределять трафик. Это будет пара серверов HAProxy с одним общим виртуальным IP-адресом. Отказоустойчивость обеспечивается при помощи пакета Heartbeat. Для развертывания мы воспользуемся первыми двумя etcd серверами.
Установим и настроим HAProxy с Heartbeat на первом и втором etcd -серверах (192.168.0.2–3 в этом примере):
etcd1# apt-get update && apt-get upgrade && apt-get install -y haproxy
etcd2# apt-get update && apt-get upgrade && apt-get install -y haproxyСохраните исходную конфигурацию и создайте новую:
etcd1# mv /etc/haproxy/haproxy.cfg{,.back}
etcd1# vi /etc/haproxy/haproxy.cfg
etcd2# mv /etc/haproxy/haproxy.cfg{,.back}
etcd2# vi /etc/haproxy/haproxy.cfgДобавьте эти параметры конфигурации для обоих HAProxy:
global
user haproxy
group haproxy
defaults
mode http
log global
retries 2
timeout connect 3000ms
timeout server 5000ms
timeout client 5000ms
frontend kubernetes
bind 192.168.0.1:6443
option tcplog
mode tcp
default_backend kubernetes-master-nodes
backend kubernetes-master-nodes
mode tcp
balance roundrobin
option tcp-check
server k8s-master-0 192.168.0.5:6443 check fall 3 rise 2
server k8s-master-1 192.168.0.6:6443 check fall 3 rise 2Как видите, обе службы HAProxy делят IP-адрес — 192.168.0.1. Этот виртуальный IP-адрес будет перемещаться между серверами, поэтому чутка схитрим и включим параметр net.ipv4.ip_nonlocal_bind, чтобы разрешить привязку системных служб к нелокальному IP-адресу.
Добавьте эту возможность в файл /etc/sysctl.conf:
etcd1# vi /etc/sysctl.conf
net.ipv4.ip_nonlocal_bind=1
etcd2# vi /etc/sysctl.conf
net.ipv4.ip_nonlocal_bind=1Запустите на обоих серверах:
sysctl -pТакже запустите HAProxy на обоих серверах:
etcd1# systemctl start haproxy
etcd2# systemctl start haproxyУбедитесь, что HAProxy запущены и прослушиваются по виртуальному IP-адресу на обоих серверах:
etcd1# netstat -ntlp
tcp 0 0 192.168.0.1:6443 0.0.0.0:* LISTEN 2833/haproxy
etcd2# netstat -ntlp
tcp 0 0 192.168.0.1:6443 0.0.0.0:* LISTEN 2833/haproxyГуд! Теперь установим Heartbeat и настроим этот виртуальный IP.
etcd1# apt-get -y install heartbeat && systemctl enable heartbeat
etcd2# apt-get -y install heartbeat && systemctl enable heartbeatПришло время создать для него несколько файлов конфигурации: для первого и второго серверов они будут, в основном, одинаковыми.
Сначала создайте файл /etc/ha.d/authkeys, в этом файле Heartbeat хранит данные для взаимной аутентификации. Файл должен быть одинаковым на обоих серверах:
# echo -n securepass | md5sum
bb77d0d3b3f239fa5db73bdf27b8d29a
etcd1# vi /etc/ha.d/authkeys
auth 1
1 md5 bb77d0d3b3f239fa5db73bdf27b8d29a
etcd2# vi /etc/ha.d/authkeys
auth 1
1 md5 bb77d0d3b3f239fa5db73bdf27b8d29aЭтот файл должен быть доступен только руту:
etcd1# chmod 600 /etc/ha.d/authkeys
etcd2# chmod 600 /etc/ha.d/authkeysТеперь создадим основной файл конфигурации для Heartbeat на обоих серверах: для каждого сервера он будет немного отличаться.
Создайте /etc/ha.d/ha.cf:
etcd1
etcd1# vi /etc/ha.d/ha.cf
# keepalive: how many seconds between heartbeats
#
keepalive 2
#
# deadtime: seconds-to-declare-host-dead
#
deadtime 10
#
# What UDP port to use for udp or ppp-udp communication?
#
udpport 694
bcast ens18
mcast ens18 225.0.0.1 694 1 0
ucast ens18 192.168.0.3
# What interfaces to heartbeat over?
udp ens18
#
# Facility to use for syslog()/logger (alternative to log/debugfile)
#
logfacility local0
#
# Tell what machines are in the cluster
# node nodename ... -- must match uname -n
node etcd1_hostname
node etcd2_hostnameetcd2
etcd2# vi /etc/ha.d/ha.cf
# keepalive: how many seconds between heartbeats
#
keepalive 2
#
# deadtime: seconds-to-declare-host-dead
#
deadtime 10
#
# What UDP port to use for udp or ppp-udp communication?
#
udpport 694
bcast ens18
mcast ens18 225.0.0.1 694 1 0
ucast ens18 192.168.0.2
# What interfaces to heartbeat over?
udp ens18
#
# Facility to use for syslog()/logger (alternative to vlog/debugfile)
#
logfacility local0
#
# Tell what machines are in the cluster
# node nodename ... -- must match uname -n
node etcd1_hostname
node etcd2_hostnameПараметры «ноды» для этой конфигурации получите, запустив uname -n на обоих Etcd серверах. Также используйте имя вашей сетевой карты вместо ens18.
Наконец, нужно создать на этих серверах файл /etc/ha.d/haresources. Для обоих серверов файл должен быть одинаковым. В этом файле мы задаем наш общий IP-адрес и определяем, какая нода является главной по умолчанию:
etcd1# vi /etc/ha.d/haresources
etcd1_hostname 192.168.0.1
etcd2# vi /etc/ha.d/haresources
etcd1_hostname 192.168.0.1Когда все готово, запускаем службы Heartbeat на обоих серверах и проверяем, что на ноде etcd1 мы получили этот заявленный виртуальный IP:
etcd1# systemctl restart heartbeat
etcd2# systemctl restart heartbeat
etcd1# ip a
ens18: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether xx:xx:xx:xx:xx:xx brd ff:ff:ff:ff:ff:ff
inet 192.168.0.2/24 brd 192.168.0.255 scope global ens18
valid_lft forever preferred_lft forever
inet 192.168.0.1/24 brd 192.168.0.255 scope global secondaryВы можете проверить, что HAProxy работает нормально, запустив nc по адресу 192.168.0.1 6443. Должно быть, у вас превышено время ожидания, поскольку Kubernetes API пока не прослушивается на серверной части. Но это означает, что HAProxy и Heartbeat настроены правильно.
# nc -v 192.168.0.1 6443
Connection to 93.158.95.90 6443 port [tcp/*] succeeded!4. Подготовка нод для Kubernetes
Следующим шагом подготовим все ноды Kubernetes. Нужно установить Docker с некоторыми дополнительными пакетами, добавить репозиторий Kubernetes и установить из него пакеты kubelet, kubeadm, kubectl. Эта настройка одинакова для всех нод Kubernetes (мастер-, рабочих и проч.)
Основное преимущество Kubeadm в том, что дополнительного ПО много не надо. Установили kubeadm на всех хостах — и пользуйтесь; хоть сертификаты CA генерируйте.
Установка Docker на всех нодах:
Update the apt package index
# apt-get update
Install packages to allow apt to use a repository over HTTPS
# apt-get -y install \
apt-transport-https \
ca-certificates \
curl \
gnupg2 \
software-properties-common
Add Docker’s official GPG key
# curl -fsSL https://download.docker.com/linux/debian/gpg | sudo apt-key add -
Add docker apt repository
# apt-add-repository \
"deb [arch=amd64] https://download.docker.com/linux/debian \
$(lsb_release -cs) \
stable"
Install docker-ce.
# apt-get update && apt-get -y install docker-ce
Check docker version
# docker -v
Docker version 18.09.0, build 4d60db4После этого установите на всех нодах пакеты Kubernetes:
kubeadm: команда для загрузки кластера.kubelet: компонент, который запускается на всех компьютерах в кластере и выполняет действия вроде как запуска подов и контейнеров.kubectl: командная строка util для связи с кластером.- kubectl — по желанию; я часто устанавливаю его на всех нодах, чтобы запускать кое-какие команды Kubernetes для отладки.
# curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add -
Add the Google repository
# cat <<EOF >/etc/apt/sources.list.d/kubernetes.list
deb https://apt.kubernetes.io/ kubernetes-xenial main
EOF
Update and install packages
# apt-get update && apt-get install -y kubelet kubeadm kubectl
Hold back packages
# apt-mark hold kubelet kubeadm kubectl
Check kubeadm version
# kubeadm version
kubeadm version: &version.Info{Major:"1", Minor:"13", GitVersion:"v1.13.1", GitCommit:"eec55b9dsfdfgdfgfgdfgdfgdf365bdd920", GitTreeState:"clean", BuildDate:"2018-12-13T10:36:44Z", GoVersion:"go1.11.2", Compiler:"gc", Platform:"linux/amd64"}Установив kubeadm и остальные пакеты, не забудьте отключить swap.
# swapoff -a
# sed -i '/ swap / s/^/#/' /etc/fstabПовторите установку на остальных нодах. Пакеты ПО одинаковыми для всех нод кластера, и только следующая конфигурация определит роли, которые они получат позже.
5. Настройка кластера HA Etcd
Итак, завершив приготовления, настроим кластер Kubernetes. Первым кирпичиком будет кластер HA Etcd, который также настраивается с помощью инструмента kubeadm.
Прежде чем начнем, убедитесь, что все etcd ноды сообщаются через порты 2379 и 2380. Кроме того, между ними нужно настроить ssh-доступ — чтобы использовать scp.
Начнем с первой etcd ноды, а затем просто скопируем все необходимые сертификаты и файлы конфигурации на остальные серверы.
На всех etcd нодах нужно добавить новый файл конфигурации systemd для юнита kubelet с более высоким приоритетом:
etcd-nodes# cat << EOF > /etc/systemd/system/kubelet.service.d/20-etcd-service-manager.conf
[Service]
ExecStart=
ExecStart=/usr/bin/kubelet --address=127.0.0.1 --pod-manifest-path=/etc/kubernetes/manifests --allow-privileged=true
Restart=always
EOF
etcd-nodes# systemctl daemon-reload
etcd-nodes# systemctl restart kubeletЗатем перейдем по ssh к первой etcd ноде — ее будем использовать для генерации всех необходимых конфигураций kubeadm для каждой etcd ноды, а затем их скопируем.
# Export all our etcd nodes IP's as variables
etcd1# export HOST0=192.168.0.2
etcd1# export HOST1=192.168.0.3
etcd1# export HOST2=192.168.0.4
# Create temp directories to store files for all nodes
etcd1# mkdir -p /tmp/${HOST0}/ /tmp/${HOST1}/ /tmp/${HOST2}/
etcd1# ETCDHOSTS=(${HOST0} ${HOST1} ${HOST2})
etcd1# NAMES=("infra0" "infra1" "infra2")
etcd1# for i in "${!ETCDHOSTS[@]}"; do
HOST=${ETCDHOSTS[$i]}
NAME=${NAMES[$i]}
cat << EOF > /tmp/${HOST}/kubeadmcfg.yaml
apiVersion: "kubeadm.k8s.io/v1beta1"
kind: ClusterConfiguration
etcd:
local:
serverCertSANs:
- "${HOST}"
peerCertSANs:
- "${HOST}"
extraArgs:
initial-cluster: ${NAMES[0]}=https://${ETCDHOSTS[0]}:2380,${NAMES[1]}=https://${ETCDHOSTS[1]}:2380,${NAMES[2]}=https://${ETCDHOSTS[2]}:2380
initial-cluster-state: new
name: ${NAME}
listen-peer-urls: https://${HOST}:2380
listen-client-urls: https://${HOST}:2379
advertise-client-urls: https://${HOST}:2379
initial-advertise-peer-urls: https://${HOST}:2380
EOF
doneТеперь создадим основной центр сертификации, используя kubeadm
etcd1# kubeadm init phase certs etcd-caЭта команда создаст два файла ca.crt & ca.key в директории /etc/kubernetes/pki/etcd/.
etcd1# ls /etc/kubernetes/pki/etcd/
ca.crt ca.keyТеперь сгенерируем сертификаты для всех etcd нод:
### Create certificates for the etcd3 node
etcd1# kubeadm init phase certs etcd-server --config=/tmp/${HOST2}/kubeadmcfg.yaml
etcd1# kubeadm init phase certs etcd-peer --config=/tmp/${HOST2}/kubeadmcfg.yaml
etcd1# kubeadm init phase certs etcd-healthcheck-client --config=/tmp/${HOST2}/kubeadmcfg.yaml
etcd1# kubeadm init phase certs apiserver-etcd-client --config=/tmp/${HOST2}/kubeadmcfg.yaml
etcd1# cp -R /etc/kubernetes/pki /tmp/${HOST2}/
### cleanup non-reusable certificates
etcd1# find /etc/kubernetes/pki -not -name ca.crt -not -name ca.key -type f -delete
### Create certificates for the etcd2 node
etcd1# kubeadm init phase certs etcd-server --config=/tmp/${HOST1}/kubeadmcfg.yaml
etcd1# kubeadm init phase certs etcd-peer --config=/tmp/${HOST1}/kubeadmcfg.yaml
etcd1# kubeadm init phase certs etcd-healthcheck-client --config=/tmp/${HOST1}/kubeadmcfg.yaml
etcd1# kubeadm init phase certs apiserver-etcd-client --config=/tmp/${HOST1}/kubeadmcfg.yaml
etcd1# cp -R /etc/kubernetes/pki /tmp/${HOST1}/
### cleanup non-reusable certificates again
etcd1# find /etc/kubernetes/pki -not -name ca.crt -not -name ca.key -type f -delete
### Create certificates for the this local node
etcd1# kubeadm init phase certs etcd-server --config=/tmp/${HOST0}/kubeadmcfg.yaml
etcd1 #kubeadm init phase certs etcd-peer --config=/tmp/${HOST0}/kubeadmcfg.yaml
etcd1# kubeadm init phase certs etcd-healthcheck-client --config=/tmp/${HOST0}/kubeadmcfg.yaml
etcd1# kubeadm init phase certs apiserver-etcd-client --config=/tmp/${HOST0}/kubeadmcfg.yaml
# No need to move the certs because they are for this node
# clean up certs that should not be copied off this host
etcd1# find /tmp/${HOST2} -name ca.key -type f -delete
etcd1# find /tmp/${HOST1} -name ca.key -type f -deleteЗатем скопируем сертификаты и конфигурации kubeadm на ноды etcd2 и etcd3.
Сначала сгенерируйте пару ssh-ключей на etcd1 и добавьте открытую часть к нодам etcd2 и 3. В этом примере все команды выполняются от имени пользователя, владеющего всеми правами в системе.
etcd1# scp -r /tmp/${HOST1}/* ${HOST1}:
etcd1# scp -r /tmp/${HOST2}/* ${HOST2}:
### login to the etcd2 or run this command remotely by ssh
etcd2# cd /root
etcd2# mv pki /etc/kubernetes/
### login to the etcd3 or run this command remotely by ssh
etcd3# cd /root
etcd3# mv pki /etc/kubernetes/Прежде чем запустить кластер etcd, убедитесь, что файлы существуют на всех нодах:
Список необходимых файлов на etcd1:
/tmp/192.168.0.2
└── kubeadmcfg.yaml
---
/etc/kubernetes/pki
├── apiserver-etcd-client.crt
├── apiserver-etcd-client.key
└── etcd
├── ca.crt
├── ca.key
├── healthcheck-client.crt
├── healthcheck-client.key
├── peer.crt
├── peer.key
├── server.crt
└── server.keyДля ноды etcd2 это:
/root
└── kubeadmcfg.yaml
---
/etc/kubernetes/pki
├── apiserver-etcd-client.crt
├── apiserver-etcd-client.key
└── etcd
├── ca.crt
├── healthcheck-client.crt
├── healthcheck-client.key
├── peer.crt
├── peer.key
├── server.crt
└── server.keyИ последняя нода etcd3:
/root
└── kubeadmcfg.yaml
---
/etc/kubernetes/pki
├── apiserver-etcd-client.crt
├── apiserver-etcd-client.key
└── etcd
├── ca.crt
├── healthcheck-client.crt
├── healthcheck-client.key
├── peer.crt
├── peer.key
├── server.crt
└── server.keyКогда все сертификаты и конфигурации на месте, создаем манифесты. На каждой ноде выполните команду kubeadm — чтобы сгенерировать статический манифест для кластера etcd:
etcd1# kubeadm init phase etcd local --config=/tmp/192.168.0.2/kubeadmcfg.yaml
etcd1# kubeadm init phase etcd local --config=/root/kubeadmcfg.yaml
etcd1# kubeadm init phase etcd local --config=/root/kubeadmcfg.yamlТеперь кластер etcd — по идее — настроен и исправен. Проверьте, выполнив следующую команду на ноде etcd1:
etcd1# docker run --rm -it \
--net host \
-v /etc/kubernetes:/etc/kubernetes quay.io/coreos/etcd:v3.2.24 etcdctl \
--cert-file /etc/kubernetes/pki/etcd/peer.crt \
--key-file /etc/kubernetes/pki/etcd/peer.key \
--ca-file /etc/kubernetes/pki/etcd/ca.crt \
--endpoints https://192.168.0.2:2379 cluster-health
### status output
member 37245675bd09ddf3 is healthy: got healthy result from https://192.168.0.3:2379
member 532d748291f0be51 is healthy: got healthy result from https://192.168.0.4:2379
member 59c53f494c20e8eb is healthy: got healthy result from https://192.168.0.2:2379
cluster is healthyКластер etcd поднялся, так что двигаемся дальше.
6. Настройка мастер- и рабочих нод
Настроим мастер-ноды нашего кластера — скопируйте эти файлы с первой ноды etcd на первую мастер-ноду:
etcd1# scp /etc/kubernetes/pki/etcd/ca.crt 192.168.0.5:
etcd1# scp /etc/kubernetes/pki/apiserver-etcd-client.crt 192.168.0.5:
etcd1# scp /etc/kubernetes/pki/apiserver-etcd-client.key 192.168.0.5:Затем перейдите по ssh к мастер-ноде master1 и создайте файл kubeadm-config.yaml со следующим содержанием:
master1# cd /root && vi kubeadm-config.yaml
apiVersion: kubeadm.k8s.io/v1beta1
kind: ClusterConfiguration
kubernetesVersion: stable
apiServer:
certSANs:
- "192.168.0.1"
controlPlaneEndpoint: "192.168.0.1:6443"
etcd:
external:
endpoints:
- https://192.168.0.2:2379
- https://192.168.0.3:2379
- https://192.168.0.4:2379
caFile: /etc/kubernetes/pki/etcd/ca.crt
certFile: /etc/kubernetes/pki/apiserver-etcd-client.crt
keyFile: /etc/kubernetes/pki/apiserver-etcd-client.keyПереместите ранее скопированные сертификаты и ключ в соответствующую директорию на ноде master1, как в описании настройки.
master1# mkdir -p /etc/kubernetes/pki/etcd/
master1# cp /root/ca.crt /etc/kubernetes/pki/etcd/
master1# cp /root/apiserver-etcd-client.crt /etc/kubernetes/pki/
master1# cp /root/apiserver-etcd-client.key /etc/kubernetes/pki/Чтобы создать первую мастер-ноду, выполните:
master1# kubeadm init --config kubeadm-config.yamlЕсли все предыдущие шаги выполнены правильно, вы увидите следующее:
You can now join any number of machines by running the following on each node
as root:
kubeadm join 192.168.0.1:6443 --token aasuvd.kw8m18m5fy2ot387 --discovery-token-ca-cert-hash sha256:dcbaeed8d1478291add0294553b6b90b453780e546d06162c71d515b494177a6Скопируйте этот вывод инициализации kubeadm в любой текстовый файл, мы будем использовать этот токен в будущем, когда присоединим к нашему кластеру вторую мастер- и рабочую ноды.
Я уже говорил, что кластер Kubernetes будет использовать некую оверлейную сеть для подов и других сервисов, поэтому на этом этапе нужно установить какой-либо плагин CNI. Я рекомендую плагин Weave CNI. Опыт показал: он полезней и менее проблемный, — но вы можете выбрать другой, например, Calico.
Установка сетевого плагина Weave на первую мастер-ноду:
master1# kubectl --kubeconfig /etc/kubernetes/admin.conf apply -f "https://cloud.weave.works/k8s/net?k8s-version=$(kubectl version | base64 | tr -d '\n')"
The connection to the server localhost:8080 was refused - did you specify the right host or port?
serviceaccount/weave-net created
clusterrole.rbac.authorization.k8s.io/weave-net created
clusterrolebinding.rbac.authorization.k8s.io/weave-net created
role.rbac.authorization.k8s.io/weave-net created
rolebinding.rbac.authorization.k8s.io/weave-net created
daemonset.extensions/weave-net createdНемного подождите, а затем введите следующую команду для проверки запуска подов компонентов:
master1# kubectl --kubeconfig /etc/kubernetes/admin.conf get pod -n kube-system -w
NAME READY STATUS RESTARTS AGE
coredns-86c58d9df4-d7qfw 1/1 Running 0 6m25s
coredns-86c58d9df4-xj98p 1/1 Running 0 6m25s
kube-apiserver-master1 1/1 Running 0 5m22s
kube-controller-manager-master1 1/1 Running 0 5m41s
kube-proxy-8ncqw 1/1 Running 0 6m25s
kube-scheduler-master1 1/1 Running 0 5m25s
weave-net-lvwrp 2/2 Running 0 78s- Рекомендуется присоединять новые ноды плоскости управления только после инициализации первой ноды.
Чтобы проверить состояние кластера, выполните:
master1# kubectl --kubeconfig /etc/kubernetes/admin.conf get nodes
NAME STATUS ROLES AGE VERSION
master1 Ready master 11m v1.13.1Прекрасно! Первая мастер-нода поднялась. Теперь она готова, и мы закончим создавать кластер Kubernetes — добавим вторую мастер-ноду и рабочие ноды.
Чтобы добавить вторую мастер-ноду, создайте ssh-ключ на ноде master1 и добавьте открытую часть в ноду master2. Выполните тестовый вход в систему, а затем скопируйте кое-какие файлы с первой мастер-ноды на вторую:
master1# scp /etc/kubernetes/pki/ca.crt 192.168.0.6:
master1# scp /etc/kubernetes/pki/ca.key 192.168.0.6:
master1# scp /etc/kubernetes/pki/sa.key 192.168.0.6:
master1# scp /etc/kubernetes/pki/sa.pub 192.168.0.6:
master1# scp /etc/kubernetes/pki/front-proxy-ca.crt @192.168.0.6:
master1# scp /etc/kubernetes/pki/front-proxy-ca.key @192.168.0.6:
master1# scp /etc/kubernetes/pki/apiserver-etcd-client.crt @192.168.0.6:
master1# scp /etc/kubernetes/pki/apiserver-etcd-client.key @192.168.0.6:
master1# scp /etc/kubernetes/pki/etcd/ca.crt 192.168.0.6:etcd-ca.crt
master1# scp /etc/kubernetes/admin.conf 192.168.0.6:
### Check that files was copied well
master2# ls /root
admin.conf ca.crt ca.key etcd-ca.crt front-proxy-ca.crt front-proxy-ca.key sa.key sa.pubНа второй мастер-ноде переместите ранее скопированные сертификаты и ключи в соответствующие директории:
master2#
mkdir -p /etc/kubernetes/pki/etcd
mv /root/ca.crt /etc/kubernetes/pki/
mv /root/ca.key /etc/kubernetes/pki/
mv /root/sa.pub /etc/kubernetes/pki/
mv /root/sa.key /etc/kubernetes/pki/
mv /root/apiserver-etcd-client.crt /etc/kubernetes/pki/
mv /root/apiserver-etcd-client.key /etc/kubernetes/pki/
mv /root/front-proxy-ca.crt /etc/kubernetes/pki/
mv /root/front-proxy-ca.key /etc/kubernetes/pki/
mv /root/etcd-ca.crt /etc/kubernetes/pki/etcd/ca.crt
mv /root/admin.conf /etc/kubernetes/admin.confПрисоединим вторую мастер-ноду к кластеру. Для этого понадобится вывод команды соединения, который был ранее передан нам kubeadm init на первой ноде.
Запустите мастер-ноду master2:
master2# kubeadm join 192.168.0.1:6443 --token aasuvd.kw8m18m5fy2ot387 --discovery-token-ca-cert-hash sha256:dcbaeed8d1478291add0294553b6b90b453780e546d06162c71d515b494177a6 --experimental-control-plane- Нужно добавить флажок
--experimental-control-plane. Он автоматизирует присоединение данных мастер-нод к кластеру. Без этого флажка просто добавится обычная рабочая нода.
Подождите немного, пока нода не присоединится к кластеру, и проверьте новое состояние кластера:
master1# kubectl --kubeconfig /etc/kubernetes/admin.conf get nodes
NAME STATUS ROLES AGE VERSION
master1 Ready master 32m v1.13.1
master2 Ready master 46s v1.13.1Также убедитесь, что все поды со всех мастер-нод запущены нормально:
master1# kubectl — kubeconfig /etc/kubernetes/admin.conf get pod -n kube-system -w
NAME READY STATUS RESTARTS AGE
coredns-86c58d9df4-d7qfw 1/1 Running 0 46m
coredns-86c58d9df4-xj98p 1/1 Running 0 46m
kube-apiserver-master1 1/1 Running 0 45m
kube-apiserver-master2 1/1 Running 0 15m
kube-controller-manager-master1 1/1 Running 0 45m
kube-controller-manager-master2 1/1 Running 0 15m
kube-proxy-8ncqw 1/1 Running 0 46m
kube-proxy-px5dt 1/1 Running 0 15m
kube-scheduler-master1 1/1 Running 0 45m
kube-scheduler-master2 1/1 Running 0 15m
weave-net-ksvxz 2/2 Running 1 15m
weave-net-lvwrp 2/2 Running 0 41mЗамечательно! Мы почти закончили конфигурацию кластера Kubernetes. И последнее, что нужно сделать, это добавить три рабочих ноды, которые мы подготовили ранее.
Войдите в рабочие ноды и выполните команду kubeadm join без флажка --experimental-control-plane.
worker1-3# kubeadm join 192.168.0.1:6443 --token aasuvd.kw8m18m5fy2ot387 --discovery-token-ca-cert-hash sha256:dcbaeed8d1478291add0294553b6b90b453780e546d06162c71d515b494177a6Еще раз проверим состояние кластера:
master1# kubectl --kubeconfig /etc/kubernetes/admin.conf get nodes
NAME STATUS ROLES AGE VERSION
master1 Ready master 1h30m v1.13.1
master2 Ready master 1h59m v1.13.1
worker1 Ready <none> 1h8m v1.13.1
worker2 Ready <none> 1h8m v1.13.1
worker3 Ready <none> 1h7m v1.13.1Как видите, у нас есть полностью настроенный HA-кластер Kubernetes с двумя мастер- и тремя рабочими нодами. Он построен на основе кластера HA etcd с отказоустойчивым балансировщиком нагрузки перед мастер-нодами. Как по мне, звучит неплохо.
7. Настройка удаленного управления кластером
Еще одно действие, которое осталось рассмотреть в этой — первой — части статьи, это настройка удаленной утилиты kubectl для управления кластером. Ранее мы запускали все команды с мастер-ноды master1, но это подходит только для первого раза — при настройке кластера. Было бы неплохо настроить внешнюю ноду управления. Для этого можно использовать ноутбук или другой сервер.
Войдите на этот сервер и запустите:
Add the Google repository key
control# curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add -
Add the Google repository
control# cat <<EOF >/etc/apt/sources.list.d/kubernetes.list
deb https://apt.kubernetes.io/ kubernetes-xenial main
EOF
Update and install kubectl
control# apt-get update && apt-get install -y kubectl
In your user home dir create
control# mkdir ~/.kube
Take the Kubernetes admin.conf from the master1 node
control# scp 192.168.0.5:/etc/kubernetes/admin.conf ~/.kube/config
Check that we can send commands to our cluster
control# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master1 Ready master 6h58m v1.13.1
master2 Ready master 6h27m v1.13.1
worker1 Ready <none> 5h36m v1.13.1
worker2 Ready <none> 5h36m v1.13.1
worker3 Ready <none> 5h36m v1.13.1Хорошо, а теперь запустим тестовый под в нашем кластере и проверим, как он работает.
control# kubectl create deployment nginx --image=nginx
deployment.apps/nginx created
control# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-5c7588df-6pvgr 1/1 Running 0 52sПоздравляю! Вы только что задеплоили Kubernetes. И это означает, что ваш новый HA-кластер готов. На самом деле, процесс настройки кластера Kubernetes с использованием kubeadm довольно простой и быстрый.
В следующей части статьи добавим внутреннее хранилище, настроив GlusterFS на всех рабочих нодах, настроим внутренний балансировщик нагрузки для нашего кластера Kubernetes, а также запустим определенные стресс-тесты, отключив кое-какие ноды, и проверим кластер на стабильность.
Послесловие
Да, работая по данному примеру, вы столкнетесь с рядом проблем. Волноваться не надо: чтобы отменить изменения и вернуть ноды в исходное состояние, просто запустите kubeadm reset — изменения, которые kubeadm внес ранее, сбросятся, и можно настраиваться заново. Также не забудьте проверить состояние Docker-контейнеров на нодах кластера — убедитесь, что все они запускаются и работают без ошибок. Для дополнительной информации о поврежденных контейнерах используйте команду docker logs containerid.
На сегодня все. Удачи!
