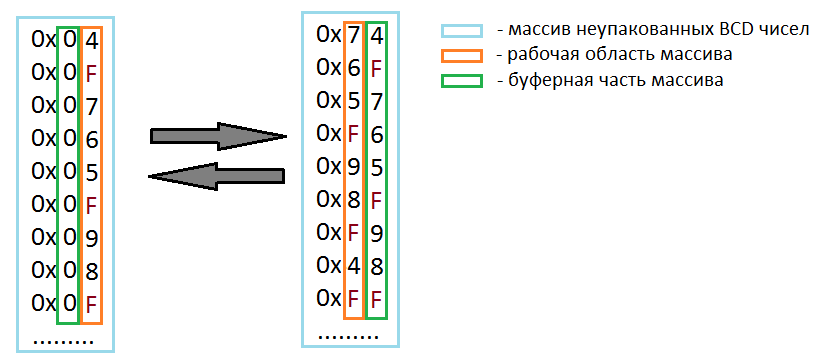
MapReduce из подручных материалов. Часть II – базовые интерфейсы реализации
 В предыдущей части серии мы (в 100500й раз) попытались рассказать про основные приемы и стадии подхода Google MapReduce, должен признаться, что первая часть была намерено "капитанской", чтобы дать знать о MapReduce целевой аудитории последующих статей. Мы не успели показать ни строчки того, как всё это мы собираемся реализовывать в Caché ObjectScript. И про это наша рассказ сегодня (и в последующие дни).
В предыдущей части серии мы (в 100500й раз) попытались рассказать про основные приемы и стадии подхода Google MapReduce, должен признаться, что первая часть была намерено "капитанской", чтобы дать знать о MapReduce целевой аудитории последующих статей. Мы не успели показать ни строчки того, как всё это мы собираемся реализовывать в Caché ObjectScript. И про это наша рассказ сегодня (и в последующие дни).
Напомним первоначальный посыл нашего мини-проекта: вы всё еще планируем реализовать MapReduce алгоритм используя те подручные средства, что есть в Caché ObjectScript. При создании интерфейсов, мы попытаемся придерживаться того API, что мы описали в предыдущей статье про оригинальную реализацию Google MapReduce, любые девиации будут озвучены соответствующе.






 Статистика приходит к нам на помощь при решении многих задач, например: когда нет возможности построить детерминированную модель, когда слишком много факторов или когда нам необходимо оценить правдоподобие построенной модели с учётом имеющихся данных. Отношение к статистике неоднозначное. Есть мнение, что существует три вида лжи: ложь, наглая ложь и статистика. С другой стороны, многие «пользователи» статистики слишком ей верят, не понимая до конца, как она работает: применяя, например, тест
Статистика приходит к нам на помощь при решении многих задач, например: когда нет возможности построить детерминированную модель, когда слишком много факторов или когда нам необходимо оценить правдоподобие построенной модели с учётом имеющихся данных. Отношение к статистике неоднозначное. Есть мнение, что существует три вида лжи: ложь, наглая ложь и статистика. С другой стороны, многие «пользователи» статистики слишком ей верят, не понимая до конца, как она работает: применяя, например, тест