
Фото с сайта Unsplash.com
Успешные постмортемы без поиска виноватых помогают учиться на инцидентах, чтобы не допускать подобных ошибок в будущем.
Постмортем — это сам и процесс, и его результат, то есть документ, где вы описываете инцидент, его разрешение и меры, которые можно принять, чтобы такого больше не повторилось.
Зачем нужен постмортем?
Ваша система включает не только информационные технологии, но и элементы реального мира — вас и ваших коллег, начальника, пользователей, вендоров, пространство и, самое ужасное, — время.
Это такая сложная структура, что почти невозможно предотвратить или хотя бы спрогнозировать сбои.
Раз инциденты будут возникать в любом случае, они должны приносить пользу, а не вред.
«В каком-то смысле, неопределенность, беспорядок, ошибки и время идут на пользу антихрупким системам…»
Antifragile, Nassim Nicholas Taleb (2012)
При сбое мы узнаем о системе что-то новое, особенно о скрытых связях между компонентами.
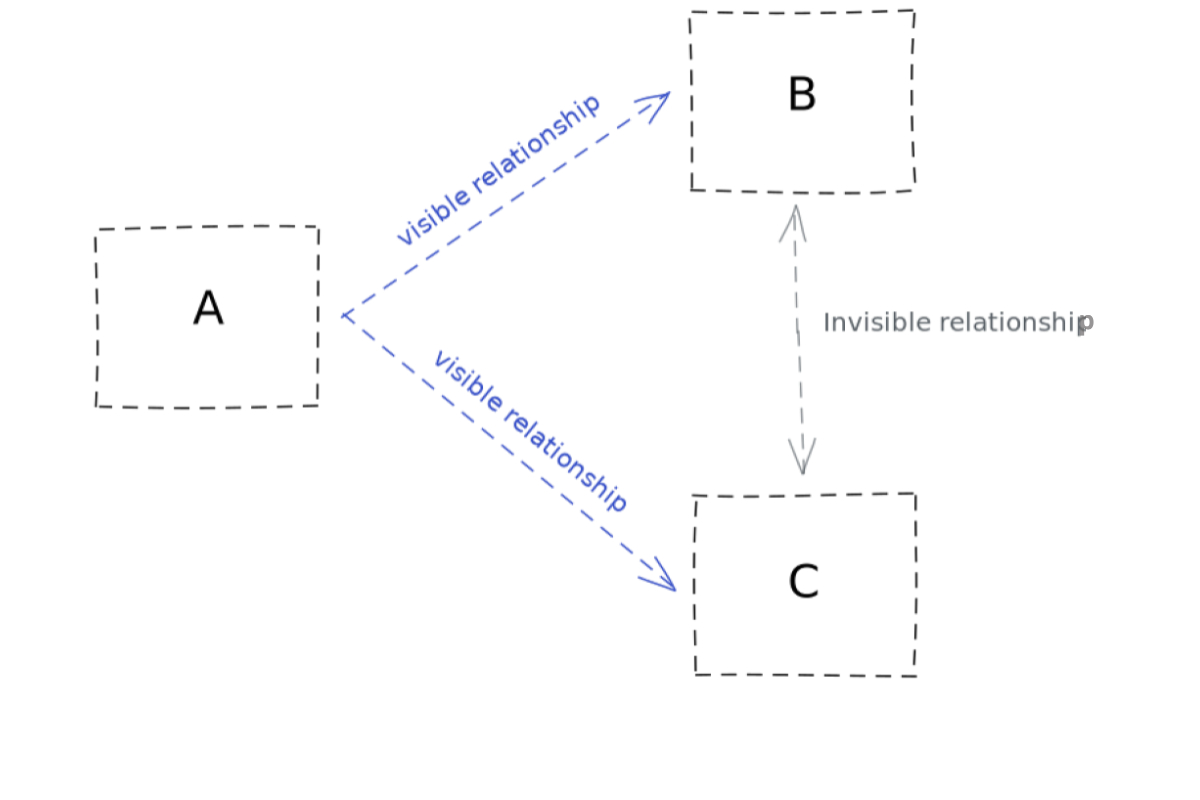
Допустим, у нас есть простая система с тремя компонентами (A, B и C) со следующими свойствами:
- A связан с B;
- A связан с C;
- между B и C никаких связей не наблюдается;
- любой процесс, порожденный A, открывает соединение с B и C.
Вот как выглядит эта схема:

Внезапно B начинает тормозить. В результате A поддерживает много открытых соединений с C, пока тот не начинает отказываться от новых входящих соединений. A не может открывать новые соединения с C и тоже начинает сбоить.
Мы открыли скрытую связь между B и C. Вот как выглядит новая схема:
В идеале результатом постмортема будет документ, где описано, что нужно изменить в системе, чтобы проблема не повторилась.
А если она будет повторяться, нужно описать, как смягчить ее последствия и ускорить разрешение.
Когда проводить постмортем
Когда в системе происходит достаточно серьезный инцидент.
В теории — любой инцидент. На практике вам вряд ли хватит ресурсов, поэтому начните с инцидентов, которые напрямую влияют на клиентов и стейкхолдеров.
Приступайте к делу как можно раньше, лучше даже на этапе разрешения, пока события еще свежи в памяти.
Что нужно делать
Опишите, что произошло. Четко сформулируйте последствия инцидента:
- Кто?
- Что?
- Как долго?
Составьте хронику событий и коммуникаций между участниками по поводу инцидента.
Попробуйте найти первопричину, если с ней можно что-то сделать:
- пять почему;
- практичность важнее «истины»;
- процесс поиска первопричины нужно документировать.
«Между истиной и практической пользой есть важное различие».
Data & Reality, William Kent (1978)
Привлеките всю команду, если это возможно, — чем больше голов, тем лучше. Вместе учитесь на ошибках и попытайтесь устранить инцидент, пока он не пошел дальше.
«Решайте проблемы коллективно, чтобы быстро учиться новому».
The DevOps Handbook, Gene Kim, Jez Humble, Patrick Debois, John Willis (2006)
Предложите улучшение для системы
Если это случится снова:
- Запишите меры по устранению, чтобы в следующий раз все сделать быстрее.
- Что можно сделать, чтобы свести последствия к минимуму?
Обращайте внимание на поток информации, фидбэк и задержки в коммуникациях:
- Мы вовремя узнали об инциденте?
- Все нужные люди получили уведомление?
- Нужные подсистемы (например, автомасштабирование) получили нужный фидбэк?
«Измените длительность задержки, и поведение всей системы может серьезно измениться».
Thinking in Systems, Donella H. Meadows (2008)
Чего не нужно делать
Никого не обвиняйте
Если мы будем тыкать друг в друга пальцами, люди станут скрывать информацию, и весь процесс развалится.
Не копайте слишком глубоко
Между вашей системой и остальным миром нет четкой границы — они плавно перетекают друг в друга. В поисках первопричины возникает искушение зайти слишком далеко — в область, которую вы не контролируете. Вы потратите ресурсы попусту.
Что делать с документом?
Главная цель — извлечь урок для себя и своей организации. Документы по постмортему должны быть:
- доступны для поиска;
- открыты максимально широкой аудитории (без раскрытия конфиденциальной информации);
- понятны аудитории (инженерам, стейкхолдерам, пользователям и т. д.).
Для вдохновения
Вот список общедоступных (и подробных) постмортемов:
