
Системы контроля версий уже давно стали повседневным инструментом разработчика. В больших монорепозиториях требования к ним оказываются весьма специфическими. Из-за этого компании либо адаптируют существующие решения, как это делает Facebook с Mercurial и Microsoft с Git, либо разрабатывают собственные системы: Piper и CitC в Google и Arc VCS в Яндексе.
В докладе разработчик Владимир Кихтенко kikht рассказывает, зачем Яндексу понадобилась собственная система контроля версий и как она работает. Рассмотрим её со стороны рядового разработчика: как получить доступ к исходному коду, отвести ветку для разработки и интегрировать изменения в общую кодовую базу. Заглянем под капот — узнаем про внутреннее представление данных и их отображение в виртуальной файловой системе с рабочей копией. Обсудим трудности при реализации функций VCS в виртуальной файловой системе и при ленивой загрузке данных. Поговорим о том, как обеспечивать надежность серверной инфраструктуры репозитория. В конце можно посмотреть неофициальную запись доклада.
— Всем добрый день, меня зовут Владимир. Вы все слышали выступления о том, что не стоит писать велосипеды. Мой доклад будет с другой стороны баррикад.
Действительно, в Яндексе есть монорепозиторий, в котором очень много кода. И мы пришли к тому, что разрабатываем свою систему контроля версий.

Как мы дошли до жизни такой? Исторически этот монорепозиторий у нас жил в SVN. В нем практикуется trunk-based development. Веток нет за очень редкими исключениями. Весь код сначала должен попасть в транк, а потом зарелизиться.
С ростом репозитория единственным возможным способом работы с ним стал селективный чекаут, благо в SVN он поддерживается. Загрузить себе весь репозиторий целиком не то чтобы совсем невозможно, но работать с этим очень тяжело.

Каков масштаб нашей проблемы? Вот некоторые цифры: 6 млн коммитов, почти 2 млн отдельных файлов. Общий размер со всей историей репозитория — 2 ТБ. Чтобы было понятно, что эти цифры значат на фоне других типичных репозиториев, вот график. GitHub median — это медианный размер репозитория на GitHub, 1 МБ. 90-й перцентиль на GitHub — это то, что мои коллеги назвали «репозиторий сына маминой подруги». А все остальное — известные крупные репозитории.
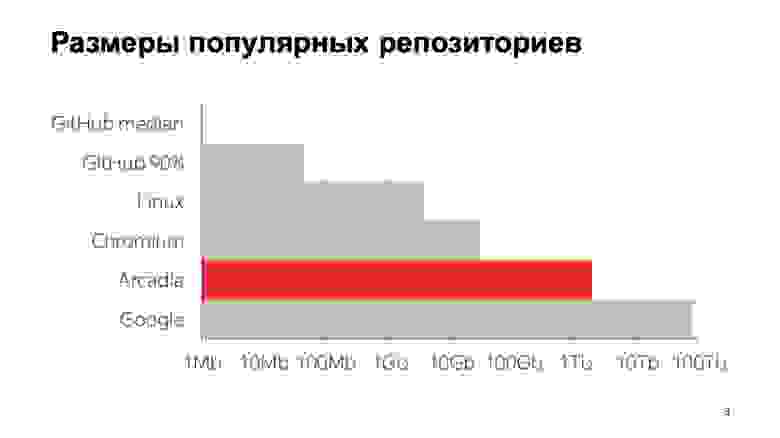
Насколько мне известно, самый крупный в мире репозиторий — у Google. Оценка его размера дана из статьи 2015 года — наверное, с тех пор они еще выросли. Как видите, шкала логарифмическая. Видно, что мы тоже довольно большие.
Как разные системы контроля версий работают при попытке весь этот репозиторий загрузить? Мы, естественно, не сразу стали разрабатывать свою систему контроля версий. Мы попробовали сконвертировать наш репозиторий в разные системы. Самая серьезная попытка была сделана с Mercurial. И результаты времени типичных операций нас все равно не устраивают.
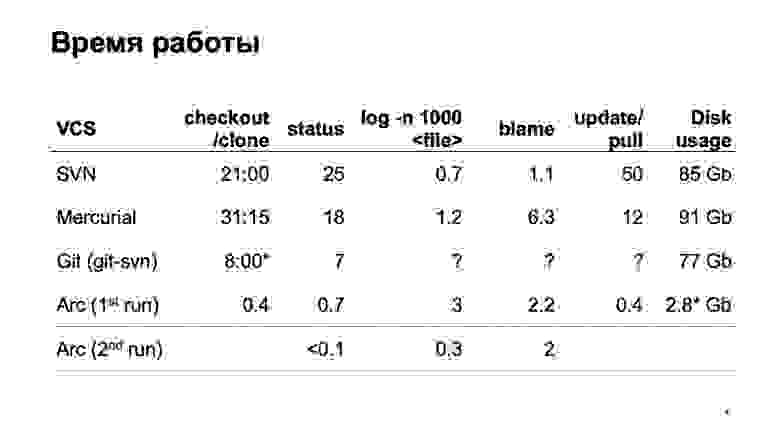
За время подготовки доклада git-svn, к сожалению, не смог сконвертировать весь наш репозиторий целиком. Сконвертировал некоторый срез небольшого числа коммитов, поэтому не могу оценить, сколько работают операции, связанные с историей. На одном отрезке они быстрые, а как оно будет на 6 млн коммитов — не очень понятно.
В конце — цифры для нашей системы контроля версий. Можно мгновенно получить себе рабочую копию. При первом запуске чуть-чуть подтормаживают операции log, при втором запуске все работает быстро.
И последняя цифра. Поскольку наша система контроля версий загружает все данные лениво, то на диске оказываются только те исходники, которые мы реально отрабатывали, которыми реально пользовались. Это существенно меньше, чем скачивать целиком.

Как мы этого достигли? Основная фишка: рабочая копия, которую мы создаем, не является настоящим файликом на диске. Это виртуальная файловая система. На Linux и Мас это сделано с помощью fuse, на Windows — с помощью ProjFS. Все данные загружаем лениво, поэтому используется столько места на диске, сколько на самом деле надо, мы не пытаемся загрузить все заранее. И всякие тяжелые операции мы выносим на сервер. В частности — операцию лога и еще некоторые.

Интерфейс нашей системы контроля версий, по большому счету, повторяет Git, поэтому не буду показывать, как выглядит типичный воркфлоу. Представьте себе Git. Все то же самое: checkout для получения нужной ревизии, branch для создания веток, commit — для коммитов, точно так же поддерживается stash. Что дает этот подход? Мы существенно уменьшаем порог входа. С Git умеют работать большинство разработчиков внутри и снаружи Яндекса. Им не приходится учить ничего нового.
С другой стороны, у нас нет цели сделать drop in replacement для Git. Про это я потом поговорю подробнее. Поддерживать все многообразие гитовых команд кажется безумием, вряд ли нам они на самом деле все нужны.

Чуть-чуть расскажу про внутренности, про то, как это все работает. Начнем с модели данных. Модель данных у нас во многом похожа на гитовую, с некоторыми отличиями. Точно так же все объекты, которые внутри создаем, — иммутабельны, адресуются хэшем своего контента и внутри хранятся в flatbuffers.

Как структура выглядит? Есть объекты коммитов, у каждого коммита есть отдельный или несколько предков. И они таким образом выстраивают некоторый DAG (directed acyclic graph) истории.
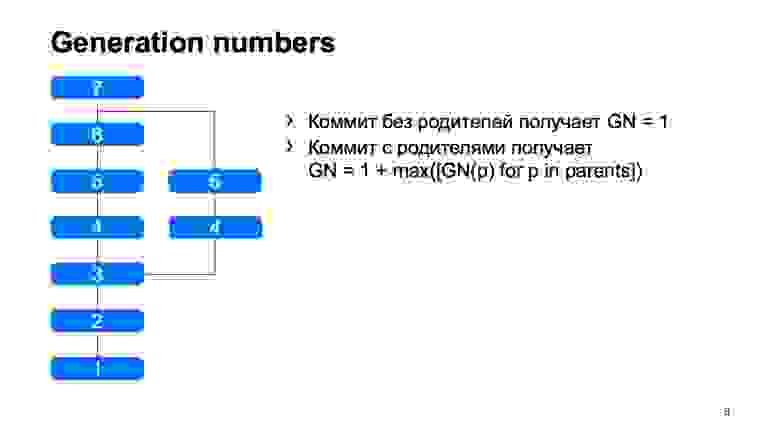
Что у нас есть и что не сразу появилось в Git — это generation numbers. По простому алгоритму мы считаем некоторое расстояние от корня дерева. Зачем нам это нужно? Это все в структуру объектов вшито, один раз зафиксирован, и больше никогда не меняется.
Довольно важная операция для системы контроля версий — это поиск наименьшего общего предка для двух коммитов. В базовом варианте ее можно реализовать просто обходом в ширину, начиная с некоторых двух точек, помечать все достигнутые коммиты там одни или другим признаком, как только нашли коммит, у которого есть оба эти признака, есть наименьший общий предок.
Как это будет работать в наивной реализации? Как-то вот так: обойдем, и найдем наш нужный коммит.
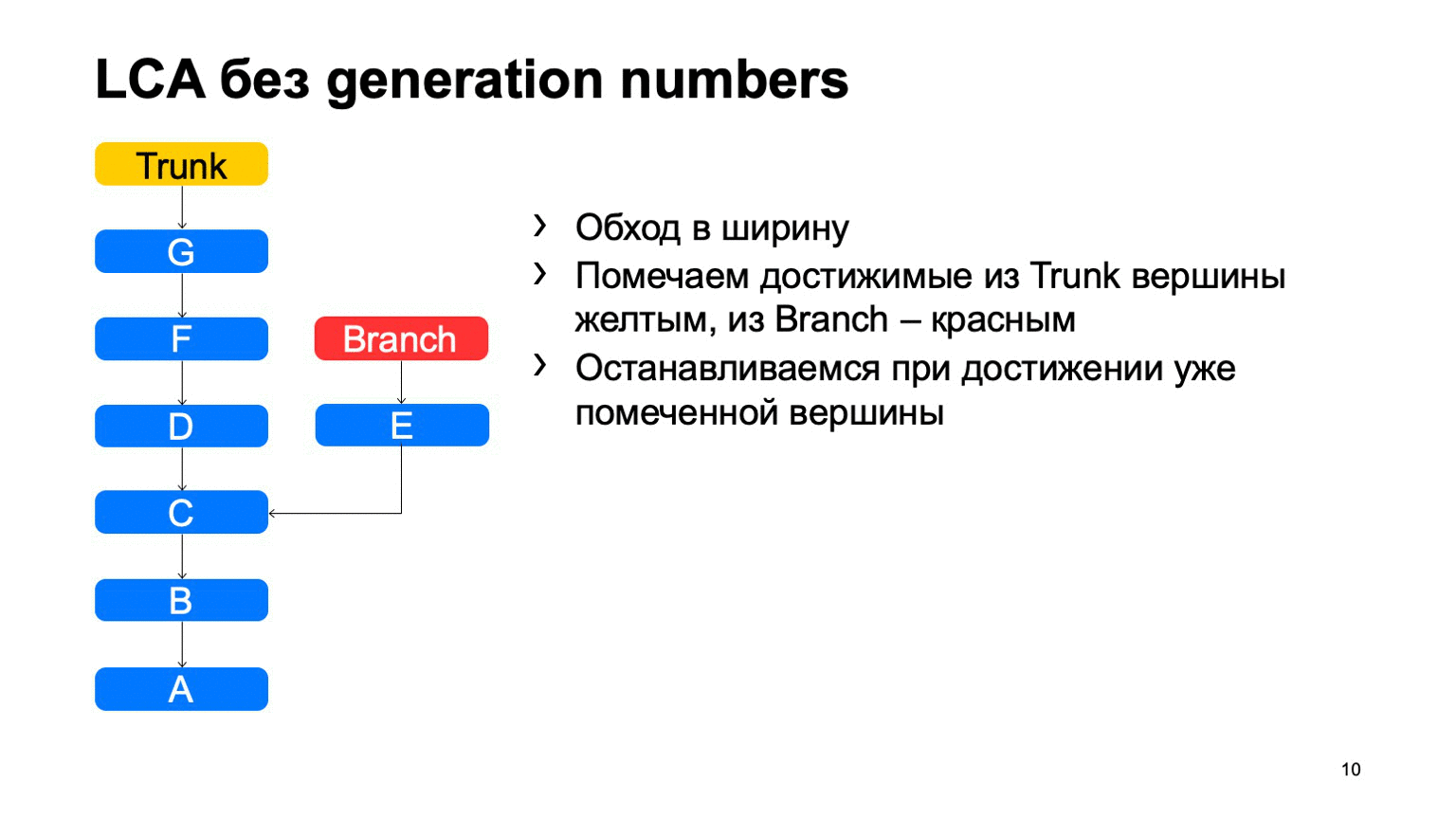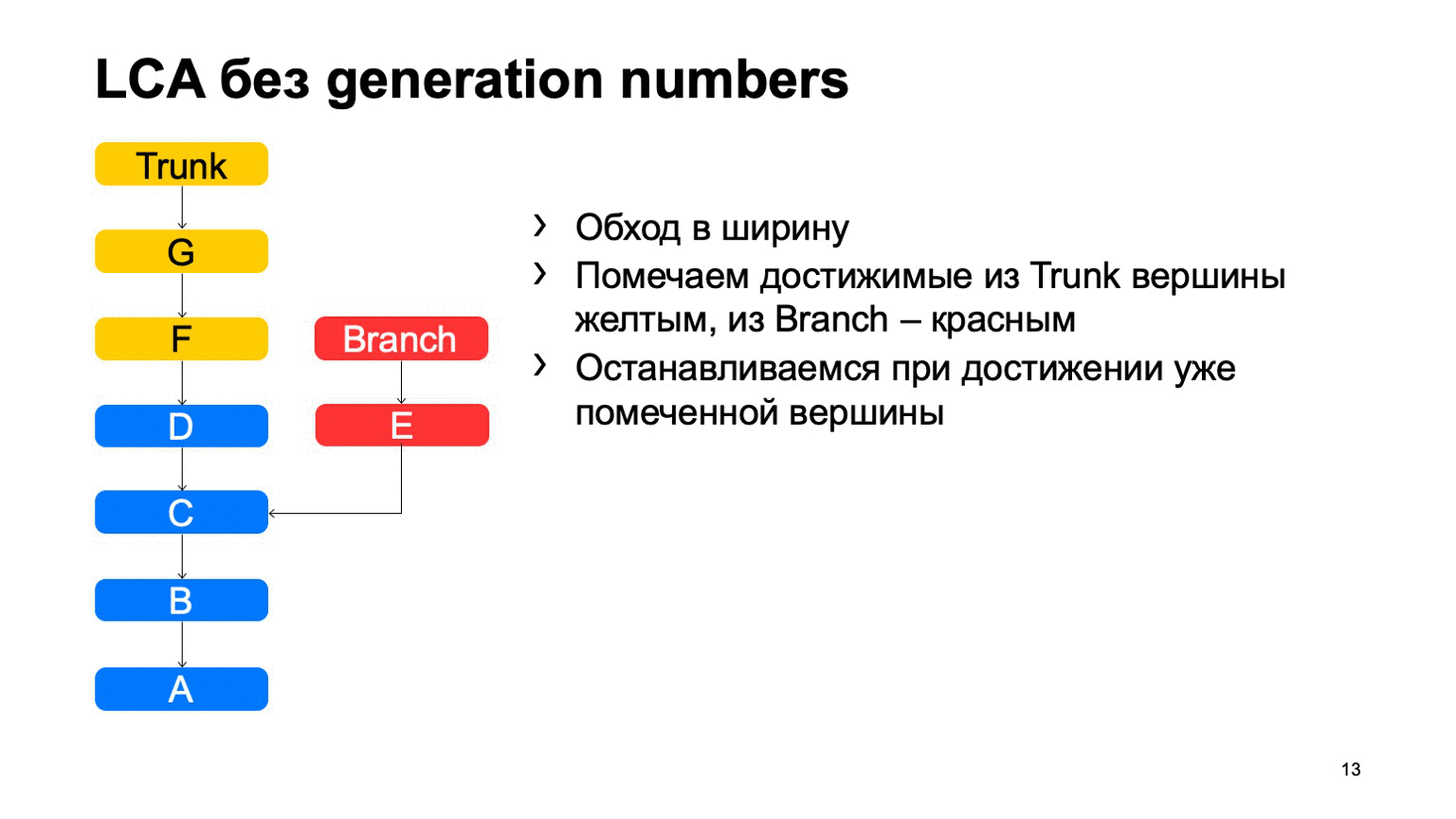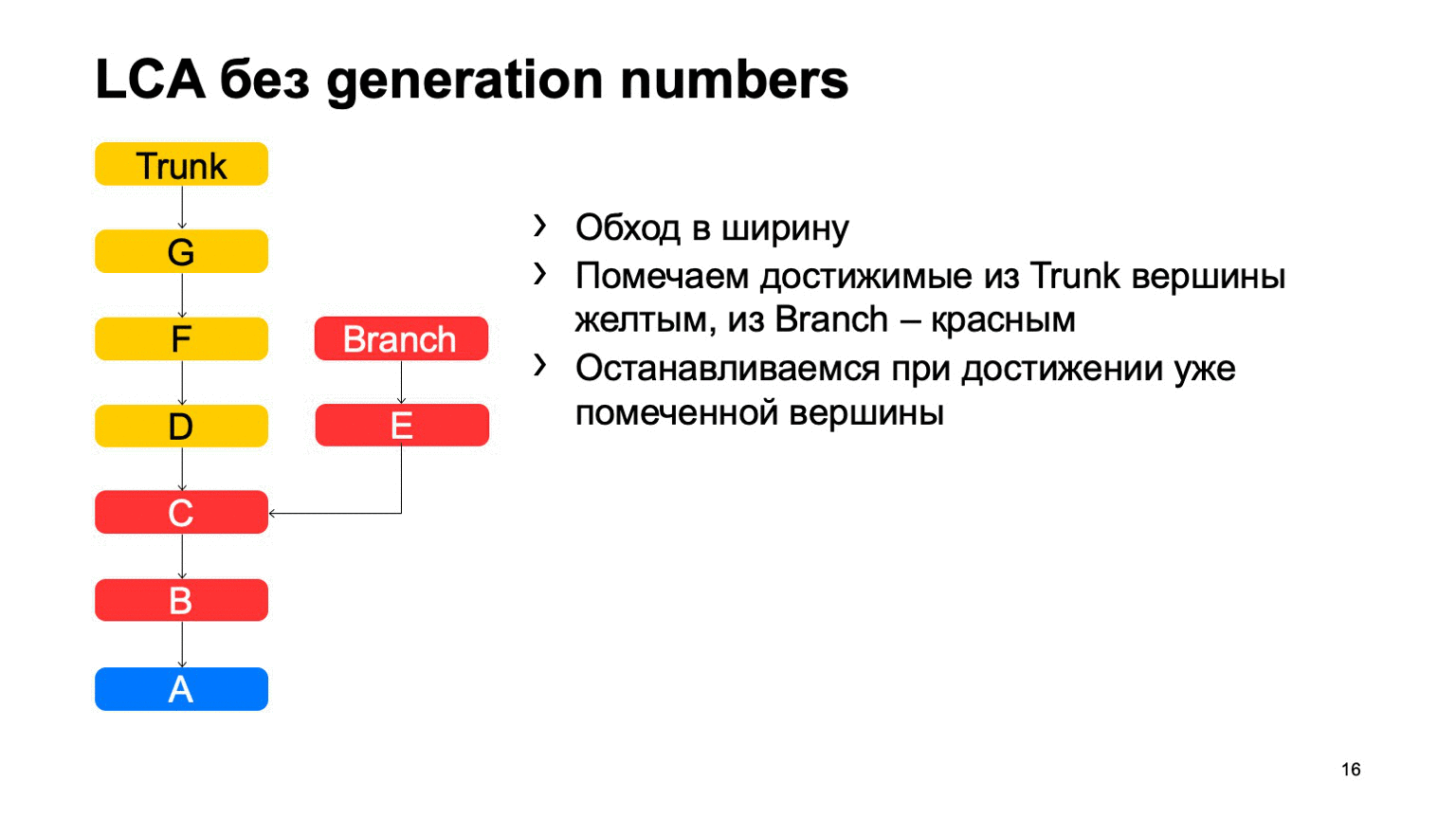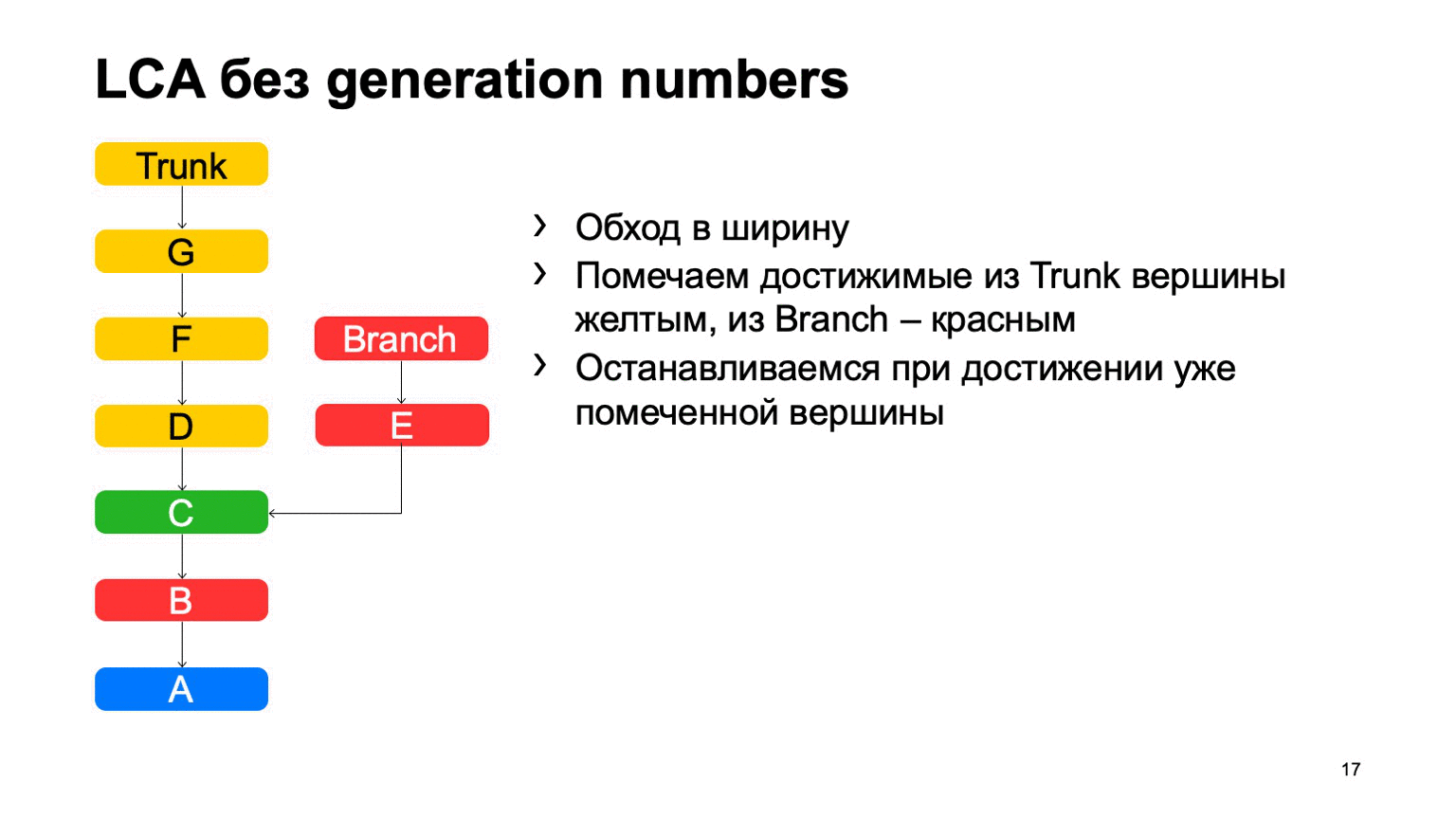
Проблема в коммите В, который лишний. Кажется, что мы могли бы в него не ходить, но мы его просмотрели. И чем больше у нас разница между веткой и транком на примере, тем больше таких лишних коммитов мы найдем. В случае монорепозитория, когда темп коммитов в транк достаточно высокий, это расстояние может быть очень большим. И таких лишних коммитов будут десятки тысяч.


В случае, когда есть generation numbers, мы можем использовать при обходе очередь с приоритетами, и обход будет выглядеть примерно так: раз — и сразу нашли то, что надо.

Это один пример отличия нашей модели. В Git эта штука и раньше поддерживалась, они использовали в качестве generation numbers timestamps, но это будет работать, только если времена создания коммитов согласованы с графом коммитов.
К сожалению, для нашей истории репозитория это не так. Есть коммиты, которые получились в результате миграции другого репозитория, и время начинает в них идти назад. В Git эту штуку поддержали в какой-то момент, но она там не всегда применима, потому что в Git можно подменить объект коммитов другим локально. От этого страдает иммутабельность модели, поэтому те generation numbers, которые не записывают, они иногда не применимы к тому, что в них записано, это неправда. У нас такой проблемы не возникает.
Еще один плюс этой оптимизации в том, что она полностью локальная. Чтобы пользоваться этими номерами, нам не нужно иметь весь граф коммитов целиком. А у нас его как раз обычно нет целиком, у нас он подгружается лениво. Чем меньше мы лениво подгружаем, тем нам живется лучше.
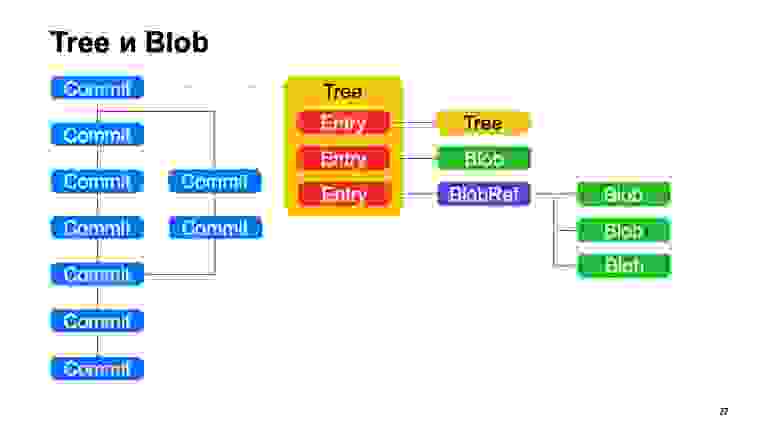
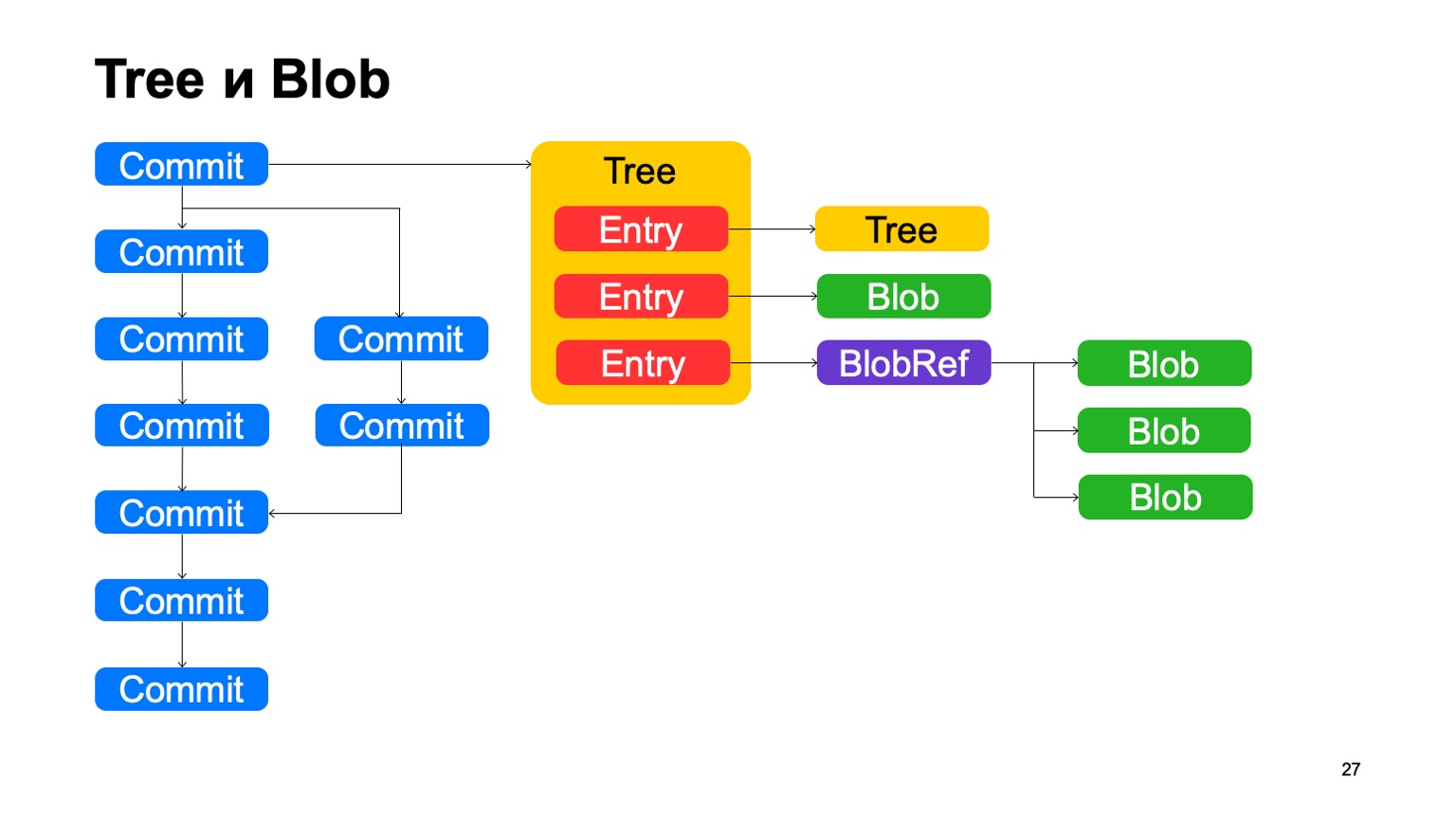
Помимо коммитов, модель очень похожа на Git. Каждый коммит указывает на некоторый объект дерева, дерево состоит из записей, каждая запись — либо еще одно дерево, и так отображается иерархия каталогов у нас, либо это blob, некоторый файл. Плюс у нас есть такая штука как BlobRef, когда файл очень большой, мы его делим на кусочки и представляем в специальном объекте. Это все, как в Git.
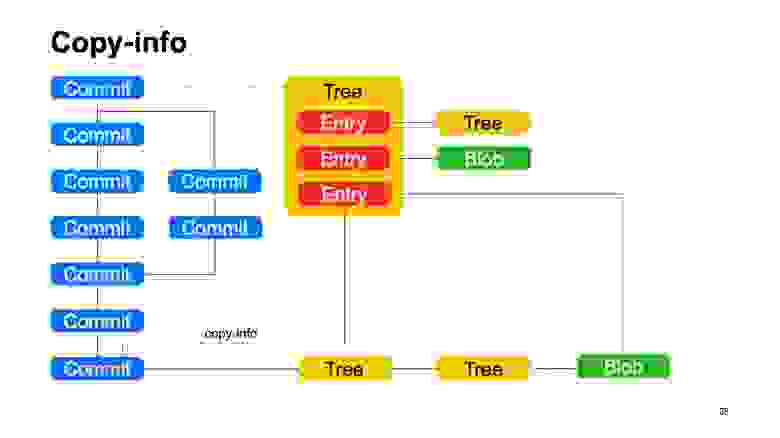
Что у нас не как в Git? Эту штуку мы называем copy-info. Если файл был скопирован в каком-то коммите, то Git эту информацию никак не сохраняет, и пытается потом эвристиками восстанавливать, когда показывает вам diffы и статусы. Мы эту информацию сохраняем в графе. У записей может быть некоторая ссылка copy-info на другой коммит, на путь внутри репозитория в этом коммите, по которому мы знаем, что в этом коммите этот файл был скопирован.
Тут еще получается дедупликация, как на сайде, этот blob хранится один раз. Но дедупликация была бы все равно, потому что контент файла не поменялся, он по хешу был бы дедуплицирован.
Как устроены бэкенды? Если в Git распределенная система контроля версий, ему не нужны какие-то бэкенды. Мы ощущаем это особенно остро, когда GitHub не работает. Мы точно понимаем, что Git не нужны бэкенды. Наша система клиент-серверная, все данные она хранит на сервере, и доступность сервера нужна для того, чтобы скачать те объекты, которых на клиенте еще нет.

Все данные мы храним в Yandex Database. Это очень крутая база данных, которая обеспечивает транзакционность, необходимый уровень надежности. В ней есть все, что нам нужно, и эта штука спасала нас от многих проблем.
Благодаря этому сами бэкенды у нас полностью без состояний, все состояние в базе данных, а бэкенды мы очень легко можем масштабировать, насколько нам надо.
И для взаимодействия что с клиентами, что межсерверного, мы используем gRPC, про него был подробный доклад сегодня.
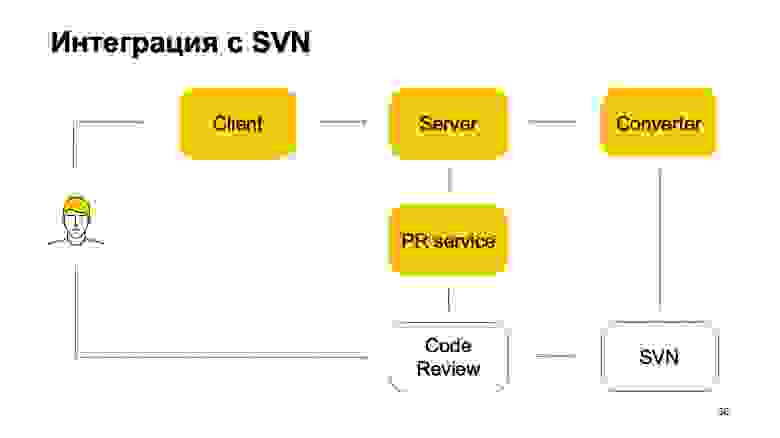
Как наша система интегрирована с SVN? SVN-репозиторий продолжает жить. Более того, наша система контроля версий пока не самодостаточная. Как она в этой части работает? Исходно есть некоторый компонент Converter, который следит за состоянием SVN-репозитория и превращает коммиты SVN в коммиты Arc — нашей системы контроля версий.
Дальше есть клиент, который монтирует (mount) рабочую копию и ходит за данными на сервер. Когда разработчик что-то коммитит, это отправляется сначала на сервер Arc, но чтобы эти изменения попали в trunk, нашу основную ветку, они должны обязательно пройти через систему пул-реквестов и систему код-ревью. Здесь возникает еще один сервис, который следит за ветками Arc, и если они обновились, отправляет пул-реквест нашей системе код-ревью. Дальше система код-ревью, когда принято решение, что этот патч нужно вмержить, коммитит его в SVN. Не совсем просто: она добавляет туда некоторое количество метаданных о том, что этот коммит на самом деле является мержем такой-то ветки из Arc. И дальше этот коммит уже видит конвертер, находит в нем эти мета-данные и создает коммит в сервере Arc. Такой получается круговорот коммитов. Поэтому пока мы без SVN жить не можем, потому что в SVN у нас лежит trunk.
Основная ветка постоянно синхронизируется с нашим сервером, но напрямую в нее закоммитить мы не разрешаем.

Про надежность бэкендов. Конечно, мы планируем, что все разработчики Яндекс будут пользоваться этой штукой, поэтому для нас важно, чтобы она не ломалась. Это такой внутрияндексовый стандарт: наши сервисы должны переживать выход из строя любого дата-центра. Система контроля версий — не исключение. Здесь нас очень спасает то, что YDB такое поддерживает. А наши бэкенды — stateless, там разные части чуть по-разному реализованы. Сервера, которые оперируют объектами Arc, оперируют ветками, они stateless, отреплицированы. Конвертеры, которые постоянно конвертируют из SVN, реплицированы по active-active схеме. Есть несколько одновременно работающих конвертеров, они одновременно конвертируют, и в момент, когда они пытаются обновить ветку Arc, они разрешают конфликты. У одного получилось, у другого не получилось. Он пытается конвертировать что-то дальше.
Сервис пул-реквестов реплицирован по master-slave. Есть главный, работающий. Если он выходит из строя, через YDB выбирается новый. Там есть такая замечательная штука, как семафоры, у которых серьезные гарантии по доступности, надежности. Доступы к семафорам полностью сериализуются. Мы используем семафоры и для сервиса дискавери пул-реквестов, и для выбора лидеров.
Немного о том, как устроен клиент. Это самая сложная часть нашей системы контроля версий, потому что там виртуальная файловая система. По сути, все операции над файлами мы вынуждены реализовать самостоятельно. Пробегусь по некоторым основным операциям, грубо на пальцах опишу, что происходит внутри, когда мы их делаем.

Например, мы открыли файл на запись. Когда мы открыли файл на запись, мы находим соответствующий блоб нашей объектной модели. Если необходимо — что-то подгружаем с сервера. Если мы физически создаем файл в специальном сторе, то все дальнейшие запросы, которые в этот файл идут, мы туда проксируем. Таким образом, пока не закоммиченые локальные изменения (в Git это называется unstaged) попадают во временное хранилище. Мы называем такие файлы материализованными.

Если же мы открываем файл на чтение, то можно ничего не материализовывать, а просто напрямую из нашего блоба отдавать данные.

Вот момент, когда мы добавляем файл в индекс. В этот момент надо посмотреть, есть ли у нас что-то материализованное. Есть ли файл, который изменился. Если он есть — создаем для него блоб и сохраняем в индекс.

Следующая операция — arc status. Она интересная, потому что это та вещь, которая в обычных системах контроля версий на таких размерах оказывается медленной, потому что она вынуждена обходить все файловое дерево. Нам не приходится обходить все файловое дерево, потому что все запросы на изменение файлов проходят через наш fuse-драйвер, и мы сразу знаем, какие файлы стоит проверить на изменение. Проверяем то, что успели записать в индекс, и печатаем ответ.

Время коммита. Вроде все должно быть понятно. Индекс есть, блобы для этих объектов мы уже создали, создаем объекты деревьев, которые этому состоянию соответствуют, создаем новый объект коммита, записываем его в объектное хранилище.

Дальше переключаем рабочую копию на новый коммит. Это хитрая операция, ее явно можно сделать командой checkout. И тут можно подумать, что все наши локальные изменения вроде бы уже материализованы, мы можем считать, что дальше мы должны отдавать те файлы, которые не материализованы, из новых коммитов. И всё. Все последующие операции просто отправляем в другое дерево и блобы.

Почему это может не работать? Первая версия примерно такой и была. Проблема во всяких хитрых операциях типа arc reset --soft. Они переключают нам дерево, но не материализуют файлы. Они продолжают существовать где-то закоммичеными. У нас есть еще untracked- и ignored-файлы, которые тоже нужно специальным образом обрабатывать. В этом месте мы много грабель собрали и в итоге пришли к тому, что все-таки во время чекаута мы должны взять дерево (сейчас — одну рабочую копию), взять дерево того коммита, на который мы переключаемся, взять индекс, и асе это аккуратненько помержить.
Но с точки зрения сложности алгоритмов мы здесь ничего не проиграли: все эти деревья локальных изменений пропорциональны тем изменениям, которые мы сделали. Поэтому мы не должны обходить этими операциями весь репозиторий, они все-таки довольно быстро отрабатывают.
В этот же момент мы делаем некоторую магию, чтобы таймстемпы, которые мы отдаем для файлов, были более-менее правильными. Если мы просто храним файлы в файловой системе, она за этим следит, а время всегда идет вперед. Здесь мы сами должны как-то помнить, какой файл в какой момент видел пользователь. И если он переключился на более ранний коммит, не начать ему отдавать более раннее время. Потому что системы сборки, все IDE к такому не готовы, они много чего сносят.

В нашей системе контроля версий гвоздями прибита поддержка trunk-based development. Во-первых, то, что я уже рассказал: все изменения проходят через пул-реквесты и транк. Есть еще пара моментов. У нас нет поддержки групповых веток. Создаваемые в Arc ветки привязаны к конкретному пользователю, и только он может туда коммитить. Это позволяет нам избежать долгоживущих веток. В SVN такого особо не было, потому что там неудобно делать ветки. А в Arc их делать удобно, и если это не контролировать, мы боимся, что некоторые части нашего монорепозитория отъедут в свои ветки, и будут вести свою разработку там. Это противоречит модели, которую мы хотим делать.

Во-вторых, у нас нет команды merge. Все слияния веток происходят под нашим чутким контролем. Мы сейчас разрабатываем ветки для релизов, в которых тоже можно будет мержить. Это тоже будет осуществляться не какой-то пользовательской командой, а серверной машинерией, скорее всего.

Какие у нас планы? 20% разработчиков монорепозитория уже пользуются нашей системой контроля версий. Мы уже уже вышли из какого-то младенческого состояния, это серьезно используемая система, выкинуть её просто так уже нельзя. Конечная цель — стать основной системой контроля версий в Яндексе. Мы должны как-то убедить оставшиеся 80% разработчиков, что мы достаточно стабильны, надежны и нами можно пользоваться. Ясно, что для этого нужно починить все баги и доделать те фичи, которые есть в Git.
Естественно, в какой-то перспективе мы планируем стать самодостаточными, отказаться от конвертера или развернуть его в обратную сторону, чтобы сначала все изменения попадали в Arc, а потом уже в SVN для самых стойких программистов.
Сейчас у нас большой челлендж — интеграция системы контроля версий в нашу автосборку, в наш CI и другие пайплайны. Челлендж в том, что люди слабы духом, они медленно печатают код и медленно коммитят. И загружают код себе тоже медленно. А роботы лишены этого недостатка.
В качестве анекдота — недавно для одного проекта, для их CI мы разрешили их роботу напрямую ходить в Arc, чуть-чуть коммитить. И они создали нам нагрузки в два раза больше, чем у всех разработчиков Яндекса вместе взятых. И это только маленький кусочек. Когда к нам придет большая автосборка, которая отвечает за основную часть С++-кода в монорепозитории, мы ожидаем, что нагрузка возрастет в сотни раз. К этому нужно серьезно подготовиться.
Предложение для обсуждения. Всю дорогу я повторял слова «как в Git». И в целом наш план остается прежним: интерфейсом повторять Git. Но чем больше мы это делаем, тем больше понимаем, что это не очень работает.
Есть несколько проблем. Интерфейсы Git весьма низкоуровневые. Они предлагают чуть ли не операции, которые напрямую взаимодействуют с нашим графом объектов. При этом программисты хотят каких-то высокоуровневых операций. И далеко не каждый разберется с тем, какие и как нужно выставить аргументы команде checkout или reset, чтобы ничего не испортить в рабочей копии. Я это знаю, потому что занимаюсь поддержкой пользователей, которые переходят на нашу систему контроля версий. Регулярно говоришь людям: все как в Git. «Ну вот я это сделал, и все сломалось». В Git тоже бы сломалось.
Для иллюстрации этой проблемы можно привести такой пример. Знаете такую нужную и полезную команду Git, как git begin-wave-stash?
Из зала:
— Очень полезная.
— Как вы думаете, в Git такая команда вообще есть? В этом и проблема — без любимой поисковой системы вы не только не знаете, что она делает, но и не знаете в принципе, есть ли она. Ее нет, я ее только что придумал. Поэтому Git не лишен недостатков. И раз уж мы разрабатываем свою систему контроля версий, странно не воспользоваться возможностью их исправить. Спасибо.
В докладе разработчик Владимир Кихтенко kikht рассказывает, зачем Яндексу понадобилась собственная система контроля версий и как она работает. Рассмотрим её со стороны рядового разработчика: как получить доступ к исходному коду, отвести ветку для разработки и интегрировать изменения в общую кодовую базу. Заглянем под капот — узнаем про внутреннее представление данных и их отображение в виртуальной файловой системе с рабочей копией. Обсудим трудности при реализации функций VCS в виртуальной файловой системе и при ленивой загрузке данных. Поговорим о том, как обеспечивать надежность серверной инфраструктуры репозитория. В конце можно посмотреть неофициальную запись доклада.
— Всем добрый день, меня зовут Владимир. Вы все слышали выступления о том, что не стоит писать велосипеды. Мой доклад будет с другой стороны баррикад.
Действительно, в Яндексе есть монорепозиторий, в котором очень много кода. И мы пришли к тому, что разрабатываем свою систему контроля версий.

Как мы дошли до жизни такой? Исторически этот монорепозиторий у нас жил в SVN. В нем практикуется trunk-based development. Веток нет за очень редкими исключениями. Весь код сначала должен попасть в транк, а потом зарелизиться.
С ростом репозитория единственным возможным способом работы с ним стал селективный чекаут, благо в SVN он поддерживается. Загрузить себе весь репозиторий целиком не то чтобы совсем невозможно, но работать с этим очень тяжело.

Каков масштаб нашей проблемы? Вот некоторые цифры: 6 млн коммитов, почти 2 млн отдельных файлов. Общий размер со всей историей репозитория — 2 ТБ. Чтобы было понятно, что эти цифры значат на фоне других типичных репозиториев, вот график. GitHub median — это медианный размер репозитория на GitHub, 1 МБ. 90-й перцентиль на GitHub — это то, что мои коллеги назвали «репозиторий сына маминой подруги». А все остальное — известные крупные репозитории.
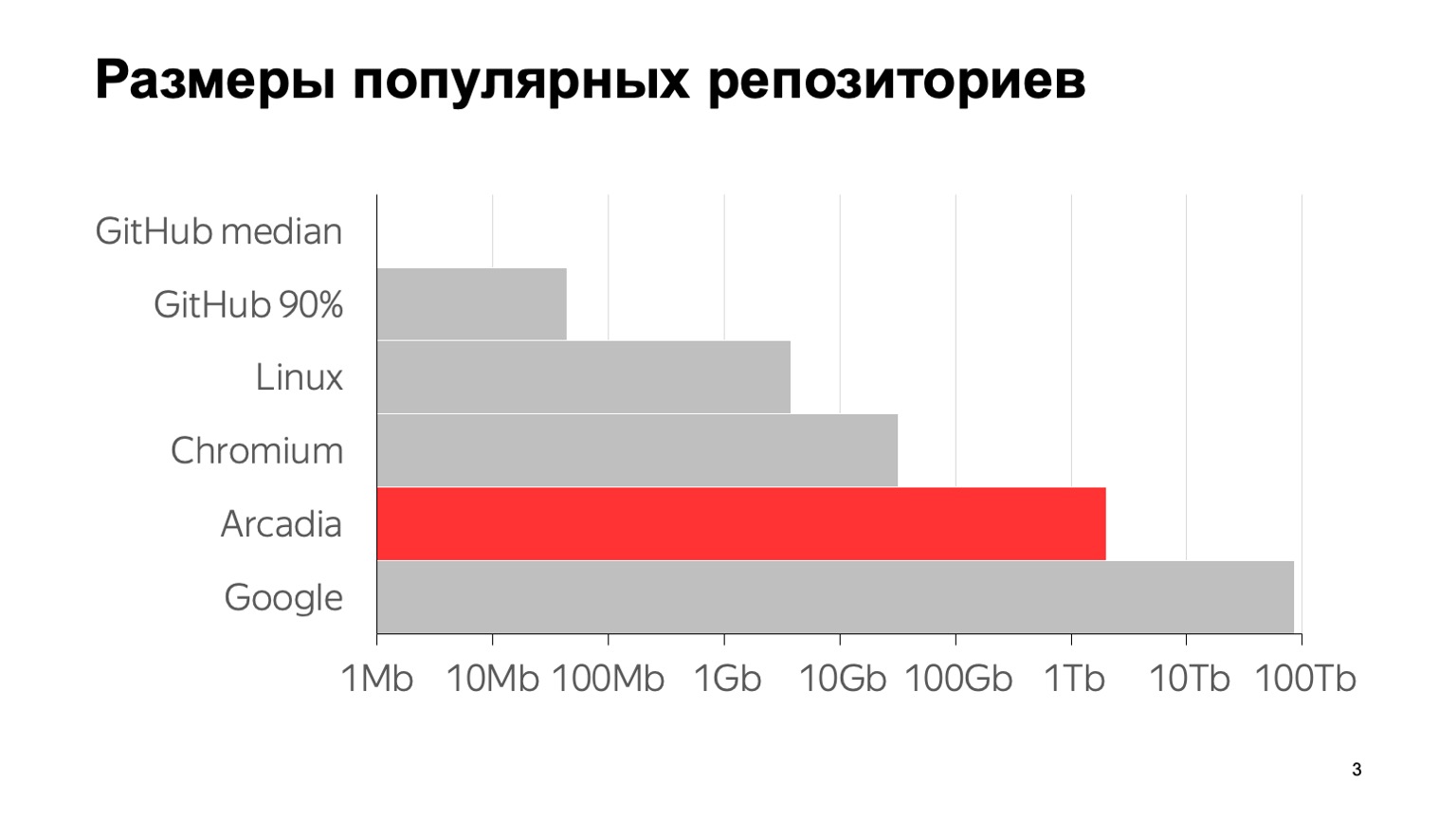
Насколько мне известно, самый крупный в мире репозиторий — у Google. Оценка его размера дана из статьи 2015 года — наверное, с тех пор они еще выросли. Как видите, шкала логарифмическая. Видно, что мы тоже довольно большие.
Как разные системы контроля версий работают при попытке весь этот репозиторий загрузить? Мы, естественно, не сразу стали разрабатывать свою систему контроля версий. Мы попробовали сконвертировать наш репозиторий в разные системы. Самая серьезная попытка была сделана с Mercurial. И результаты времени типичных операций нас все равно не устраивают.
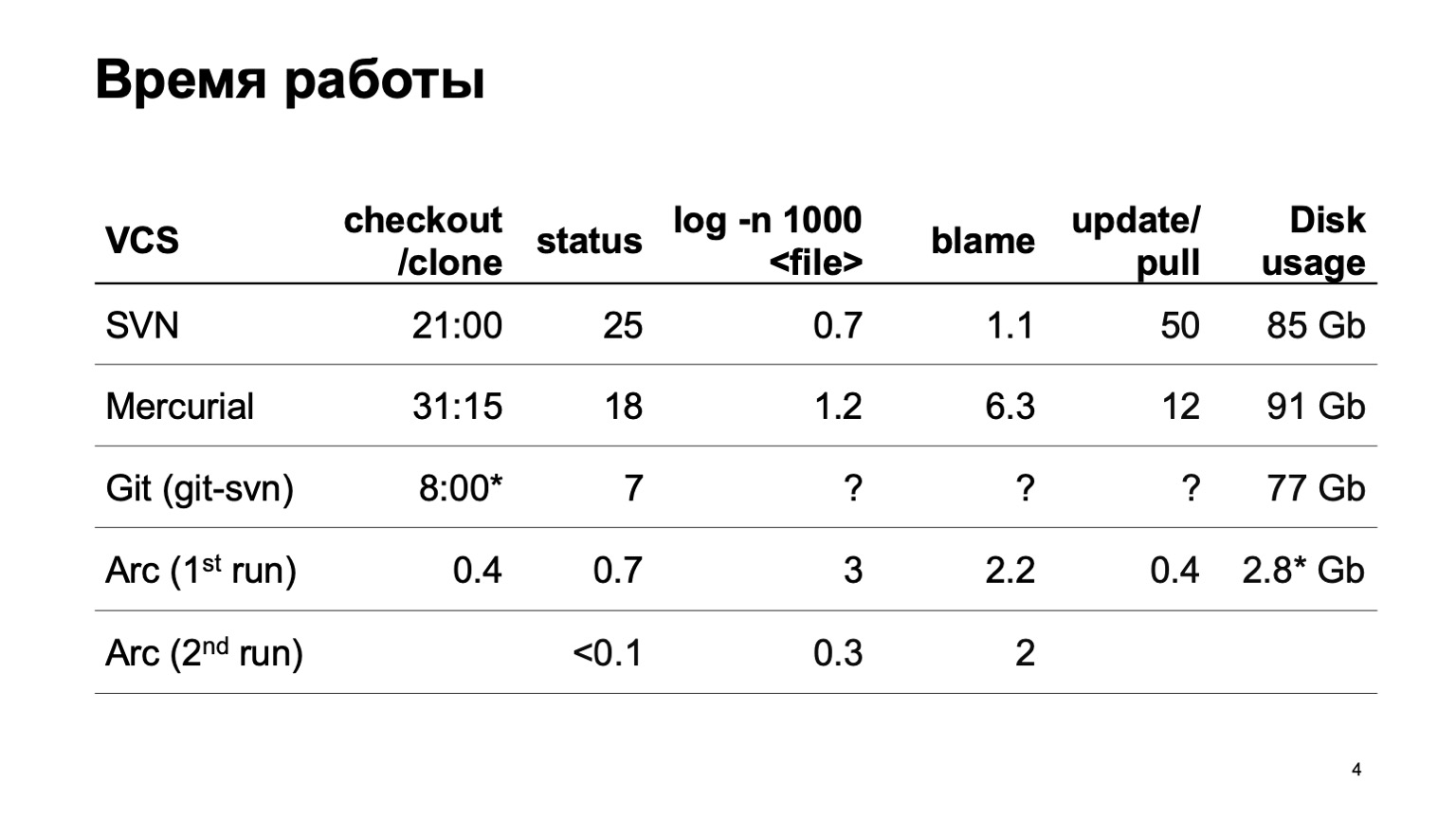
За время подготовки доклада git-svn, к сожалению, не смог сконвертировать весь наш репозиторий целиком. Сконвертировал некоторый срез небольшого числа коммитов, поэтому не могу оценить, сколько работают операции, связанные с историей. На одном отрезке они быстрые, а как оно будет на 6 млн коммитов — не очень понятно.
В конце — цифры для нашей системы контроля версий. Можно мгновенно получить себе рабочую копию. При первом запуске чуть-чуть подтормаживают операции log, при втором запуске все работает быстро.
И последняя цифра. Поскольку наша система контроля версий загружает все данные лениво, то на диске оказываются только те исходники, которые мы реально отрабатывали, которыми реально пользовались. Это существенно меньше, чем скачивать целиком.

Как мы этого достигли? Основная фишка: рабочая копия, которую мы создаем, не является настоящим файликом на диске. Это виртуальная файловая система. На Linux и Мас это сделано с помощью fuse, на Windows — с помощью ProjFS. Все данные загружаем лениво, поэтому используется столько места на диске, сколько на самом деле надо, мы не пытаемся загрузить все заранее. И всякие тяжелые операции мы выносим на сервер. В частности — операцию лога и еще некоторые.

Интерфейс нашей системы контроля версий, по большому счету, повторяет Git, поэтому не буду показывать, как выглядит типичный воркфлоу. Представьте себе Git. Все то же самое: checkout для получения нужной ревизии, branch для создания веток, commit — для коммитов, точно так же поддерживается stash. Что дает этот подход? Мы существенно уменьшаем порог входа. С Git умеют работать большинство разработчиков внутри и снаружи Яндекса. Им не приходится учить ничего нового.
С другой стороны, у нас нет цели сделать drop in replacement для Git. Про это я потом поговорю подробнее. Поддерживать все многообразие гитовых команд кажется безумием, вряд ли нам они на самом деле все нужны.

Чуть-чуть расскажу про внутренности, про то, как это все работает. Начнем с модели данных. Модель данных у нас во многом похожа на гитовую, с некоторыми отличиями. Точно так же все объекты, которые внутри создаем, — иммутабельны, адресуются хэшем своего контента и внутри хранятся в flatbuffers.

Как структура выглядит? Есть объекты коммитов, у каждого коммита есть отдельный или несколько предков. И они таким образом выстраивают некоторый DAG (directed acyclic graph) истории.
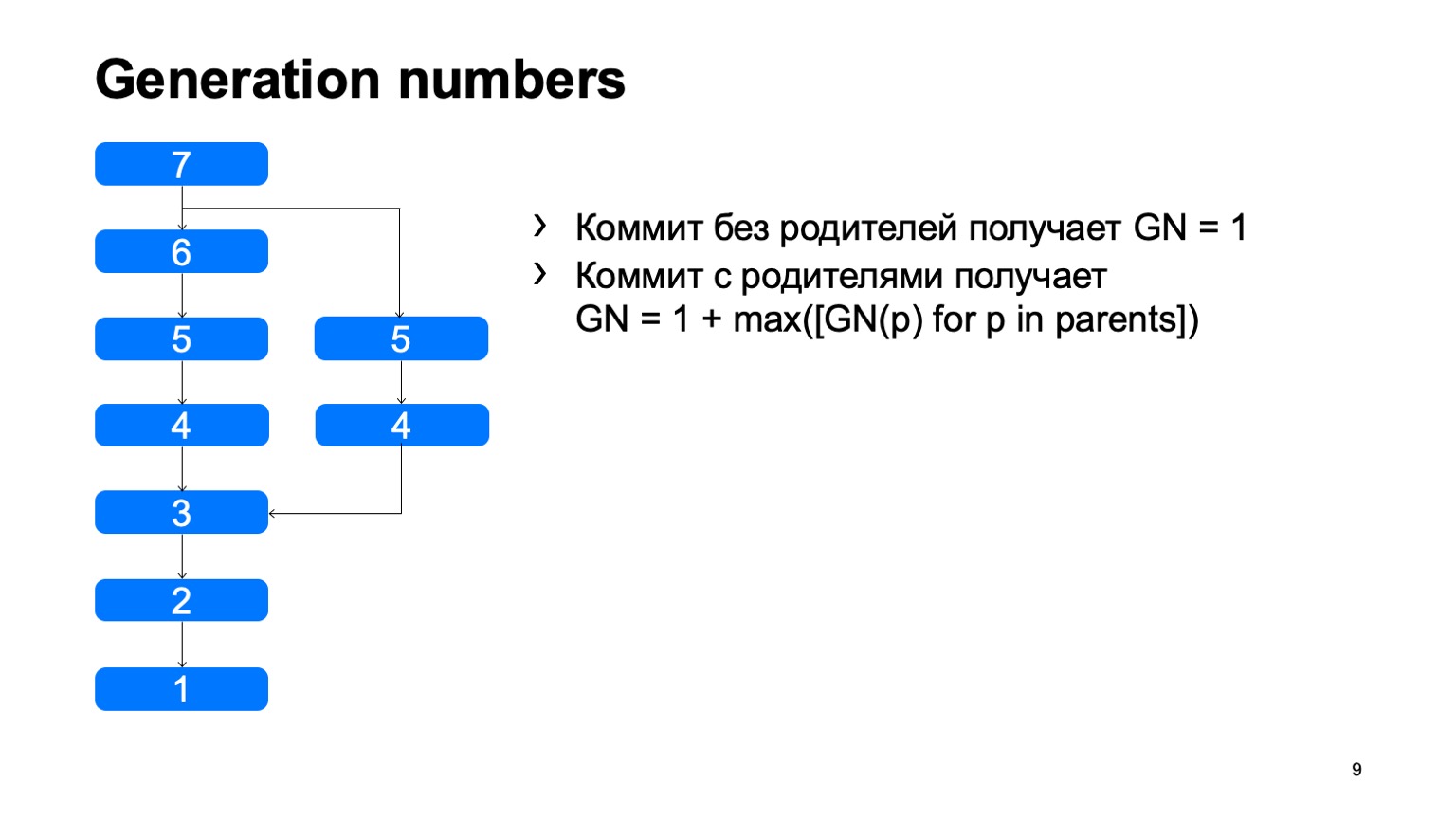
Что у нас есть и что не сразу появилось в Git — это generation numbers. По простому алгоритму мы считаем некоторое расстояние от корня дерева. Зачем нам это нужно? Это все в структуру объектов вшито, один раз зафиксирован, и больше никогда не меняется.
Довольно важная операция для системы контроля версий — это поиск наименьшего общего предка для двух коммитов. В базовом варианте ее можно реализовать просто обходом в ширину, начиная с некоторых двух точек, помечать все достигнутые коммиты там одни или другим признаком, как только нашли коммит, у которого есть оба эти признака, есть наименьший общий предок.
Как это будет работать в наивной реализации? Как-то вот так: обойдем, и найдем наш нужный коммит.
Проблема в коммите В, который лишний. Кажется, что мы могли бы в него не ходить, но мы его просмотрели. И чем больше у нас разница между веткой и транком на примере, тем больше таких лишних коммитов мы найдем. В случае монорепозитория, когда темп коммитов в транк достаточно высокий, это расстояние может быть очень большим. И таких лишних коммитов будут десятки тысяч.

В случае, когда есть generation numbers, мы можем использовать при обходе очередь с приоритетами, и обход будет выглядеть примерно так: раз — и сразу нашли то, что надо.

Это один пример отличия нашей модели. В Git эта штука и раньше поддерживалась, они использовали в качестве generation numbers timestamps, но это будет работать, только если времена создания коммитов согласованы с графом коммитов.
К сожалению, для нашей истории репозитория это не так. Есть коммиты, которые получились в результате миграции другого репозитория, и время начинает в них идти назад. В Git эту штуку поддержали в какой-то момент, но она там не всегда применима, потому что в Git можно подменить объект коммитов другим локально. От этого страдает иммутабельность модели, поэтому те generation numbers, которые не записывают, они иногда не применимы к тому, что в них записано, это неправда. У нас такой проблемы не возникает.
Еще один плюс этой оптимизации в том, что она полностью локальная. Чтобы пользоваться этими номерами, нам не нужно иметь весь граф коммитов целиком. А у нас его как раз обычно нет целиком, у нас он подгружается лениво. Чем меньше мы лениво подгружаем, тем нам живется лучше.
Помимо коммитов, модель очень похожа на Git. Каждый коммит указывает на некоторый объект дерева, дерево состоит из записей, каждая запись — либо еще одно дерево, и так отображается иерархия каталогов у нас, либо это blob, некоторый файл. Плюс у нас есть такая штука как BlobRef, когда файл очень большой, мы его делим на кусочки и представляем в специальном объекте. Это все, как в Git.

Что у нас не как в Git? Эту штуку мы называем copy-info. Если файл был скопирован в каком-то коммите, то Git эту информацию никак не сохраняет, и пытается потом эвристиками восстанавливать, когда показывает вам diffы и статусы. Мы эту информацию сохраняем в графе. У записей может быть некоторая ссылка copy-info на другой коммит, на путь внутри репозитория в этом коммите, по которому мы знаем, что в этом коммите этот файл был скопирован.
Тут еще получается дедупликация, как на сайде, этот blob хранится один раз. Но дедупликация была бы все равно, потому что контент файла не поменялся, он по хешу был бы дедуплицирован.
Как устроены бэкенды? Если в Git распределенная система контроля версий, ему не нужны какие-то бэкенды. Мы ощущаем это особенно остро, когда GitHub не работает. Мы точно понимаем, что Git не нужны бэкенды. Наша система клиент-серверная, все данные она хранит на сервере, и доступность сервера нужна для того, чтобы скачать те объекты, которых на клиенте еще нет.

Все данные мы храним в Yandex Database. Это очень крутая база данных, которая обеспечивает транзакционность, необходимый уровень надежности. В ней есть все, что нам нужно, и эта штука спасала нас от многих проблем.
Благодаря этому сами бэкенды у нас полностью без состояний, все состояние в базе данных, а бэкенды мы очень легко можем масштабировать, насколько нам надо.
И для взаимодействия что с клиентами, что межсерверного, мы используем gRPC, про него был подробный доклад сегодня.
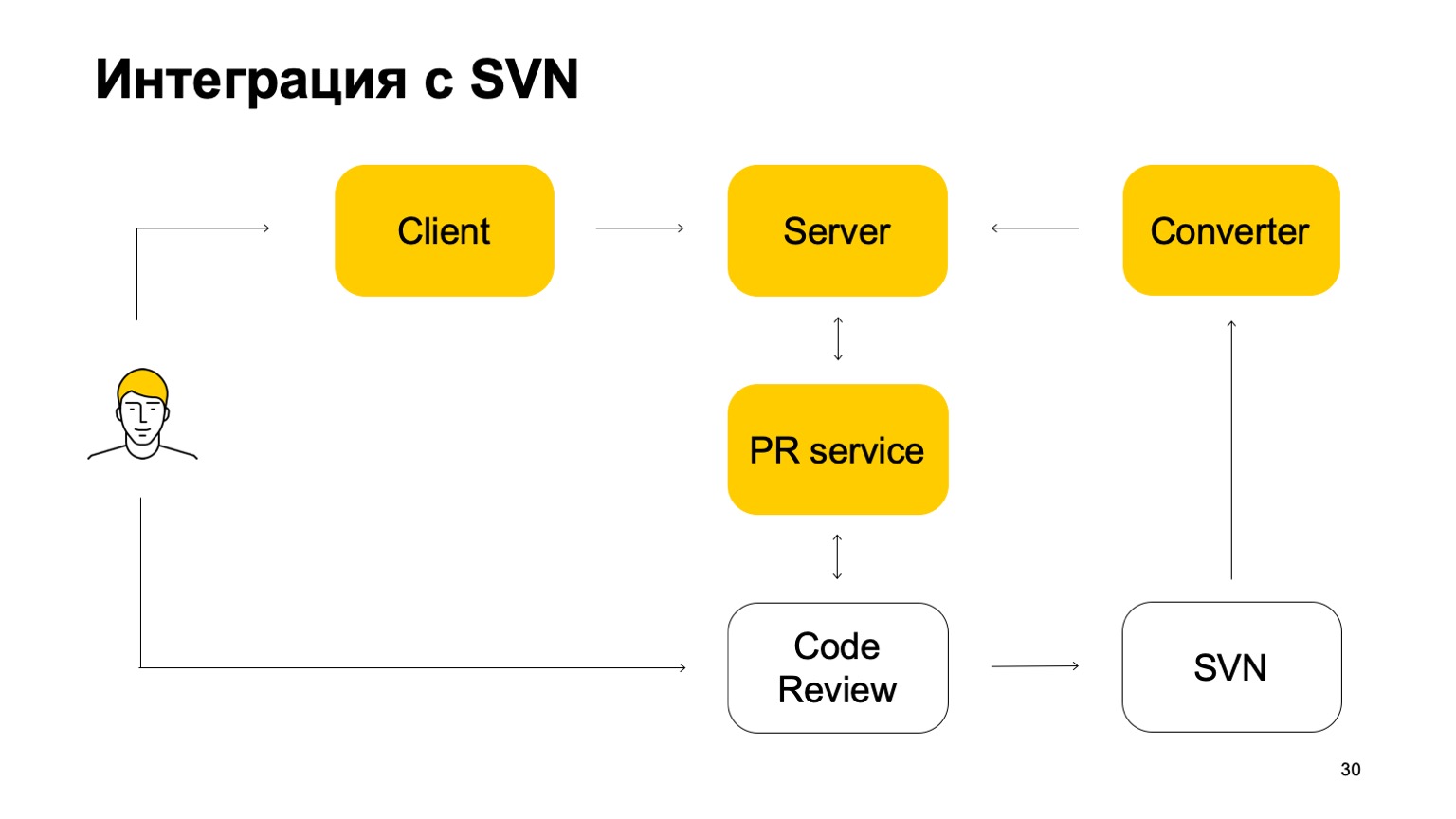
Как наша система интегрирована с SVN? SVN-репозиторий продолжает жить. Более того, наша система контроля версий пока не самодостаточная. Как она в этой части работает? Исходно есть некоторый компонент Converter, который следит за состоянием SVN-репозитория и превращает коммиты SVN в коммиты Arc — нашей системы контроля версий.
Дальше есть клиент, который монтирует (mount) рабочую копию и ходит за данными на сервер. Когда разработчик что-то коммитит, это отправляется сначала на сервер Arc, но чтобы эти изменения попали в trunk, нашу основную ветку, они должны обязательно пройти через систему пул-реквестов и систему код-ревью. Здесь возникает еще один сервис, который следит за ветками Arc, и если они обновились, отправляет пул-реквест нашей системе код-ревью. Дальше система код-ревью, когда принято решение, что этот патч нужно вмержить, коммитит его в SVN. Не совсем просто: она добавляет туда некоторое количество метаданных о том, что этот коммит на самом деле является мержем такой-то ветки из Arc. И дальше этот коммит уже видит конвертер, находит в нем эти мета-данные и создает коммит в сервере Arc. Такой получается круговорот коммитов. Поэтому пока мы без SVN жить не можем, потому что в SVN у нас лежит trunk.
Основная ветка постоянно синхронизируется с нашим сервером, но напрямую в нее закоммитить мы не разрешаем.

Про надежность бэкендов. Конечно, мы планируем, что все разработчики Яндекс будут пользоваться этой штукой, поэтому для нас важно, чтобы она не ломалась. Это такой внутрияндексовый стандарт: наши сервисы должны переживать выход из строя любого дата-центра. Система контроля версий — не исключение. Здесь нас очень спасает то, что YDB такое поддерживает. А наши бэкенды — stateless, там разные части чуть по-разному реализованы. Сервера, которые оперируют объектами Arc, оперируют ветками, они stateless, отреплицированы. Конвертеры, которые постоянно конвертируют из SVN, реплицированы по active-active схеме. Есть несколько одновременно работающих конвертеров, они одновременно конвертируют, и в момент, когда они пытаются обновить ветку Arc, они разрешают конфликты. У одного получилось, у другого не получилось. Он пытается конвертировать что-то дальше.
Сервис пул-реквестов реплицирован по master-slave. Есть главный, работающий. Если он выходит из строя, через YDB выбирается новый. Там есть такая замечательная штука, как семафоры, у которых серьезные гарантии по доступности, надежности. Доступы к семафорам полностью сериализуются. Мы используем семафоры и для сервиса дискавери пул-реквестов, и для выбора лидеров.
Немного о том, как устроен клиент. Это самая сложная часть нашей системы контроля версий, потому что там виртуальная файловая система. По сути, все операции над файлами мы вынуждены реализовать самостоятельно. Пробегусь по некоторым основным операциям, грубо на пальцах опишу, что происходит внутри, когда мы их делаем.

Например, мы открыли файл на запись. Когда мы открыли файл на запись, мы находим соответствующий блоб нашей объектной модели. Если необходимо — что-то подгружаем с сервера. Если мы физически создаем файл в специальном сторе, то все дальнейшие запросы, которые в этот файл идут, мы туда проксируем. Таким образом, пока не закоммиченые локальные изменения (в Git это называется unstaged) попадают во временное хранилище. Мы называем такие файлы материализованными.

Если же мы открываем файл на чтение, то можно ничего не материализовывать, а просто напрямую из нашего блоба отдавать данные.

Вот момент, когда мы добавляем файл в индекс. В этот момент надо посмотреть, есть ли у нас что-то материализованное. Есть ли файл, который изменился. Если он есть — создаем для него блоб и сохраняем в индекс.

Следующая операция — arc status. Она интересная, потому что это та вещь, которая в обычных системах контроля версий на таких размерах оказывается медленной, потому что она вынуждена обходить все файловое дерево. Нам не приходится обходить все файловое дерево, потому что все запросы на изменение файлов проходят через наш fuse-драйвер, и мы сразу знаем, какие файлы стоит проверить на изменение. Проверяем то, что успели записать в индекс, и печатаем ответ.

Время коммита. Вроде все должно быть понятно. Индекс есть, блобы для этих объектов мы уже создали, создаем объекты деревьев, которые этому состоянию соответствуют, создаем новый объект коммита, записываем его в объектное хранилище.

Дальше переключаем рабочую копию на новый коммит. Это хитрая операция, ее явно можно сделать командой checkout. И тут можно подумать, что все наши локальные изменения вроде бы уже материализованы, мы можем считать, что дальше мы должны отдавать те файлы, которые не материализованы, из новых коммитов. И всё. Все последующие операции просто отправляем в другое дерево и блобы.

Почему это может не работать? Первая версия примерно такой и была. Проблема во всяких хитрых операциях типа arc reset --soft. Они переключают нам дерево, но не материализуют файлы. Они продолжают существовать где-то закоммичеными. У нас есть еще untracked- и ignored-файлы, которые тоже нужно специальным образом обрабатывать. В этом месте мы много грабель собрали и в итоге пришли к тому, что все-таки во время чекаута мы должны взять дерево (сейчас — одну рабочую копию), взять дерево того коммита, на который мы переключаемся, взять индекс, и асе это аккуратненько помержить.
Но с точки зрения сложности алгоритмов мы здесь ничего не проиграли: все эти деревья локальных изменений пропорциональны тем изменениям, которые мы сделали. Поэтому мы не должны обходить этими операциями весь репозиторий, они все-таки довольно быстро отрабатывают.
В этот же момент мы делаем некоторую магию, чтобы таймстемпы, которые мы отдаем для файлов, были более-менее правильными. Если мы просто храним файлы в файловой системе, она за этим следит, а время всегда идет вперед. Здесь мы сами должны как-то помнить, какой файл в какой момент видел пользователь. И если он переключился на более ранний коммит, не начать ему отдавать более раннее время. Потому что системы сборки, все IDE к такому не готовы, они много чего сносят.

В нашей системе контроля версий гвоздями прибита поддержка trunk-based development. Во-первых, то, что я уже рассказал: все изменения проходят через пул-реквесты и транк. Есть еще пара моментов. У нас нет поддержки групповых веток. Создаваемые в Arc ветки привязаны к конкретному пользователю, и только он может туда коммитить. Это позволяет нам избежать долгоживущих веток. В SVN такого особо не было, потому что там неудобно делать ветки. А в Arc их делать удобно, и если это не контролировать, мы боимся, что некоторые части нашего монорепозитория отъедут в свои ветки, и будут вести свою разработку там. Это противоречит модели, которую мы хотим делать.

Во-вторых, у нас нет команды merge. Все слияния веток происходят под нашим чутким контролем. Мы сейчас разрабатываем ветки для релизов, в которых тоже можно будет мержить. Это тоже будет осуществляться не какой-то пользовательской командой, а серверной машинерией, скорее всего.

Какие у нас планы? 20% разработчиков монорепозитория уже пользуются нашей системой контроля версий. Мы уже уже вышли из какого-то младенческого состояния, это серьезно используемая система, выкинуть её просто так уже нельзя. Конечная цель — стать основной системой контроля версий в Яндексе. Мы должны как-то убедить оставшиеся 80% разработчиков, что мы достаточно стабильны, надежны и нами можно пользоваться. Ясно, что для этого нужно починить все баги и доделать те фичи, которые есть в Git.
Естественно, в какой-то перспективе мы планируем стать самодостаточными, отказаться от конвертера или развернуть его в обратную сторону, чтобы сначала все изменения попадали в Arc, а потом уже в SVN для самых стойких программистов.
Сейчас у нас большой челлендж — интеграция системы контроля версий в нашу автосборку, в наш CI и другие пайплайны. Челлендж в том, что люди слабы духом, они медленно печатают код и медленно коммитят. И загружают код себе тоже медленно. А роботы лишены этого недостатка.
В качестве анекдота — недавно для одного проекта, для их CI мы разрешили их роботу напрямую ходить в Arc, чуть-чуть коммитить. И они создали нам нагрузки в два раза больше, чем у всех разработчиков Яндекса вместе взятых. И это только маленький кусочек. Когда к нам придет большая автосборка, которая отвечает за основную часть С++-кода в монорепозитории, мы ожидаем, что нагрузка возрастет в сотни раз. К этому нужно серьезно подготовиться.
Предложение для обсуждения. Всю дорогу я повторял слова «как в Git». И в целом наш план остается прежним: интерфейсом повторять Git. Но чем больше мы это делаем, тем больше понимаем, что это не очень работает.
Есть несколько проблем. Интерфейсы Git весьма низкоуровневые. Они предлагают чуть ли не операции, которые напрямую взаимодействуют с нашим графом объектов. При этом программисты хотят каких-то высокоуровневых операций. И далеко не каждый разберется с тем, какие и как нужно выставить аргументы команде checkout или reset, чтобы ничего не испортить в рабочей копии. Я это знаю, потому что занимаюсь поддержкой пользователей, которые переходят на нашу систему контроля версий. Регулярно говоришь людям: все как в Git. «Ну вот я это сделал, и все сломалось». В Git тоже бы сломалось.
Для иллюстрации этой проблемы можно привести такой пример. Знаете такую нужную и полезную команду Git, как git begin-wave-stash?
Из зала:
— Очень полезная.
— Как вы думаете, в Git такая команда вообще есть? В этом и проблема — без любимой поисковой системы вы не только не знаете, что она делает, но и не знаете в принципе, есть ли она. Ее нет, я ее только что придумал. Поэтому Git не лишен недостатков. И раз уж мы разрабатываем свою систему контроля версий, странно не воспользоваться возможностью их исправить. Спасибо.
Неофициальная запись доклада
