
Исторически во многих уголках Яндекса разрабатывались свои системы хранения и обработки больших объемов данных — с учетом специфики конкретных проектов. При такой разработке в приоритете всегда была эффективность, масштабируемость и надежность, поэтому на удобные интерфейсы для использования подобных систем времени, как правило, не оставалось. Полтора года назад разработку крупных инфраструктурных компонентов выделили из продуктовых команд в отдельное направление. Цели были следующими: начать двигаться быстрее, уменьшить дублирование среди схожих систем и снизить порог входа новых внутренних пользователей.

Очень скоро мы поняли, что тут мог бы здорово помочь общий высокоуровневый язык запросов, который бы предоставлял единообразный доступ к уже имеющимся системам, а также избавлял от необходимости заново реализовывать типовые абстракции на низкоуровневых примитивах, принятых в этих системах. Так началась разработка Yandex Query Language (YQL) — универсального декларативного языка запросов к системам хранения и обработки данных. (Сразу скажу, что мы знаем, что это уже не первая штука в мире, которая называется YQL, но мы решили, что это делу не мешает, и оставили название.)
В преддверии нашей встречи, которая будет посвящена инфраструктуре Яндекса, мы решили рассказать о YQL читателям Хабрахабра.
Мы, конечно, могли бы взглянуть в сторону популярных в мире open source-экосистем — таких как Hadoop или Spark. Но всерьез они даже не рассматривались. Дело в том, что требовалась поддержка уже распространенных в Яндексе хранилищ данных и вычислительных систем. Во многом из-за этого YQL был спроектирован и реализован расширяемым на любом из уровней. Все уровни мы по очереди разберем ниже.
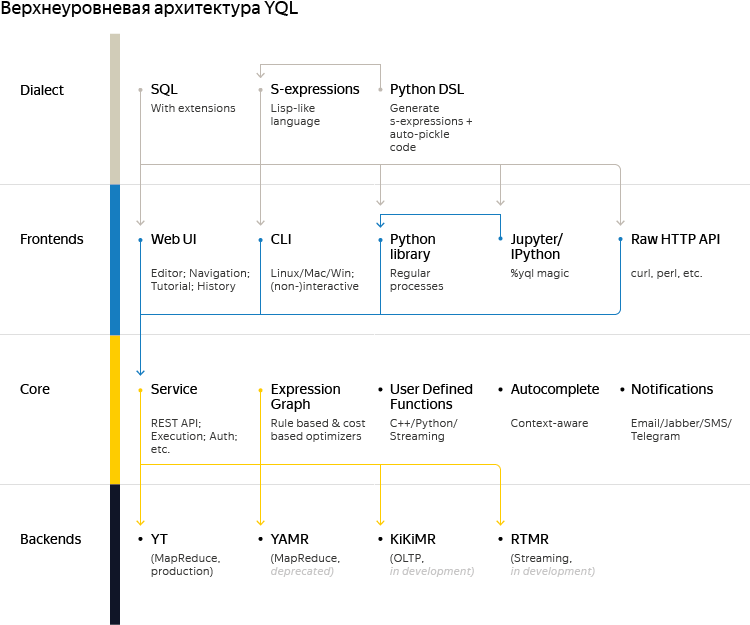
На диаграмме пользовательские запросы перемещаются сверху вниз, но обсуждать затрагиваемые элементы мы будем в обратном порядке, cнизу вверх, чтобы рассказ получился более связным. Для начала пару слов о поддерживаемых на данный момент бэкендах или, как мы их называем, провайдерах данных:
Технически YQL, хоть он и состоит из относительно изолированных компонентов и библиотек, внутренним пользователям предоставляется в первую очередь как сервис. Это позволяет выглядеть с их точки зрения «службой одного окна» и минимизировать трудозатраты на организационные вопросы вроде выдачи доступов или настроек фаервола для каждого из бэкендов. Кроме того, обе реализации классического MapReduce в Яндексе требуют наличия синхронно ожидающего завершения транзакции клиентского процесса, а сервис YQL берет это на себя и позволяет пользователям работать в режиме «запустил изабыл пришел за результатами позже». Но если сравнить модель предоставления сервиса с распространением в виде библиотеки, минусы тоже найдутся. Например, следует гораздо более аккуратно относиться к несовместимым изменениям и релизам — иначе можно в самый неподходящий момент сломать пользовательские процессы.
Основной точкой входа в сервис YQL является HTTP REST API, который реализован как Java-приложение на Netty и не только занимается запуском поступающих запросов на вычисление, но и имеет широкий спектр вспомогательных обязанностей:
Использование Java позволило достаточно быстро реализовать всю эту бизнес-логику благодаря наличию готовых асинхронных клиентов для всех нужных систем. Поскольку слишком строгих требований по latency пока нет, то проблем со сборкой мусора было мало, а после перехода на G1 они практически исчезли. Еще, помимо упомянутого выше, для синхронизации между узлами используется ZooKeeper, в том числе в паттерне publisher-subscriber при отправке уведомлений.
Само выполнение пользовательских запросов на вычисление оркестрируется отдельными процессами на С++ под названием yqlworker. Они могут быть запущены как на тех же машинах, что и REST API, так и удаленно. Дело в том, что между ними идет общение по сети с помощью разработанного и широко распространенного в Яндексе протокола MessageBus. Под каждый запрос с помощью системного вызова fork (без exec) создается копия yqlworker. Такая схема позволяет достичь достаточной изоляции между запросами разных пользователей и при этом — благодаря механизму copy-on-write — не потратить время на инициализацию.
Как видно из диаграммы с высокоуровневой архитектурой, Yandex Query Language имеет два представления:
Из запроса, вне зависимости от выбранного синтаксиса, создается граф вычислений (Expression Graph), который логически описывает необходимую обработку данных с использованием примитивов, популярных в функциональном программировании. К таким примитивам относятся: λ-функции, отображение (Map и FlatMap), фильтрация (Filter), свёртка (Fold), сортировка (Sort), применение (Apply) и многие другие. Для SQL-синтаксиса лексер и парсер, основанные на ANTLR v3, строят Abstract Syntax Tree, по которому затем строится граф вычислений. Для синтаксиса s-expression парсер практически тривиален, поскольку грамматика крайне проста, а программы и так оперируют этими абстракциями.
Далее для получения требуемого результата запрос проходит через несколько стадий, при необходимости возвращаясь к уже пройденным:
На любой из стадий жизни запроса он может быть сериализован обратно в синтаксисе s-expressions, что крайне удобно для диагностики и понимания происходящего.
Как упоминалось во введении, одним из ключевых требований к YQL являлось удобство использования. Поэтому публичным интерфейсам уделяется особое внимание и они крайне активно развиваются.
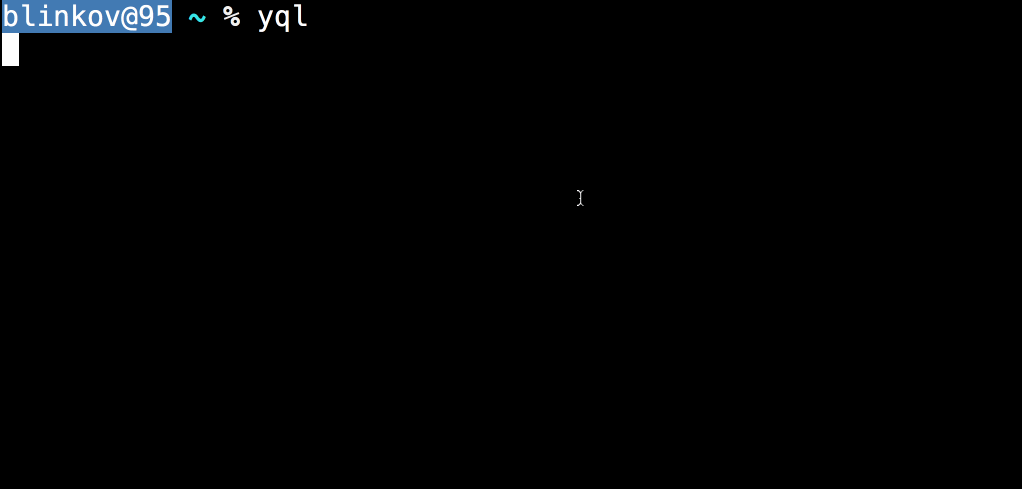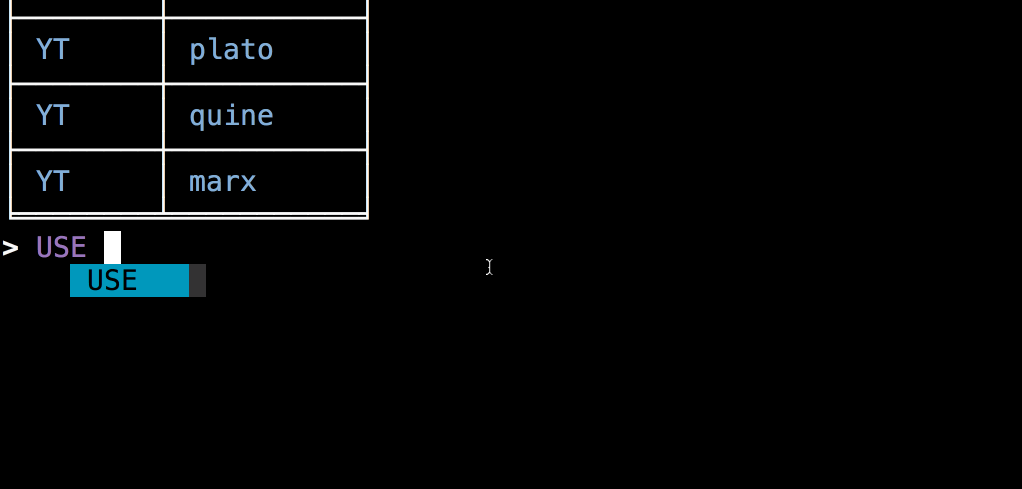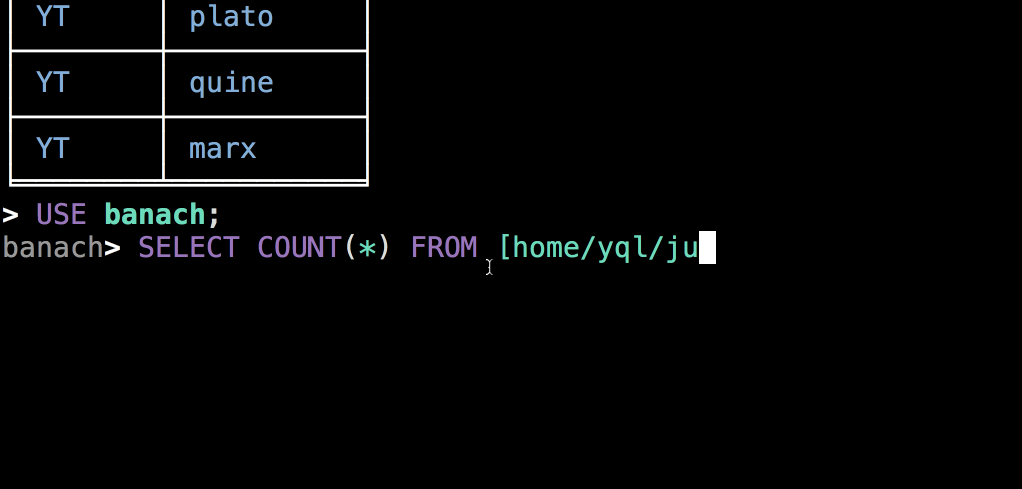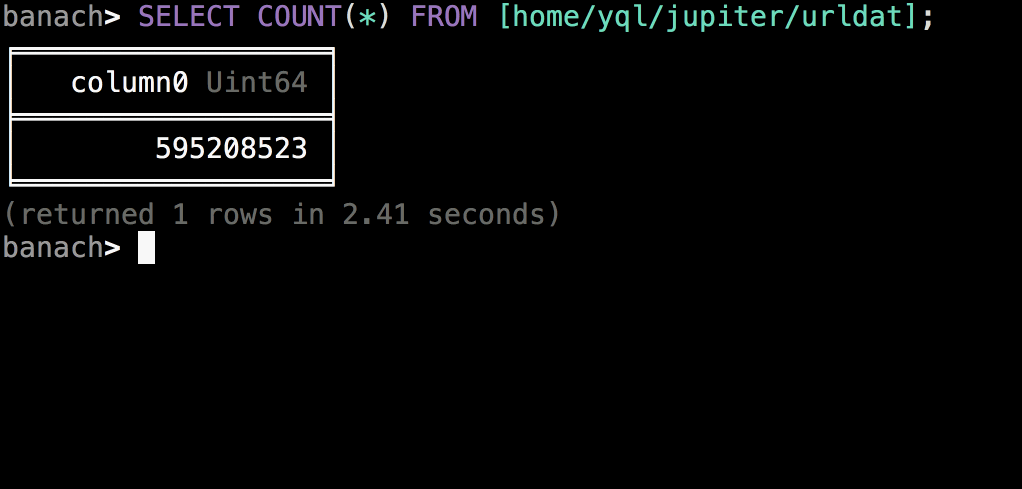
На картинке показан интерактивный режим с автодополнением, подсветкой синтаксиса, цветовыми темами, уведомлениями и прочими украшательствами. Но консольный клиент может запускаться и в режиме ввода-вывода из файлов или стандартных потоков, что позволяет интегрировать его в произвольные скрипты и регулярные процессы. Есть как синхронный, так и асинхронный запуск операций, просмотр плана запроса, прикрепление локальных файлов, навигация по кластерам и прочие основные возможности.
Такая богатая функциональность появилась по двум причинам. С одной стороны, в Яндексе есть заметный пласт людей, предпочитающих работать преимущественно в консоли. С другой, это было сделано, чтобы выиграть время на разработку полнофункционального веб-интерфейса, о котором мы еще поговорим.
Любопытный технический нюанс: консольный клиент реализован на Python, но распространяется как статически слинкованное нативное приложение без зависимостей со встроенным интерпретатором, которое компилируется под Linux, OS X и Windows. Кроме того, он умеет автоматически самостоятельно обновляться — примерно как современные браузеры. Все это было достаточно просто организовать благодаря внутренней инфраструктуре Яндекса для сборки кода и подготовки релизов.
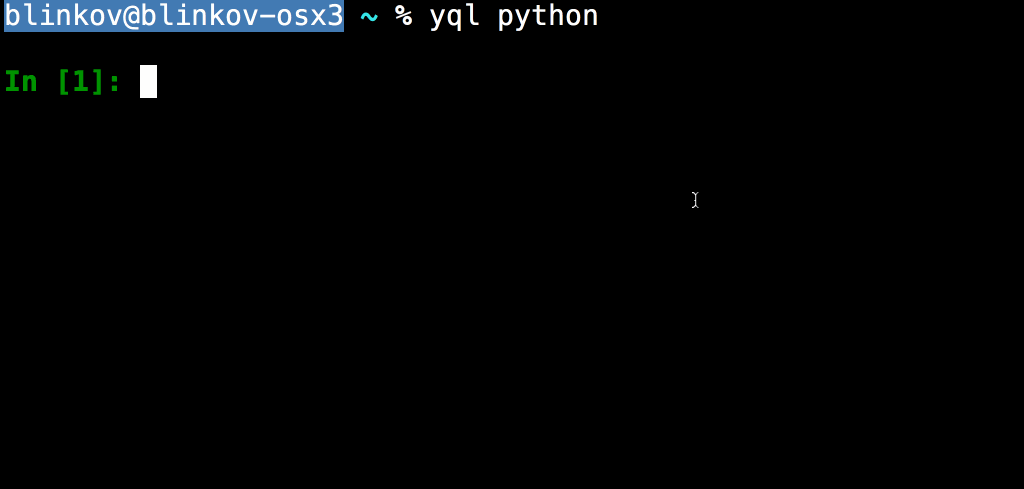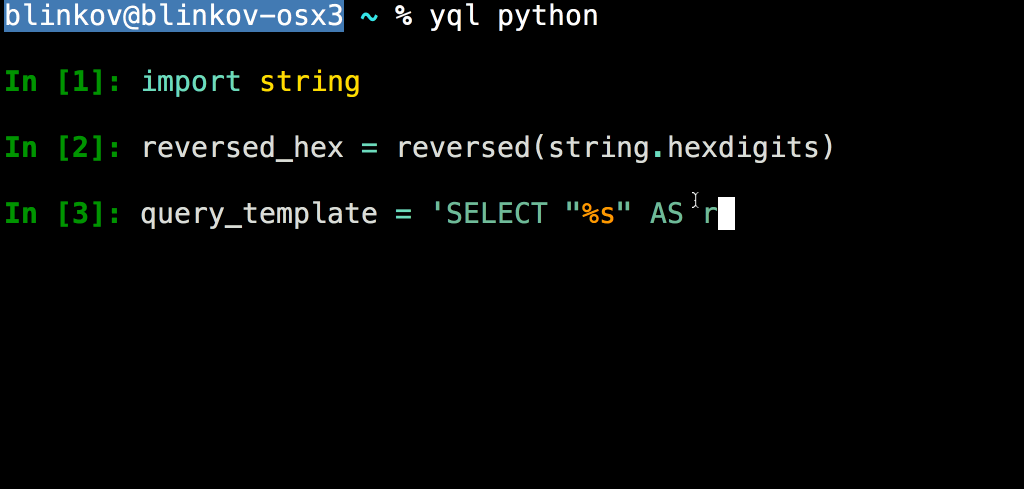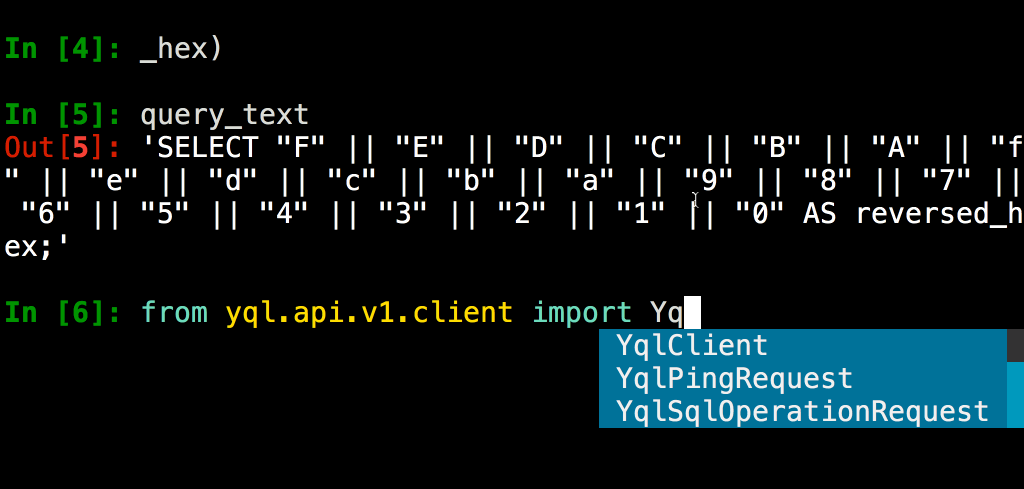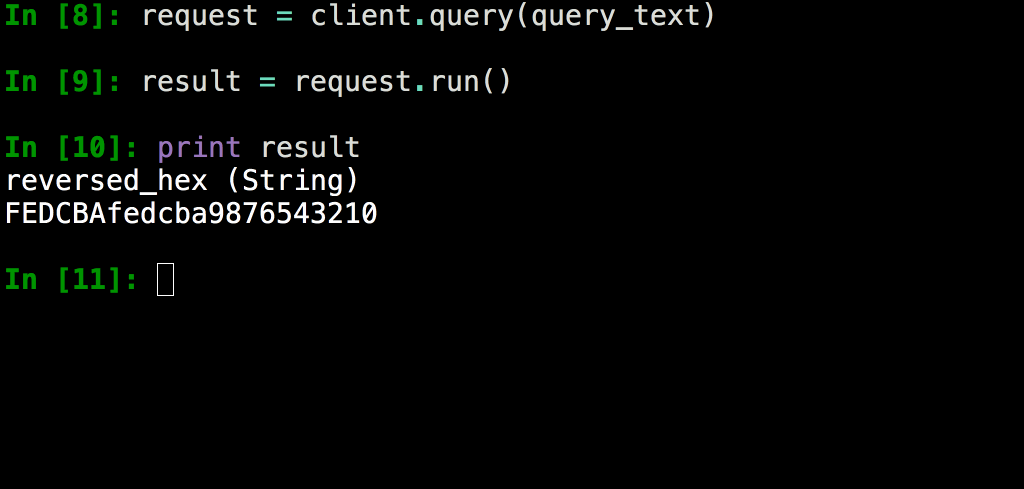
Python является вторым по распространенности языком программирования в Яндексе после C++,поэтому клиентская библиотека YQL реализована именно на нем. На самом деле она изначально разрабатывалась как часть консольного клиента, а затем была выделена в независимый продукт, чтобы появилась возможность использовать ее в других Python-окружениях, не изобретая аналогичный код заново.
Например, многие аналитики любят работать в среде Jupyter, для которой на основе данной клиентской библиотеки был создан так называемый %yql magic:

Вместе с консольным клиентом поставляются две специальные подпрограммы, которые запускают преднастроенный Jupyter или IPython с уже доступной клиентской библиотекой. Именно онии показаны выше.
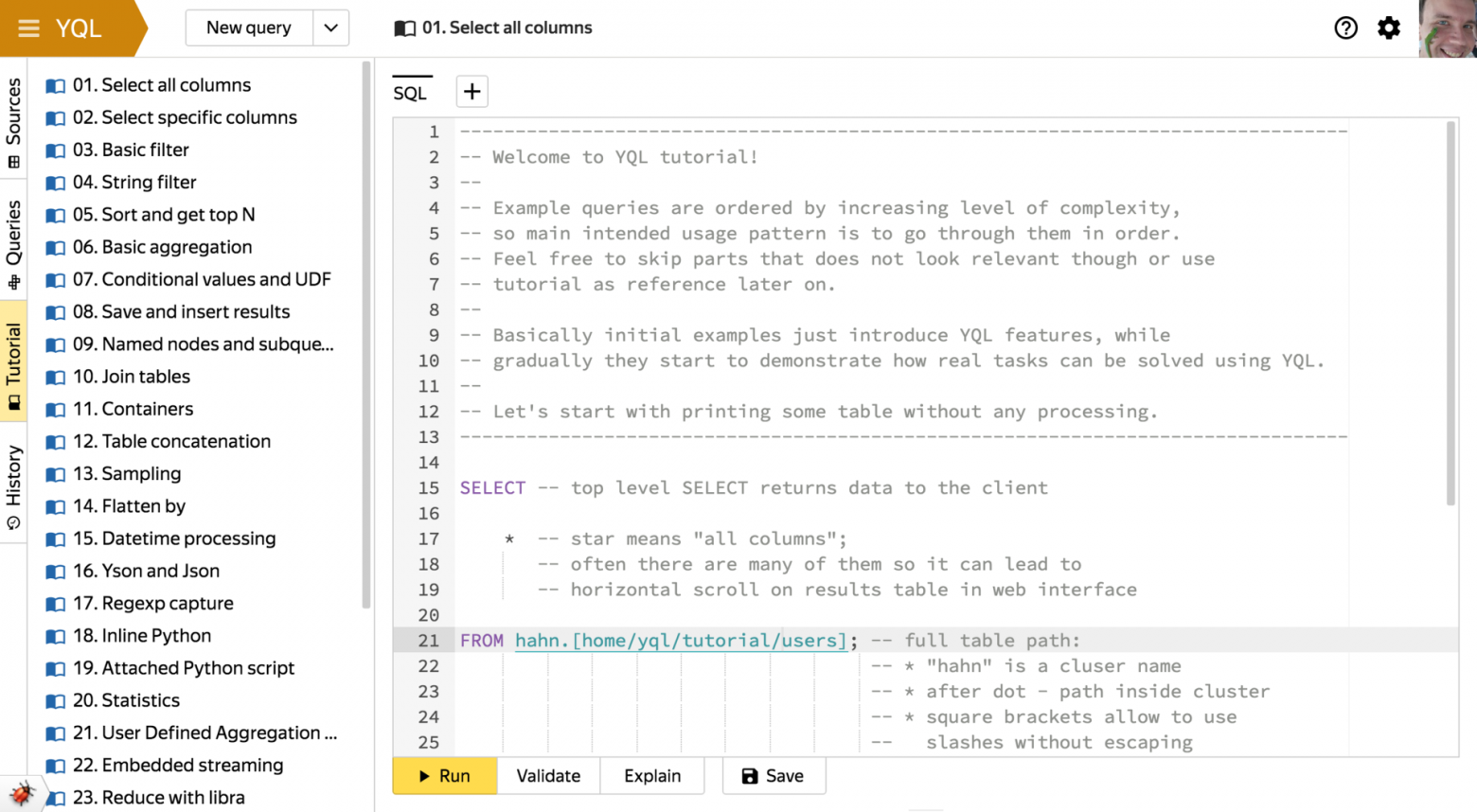
Основной инструмент изучения языка YQL, разработки запросов и аналитики мы оставили на закуску. В веб-интерфейсе, благодаря отсутствию технических ограничений консоли, все функции YQL доступны в более наглядной форме и всегда находятся под рукой. Часть возможностей интерфейса показана на примерах других экранов:
Все ручки в самом REST API аннотируются по коду, и на основе этих аннотаций с помощью Swagger автоматически генерируется подробная онлайн-документация. Из нее можно попробовать позадавать запросы без единой строчки кода. Это позволяет легко использовать YQL, даже если перечисленные выше готовые варианты по каким-то причинам не подошли. Например — если вы любите Perl.
Настала пора поговорить о том, какого плана задачи можно решать с помощью Yandex Query Language и какие возможности предоставляются пользователям. Эта часть будет скорее тезисной, чтобы не удлинять и без того длинный пост.
Не все виды преобразований данных удобно выражать декларативно. Иногда проще написать цикл или воспользоваться какой-нибудь готовой библиотекой. Для таких ситуаций YQL предоставляет механизм пользовательских функций, они же User Defined Functions, они же UDF:
Внутри у агрегационных функций используется общий фреймворк с поддержкой
Из соображений производительности, в терминах MapReduce для агрегационных функций автоматически создается Map-side Combiner с объединением промежуточных результатов агрегации в Reduce.
Слияние таблиц по ключам — одна из самых популярных операций, которая часто нужна для решения задач, но правильно реализовать которую в терминах MapReduce — почти целая наука. Логически в Yandex Query Language доступны все стандартные режимы плюс несколько дополнительных:
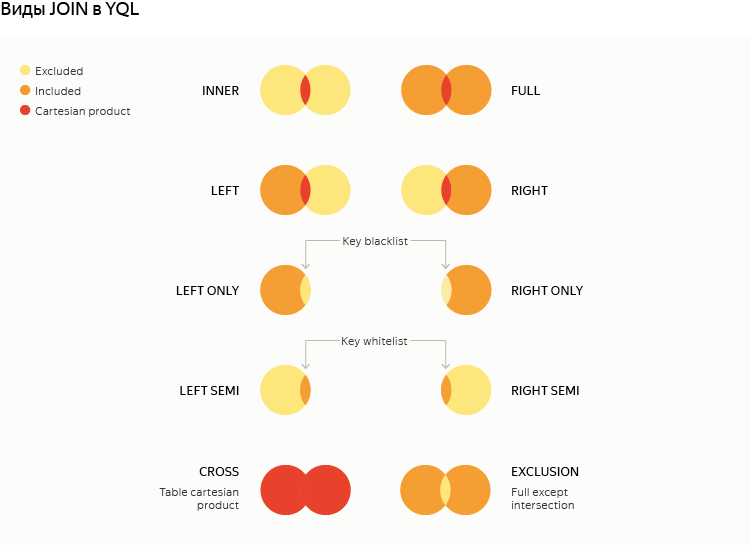
Чтобы скрыть детали от пользователей, для бэкендов, основанных на MapReduce, стратегия выполнения JOIN выбирается на лету в зависимости от требуемого логического типа и физических свойств участвующих таблиц (это так называемая cost based optimization):
Среди наших ближайших и среднесрочных планов по Yandex Query Language:
Напоследок — еще раз приглашаем на встречу в нашем офисе в ближайшую субботу, 15 октября, где мы подробнее расскажем о разных аспектах инфраструктуры Яндекса.

Очень скоро мы поняли, что тут мог бы здорово помочь общий высокоуровневый язык запросов, который бы предоставлял единообразный доступ к уже имеющимся системам, а также избавлял от необходимости заново реализовывать типовые абстракции на низкоуровневых примитивах, принятых в этих системах. Так началась разработка Yandex Query Language (YQL) — универсального декларативного языка запросов к системам хранения и обработки данных. (Сразу скажу, что мы знаем, что это уже не первая штука в мире, которая называется YQL, но мы решили, что это делу не мешает, и оставили название.)
В преддверии нашей встречи, которая будет посвящена инфраструктуре Яндекса, мы решили рассказать о YQL читателям Хабрахабра.
Архитектура
Мы, конечно, могли бы взглянуть в сторону популярных в мире open source-экосистем — таких как Hadoop или Spark. Но всерьез они даже не рассматривались. Дело в том, что требовалась поддержка уже распространенных в Яндексе хранилищ данных и вычислительных систем. Во многом из-за этого YQL был спроектирован и реализован расширяемым на любом из уровней. Все уровни мы по очереди разберем ниже.
На диаграмме пользовательские запросы перемещаются сверху вниз, но обсуждать затрагиваемые элементы мы будем в обратном порядке, cнизу вверх, чтобы рассказ получился более связным. Для начала пару слов о поддерживаемых на данный момент бэкендах или, как мы их называем, провайдерах данных:
- Так сложилось, что в Яндексе уже больше пяти лет разрабатываются две реализации парадигмы MapReduce — YaMR и YT, о которой можно подробнее почитать в недавнем посте. Технически они не имеют почти ничего общего ни друг с другом, ни с Hadoop. Поскольку разработка систем такого класса — достаточно дорогое удовольствие, год назад было принято решение провести «MapReduce-тендер». YT победил, и сейчас пользователи YaMR заканчивают на него переходить. Разработка YQL началась почти одновременно со стартом тендера, поэтому одним из основных требований стала поддержка и YT, и YaMR, которую нужно было реализовать для облегчения жизни пользователей в переходный период.
- Про RTMR (Real Time MapReduce) тоже когда-то был отдельный пост. Его поддержка сейчас находится на ранней стадии разработки. Во-первых, этот проект по интеграции позволит новым пользователям внедрять RTMR без спецподготовки. Во-вторых, они смогут единообразно анализировать как поток свежих данных, так и архив, собранный за длительный период и находящийся в распределенной файловой системе YT.
- В Яндексе систем хранения данных с OLTP-паттерном использования еще больше, чем основанных на парадигме MapReduce. В качестве пилотного проекта по интеграции с YQL среди них был выбран KiKiMR. Во многом такой выбор был сделан потому, что потребность в дружелюбном интерфейсе KiKiMR сформировалась в одно время с активным ростом популярности YQL. Еще одна причина была в наличии у команды KiKiMR ресурсов на этот проект. Детальный рассказ про KiKiMR здесь не уместить, но если вкратце, это распределенное отказоустойчивое strict consistent-хранилище данных, в том числе распределенное между дата-центрами. Оно может использоваться в инсталляциях, состоящих и из нескольких машин, и из тысяч узлов. Отличительной особенностью хранилища KiKiMR является встроенная возможность выполнять операции эффективно и транзакционно c уровнем изоляции serializable как над отдельными объектами (single-row transactions), так и над группами распределенных объектов хранилища (cross-row/cross-table transactions).
- Этот список содержит лишь то, что уже реализовано или находится в работе. В планах — расширять ассортимент поддерживаемых в YQL систем и дальше. Например, очень логичным развитием событий станет поддержка ClickHouse, которая сейчас несколько отложена лишь из-за ограниченности ресурсов и отсутствия острой необходимости.
Ядро
Технически YQL, хоть он и состоит из относительно изолированных компонентов и библиотек, внутренним пользователям предоставляется в первую очередь как сервис. Это позволяет выглядеть с их точки зрения «службой одного окна» и минимизировать трудозатраты на организационные вопросы вроде выдачи доступов или настроек фаервола для каждого из бэкендов. Кроме того, обе реализации классического MapReduce в Яндексе требуют наличия синхронно ожидающего завершения транзакции клиентского процесса, а сервис YQL берет это на себя и позволяет пользователям работать в режиме «запустил и
Основной точкой входа в сервис YQL является HTTP REST API, который реализован как Java-приложение на Netty и не только занимается запуском поступающих запросов на вычисление, но и имеет широкий спектр вспомогательных обязанностей:
- Несколько вариантов аутентификации.
- Просмотр списка доступных кластеров с бэкендами, а также списков таблиц и схем, навигация по ним.
- Репозиторий сохраненных пользователями запросов, а также история всех запусков (исторически живет в MongoDB, но возможно, в будущем это изменится).
- Уведомления о завершенных запросах:
- Рядом с REST API доступен WebSocket endpoint, с помощью которого пользовательские интерфейсы (о них поговорим чуть ниже) способны показывать всплывающие сообщения в реальном времени;
- Интеграция с внутренними сервисами для отправки писем, смс и сообщений в Jabber;
- Оповещения через бота в Telegram.
Использование Java позволило достаточно быстро реализовать всю эту бизнес-логику благодаря наличию готовых асинхронных клиентов для всех нужных систем. Поскольку слишком строгих требований по latency пока нет, то проблем со сборкой мусора было мало, а после перехода на G1 они практически исчезли. Еще, помимо упомянутого выше, для синхронизации между узлами используется ZooKeeper, в том числе в паттерне publisher-subscriber при отправке уведомлений.
Само выполнение пользовательских запросов на вычисление оркестрируется отдельными процессами на С++ под названием yqlworker. Они могут быть запущены как на тех же машинах, что и REST API, так и удаленно. Дело в том, что между ними идет общение по сети с помощью разработанного и широко распространенного в Яндексе протокола MessageBus. Под каждый запрос с помощью системного вызова fork (без exec) создается копия yqlworker. Такая схема позволяет достичь достаточной изоляции между запросами разных пользователей и при этом — благодаря механизму copy-on-write — не потратить время на инициализацию.
Как видно из диаграммы с высокоуровневой архитектурой, Yandex Query Language имеет два представления:
- Основной синтаксис базируется на SQL и предназначен для написания людьми.
- Синтаксис s-expressions, в свою очередь, более удобен для кодогенерации.
Из запроса, вне зависимости от выбранного синтаксиса, создается граф вычислений (Expression Graph), который логически описывает необходимую обработку данных с использованием примитивов, популярных в функциональном программировании. К таким примитивам относятся: λ-функции, отображение (Map и FlatMap), фильтрация (Filter), свёртка (Fold), сортировка (Sort), применение (Apply) и многие другие. Для SQL-синтаксиса лексер и парсер, основанные на ANTLR v3, строят Abstract Syntax Tree, по которому затем строится граф вычислений. Для синтаксиса s-expression парсер практически тривиален, поскольку грамматика крайне проста, а программы и так оперируют этими абстракциями.
Далее для получения требуемого результата запрос проходит через несколько стадий, при необходимости возвращаясь к уже пройденным:
- Типизация. YQL — принципиально строго типизированный язык. Доводов в пользу этого было много, начиная от корней в SQL, где подразумевается схематизация, и заканчивая более широким простором для ускорения — например, за счет генерации нативного кода на лету. Кроме простых типов данных, поддерживается несколько видов контейнеров (Optional, List, Dict, Tuple и Struct) и специальных типов, например непрозрачный указатель (Resource).
- Оптимизация. На этой стадии происходят не только эквивалентные преобразования, призванные сократить время выполнения. Помимо них выполняется приведение плана действий к виду, который бэкенд способен исполнить. В частности, логические операции, которые бэкенд может нативно выполнить, заменяются на физические. Таким образом, в YQL есть свой фреймворк для оптимизаторов, которые можно условно разделить на три категории:
- общие правила логических оптимизаций;
- общие правила, специфичные для конкретных бэкендов;
- оптимизации, выбирающие ту или иную стратегию выполнения в runtimе (к ним мы еще вернемся).
- Выполнение. Если после оптимизации не осталось ошибок, граф приобретает вид, выполнимый с использованием API бэкенда. Большую часть времени yqlworker именно это и делает. Оставшиеся в графе вычислений логические операции исполняются с помощью узкоспециализированного интерпретатора, по возможности — на вычислительных мощностях бэкендов.
На любой из стадий жизни запроса он может быть сериализован обратно в синтаксисе s-expressions, что крайне удобно для диагностики и понимания происходящего.
Интерфейсы
Как упоминалось во введении, одним из ключевых требований к YQL являлось удобство использования. Поэтому публичным интерфейсам уделяется особое внимание и они крайне активно развиваются.
Консольный клиент
На картинке показан интерактивный режим с автодополнением, подсветкой синтаксиса, цветовыми темами, уведомлениями и прочими украшательствами. Но консольный клиент может запускаться и в режиме ввода-вывода из файлов или стандартных потоков, что позволяет интегрировать его в произвольные скрипты и регулярные процессы. Есть как синхронный, так и асинхронный запуск операций, просмотр плана запроса, прикрепление локальных файлов, навигация по кластерам и прочие основные возможности.
Такая богатая функциональность появилась по двум причинам. С одной стороны, в Яндексе есть заметный пласт людей, предпочитающих работать преимущественно в консоли. С другой, это было сделано, чтобы выиграть время на разработку полнофункционального веб-интерфейса, о котором мы еще поговорим.
Любопытный технический нюанс: консольный клиент реализован на Python, но распространяется как статически слинкованное нативное приложение без зависимостей со встроенным интерпретатором, которое компилируется под Linux, OS X и Windows. Кроме того, он умеет автоматически самостоятельно обновляться — примерно как современные браузеры. Все это было достаточно просто организовать благодаря внутренней инфраструктуре Яндекса для сборки кода и подготовки релизов.
Python-библиотека
Python является вторым по распространенности языком программирования в Яндексе после C++,
Например, многие аналитики любят работать в среде Jupyter, для которой на основе данной клиентской библиотеки был создан так называемый %yql magic:
Вместе с консольным клиентом поставляются две специальные подпрограммы, которые запускают преднастроенный Jupyter или IPython с уже доступной клиентской библиотекой. Именно онии показаны выше.
Веб-интерфейс
Основной инструмент изучения языка YQL, разработки запросов и аналитики мы оставили на закуску. В веб-интерфейсе, благодаря отсутствию технических ограничений консоли, все функции YQL доступны в более наглядной форме и всегда находятся под рукой. Часть возможностей интерфейса показана на примерах других экранов:
- Автодополнение и просмотр схемы таблиц
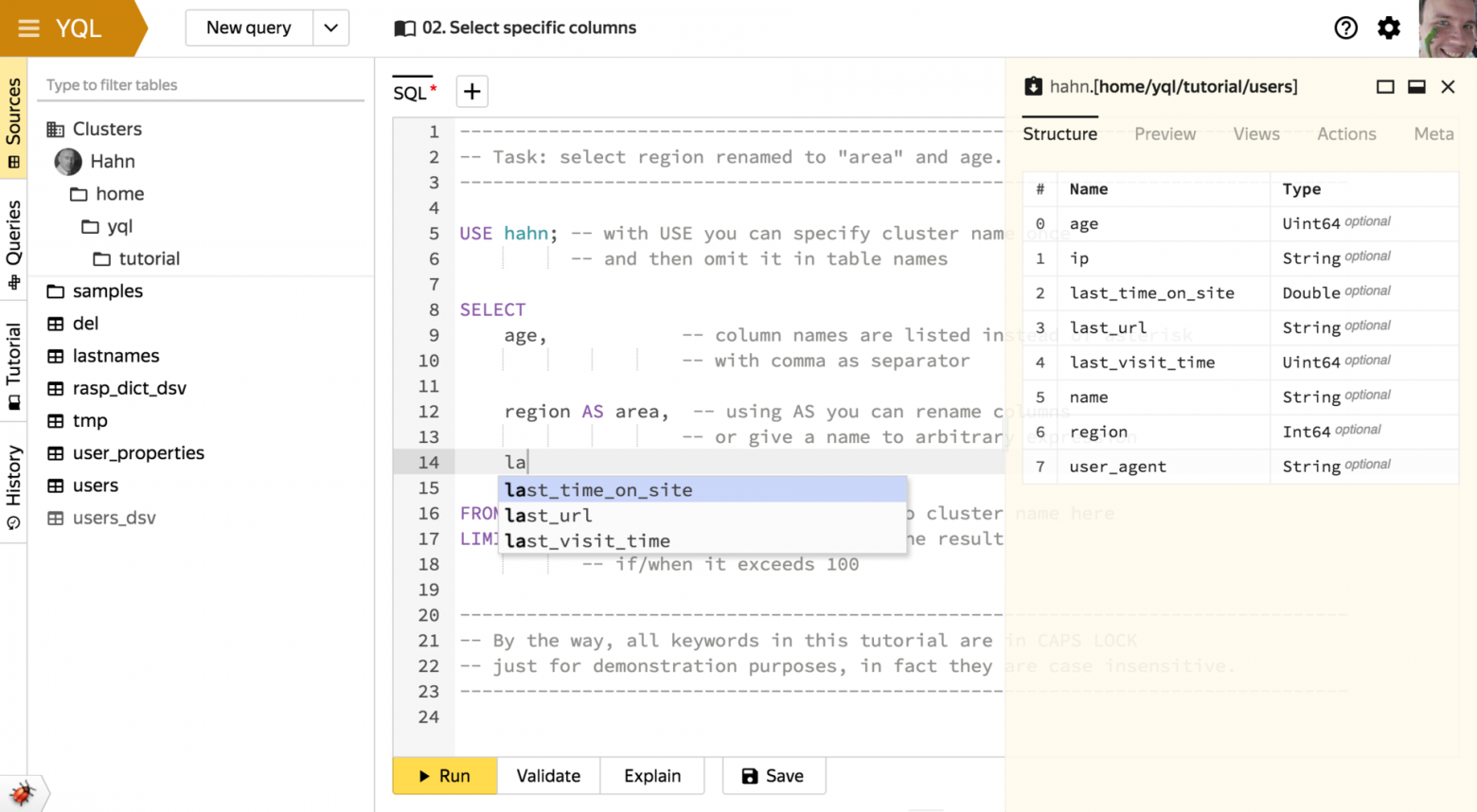
Логика автодополнения запросов у консольного клиента и веб-интерфейса общая. Она умеет достаточно точно учитывать контекст, в котором происходит ввод. Это позволяет ей подсказывать только релевантные ключевые слова или имена таблиц, колонок и функций, а не всё подряд.
- Работа с сохраненными запросами
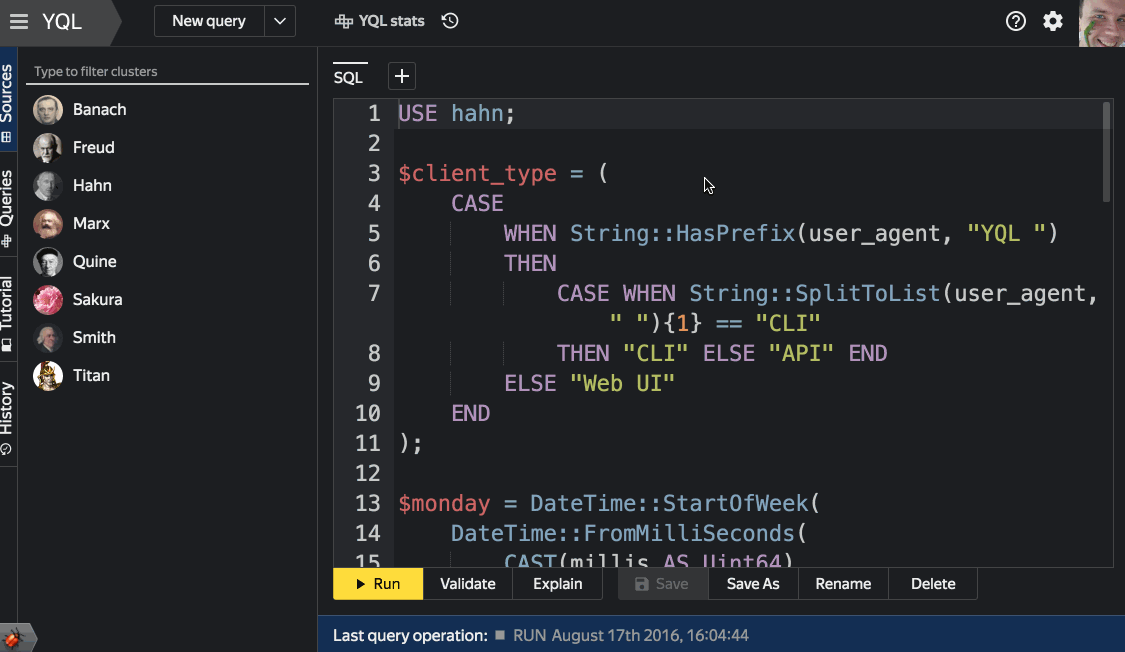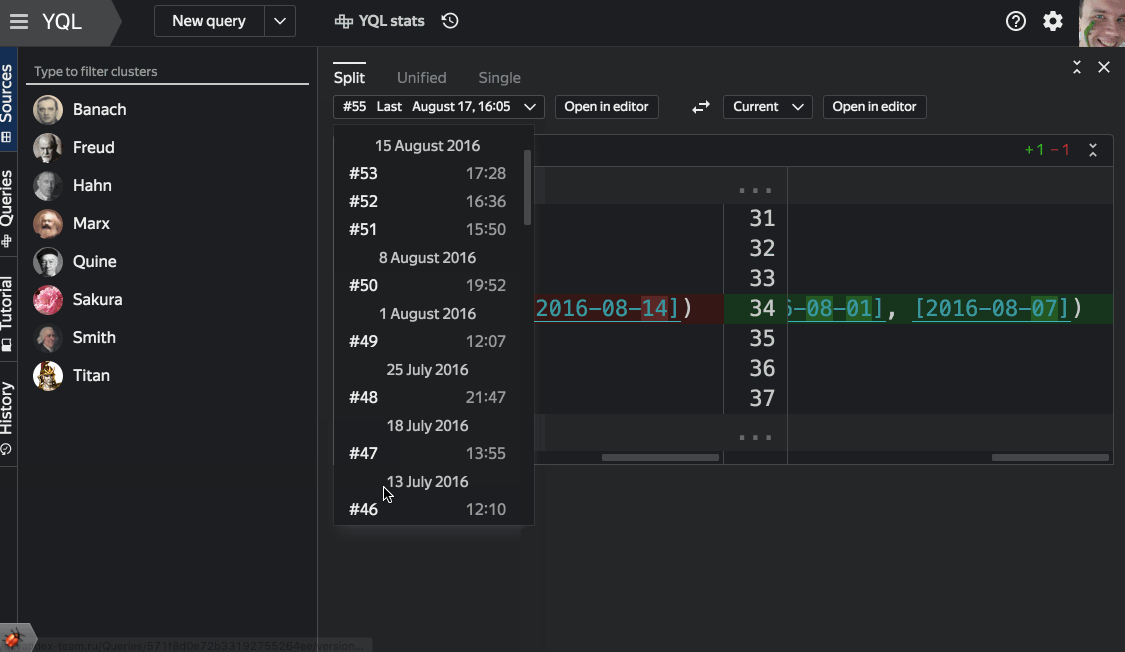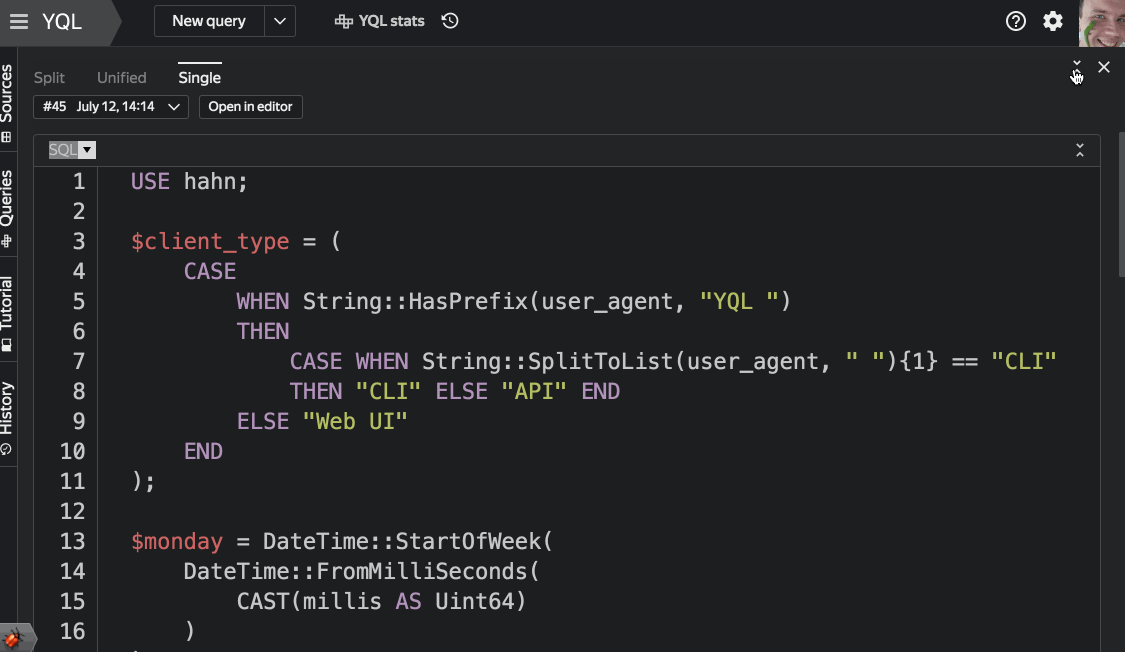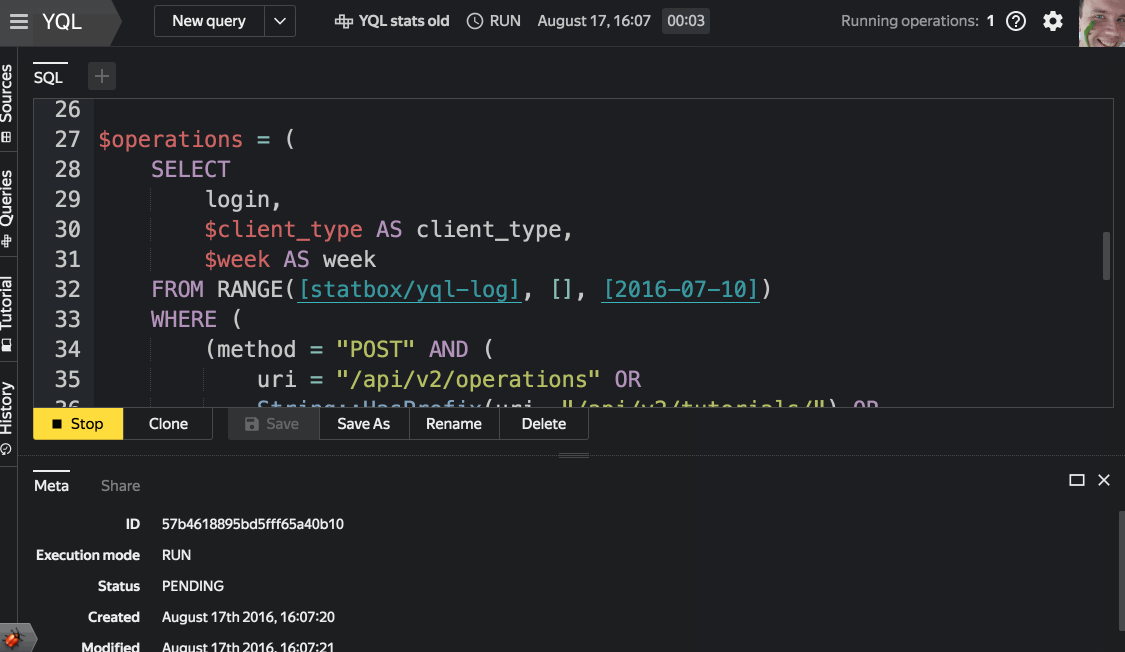
При сохранении запроса под именем они попадают в мини-аналог репозитория кода с возможностью просмотра истории и возврата к предыдущим версиям.
- План выполнения запроса

Здесь показана наиболее простая и универсальная реализация JOIN в терминах MapReduce.
… и не только
Все ручки в самом REST API аннотируются по коду, и на основе этих аннотаций с помощью Swagger автоматически генерируется подробная онлайн-документация. Из нее можно попробовать позадавать запросы без единой строчки кода. Это позволяет легко использовать YQL, даже если перечисленные выше готовые варианты по каким-то причинам не подошли. Например — если вы любите Perl.
Возможности
Настала пора поговорить о том, какого плана задачи можно решать с помощью Yandex Query Language и какие возможности предоставляются пользователям. Эта часть будет скорее тезисной, чтобы не удлинять и без того длинный пост.
SQL
- Основной диалект YQL основан на стандарте SQL:1992 с вкраплениями из более новых редакций. Все основные конструкции поддерживаются, но полная совместимость в тонкостях, которые оказались не очень востребованы, — еще в разработке. Благодаря этому многим новым пользователям, которые раньше работали с какими-либо базами данных с SQL-интерфейсом, приходится изучать язык далеко не с нуля.
- На бэкендах, работающих в парадигме MapReduce, целевые таблицы (для простоты) создаются автоматически. Запросы чаще всего состоят из
SELECTпроизвольного уровня сложности и опционально содержатINSERT INTO. - В OLTP-сценариях доступны полноценные DDL (
CREATE TABLE) и CRUD (плюсUPDATE,REPLACE,UPSERTиDELETE). - Для многих ситуаций, которые в стандартном SQL либо не поддерживаются, либо получились бы слишком громоздкими, в YQL добавлены различные расширения синтаксиса, например:
- Именованные выражения
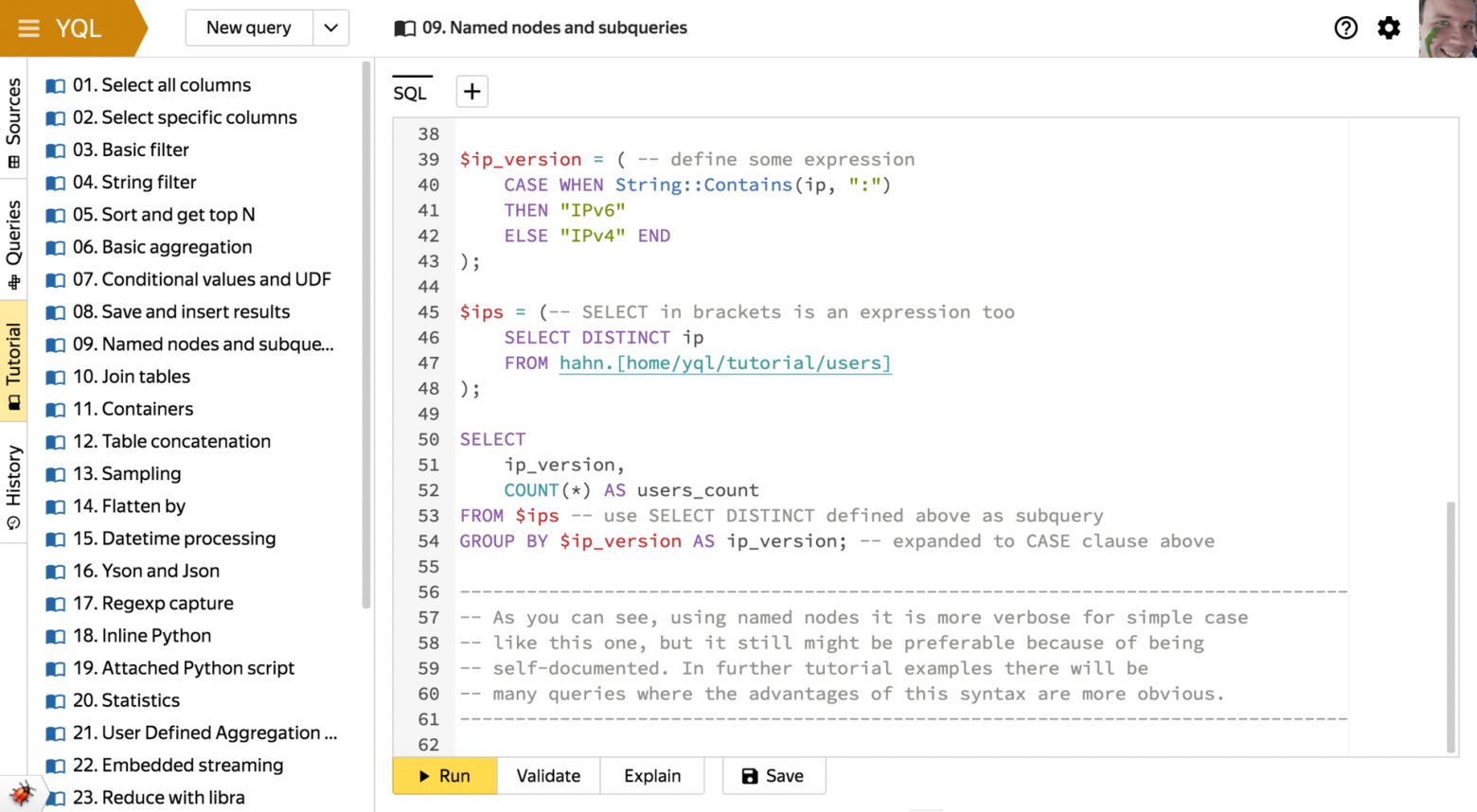
Позволяют при большом количестве уровней вложенности подзапросов писать их по очереди, а не в друг в друге по стандарту. Также они дают возможность не копипастить часто используемые выражения.
- Работа с типами-контейнерами

Доступен как синтаксис для получения элементов по ключу или индексу, так и набор специализированных встроенных функций.
FLATTEN BY
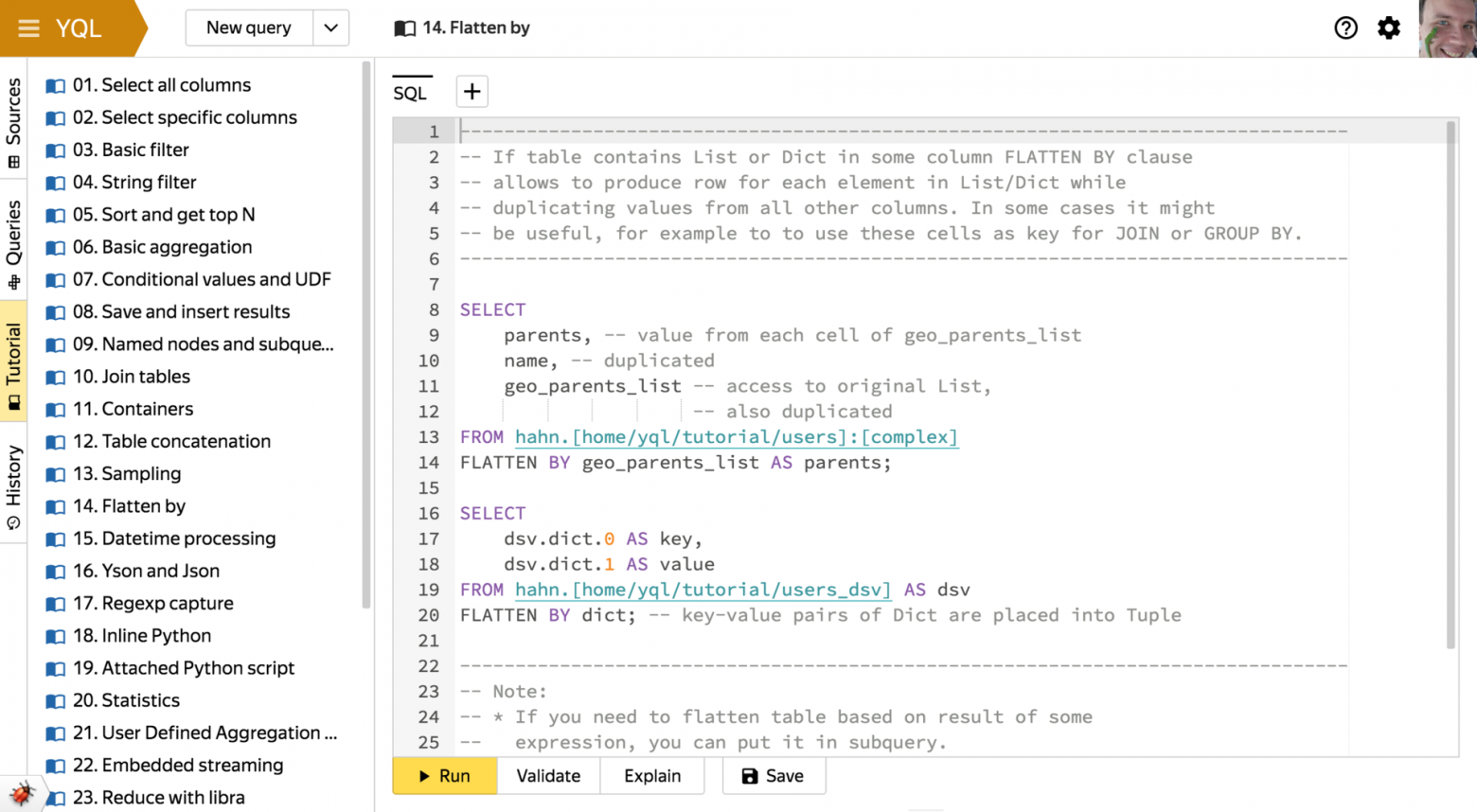
За этим ключевым словом закреплена возможность размножать строки исходной таблицы с вертикальным разворачиванием контейнеров (списков или словарей) переменной длины из колонки с соответствующим типом данных.
Звучит немного запутанно — проще показать на примере. Возьмем таблицу следующего вида:
Применив[a, b, c] 1 [d] 2 [] 3 FLATTEN BYк левой колонке, получим такую таблицу:
Подобное преобразование может быть удобным, когда по ячейкам из колонки-контейнера нужно посчитать какую-либо статистику (скажем, черезa 1 b 1 c 1 d 2 GROUP BY) или когда в ячейках содержатся идентификаторы из другой таблицы, с которой нужно сделатьJOIN.
Самое забавное воFLATTEN BYвот что: оно называется по-разному во всех системах, которые умеют так делать. Из того, что мы нашли, нет ни одного повтора:
ARRAY JOIN— ClickHouse,unnest— PostgreSQL,$unwind— MongoDB,LATERAL VIEW— Hive,FLATTEN— Google BigQuery.
- Явные
PROCESS(Map) иREDUCE(Reduce).
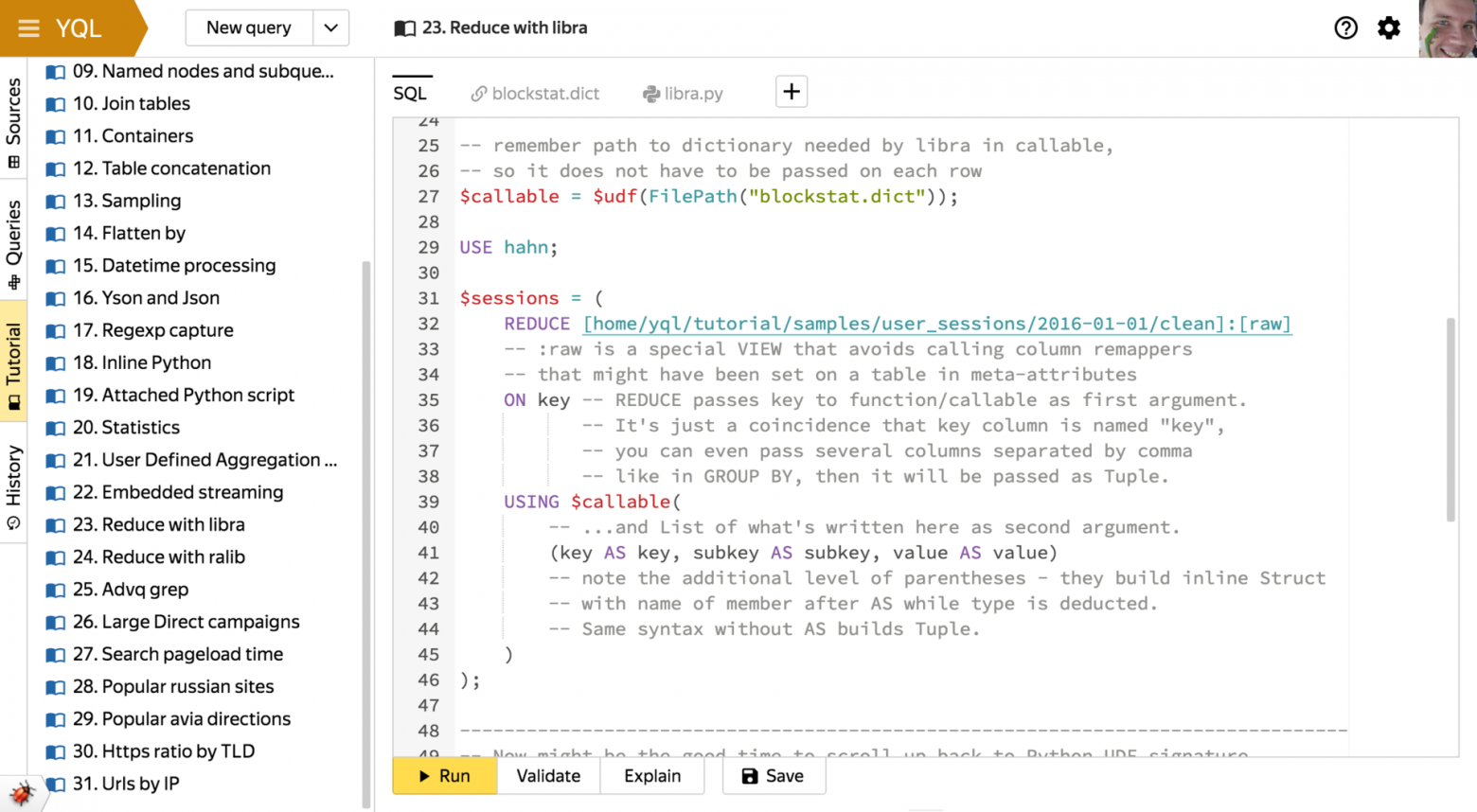
Позволяют встраивать в запросы на YQL cуществующий код, написанный в парадигме MapReduce, в сочетании с механизмом пользовательских функций, о котором пойдет речь ниже.
- Именованные выражения
User Defined Functions
Не все виды преобразований данных удобно выражать декларативно. Иногда проще написать цикл или воспользоваться какой-нибудь готовой библиотекой. Для таких ситуаций YQL предоставляет механизм пользовательских функций, они же User Defined Functions, они же UDF:
- С++ UDF
- «Из коробки» доступно более 100 функций на C++, разделенных более чем на 15 модулей. Примеры модулей: String, DateTime, Pire, Re2, Protobuf, Json и др.
- Физически C++ UDF представляют собой динамически подгружаемые библиотеки (.so) с ABI-safe-протоколом вызова и регистрации функций.
- Есть возможность написать свою C++ UDF, собрать ее локально (система сборки имеет готовый набор настроек сборки для UDF), загрузить стандартным образом в хранилище и сразу же начать использовать в запросах, приложив ее по URL.
- Для простых UDF удобно использовать готовые C++-макросы, скрывающие детали, а при необходимости можно воспользоваться гибкими интерфейсами, созданными под разные потребности.
- Python UDF
- Когда производительность не так важна, а для решения задачи нужно быстро сделать вставку с императивной бизнес-логикой, очень удобно разбавить декларативный запрос кодом на Python. Большинство сотрудников Яндекса знают Python, а если кто-то не знает — на базовом уровне он изучается за единицы дней.
- Скрипт на Python можно либо написать как inline вперемешку с SQL или s-expressions, либо приложить к запросу отдельным файлом. Вообще, механизм доставки файлов до места вычислений с клиента или по URL универсален и может использоваться для всего необходимого, например для файлов-словарей.
- Поскольку в Python используется динамическая типизация, а в YQL — статическая, то от пользователя требуется объявить сигнатуру функции на границе. Сейчас она описывается снаружи с помощью дополнительного мини-языка: дело в том, что на этапе типизации не хочется запускать интерпретатор. В будущем, возможно, прикрутим поддержку Python 3 type hints.
- Технически поддержка Python в YQL реализована через C++ UDF со встроенным интерпретатором Python и небольшой синтаксический сахар в SQL-парсере для ее вызова.
- Streaming UDF. Чтобы можно было плавно перейти с других технологий, и для некоторых особых случаев есть способ запустить произвольный скрипт или исполняемый файл в потоковом режиме. В итоге получим UDF, преобразующую один список строк в другой.
Агрегационные функции
Внутри у агрегационных функций используется общий фреймворк с поддержкой
DISTINCT и выполнения как на верхнем уровне, так и в GROUP BY (в том числе с ROLLUP/CUBE/GROUPING SETS из стандарта SQL:1999). А отличаются эти функции лишь бизнес-логикой. Вот некоторые примеры:- Стандартные:
COUNT,SUM,MIN,MAX,AVG,STDDEV,VARIANCE; - Дополнительные:
COUNT_IF,SOME,LIST,MIN_BY/MAX_BY,BIT_AND/OR/XOR,BOOL_AND/OR; - Статистика:
MEDIANиPERCENTILE(по алгоритму TDigest);HISTOGRAM— адаптивные гистограммы по числовым значениям, не требующие никакого знания их распределения (по алгоритму на основе Streaming Parallel Decision Tree).
- User Defined Aggregation Functions: для совсем специфичных задач можно передать в фрейморк агрегационных функций свою бизнес-логику, создав несколько вызываемых значений с определенной сигнатурой при помощи описанного выше механизма UDF, например, на Python.
Из соображений производительности, в терминах MapReduce для агрегационных функций автоматически создается Map-side Combiner с объединением промежуточных результатов агрегации в Reduce.
DISTINCT сейчас всегда работает точно (без приближенных вычислений), поэтому требует дополнительного Reduce для разметки уникальных значений.JOIN таблиц
Слияние таблиц по ключам — одна из самых популярных операций, которая часто нужна для решения задач, но правильно реализовать которую в терминах MapReduce — почти целая наука. Логически в Yandex Query Language доступны все стандартные режимы плюс несколько дополнительных:
Чтобы скрыть детали от пользователей, для бэкендов, основанных на MapReduce, стратегия выполнения JOIN выбирается на лету в зависимости от требуемого логического типа и физических свойств участвующих таблиц (это так называемая cost based optimization):
| Стратегия | Краткое описание | Доступна для логических типов |
| Common Join | 1-2 Map + Reduce | Все |
| Map-side Join | 1 Map | Inner, Left, Left only, Left semi, Cross |
| Sharded Map-side Join | k паралелльных Map (k <= 4 по-умолчанию) | Inner, Left semi с уникальной правой, Cross |
| Reduce Without Sort | 1 Reduce, но требует заранее правильно отсортированного входа | в разработке |
Направления развития
Среди наших ближайших и среднесрочных планов по Yandex Query Language:
- Больше бэкендов в статусе production.
- Генерация нативного кода и векторизация вместо специализированного интерпретатора.
- Продолжение оптимизации ввода-вывода и выбора стратегий выполнения на лету в зависимости от физических свойств таблиц.
- Оконные функции на основе стандарта SQL:2003.
- Поддержка SQL:1992 в полном объеме, создание ODBC/JDBC-драйверов с последующей интеграцией с популярными ORM и инструментами бизнес-аналитики.
- Наглядная демонстрация прогресса выполнения операций.
- Расширенный ассортимент доступных языков программирования для UDF — посматриваем на JavaScript (V8), Lua (LuaJIT) и Python 3.
- Интеграция с:
- распределенным отказоустойчивым сервисом запуска задач по расписанию (a la cron) или наступлению событий,
- инструментами визуализации (внутренний аналог Яндекс.Статистики).
Подводим итоги
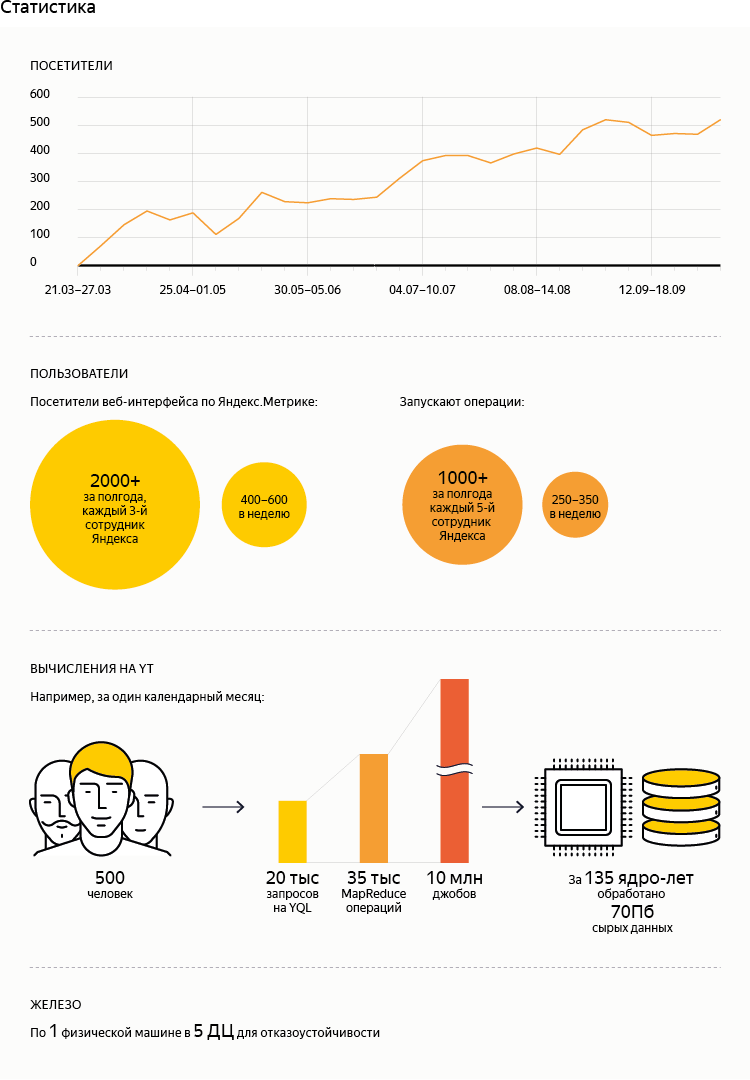
- Как показывают цифры (см. статистику), YQL стал продуктом, очень востребованным среди сотрудников Яндекса. Тем не менее, объемы обработанных с его помощью данных не так велики. Это обусловлено тем, что исторически все продакшен-процессы работают на низкоуровневых интерфейсах, подходящих под требования соответствующих систем. То есть их постепенный перевод на YQL только начинается.
- Внутри Яндекса мы поначалу сталкивались с сопротивлением следующего вида: работая в парадигме MapReduce долгие годы, многие уже настолько к ней привыкли, что не хотят переучиваться. В Аркадии, основном монолитном репозитории кода Яндекса, у каждого сотрудника есть свой уголок. Там исторически лежат буквально сотни программ на C++, написанных исключительно чтобы отфильтровать какой-нибудь специфичный лог или просто таблицу в MapReduce под конкретную задачу. Но после набора критической массы довольных пользователей подобный скептицизм встречается всё реже.
- Возвращаясь к вопросу, «почему не Hive, Spark SQL или любой другой
SQL over ***»: в первую очередь нас интересовала именно поддержка активно используемых в Яндекс систем. Хотелось упростить миграции проектов, то есть все компоненты из диаграммы в начале поста все равно пришлось бы разрабатывать и/или дорабатывать. При этом нужно было бы подстраиваться под устои open source-сообщества. Кроме того, были бы трудности с тем, что Java-разработчиков в Яндексе примерно на порядок меньше, чем C++-разработчиков, а люди с опытом разработки ядра этих open source-проектов — дефицит даже в США. И в результате совершенно не факт, что получилось бы лучше или быстрее. YQL создан с нуля где-то за год командой примерно из 10 человек, большинство из которых участвовали не full time. - Сконцентрировавшись исключительно на SQL-диалекте, мы бы закрыли двери перед заметным классом людей, которым удобнее описывать макропреобразования данных и бизнес-логику однородным образом на одном языке программирования. В Яндексе уже существовала библиотека такого класса для Python под названием Nile: мы вместо имевшегося в ней runtime реализовали (за ее публичным API) генерацию и запуск YQL-запросов на s-expressions. Сейчас мы находимся в процессе доработок для переключения на него по умолчанию. Другие языки программирования, где такой интерфейс был бы востребован, в Яндексе гораздо менее распространены, но в будущем не исключено появление аналогов и для, например, Java.
- Нам было бы очень интересно выложить YQL с каким-нибудь подмножеством бэкендов в open source — чтобы попробовать составить конкуренцию экосистемам от Apache Software Foundation: Hadoop и Spark. К сожалению, в самое ближайшее время этого не случится ввиду разного рода сложностей: например, отсутствия инструментов для частичной публикации Аркадии или многочисленных завязок на внутреннюю инфраструктуру. Но мы уже потихоньку начали двигаться в этом направлении.
Напоследок — еще раз приглашаем на встречу в нашем офисе в ближайшую субботу, 15 октября, где мы подробнее расскажем о разных аспектах инфраструктуры Яндекса.
