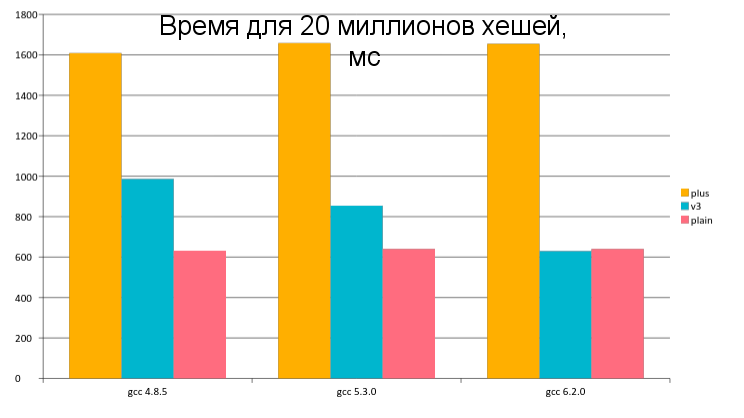
Эффективный расчёт области видимости и линии взгляда в играх
16 мин
Перевод
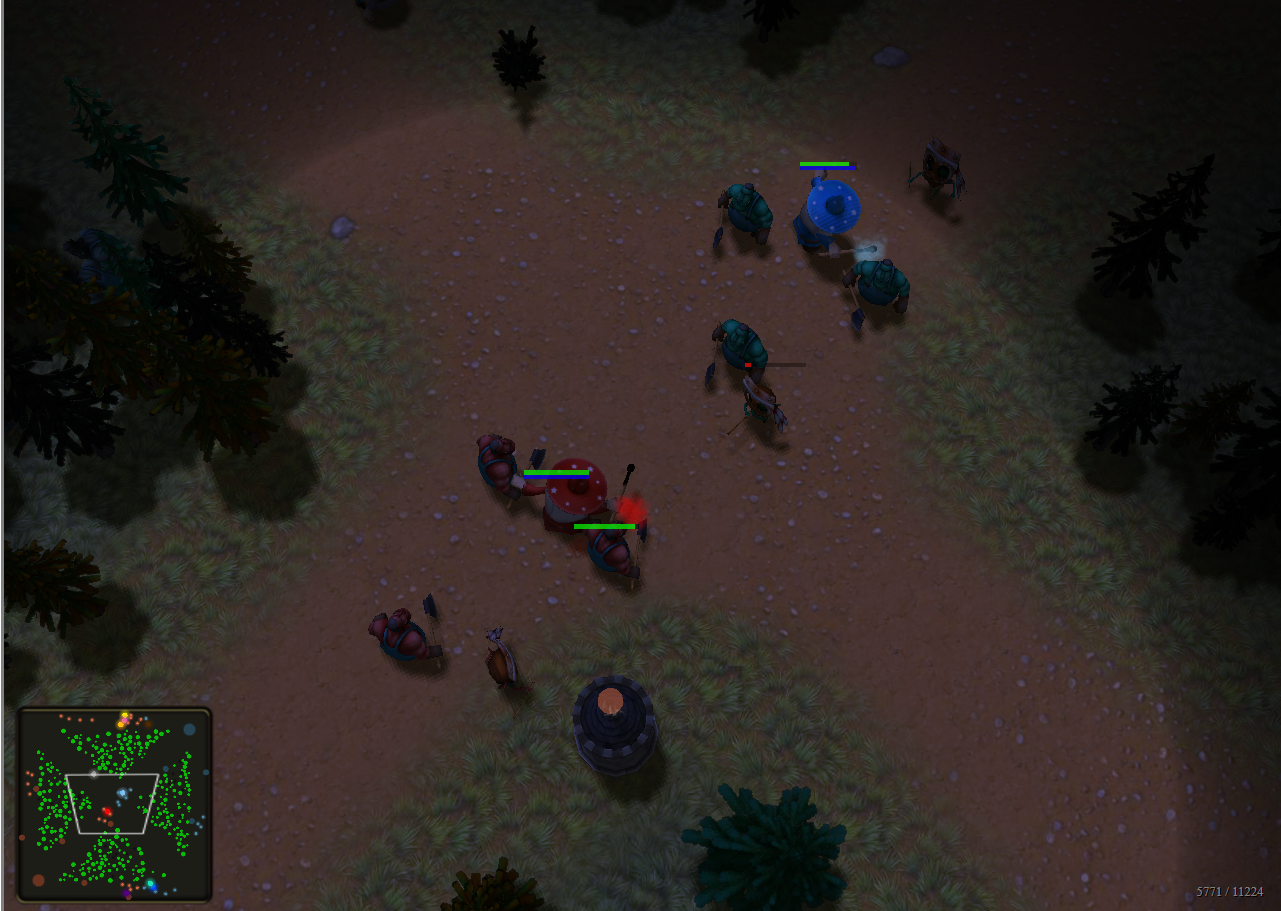
В стратегических играх обычно требуется знать область видимости NPC, чтобы игрок мог продумывать стратегию и делать следующий ход. Мы рассмотрим математику и реализацию рациональной модели, не просаживающей скорость игры при большом количестве NPC на карте. Если вы хотите увидеть готовое интерактивное демо модели, перейдите сюда и играйте прямо в браузере! Вот скриншот демонстрации:
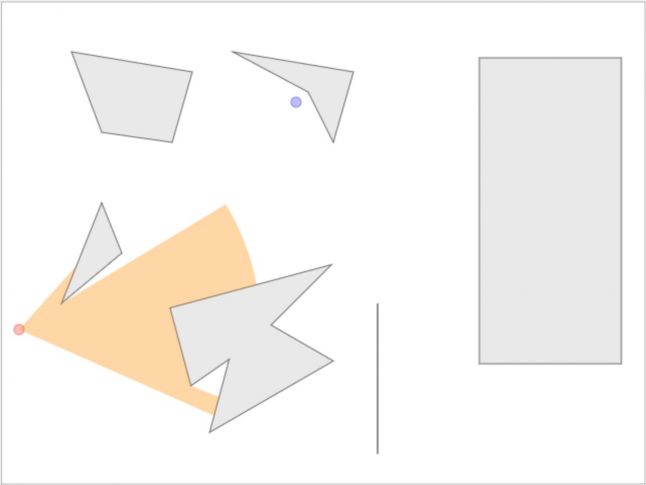
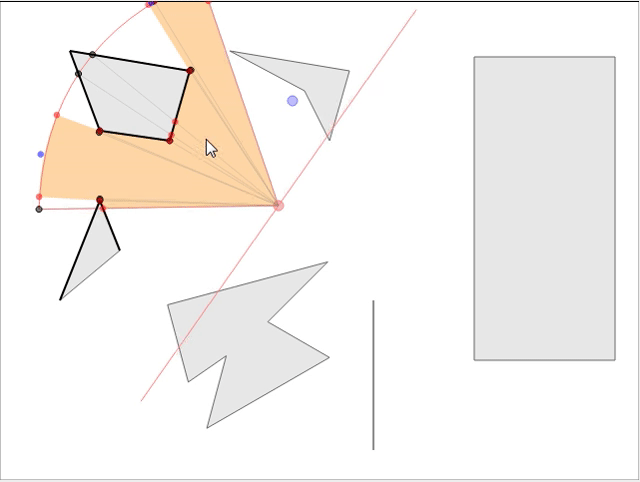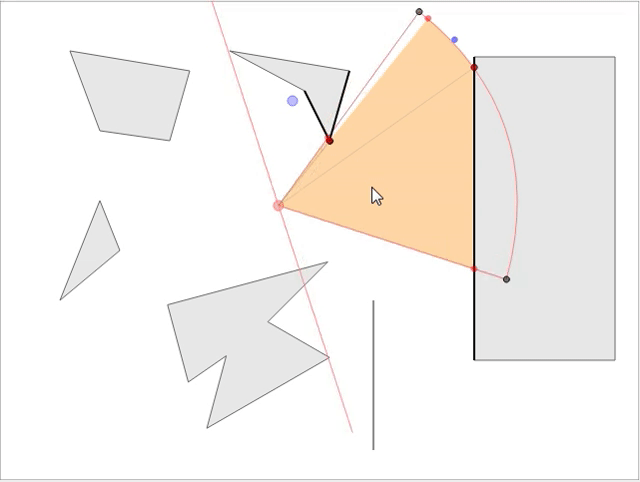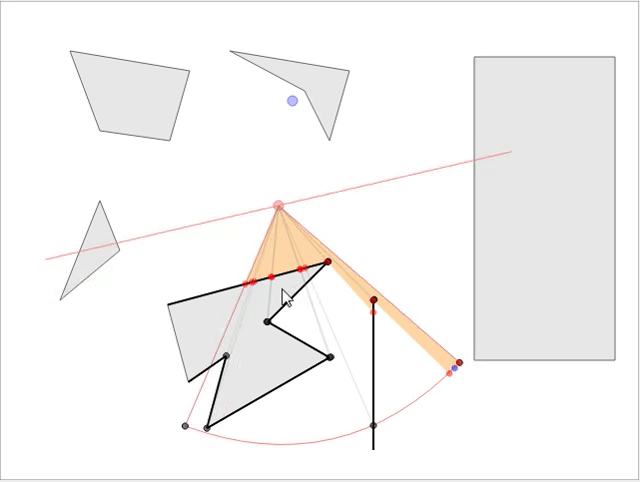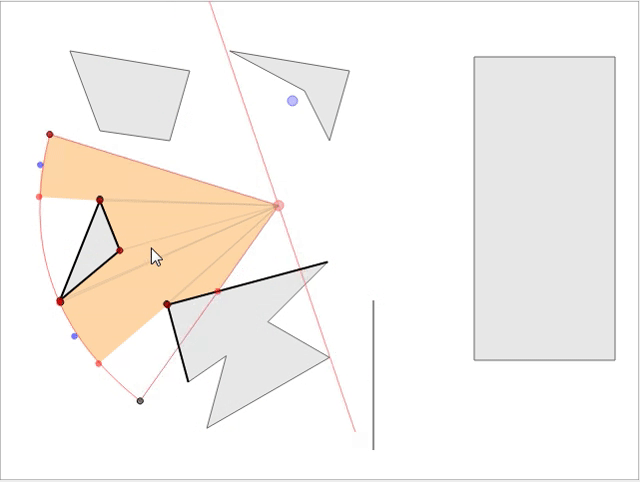
Имея параметры видимости наблюдателя (направление взгляда, расстояние видимости и угол поля зрения), нам нужно найти видимую для него область, т.е. определить область видимости (field of view, FoV). Если препятствия отсутствуют, это будет сектор круга, состоящий из двух граней (радиусов) и соединяющей их дуги (см. Рис. 1). Кроме того, имея заданную точку мира, мы должны быстро определить, видима ли она для наблюдателя, т.е. необходимо обрабатывать запросы линии взгляда (line of sight, LOS) для заданной точки. Обе эти операции можно выполнить достаточно эффективно для использования при рендеринге в реальном времени.


 Многие из вас наверняка знакомы с такой головоломкой, как судоку. Возможно, даже реализовывали программу для автоматического решения. На хабре тема судоку обсуждалась уже множество раз, и, как показывает практика, практически любой способ автоматического нахождения ответа в итоге сводится к направленному перебору. И это вполне естественно, ведь даже ручные решения придерживаются тех же принципов. Но что, если поступить иначе?
Многие из вас наверняка знакомы с такой головоломкой, как судоку. Возможно, даже реализовывали программу для автоматического решения. На хабре тема судоку обсуждалась уже множество раз, и, как показывает практика, практически любой способ автоматического нахождения ответа в итоге сводится к направленному перебору. И это вполне естественно, ведь даже ручные решения придерживаются тех же принципов. Но что, если поступить иначе?


 После не сильно долгих уговоров, меня убедили, что 30 место не так уж и плохо, и написать статью стоит. Я – участник с ником
После не сильно долгих уговоров, меня убедили, что 30 место не так уж и плохо, и написать статью стоит. Я – участник с ником