
Меня зовут Илья, я отвечаю за инфраструктуру пользовательских продуктов в Яндекс Go. Мы строим цикл заказа такси — процессы, происходящие под капотом после того, как пользователь нажимает «Заказать». Поиск машины, назначение водителя, изменение адреса, оплата поездки — всё это части цикла. Ещё мы делаем инфраструктуру создания циклов, которая используется в Еде, Лавке, Доставке и других направлениях внутри Яндекса.
Но обо всём по порядку. Давайте расскажу историю того, как мы развивали механизм обработки заказа, адаптировали его под нужды пользователей и старались исключить ошибки, а главное, почему мы используем такую архитектуру сейчас. Если у вас на бэкенде тоже выполняются последовательности зависящих друг от друга действий, и не оставляет желание оптимизировать логику — то тем более добро пожаловать под кат.
В 2011 году мы запустили сервис заказа такси. В первой реализации в бэкенде был endpoint /create-order, внутри которого мы создавали заказ, искали ближайшую машину и отправляли заказ водителю (кстати, если вы не знали о том, как устроен поиск водителя, то обязательно почитайте).

Получается, в момент поиска бэкенд должен сделать несколько действий подряд, каждое из которых может сломаться с небольшой вероятностью. В этом случае нужно, чтобы кто-то повторил действия, продолжив с нужного места. Проще всего попросить это делать пользователя. Но у такого решения есть проблемы: например, пользователь может не отправить запрос повторно, поскольку у него пропал интернет, разрядился телефон или потому что человек просто закрыл приложение. Тогда (в случае ошибки) бэкенд выполнит только часть действий. Скажем, назначит на заказ водителя, но не сообщит об этом. Мы не хотим такого допускать — это может привести к тому, что пассажир и водитель не смогут встретиться и начать поездку. Для решения проблемы мы вынесли последовательность действий, которую нужно совершить для заказа, в отдельную асинхронную задачу на бэкенде — она перезапускается сама в случае ошибки. Теперь клиент получает ответ о том, что заказ принят к обработке, а сами действия по назначению водителя выполняются асинхронно. Даже если пользователь закроет приложение, мы будем уверены, что заказ пройдёт все нужные стадии обработки.
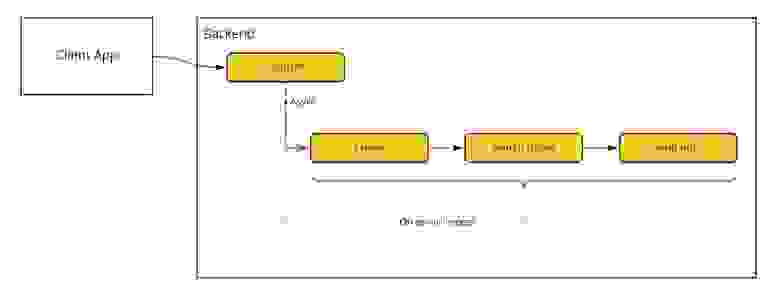
Саму последовательность действий, которую нужно выполнять асинхронно, мы назвали процедурой обработки заказа или процессингом.
Чтобы заводить асинхронные задачи, поначалу взяли самое простое решение — запускать на серверах крон-таски, выполняющиеся раз в минуту. Внутри крона мы сканировали базу данных на наличие новых заказов и запускали их в обработку. К сожалению, и тут не всё было гладко. Во-первых, заказы, добавленные сразу после запуска крона, могли пролежать без дела целую минуту, а мы не хотим заставлять пользователя ждать. Во-вторых, все решения, которые мы разрабатываем в Яндексе, должны уметь переживать отказы единичных серверов. (Даже более того: все наши сервисы сейчас представлены в двух-трёх зонах доступности и умеют переживать отключение как минимум одной из них.) Решение на кронах плохо горизонтально масштабируется — нужно, чтобы один заказ не обрабатывался одновременно на нескольких серверах. Значит, нужно придумывать распределенные блокировки. Архитектура такого решения становится избыточной, её сложно понимать и поддерживать.
Поэтому следующим нашим шагом стал переход цикла заказа на Сelery. Это широко используемый проект, с помощью которого можно организовать фоновую обработку задач. Celery написана на Python, поддерживает несколько брокеров сообщений и баз данных для хранения результатов задач. В нашей конфигурации мы использовали MongoDB в качестве брокера, потому что у Такси уже был богатый опыт работы с этой базой. Бэкенд ставил задачу в очередь, Celery-worker получал задачу и выполнял нужную последовательность действий — поиск водителя и отправку предложения о заказе ему на устройство. Если какая-то операция приводила к ошибке, задача перезапускалась.
Некоторое время всё работало успешно, но однажды Celery перестала справляться с нагрузкой. Существенным фактором было то, что мы не хотели поддерживать зоопарк баз данных и использовали только MongoDB, а Celery с ней работает не так хорошо, как хотелось бы.
Мы прикинули за и против и решили разрабатывать собственную платформу для запуска асинхронных задач. Начали с небольшого проекта на Python и MongoDB. Решение оказалось удачным и продолжило развиваться.
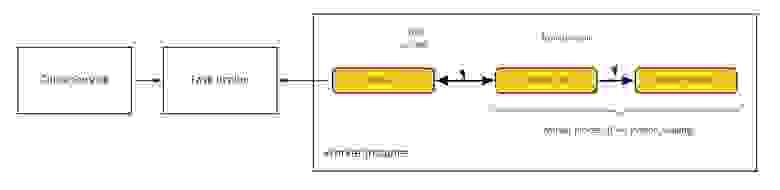
Если разработчик хочет обрабатывать свои задачи, то ему нужно объявить под это функцию у себя в сервисе, и она будет вызываться в нужные моменты. После этого надо зарегистрировать очередь в системе — и можно отправлять задачи в брокер. Тот проследит, чтобы задача была выполнена как минимум один раз, при этом не допустит ситуации, когда задача выполняется несколькими обработчиками одновременно. Разработчик может контролировать, какие сервисы и с какой частотой могут добавлять задачу в очередь, не копятся ли в очереди необработанные задачи, и устанавливать максимальную пропускную способность «разгребания» задач.
Внутри система состоит из stateless-брокера задач, хранилища данных и обвязки на стороне обработчика. Рядом с кодом обработчика стоит side-car-демон, то есть агент, который с одной стороны взаимодействует с брокером задач, а с другой — с библиотекой интеграции внутри обработчика. Агент следит за состоянием обработчика, собирает метрики и группирует задачи, уменьшая нагрузку на брокер. Такая архитектура позволяет быстро добавлять поддержку новых языков: зависящая от языка часть системы совсем маленькая и пишется опытным разработчиком за пару дней. Например, недавно мы добавили поддержку Go.
Платформа сейчас обрабатывает десятки тысяч задач в секунду. Время от постановки задачи до начала выполнения в среднем составляет всего пару десятков миллисекунд.
Иногда пользователи отменяют заказы. В 2015 году случалось, что на такие отменённые заказы всё же приезжали водители. Проблема возникало достаточно редко, всего несколько раз в неделю, но пользовательский опыт от этого сильно страдал. Оказалось, что возникал race condition между отправкой предложения водителю и отменой заказа пользователем.
Такую проблему можно решить разными способами. Мы решили создать лог событий, отражающих всё, что происходит с заказом, и актора, который будет применять события друг за другом.
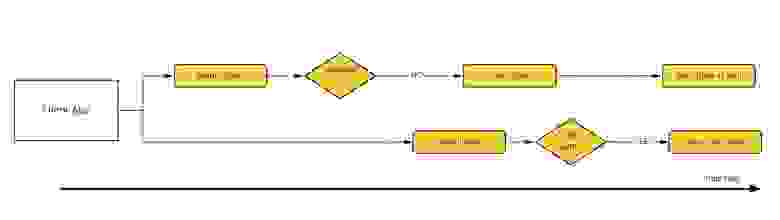
У нас появилась точка сериализации, по логу мы всегда можем определить порядок событий — для любых двух из них можно понять, какое произошло раньше. Пусть при создании заказа генерируется событие create, когда мы находим подходящего водителя — new_driver_found, в при отмене — cancel. Тогда при конкурирующих поиске и отмене может возникнуть две последовательности событий.
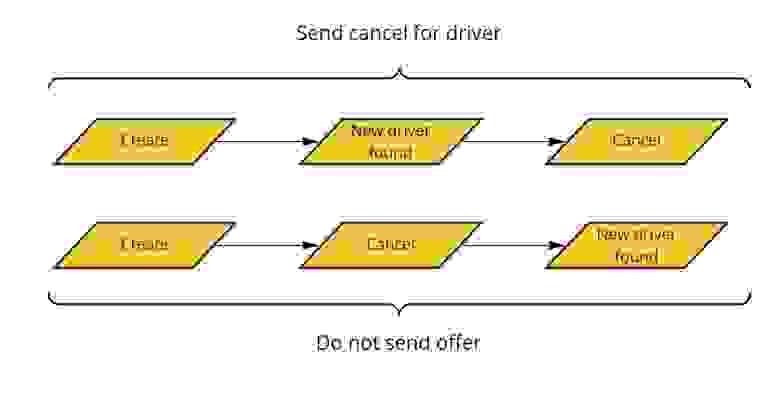
В первом сценарии нужно отправить водителю отмену, а во втором — вообще не отправлять ему предложение. Получается, что действия, которые необходимо производить при обработке каждого события, зависят от текущего состояния заказа. Так у нас появился конечный автомат заказа и цикл его обработки. К этой архитектуре мы пришли примерно к 2016 году.
С развитием проекта росло и количество действий, необходимых для обработки каждого события. Появлялась поддержка новых способов оплаты, добавлялись тарифы и сценарии использования, например доставка. Запустился Яндекс Плюс — то есть добавилась механика начисления кешбэка и списания баллов. К 2019 году перед нами встала задача управления сложностью нашей конструкции. Мы постарались максимально структурировать схему. Сделали собственный DSL — специализированный под задачу язык описания действий, которые нужно выполнять при обработке заказа. Взяли фреймворк userver и написали рантайм, который выполнял код на нашем DSL.
Действия могут быть такими: сходить в сервис по HTTP или отправить сообщение в очередь. Последнее, если нужно выполнить действие безусловно, работает отлично. Например, можно отправить сообщение «начать поиск машины». Когда надо получить результат от сервиса, удобнее написать HTTP-запрос. В том числе, назначая водителя на заказ, мы отправляем запрос в сервис driver-app-api. Тот отвечает, удалось ли зарезервировать машину или по какой-то причине не удалось. От ответа зависят наши дальнейшие шаги — ждать, пока водитель доедет до пассажира, или начать новый поиск.
На нашем DSL описание этой логики выглядит примерно так:
Быстро оказалось, что наш подход к конструированию цикла заказа можно переиспользовать и для других проектов, например для обработки платежей или заказов в Лавке. Вот только формат заказов у этих сервисов сильно отличается от Такси, да и сами переходы конечного автомата не имеют с Такси ничего общего. Мы сделали ещё одну итерацию разработки, чтобы полностью отвязать наш процессинг от цикла заказа такси. Команда разработала хранилище событий, разделив его на горячую и холодную части. Так мы можем запоминать всё, что происходит с заказами (это очень помогает поддержке), и при этом не проседать в производительности. Добавили в наш DSL возможность декларативного описания переходов конечного автомата, чтобы разработчики Еды или Лавки могли описать свои циклы обработки. В результате получили инфраструктуру для создания циклов обработки чего угодно, processing as a service.
Продуктовые требования к нашей инфраструктуре получаются очень противоречивыми. С одной стороны, нужно обрабатывать заказы как можно быстрее. Нельзя допускать, чтобы время поиска водителя увеличилось на десятки секунд из-за проблем с каким-нибудь компонентом: пользователям вряд ли такое понравится.
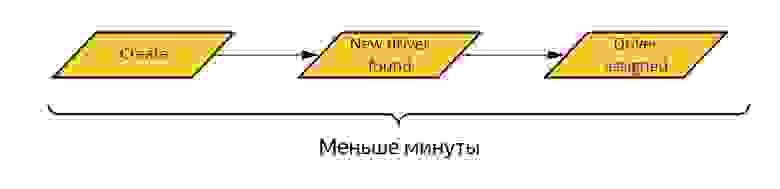
Посмотрим на пример выше. Мы хотим приступить к обработке события new_driver_found как можно раньше — в идеале, сразу после того, как оно произошло. Но мы действуем последовательно — значит, сначала должны обработать событие created и только потом перейти к new_driver_found. А обработка каждого события состоит из десятков действий, каждое из которых может потенциально сломаться — и затормозить весь конечный автомат.
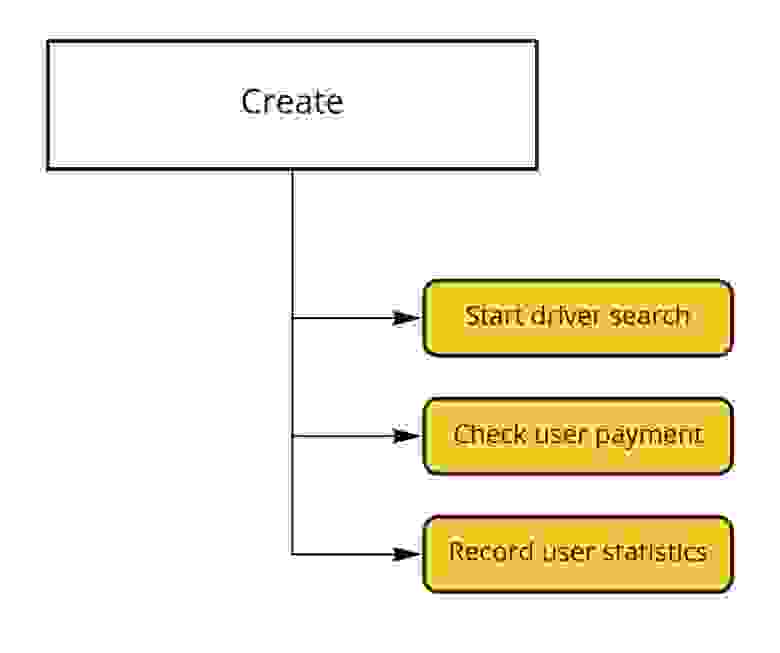
Мы придумали несколько стратегий, которые помогают сочетать быструю обработку событий с сохранением их последовательности.
Чтобы переживать отказы единичных обработчиков, мы развиваем систему стратегий фолбэков. Нам нужно уметь обнаруживать отказы и справляться с ними. Задача определения отказов на первый взгляд выглядит простой: если мы сходили в сервис по HTTP и получили 503, значит, сервис не работает. Правда, бывают врéменные флапы, если, скажем, переключился мастер одного из десяти шардов базы данных. Вряд ли можно считать, что сервис при этом сломался: процесс завершится за несколько секунд и пользователи ничего не заметят. Поэтому не стоит отключать сервис сразу, когда на нём появляются ошибки. Для более надёжной детекции мы подсчитываем статистику в некотором окне. Подробнее о том, как всё устроено, можно почитать в этом конспекте.
Иногда сервис не работает только для пользователей, заказавших такси на полнолуние в Нижних Васюках. Такой пользователь может быть всего один, для него сервис определённо сломан, а на статистике в разрезе сервиса этого не видно. Но нам важна история каждого пользователя, поэтому мы ведём статистику не только в разрезе сервиса, но и в разрезе определённого заказа: даже одна зависшая поездка будет замечена, а баг, который вызвал зависание, пофиксят.
Мы научились определять отказы сервисов, но что можно сделать, чтобы пережить отказ? Мы рассматриваем несколько возможных политик фолбэков:
Когда мы делаем систему, в которой взаимодействуют десятки микросервисов, неизбежно возникают проблемы совместимости интерфейсов. У нас интерпретируемый DSL, поэтому мы узнаём о таких проблемах, только когда они случаются. Чтобы легче справляться с этой проблемой, нам пришлось сделать механизм интеграционных тестов для циклов процессинга, которые пишут наши коллеги из Еды и Лавки. В Такси мы используем кодогенерацию интерфейсов на основе схем OpenAPI (Swagger) — в теории можно настроить валидацию потоков с помощью статического анализа. Но это уже планы на будущее.
Мы успешно обрабатываем тысячи событий в секунду для задач Такси, Лавки и логистики, а значит, наш подход имеет право на жизнь. Возможно, вы найдёте что-то общее между проблемами, которые решаете сами, и теми, с которыми пришлось столкнуться нам, и тогда мой рассказ поможет вам посмотреть на ваши процессы со стороны. А может, вы решаете такую же задачу другим способом, я был бы рад, если бы вы поделились своим опытом. Я не старался описать наше решение суперподробно, чтобы статью можно было осилить за один присест. Если интересно раскрыть какую-то тему детальнее, то спрашивайте в комментариях.
Но обо всём по порядку. Давайте расскажу историю того, как мы развивали механизм обработки заказа, адаптировали его под нужды пользователей и старались исключить ошибки, а главное, почему мы используем такую архитектуру сейчас. Если у вас на бэкенде тоже выполняются последовательности зависящих друг от друга действий, и не оставляет желание оптимизировать логику — то тем более добро пожаловать под кат.
Как всё начиналось
В 2011 году мы запустили сервис заказа такси. В первой реализации в бэкенде был endpoint /create-order, внутри которого мы создавали заказ, искали ближайшую машину и отправляли заказ водителю (кстати, если вы не знали о том, как устроен поиск водителя, то обязательно почитайте).

Получается, в момент поиска бэкенд должен сделать несколько действий подряд, каждое из которых может сломаться с небольшой вероятностью. В этом случае нужно, чтобы кто-то повторил действия, продолжив с нужного места. Проще всего попросить это делать пользователя. Но у такого решения есть проблемы: например, пользователь может не отправить запрос повторно, поскольку у него пропал интернет, разрядился телефон или потому что человек просто закрыл приложение. Тогда (в случае ошибки) бэкенд выполнит только часть действий. Скажем, назначит на заказ водителя, но не сообщит об этом. Мы не хотим такого допускать — это может привести к тому, что пассажир и водитель не смогут встретиться и начать поездку. Для решения проблемы мы вынесли последовательность действий, которую нужно совершить для заказа, в отдельную асинхронную задачу на бэкенде — она перезапускается сама в случае ошибки. Теперь клиент получает ответ о том, что заказ принят к обработке, а сами действия по назначению водителя выполняются асинхронно. Даже если пользователь закроет приложение, мы будем уверены, что заказ пройдёт все нужные стадии обработки.

Саму последовательность действий, которую нужно выполнять асинхронно, мы назвали процедурой обработки заказа или процессингом.
Как у нас появилась своя очередь задач
Чтобы заводить асинхронные задачи, поначалу взяли самое простое решение — запускать на серверах крон-таски, выполняющиеся раз в минуту. Внутри крона мы сканировали базу данных на наличие новых заказов и запускали их в обработку. К сожалению, и тут не всё было гладко. Во-первых, заказы, добавленные сразу после запуска крона, могли пролежать без дела целую минуту, а мы не хотим заставлять пользователя ждать. Во-вторых, все решения, которые мы разрабатываем в Яндексе, должны уметь переживать отказы единичных серверов. (Даже более того: все наши сервисы сейчас представлены в двух-трёх зонах доступности и умеют переживать отключение как минимум одной из них.) Решение на кронах плохо горизонтально масштабируется — нужно, чтобы один заказ не обрабатывался одновременно на нескольких серверах. Значит, нужно придумывать распределенные блокировки. Архитектура такого решения становится избыточной, её сложно понимать и поддерживать.
Поэтому следующим нашим шагом стал переход цикла заказа на Сelery. Это широко используемый проект, с помощью которого можно организовать фоновую обработку задач. Celery написана на Python, поддерживает несколько брокеров сообщений и баз данных для хранения результатов задач. В нашей конфигурации мы использовали MongoDB в качестве брокера, потому что у Такси уже был богатый опыт работы с этой базой. Бэкенд ставил задачу в очередь, Celery-worker получал задачу и выполнял нужную последовательность действий — поиск водителя и отправку предложения о заказе ему на устройство. Если какая-то операция приводила к ошибке, задача перезапускалась.
Некоторое время всё работало успешно, но однажды Celery перестала справляться с нагрузкой. Существенным фактором было то, что мы не хотели поддерживать зоопарк баз данных и использовали только MongoDB, а Celery с ней работает не так хорошо, как хотелось бы.
Мы прикинули за и против и решили разрабатывать собственную платформу для запуска асинхронных задач. Начали с небольшого проекта на Python и MongoDB. Решение оказалось удачным и продолжило развиваться.
Если разработчик хочет обрабатывать свои задачи, то ему нужно объявить под это функцию у себя в сервисе, и она будет вызываться в нужные моменты. После этого надо зарегистрировать очередь в системе — и можно отправлять задачи в брокер. Тот проследит, чтобы задача была выполнена как минимум один раз, при этом не допустит ситуации, когда задача выполняется несколькими обработчиками одновременно. Разработчик может контролировать, какие сервисы и с какой частотой могут добавлять задачу в очередь, не копятся ли в очереди необработанные задачи, и устанавливать максимальную пропускную способность «разгребания» задач.
Внутри система состоит из stateless-брокера задач, хранилища данных и обвязки на стороне обработчика. Рядом с кодом обработчика стоит side-car-демон, то есть агент, который с одной стороны взаимодействует с брокером задач, а с другой — с библиотекой интеграции внутри обработчика. Агент следит за состоянием обработчика, собирает метрики и группирует задачи, уменьшая нагрузку на брокер. Такая архитектура позволяет быстро добавлять поддержку новых языков: зависящая от языка часть системы совсем маленькая и пишется опытным разработчиком за пару дней. Например, недавно мы добавили поддержку Go.

Платформа сейчас обрабатывает десятки тысяч задач в секунду. Время от постановки задачи до начала выполнения в среднем составляет всего пару десятков миллисекунд.
Почему нужна сериалиазция событий
Иногда пользователи отменяют заказы. В 2015 году случалось, что на такие отменённые заказы всё же приезжали водители. Проблема возникало достаточно редко, всего несколько раз в неделю, но пользовательский опыт от этого сильно страдал. Оказалось, что возникал race condition между отправкой предложения водителю и отменой заказа пользователем.

Такую проблему можно решить разными способами. Мы решили создать лог событий, отражающих всё, что происходит с заказом, и актора, который будет применять события друг за другом.
[
{
"timestamp": 1634156405029,
"key": "create",
},
{
"timestamp": 1634156433765,
"key": "new-driver-found",
"driver-id": "xxAAA"
},
{
"timestamp": 1634156433765,
"key": "cancel"
}
// ...
]У нас появилась точка сериализации, по логу мы всегда можем определить порядок событий — для любых двух из них можно понять, какое произошло раньше. Пусть при создании заказа генерируется событие create, когда мы находим подходящего водителя — new_driver_found, в при отмене — cancel. Тогда при конкурирующих поиске и отмене может возникнуть две последовательности событий.

В первом сценарии нужно отправить водителю отмену, а во втором — вообще не отправлять ему предложение. Получается, что действия, которые необходимо производить при обработке каждого события, зависят от текущего состояния заказа. Так у нас появился конечный автомат заказа и цикл его обработки. К этой архитектуре мы пришли примерно к 2016 году.
class OrderStateMachine:
def __init__(self):
self.status = 'pending'
self.driver_id = None
def process_event(self, event):
# ...
if (self.status == 'pending' and event.key == 'new-driver-found'):
self.status = 'assigned'
self.driver_id = event.driver_id
elif (self.status == 'assigned' and event.key == 'cancel'):
self.status = 'canceled'
send_cancel_to_driver(self.driver_id)
# ...
def process_order(event_log):
processor = OrderStateMachine()
for event in event_log:
processor.process_event(event_log)К чему мы пришли в 2021 году
С развитием проекта росло и количество действий, необходимых для обработки каждого события. Появлялась поддержка новых способов оплаты, добавлялись тарифы и сценарии использования, например доставка. Запустился Яндекс Плюс — то есть добавилась механика начисления кешбэка и списания баллов. К 2019 году перед нами встала задача управления сложностью нашей конструкции. Мы постарались максимально структурировать схему. Сделали собственный DSL — специализированный под задачу язык описания действий, которые нужно выполнять при обработке заказа. Взяли фреймворк userver и написали рантайм, который выполнял код на нашем DSL.
Действия могут быть такими: сходить в сервис по HTTP или отправить сообщение в очередь. Последнее, если нужно выполнить действие безусловно, работает отлично. Например, можно отправить сообщение «начать поиск машины». Когда надо получить результат от сервиса, удобнее написать HTTP-запрос. В том числе, назначая водителя на заказ, мы отправляем запрос в сервис driver-app-api. Тот отвечает, удалось ли зарезервировать машину или по какой-то причине не удалось. От ответа зависят наши дальнейшие шаги — ждать, пока водитель доедет до пассажира, или начать новый поиск.
На нашем DSL описание этой логики выглядит примерно так:
stages:
- id: book-driver
handlers:
- /drivers-app-module/send-offer
result:
book-result: /handlers/send-offer/response/body/result
- id: restart-search
handlers:
- /lookup-module/start-search
enabled-if-equal:
- /shared-state/book-result
- "success"Быстро оказалось, что наш подход к конструированию цикла заказа можно переиспользовать и для других проектов, например для обработки платежей или заказов в Лавке. Вот только формат заказов у этих сервисов сильно отличается от Такси, да и сами переходы конечного автомата не имеют с Такси ничего общего. Мы сделали ещё одну итерацию разработки, чтобы полностью отвязать наш процессинг от цикла заказа такси. Команда разработала хранилище событий, разделив его на горячую и холодную части. Так мы можем запоминать всё, что происходит с заказами (это очень помогает поддержке), и при этом не проседать в производительности. Добавили в наш DSL возможность декларативного описания переходов конечного автомата, чтобы разработчики Еды или Лавки могли описать свои циклы обработки. В результате получили инфраструктуру для создания циклов обработки чего угодно, processing as a service.
Продуктовые требования к нашей инфраструктуре получаются очень противоречивыми. С одной стороны, нужно обрабатывать заказы как можно быстрее. Нельзя допускать, чтобы время поиска водителя увеличилось на десятки секунд из-за проблем с каким-нибудь компонентом: пользователям вряд ли такое понравится.

Посмотрим на пример выше. Мы хотим приступить к обработке события new_driver_found как можно раньше — в идеале, сразу после того, как оно произошло. Но мы действуем последовательно — значит, сначала должны обработать событие created и только потом перейти к new_driver_found. А обработка каждого события состоит из десятков действий, каждое из которых может потенциально сломаться — и затормозить весь конечный автомат.

Мы придумали несколько стратегий, которые помогают сочетать быструю обработку событий с сохранением их последовательности.
Чтобы переживать отказы единичных обработчиков, мы развиваем систему стратегий фолбэков. Нам нужно уметь обнаруживать отказы и справляться с ними. Задача определения отказов на первый взгляд выглядит простой: если мы сходили в сервис по HTTP и получили 503, значит, сервис не работает. Правда, бывают врéменные флапы, если, скажем, переключился мастер одного из десяти шардов базы данных. Вряд ли можно считать, что сервис при этом сломался: процесс завершится за несколько секунд и пользователи ничего не заметят. Поэтому не стоит отключать сервис сразу, когда на нём появляются ошибки. Для более надёжной детекции мы подсчитываем статистику в некотором окне. Подробнее о том, как всё устроено, можно почитать в этом конспекте.
Иногда сервис не работает только для пользователей, заказавших такси на полнолуние в Нижних Васюках. Такой пользователь может быть всего один, для него сервис определённо сломан, а на статистике в разрезе сервиса этого не видно. Но нам важна история каждого пользователя, поэтому мы ведём статистику не только в разрезе сервиса, но и в разрезе определённого заказа: даже одна зависшая поездка будет замечена, а баг, который вызвал зависание, пофиксят.
Мы научились определять отказы сервисов, но что можно сделать, чтобы пережить отказ? Мы рассматриваем несколько возможных политик фолбэков:
- Отключение микросервиса. Это самое простое, что может быть. Отлично работает для функций, которые не критичны для продолжения заказа. Например, лучше не показать пассажиру имя водителя, чем не дать уехать совсем. Можно не показать плашку «10 лет сервису поиска такси» или новогоднее промо — главное, чтобы отображалась цена поездки. Важно только создать систему метрик и мониторинга, чтобы отключение было вовремя замечено и владельцы как можно скорее вернули микросервис к жизни. Наши мониторинги доставляют алерты команде разработки в течение пары минут, и проблемы, которые как-то задевают пользователей, обычно чинятся в течение получаса.
- Использование запасного варианта. Если сервис назначения через буферный подход даст сбой, можно вернуться к более простому жадному алгоритму (вот подробности на Хабре про алгоритмы поиска).
- Выполнить действие в сервисе после того, как он починится. Самая распространённая стратегия, в простом сценарии она решается тем, что мы передаём события сервису через очередь задач или сообщений. Всё сильно усложняется, если у следующих шагов обработки есть зависимости по данным от сервиса, выполнение которого мы хотим отложить. Например, статистику по заказам можно пересчитать офлайн с задержкой в 10 минут, если сервис онлайн-подсчёта будет недоступен. В такси вынесение в офлайн тех расчётов, задержка которых не так важна, позволяет уменьшить время выполнения основных функций — ускорить поиск водителя и уменьшить время подачи машины.
Выводы
Когда мы делаем систему, в которой взаимодействуют десятки микросервисов, неизбежно возникают проблемы совместимости интерфейсов. У нас интерпретируемый DSL, поэтому мы узнаём о таких проблемах, только когда они случаются. Чтобы легче справляться с этой проблемой, нам пришлось сделать механизм интеграционных тестов для циклов процессинга, которые пишут наши коллеги из Еды и Лавки. В Такси мы используем кодогенерацию интерфейсов на основе схем OpenAPI (Swagger) — в теории можно настроить валидацию потоков с помощью статического анализа. Но это уже планы на будущее.
Мы успешно обрабатываем тысячи событий в секунду для задач Такси, Лавки и логистики, а значит, наш подход имеет право на жизнь. Возможно, вы найдёте что-то общее между проблемами, которые решаете сами, и теми, с которыми пришлось столкнуться нам, и тогда мой рассказ поможет вам посмотреть на ваши процессы со стороны. А может, вы решаете такую же задачу другим способом, я был бы рад, если бы вы поделились своим опытом. Я не старался описать наше решение суперподробно, чтобы статью можно было осилить за один присест. Если интересно раскрыть какую-то тему детальнее, то спрашивайте в комментариях.
