
Яндекс второй раз в этом году проводит конкурс «Интернет-математика».
Цель этого конкретного конкурса — предоставить всем желающим возможность провести исследования по предсказанию релевантности документов по пользовательскому поведению. Специально для конкурса Яндекс предоставляет уникальный набор данных — информацию о переходах на документы из результатов поиска и асессорские оценки релевантности этих документов. Все данные о поисковом поведении принципиально обезличены, а в данных, предоставляемых для данного конкурса, удалены также тексты запросов и адреса сайтов (путем замены на случайные числовые идентификаторы). Таким образом, конкурсная задача представлена в максимально абстрактном математическом виде.
Как и раньше, участвовать можно в одиночку или командой, за первые три места участников ждет денежный приз (до 5000$). Лучшему российскому участнику мы оплатим полет в Сиэтл, США, где пройдет презентация лучших решений (на WSCD 2012 workshop), и регистрацию на ведущую конференцию по веб поиску – WSDM 2012.
Подробная информация о конкурсе, данные и рейтинг решений — на сайте, общение участников — в клубе.
Обзор статей по теме.
P.S.: Зарегистрировалось уже более 200 участников.
Цель этого конкретного конкурса — предоставить всем желающим возможность провести исследования по предсказанию релевантности документов по пользовательскому поведению. Специально для конкурса Яндекс предоставляет уникальный набор данных — информацию о переходах на документы из результатов поиска и асессорские оценки релевантности этих документов. Все данные о поисковом поведении принципиально обезличены, а в данных, предоставляемых для данного конкурса, удалены также тексты запросов и адреса сайтов (путем замены на случайные числовые идентификаторы). Таким образом, конкурсная задача представлена в максимально абстрактном математическом виде.
Как и раньше, участвовать можно в одиночку или командой, за первые три места участников ждет денежный приз (до 5000$). Лучшему российскому участнику мы оплатим полет в Сиэтл, США, где пройдет презентация лучших решений (на WSCD 2012 workshop), и регистрацию на ведущую конференцию по веб поиску – WSDM 2012.
Подробная информация о конкурсе, данные и рейтинг решений — на сайте, общение участников — в клубе.
Обзор статей по теме.
P.S.: Зарегистрировалось уже более 200 участников.






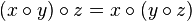

{kind=link}