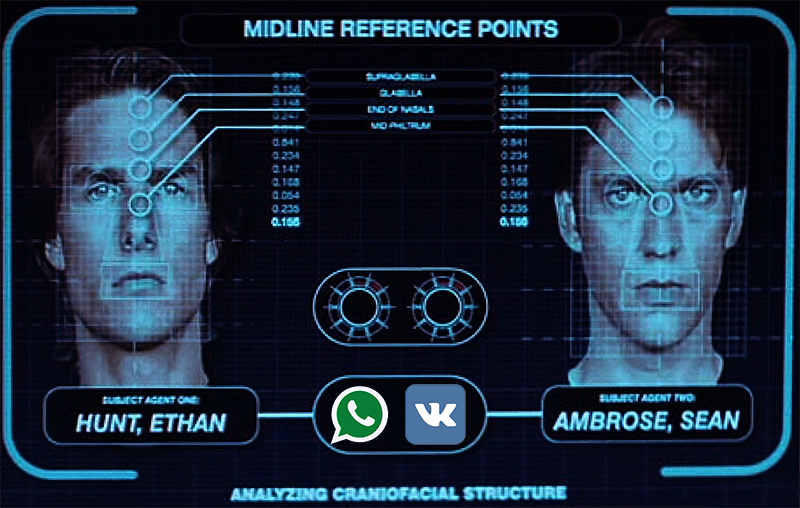
кадр из фильма Миссия Невыполнима II
Эта история началась пару месяцев назад, в первый день рождения моего сына. На мой телефон пришло СМС-сообщение с поздравлением и пожеланиями от неизвестного номера. Думаю, если бы это был мой день рождения мне бы хватило наглости отправить в ответ, не совсем культурное, по моему мнению, «Спасибо, а Вы кто?». Однако день рождения не мой, а узнать кто передаёт поздравления было интересно.
Первый успех
Было решено попробовать следующий вариант:
- Добавить неизвестный номер в адресную книгу телефона;
- Зайти по очереди в приложения, привязанные к номеру (Viber, WhatsApp);
- Открыть новый чат с вновь созданным контактом и по фотографии определить отправителя.
Мне повезло и в моём случае в списке контактов Viber рядом с вновь созданным контактом появилась миниатюра фотографии, по которой я, не открывая её целиком, распознал отправителя и удовлетворенный проведенным «расследованием» написал смс с благодарностью за поздравления.
Сразу же за секундным промежутком эйфории от удачного поиска в голове появилась идея перебором по списку номеров мобильных операторов составить базу [номер_телефона => фото]. А еще через секунду идея пропустить эти фотографии через систему распознавания лиц и связать с другими открытыми данными, например, фотографиями из социальных сетей.
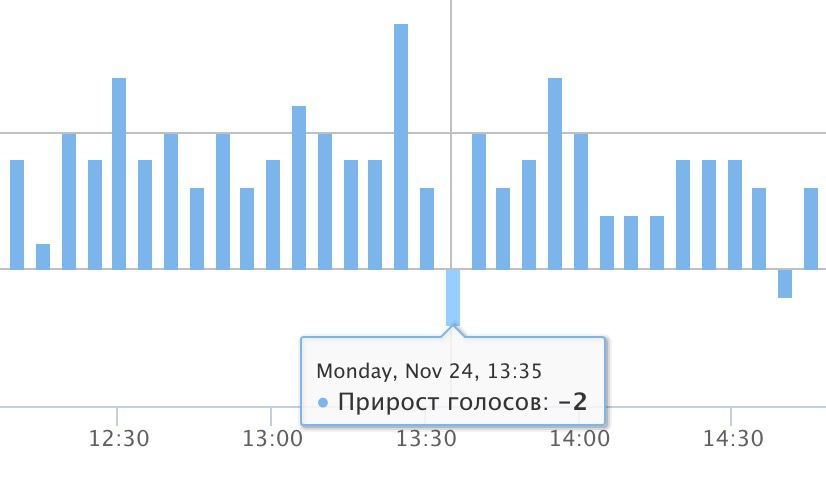




 Недавно я наткнулся на такую удивительную штуку как число Данбара.
Недавно я наткнулся на такую удивительную штуку как число Данбара.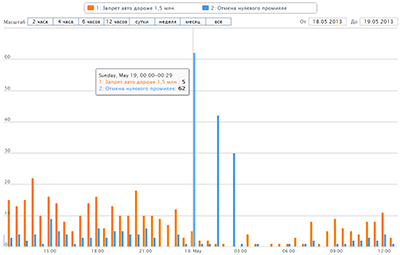 По результатам мониторинга голосования на сайте «Российская общественная инициатива» (РОИ), обнаружились интересные подробности. Складывается ощущение, что кто-то очень не хочет, чтобы инициатива известного оппозиционера стала первой набравшей 100 тысяч голосов. А поскольку пиарить свою инициативу, как это делает Алексей Н. это сильно хлопотно, то на арену выходят другие методы, привычные в оффлайн голосованиях.
По результатам мониторинга голосования на сайте «Российская общественная инициатива» (РОИ), обнаружились интересные подробности. Складывается ощущение, что кто-то очень не хочет, чтобы инициатива известного оппозиционера стала первой набравшей 100 тысяч голосов. А поскольку пиарить свою инициативу, как это делает Алексей Н. это сильно хлопотно, то на арену выходят другие методы, привычные в оффлайн голосованиях.