
Динамические деревья
8 мин
Перед прочтением статьи рекомендую посмотреть посты про splay-деревья (1) и деревья по неявному ключу (2, 3, 4)
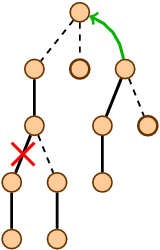 Динамические деревья (link/cut trees) мало освещены в русскоязычном интернете. Я нашел только краткое описание на алголисте. Тем не менее эта структура данных очень интересна. Она находится на стыке двух областей: потоки и динамические графы.
Динамические деревья (link/cut trees) мало освещены в русскоязычном интернете. Я нашел только краткое описание на алголисте. Тем не менее эта структура данных очень интересна. Она находится на стыке двух областей: потоки и динамические графы.
В первом случае динамические деревья позволяют построить эффективные алгоритмы для задачи о поиске максимального потока. Улучшенные алгоритмы Диница и проталкивания предпотока работают за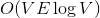 и
и 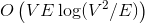 соответственно. Если вы не знаете, что такое поток, и на лекциях у вас такого не было, спешите пополнить свои знания в Кормене.
соответственно. Если вы не знаете, что такое поток, и на лекциях у вас такого не было, спешите пополнить свои знания в Кормене.
Второй случай требует небольшого введения. Динамические графы — это активно развивающаяся современная область алгоритмов. Представьте, что у вас есть граф. В нем периодически происходят изменения: появляются и исчезают ребра, меняются их веса. Изменения нужно быстро обрабатывать, а еще уметь эффективно считать разные метрики, проверять связность, искать диаметр. Динамические деревья являются инструментом, который позволяет ловко манипулировать с частным случаем графов, деревьями.
Перед тем, как нырнуть под кат, попробуйте решить следующую задачу. Дан взвешенный граф в виде последовательности ребер. По последовательности можно пройти только один раз. Требуется посчитать минимальное покрывающее дерево, используя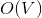 памяти и
памяти и 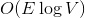 времени. По прочтении статьи вы поймете, как легко и просто можно решить эту задачу, используя динамические деревья.
времени. По прочтении статьи вы поймете, как легко и просто можно решить эту задачу, используя динамические деревья.
Динамические деревья (link/cut trees) мало освещены в русскоязычном интернете. Я нашел только краткое описание на алголисте. Тем не менее эта структура данных очень интересна. Она находится на стыке двух областей: потоки и динамические графы. В первом случае динамические деревья позволяют построить эффективные алгоритмы для задачи о поиске максимального потока. Улучшенные алгоритмы Диница и проталкивания предпотока работают за
и соответственно. Если вы не знаете, что такое поток, и на лекциях у вас такого не было, спешите пополнить свои знания в Кормене.Второй случай требует небольшого введения. Динамические графы — это активно развивающаяся современная область алгоритмов. Представьте, что у вас есть граф. В нем периодически происходят изменения: появляются и исчезают ребра, меняются их веса. Изменения нужно быстро обрабатывать, а еще уметь эффективно считать разные метрики, проверять связность, искать диаметр. Динамические деревья являются инструментом, который позволяет ловко манипулировать с частным случаем графов, деревьями.
Перед тем, как нырнуть под кат, попробуйте решить следующую задачу. Дан взвешенный граф в виде последовательности ребер. По последовательности можно пройти только один раз. Требуется посчитать минимальное покрывающее дерево, используя
памяти и времени. По прочтении статьи вы поймете, как легко и просто можно решить эту задачу, используя динамические деревья. Однажды для презентации мне понадобились анимированные графики. С графиками, собственно, проблем не возникло, а для их анимации пришлось воспользоваться еще одним пакетом
Однажды для презентации мне понадобились анимированные графики. С графиками, собственно, проблем не возникло, а для их анимации пришлось воспользоваться еще одним пакетом 
 Доброго времени суток, читатель.
Доброго времени суток, читатель. 


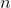 ключах и теперь нам нужно отвечать на запросы, лежит ли заданный ключ в дереве. Может так оказаться, что пользователя интересует в основном один ключ, и остальные он запрашивает только время от времени. Если ключ лежит далеко от корня, то
ключах и теперь нам нужно отвечать на запросы, лежит ли заданный ключ в дереве. Может так оказаться, что пользователя интересует в основном один ключ, и остальные он запрашивает только время от времени. Если ключ лежит далеко от корня, то  запросов могут отнять
запросов могут отнять 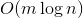 времени. Здравый смысл подсказывает, что оценку можно оптимизировать до
времени. Здравый смысл подсказывает, что оценку можно оптимизировать до 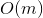 , надстроив над деревом кэш. Но этот подход имеет некоторый недостаток гибкости и элегантности.
, надстроив над деревом кэш. Но этот подход имеет некоторый недостаток гибкости и элегантности. , что делает splay-деревья хорошей альтернативой для перманентно сбалансированных собратьев.
, что делает splay-деревья хорошей альтернативой для перманентно сбалансированных собратьев.