

В приложении Авто.ру есть такая фича — панорамы автомобилей. Она позволяет любому сделать 3D-фото своей машины, показать её во всей красе. Как это работает и как нашим коллегам из ML удалось уместить в смартфон то, что раньше требовало целого ангара, напичканного дорогостоящим оборудованием, yaantonn уже рассказывал на Хабре.
Но отснять панораму — лишь полдела. Затем её предстоит воспроизвести, причём сделать это одинаково хорошо и на топовом флагмане, и на бюджетном смартфоне.
Что за «панорама» такая?

Панорама автомобиля — не то же самое, что панорама пейзажа.
С продуктовой стороны
Панорамой автомобиля мы называем 3D-фото машины, которое можно прокрутить и рассмотреть со всех сторон, а не только с «удачных» ракурсов, выбранных продавцом автомобиля. Кроме того, на панораме можно разметить любопытные детали экстерьера автомобиля при помощи «точек интереса».
С технической стороны

Но хоть мы и используем эвфемизм «3D-фото», на самом деле панорама автомобиля — это короткое видео (примерно на 120 кадров), которое нужно воспроизводить необычным образом.
Обычное видео чаще всего смотрят от начала и до конца, изредка перематывая вперёд. Наше же видео стоит на паузе, и когда пользователь начинает скроллить его, мы должны перемотаться на несколько кадров вперёд или назад, чтобы создать иллюзию объёмного изображения.
Наивный подход — просто плеер
Задача звучала подозрительно просто, поэтому мы отправились за консультацией к iOS-команде, которая приступила к этой фиче чуть раньше. Разработчик Дима ответил, что они взяли стандартный плеер, запихнули в него видосик и программно проматывают его на нужный кадр в зависимости от того, как двигает пальцем пользователь.
Порадовавшись за коллег, мы взяли стандартный для нас ExoPlayer, который уже успешно использовали в нескольких местах приложения. Прикрутив к нему простейший GestureDetector, запустили наш прототип на тестовой панораме и…

На слабых устройствах вместо плавного проигрывания, как у коллег на iOS, мы получили слайд-шоу. На свежих, благодаря поддержке Low Latency Media API, всё выглядело довольно прилично. Профайлер показывал сравнительно высокую задержку при доступе к кадрам и перемотке. Да вы и сами видите всё на гифке.
Что ж, на то мы и Android-разработчики, чтобы жизнь мёдом не казалась и не оставляла слишком много времени на классный UX и красивые анимации. Попросили у менеджера проекта время на R&D и начали исследовать, отчего наши панорамы так лагают.
Что не так с наивным подходом?
Как уже говорилось выше, видео с панорамой проигрывается иначе, чем обычное. Вместо того чтобы последовательно смотреть кадры один за другим, мы пытаемся получить произвольный кадр: так пользователь сможет крутить автомобиль пальцем вперёд-назад, как ему вздумается. Спойлер: в этом и кроется источник наших проблем с производительностью, ведь видеоформаты разрабатывались для обычных условий воспроизведения. Но давайте по порядку.
Как устроены видеоформаты?

Итак, мы знаем, что видео — это, по сути, последовательность изображений, называемых кадрами. Каждое изображение — уже трёхмерная структура данных, поскольку для каждого пикселя нам нужно хранить его координаты по осям x и y, а также значения основных цветов. Умножим этот объём данных на 24, 30, а то и 60 или 120 кадров в секунду и станет понятно, почему видео без сжатия вы практически никогда не встретите в повседневной жизни. Наша панорама состоит всего из 120 кадров (3 секунды при почти стандартном 30FPS) разрешением 1280х720 и без сжатия занимала бы около 316 МБ. Это катастрофически много, скачать такое видео по мобильной сети практически невозможно. Вы быстрее купите себе автомобиль на другой площадке, чем дождётесь окончания загрузки.
Spatial compression

Первое, что приходит в голову в качестве алгоритма для сжатия видео — применить старые трюки для сжатия изображений. Но даже если бы мы пережали все кадры видео в популярный формат JPEG, всё равно наш трёхсекундный видосик занимал бы около 31 МБ (в зависимости от содержания кадров).
Несмотря на то, что такие методы действительно используются для сжатия видео, это только первый этап. Чтобы зайти ещё дальше, нам нужно перестать мыслить отдельными кадрами и попытаться переиспользовать информацию между двумя и более соседними кадрами.
Temporal compression

Если внимательно изучить множество видео, можно заметить, что некоторые участки (например, красивый фон позади головы персонажа) остаются неподвижными или перемещаются в кадре практически без изменений. Это так называемая temporal redundancy, которую можно устранить, если кусочки из каких-то участков кадра переиспользовать в других кадрах. Проще всего этот механизм объяснить на MPEG-2. В нём используются три вида кадров: I-, P- и B-кадры.

- I-кадры
I-кадры ещё называют «ключевыми» — в них не используется темпоральное сжатие, поэтому они являются опорными для остальных видов кадров. Именно они служат «палитрой» для тех кусков изображения, которые перемещаются по кадру без особых изменений.
- P-кадры
P-кадры могут переиспользовать участки предыдущих кадров. Вместо того чтобы записывать всю информацию об изображении, фиксируем только какой участок какого кадра нам нужен, на сколько и в каком направлении его переместить.
- B-кадры
B-кадры могут использовать участки как предыдущих, так и следующих кадров. Для того чтобы их раскодировать, нужно дойти до следующего I-кадра.
Так почему же наивное решение тормозит?

Внимательный читатель уже догадался, что наивное решение использовать обычный плеер для доступа к произвольным кадрам рассыпается, столкнувшись с P- и B-кадрами видео. Ведь для того, чтобы отобразить такие кадры, нужно:
- Найти предыдущий (в случае B-кадра ещё и следующий) I-кадр.
- Раскодировать его и все кадры между ним и интересующим нас кадром.
- Наконец, раскодировать интересующий нас кадр и отобразить его на экране.
Причём плеер, оптимизированный под последовательное воспроизведение видео, вряд ли будет тратить ресурсы под хранение уже раскодированных промежуточных кадров. Поэтому при малейшем смещении придётся начинать процесс заново.
Распаковываем видео при помощи MediaMetadataRetriever
Мы могли бы прибегнуть к специализированным кодекам, которые используются для монтажа и предоставляют неплохое сжатие при существенно меньших задержках доступа к произвольным кадрам видео. Но это не очень оправдано, так как возросла бы нагрузка на сеть, да и не все девайсы поддерживают эти кодеки. Особенно старые модели, на которых мы и хотели починить производительность.
Для того чтобы сохранить низкий объём передаваемых по сети данных, но при этом иметь хорошую скорость произвольного доступа к отдельным кадрам, мы можем предварительно раскодировать всё видео в последовательность изображений и навигироваться уже по ним.
MediaMetadataRetriever API
У MediaMetadataRetriever довольно-таки простое API. Нам всего-то нужно передать URI нашего видео и последовательно вычитать все фреймы в битмапу.
val retriever = MediaMetadataRetriever()
try {
retriever.setDataSource(context, videoUri)
val framesCount = retriever
.extractMetadata(MediaMetadataRetriever.METADATA_KEY_VIDEO_FRAME_COUNT)
?.toIntOrNull() ?: 0
for (i in 0 until framesCount) {
retriever.getFrameAtIndex(i)?.let { bm ->
bm.writeToFile(file)
bm.recycle()
}
}
} finally {
retriever.release()
}Проверяем работу

Как и ожидалось, работая с отдельными кадрами без темпорального сжатия, мы получаем плавную анимацию без рывков и проблем со временем доступа.
Замеряем время на распаковку
Но теперь перед проигрыванием видео у нас появился этап распаковки. Необходимо было его замерить, чтобы перед просмотром пользователи не наблюдали грустную крутилку панорам. На распаковку уходило три секунды. Время не очень хорошее, но приемлемое.
И тогда мы достали из нашего Гиперкуба Nexus 6. Когда-то «топ за свои деньги», этот легендарный старичок теперь выполняет роль референса low-end-девайса. Ух, сколько разработчиков он обломал перед выкаткой. Обломал он и нас: результат в 35 секунд на извлечение был просто ужасен. Пришлось возвращаться к R&D и думать, как это улучшить.
| Девайс | Время |
|---|---|
| OnePlus 9 Pro | 3,5 с |
| Nexus 6 | 35 с |
Ищем способы сделать это быстрее на Low Level
Когда что-то тормозит, можно попытаться спуститься на уровень абстракции ниже и взять дело в свои руки. Просмотр сорcов MediaMetadataRetriever показал, что в чём кроется возможная причина тормозов: на каждый вызов getFrameAtIndex создаётся новый декодер и отматывается на нужный кадр. А как мы знаем, произвольный доступ к кадрам — не очень быстрая штука.
К счастью, Android предоставляет доступ к низкоуровневым API для работы с медиафайлами. Одной из важных для нас сущностей является MediaCodec, открывающий доступ к кодекам, которые поддерживает девайс.
Как работают кодеки в Android
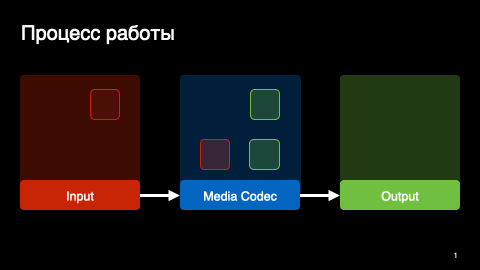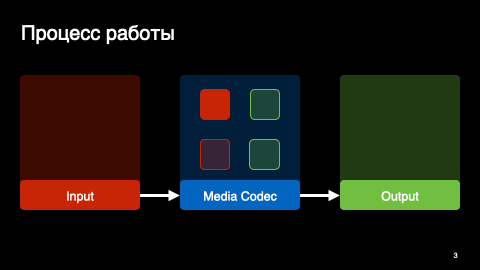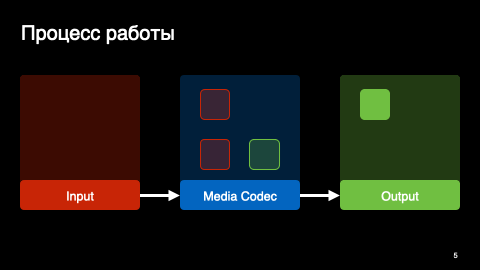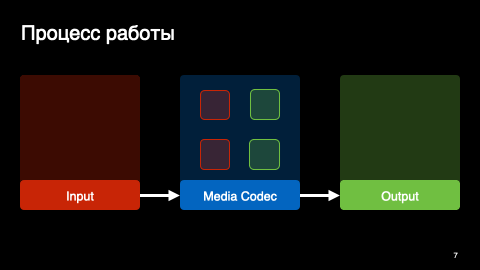
MediaCodec — это сигнальный процессор с входным и выходным буферами. Мы загружаем наши байтики во входной буфер и получаем распакованные кадры в выходном.
MediaExtractor
Мы не можем просто положить файл во входной буфер и ждать чуда. Для того чтобы кодек мог распаковать наше видео, он должен узнать множество параметров: формат, битрейт, в каком разрешении был записан видеофайл.
К счастью, вся необходимая информация хранится в заголовках самого файла. А в Low Level Media API есть удобный класс MediaExtractor, который достанет всё необходимое за нас.
// Создаём кодек
val extractor = MediaExtractor()
extractor.setDataSource(context, uri, null)
var format: MediaFormat? = null
var decoder: MediaCodec? = null
for (i in 0 until extractor.trackCount) {
// находим mime видео потока
format = extractor.getTrackFormat(i)
val mime = format.getString(MediaFormat.KEY_MIME)
if (mime != null && mime.startsWith("video/")) {
extractor.selectTrack(i)
// создаём кодек с этим mime
decoder = MediaCodec.createByCodecName(mime)
break
}
}
// запомним разрешение видео, оно нам ещё пригодится
val width = format.getInteger(MediaFormat.KEY_WIDTH)
val height = format.getInteger(MediaFormat.KEY_HEIGHT)
val surface = createSurface(width, height)
// скармливаем дополнительные данные о формате
// а также выходной буфер кодеку
decoder.configure(format, surface, null, 0)Стейт-машина
Теперь, когда мы вытащили форматы из файла и натравили на них наш кодек, можем приступать к распаковке. Документация на https://developers.android.com подробно описывает работу этого кодека. Самое интересное в ней — картинка с состояниями, которые может принимать класс кодека.

На этой схеме видно, что после вызова decoder.configure(...) наш кодек переходит в состояние configured и ждёт, пока мы запустим его и начнём использовать. Весь процесс почти умещается в один цикл, в ходе которого мы постоянно читаем новые чанки с помощью MediaExtractor и отдаём их кодеку.
fun doExtract(
extractor: MediaExtractor,
decoder: MediaCodec,
onFrameDecoded: () -> Unit
) {
val infor = MediaCodec.BufferInfo()
val isOutputDone = false
val isInputDone = false
val frameIndex = 0
while (!isOutputDone) {
// Даём информацию на вход кодеку
if (!isInputDone) {
// Получаем индекс буфера
val inputBufferIndex = decoder.dequeueInputBuffer(BUFFER_TIMEOUT_US)
// Если этот индекс больше нуля, то этот буфер доступен для распаковки
if (inputBufferIndex >= 0) {
val inputBuffer = decoder.getInputBuffer(inputBufferIndex)
val chunkSize = extractor.readSampleData(inputBuffer, 0)
// Если количество оставшихся чанков меньше нуля, то мы знаем, что поток данных закончился
if (chunkSize < 0) {
// И нам нужно отправить сигнал об окончании потока в кодек
decoder.queueInputBuffer(inputBufferIndex, 0, 0, 0L, MediaCodec.BUFFER_FLAG_END_OF_STREAM)
isInputDone = true
} else {
// Иначе мы просто передаём новый буфер в кодек
val presentationTimeUs = extractor.sampleTime
decoder.queueInputBuffer(inputBufferIndex, 0, chunkSize, presentationTimeUs, 0)
// И переводим экстрактор дальше, на следующий индекс
extractor.advance()
}
}
}
// Используем результаты работы кодека
if (!isOutputDone) {
val decoderStatus = dequeueOutputBuffer(info, BUFFER_TIMEOUT_US)
when {
decoderStatus == MediaCodec.INFO_TRY_AGAIN_LATER -> {
// Выходной буфер ещё пуст
}
decoderStatus == MediaCodec.INFO_OUTPUT_BUFFERS_CHANGED -> {
// Для нас не важный статус, так как мы будем использовать Surface
}
decoderStatus == MediaCodec.INFO_OUTPUT_FORMAT_CHANGED -> {
// Выходной формат поменялся
}
decoderStatus < 0 -> {
error("unexpected result from decoder.dequeueOutputBuffer: $decoderStatus")
}
decoderStatus >= 0 -> { // Всё ок, можем отображать данные
// Если мы достигли конца потока, то можем прерывать цикл
if ((info.flags and MediaCodec.BUFFER_FLAG_END_OF_STREAM) != 0) {
isOutputDone = true
}
// На всякий случай проверяем, что выходные данные вообще есть
val doRender = info.size != 0
// Сообщаем кодеку, что он может отправлять выходной буфер на surface
decoder.releaseOutputBuffer(decoderStatus, doRender)
if (doRender) {
// Сообщаем в коллбэк, что мы раскодировали очередной кадр
onFrameDecoded(frameIndex)
frameIndex++
}
}
}
}
}
}Surface
Раскодированные данные нужно как-то использовать. Мы бы хотели разложить их покадрово в файловой системе для удобного доступа. Чтобы это сделать, сырые данные кодека нужно превратить в битмап. В этом нам поможет отображение кадров на Surface и копирование его пикселей в битмап.
Но сначала Surface нужно создать. Под капотом его обычно создают TextureView и SurfaceView, но нам не нужно отображать этот Surface, поэтому тут мы сэкономим и создадим его сами. В репозитории с семплами работы с Low Level Media API https://github.com/google/grafika есть неплохие примеры того, как создать off-screen Surface и пара утильных классов, которые можно забрать к себе в проект. Один из них — EglCore, прячущий под капот всякие OpenGL-флажочки и за пару методов создающий Surface со всеми нужными настройками.
import com.android.grafika.gles.EglCore
val eglCore = EglCore(null, EglCore.FLAG_TRY_GLES3)
val eglSurface = eglCore.createOffscreenSurface(width, height)
eglCore.makeCurrent(eglSurface)
val textureRenderProgram = TextureRenderProgram()
val surfaceTexture = SurfaceTexture(textureRenderProgram.textureId)
surfaceTexture.setOnFrameAvailableListener(this)
val surface = Surface(surfaceTexture)TextureRenderProgram
Выше мы создали Surface, передав ему некоторую текстурную программу, с помощью которой можем отобразить наш кадр текстурой на прямоугольнике, растянутом на весь экран. К сожалению, в OpenGL даже такую простую задачу выполнить не так легко. Даже для самой простой программы на OpenGL нужно два компонента: вертексный и фрагментный шейдеры.
fun createTextureRenderProgram(): Int {
val vertexShader = loadShader(GLES20.GL_VERTEX_SHADER, VERTEX_SHADER)
val fragmentShader = loadShader(GLES20.GL_FRAGMENT_SHADER, FRAGMENT_SHADER)
val program: Int = GLES20.glCreateProgram()
GLES20.glAttachShader(program, vertexShader)
GLES20.glAttachShader(program, fragmentShader)
GLES20.glLinkProgram(program)
return program
}Вертексный шейдер
Хотя бы шейдеры будут достаточно простыми сами по себе. Суть вертексного шейдера — производить манипуляции над вершинами и как-то сопоставлять их с координатами текстур. В нашем случае вершины остаются на месте, поэтому мы их передаём как есть в gl_Position. А вот вершины текстуры мы умножаем на матрицу, которую получим из текстурной программы, чтобы расположить текстуру на нашем прямоугольнике.
uniform mat4 uTextureMatrix;
attribute vec4 aPosition;
attribute vec4 aTextureCoord;
varying vec2 vTextureCoord;
void main() {
gl_Position = aPosition;
vTextureCoord = (uTextureMatrix * aTextureCoord).xy;
}Фрагментный шейдер
Фрагментный шейдер, отвечающий за окраску непосредственно пикселей, в нашем случае ещё проще вертексного. Мы просто отображаем текстуру в текущей точке, и на этом всё.
#extension GL_OES_EGL_image_external : require
precision mediump float;
varying vec2 vTextureCoord;
uniform samplerExternalOES sTexture;
void main() {
gl_FragColor = texture2D(sTexture, vTextureCoord);
}Сочиняем прямоугольник для вертексного шейдера
Для того чтобы вертексный шейдер отработал, нужно передать ему данные о прямоугольнике, который мы хотим нарисовать. Система координат фрейма довольно простая: её центр находится в (0, 0), а по краям координаты варьируются от (-1, -1) слева внизу до (1, 1) справа вверху. Зная это, несложно сочинить такую матрицу, чтобы растянуть наш прямоугольник на весь фрейм.

val triangleVerticesData = floatArrayOf(
// X, Y, Z, U, V
-1.0f, -1.0f, 0f, 0f, 0f,
1.0f, -1.0f, 0f, 1f, 0f,
-1.0f, 1.0f, 0f, 0f, 1f,
1.0f, 1.0f, 0f, 1f, 1f,
)
const val FLOAT_SIZE_BYTES = 4
const val TRIANGLE_VERTICES_DATA_STRIDE_BYTES = 5 * FLOAT_SIZE_BYTES
val triangleVertices: FloatBuffer =
ByteBuffer.allocateDirect(triangleVerticesData.size * FLOAT_SIZE_BYTES)
.order(ByteOrder.nativeOrder())
.asFloatBuffer()Каждый ряд этой матрицы описывает координаты некоторой точки. Заметим, что нам нужно перечислять точки как бы зигзагом, потому что OpenGL умеет рисовать только точки, линии и треугольники. При этом повторять точки, чтобы «закрыть» треугольники, совсем не обязательно.

При этом UV-координаты, ответственные за расположение текстуры, нужно расположить так, чтобы координата (0, 0) оказалась в левом нижнем углу экрана, а (1, 1) — в правом верхнем.

Отображаем наш фрейм
Сначала нужно передать шейдерам данные, которые мы для них подготовили: координаты вертексов нашего прямоугольника и текстуру, в которую мы будем читать байты. Также указываем, из какого смещения в нашу матрицу попали данные, интересующие шейдер.
val aPosition = GLES20.glGetAttribLocation(program, "aPosition")
val aTextureCoord = GLES20.glGetAttribLocation(program, "aTextureCoord")
val uSTMatrix = GLES20.glGetUniformLocation(program, "uTextureMatrix")
val textures = IntArray(1)
GLES20.glGenTextures(1, textures, 0)
val textureId = textures[0]
GLES20.glBindTexture(GLES11Ext.GL_TEXTURE_EXTERNAL_OES, textureId)
triangleVertices.position(TRIANGLE_VERTICES_DATA_POS_OFFSET)
GLES20.glVertexAttribPointer(programSetup.aPosition, 3, GLES20.GL_FLOAT, false, TRIANGLE_VERTICES_DATA_STRIDE_BYTES, triangleVertices)
GLES20.glEnableVertexAttribArray(programSetup.aPosition)
GLES20.glVertexAttribPointer(maTextureHandle, 2, GLES20.GL_FLOAT, false, TRIANGLE_VERTICES_DATA_STRIDE_BYTES, mTriangleVertices)
GLES20.glEnableVertexAttribArray(maTextureHandle)Далее, обновив текстуру из коллбэка кодека (вы же ещё помните про кодек?), мы можем её нарисовать и собрать в пиксельный буфер для перегонки в битмап.
surfaceTexture.updateTexImage()
textureRenderProgram.drawFrame(surfaceTexture)
val pixelBuf: ByteBuffer = ByteBuffer.allocateDirect(width * height * 4).apply {
order(ByteOrder.LITTLE_ENDIAN)
}
// Wait for onFrameAvailable() to signal us.
pixelBuf.rewind()
GLES20.glReadPixels(0, 0, width, height, GLES20.GL_RGBA, GLES20.GL_UNSIGNED_BYTE, pixelBuf)
return pixelBuf.toBitmap(width, height)После того как мы получили битмап, дальше можем сохранять его на диск, отображать пользователю, да и вообще делать с ним всё что угодно.
Все ещё долго распаковывается?
Давайте посмотрим, что же получилось в результате. Удалось ли нам выиграть по времени? Замеры показывают, что да, и намного. Предположение о том, что переиспользование одного инстанса кодека и последовательная распаковка видео победит стандартный getFrameAtIndex оказалось более чем верным.
Было:
Стало:

| Device | MediaMetadataRetriever | Custom solution |
|---|---|---|
| OnePlus 9 Pro | 3,5 с | 2,5 с |
| Nexus 6 | 35 с | 9 с |
C такими результатами можно жить! Да и пространство для оптимизаций стремительно сокращается и приближается к «красной зоне» по Шипилеву, поэтому на данном шаге остановились и пустили решение в релиз!
Выводы
Конечно, у нашего решения есть и минусы. Помните, что 120 кадров в джипеге занимают приличное по меркам мобильных устройств место? Хоть мы больше не передаём видео покадрово, теперь мы распаковываем его в такие же кадры. Он занимает много места: хранить много панорам в распакованном виде не получится.
Пришлось сделать механизм очистки кеша, который зачищает старые кадры. Но это компромисс между количеством передаваемых по сети данных и оверхедом на распаковку видео. Для нас было важно, чтобы в прекрасном будущем, когда панорамами обзаведутся все объявления о продаже автомобилей, приложение Авто.ру не стало бы главным потребителем трафика на вашем смартфоне.
А как бы вы расставили приоритеты в этой задаче? Пишите в комментариях.
