
SOINN — самообучающийся алгоритм для роботов
23 мин
Пост №1. Что такое SOINN

SOINN – это самоорганизующаяся инкрементная нейронная сеть. Структура и алгоритм такой нейронной сети повидимому хорошо себя зарекомендовал в японской лаборатории Hasegawa (сайт — haselab.info), потому что он в итоге был взят за основу и дальнейшее развитие алгоритмов искусственного интеллекта шло путем небольших модификаций и надстроек к сети SOINN.
Базовая сеть SOINN состоит из двух слоев. Сеть получает входной вектор и на первом слое после обучения создает узел (нейрон) – определяющий класс для входных данных. Если входной вектор похож на существующий класс (мера похожести определяется настройками алгоритма обучения) то два самых похожих нейрона первого слоя объединяются связью, либо если входной вектор не похож не на один существующей класс, то в первом слое создается новый нейрон, определяющий текущий класс. Очень похожие нейроны первого слоя, объединенные связью, определяются как один класс. Первый слой является входным слоем для второго слоя, и по аналогичному алгоритму, с небольшим исключением, создаются классы во втором слое.
На основе SOINN созданы такие сети, как (далее представлены название сети и описание сети от ее создателей):
SOINN – это самоорганизующаяся инкрементная нейронная сеть. Структура и алгоритм такой нейронной сети повидимому хорошо себя зарекомендовал в японской лаборатории Hasegawa (сайт — haselab.info), потому что он в итоге был взят за основу и дальнейшее развитие алгоритмов искусственного интеллекта шло путем небольших модификаций и надстроек к сети SOINN.
Базовая сеть SOINN состоит из двух слоев. Сеть получает входной вектор и на первом слое после обучения создает узел (нейрон) – определяющий класс для входных данных. Если входной вектор похож на существующий класс (мера похожести определяется настройками алгоритма обучения) то два самых похожих нейрона первого слоя объединяются связью, либо если входной вектор не похож не на один существующей класс, то в первом слое создается новый нейрон, определяющий текущий класс. Очень похожие нейроны первого слоя, объединенные связью, определяются как один класс. Первый слой является входным слоем для второго слоя, и по аналогичному алгоритму, с небольшим исключением, создаются классы во втором слое.
На основе SOINN созданы такие сети, как (далее представлены название сети и описание сети от ее создателей):

 В 2012 году вся общественность, более или менее причастная к информационной безопасности, пристально следила за выборами нового стандарта хеширования данных SHA-3. На хабре достаточно широко освещалось это важное событие: публиковались результаты каждого раунда конкурса (
В 2012 году вся общественность, более или менее причастная к информационной безопасности, пристально следила за выборами нового стандарта хеширования данных SHA-3. На хабре достаточно широко освещалось это важное событие: публиковались результаты каждого раунда конкурса (

 Доброго времени суток, уважаемые! К сожалению, из-за больничного режима, я не мог последний месяц опубликовать своё очередное изыскание на тему игры «Морской бой». Надеюсь, моя заметка окажется для кого-то полезной, и, даже если и будет частичным повторением, то в новой интерпретации.
Доброго времени суток, уважаемые! К сожалению, из-за больничного режима, я не мог последний месяц опубликовать своё очередное изыскание на тему игры «Морской бой». Надеюсь, моя заметка окажется для кого-то полезной, и, даже если и будет частичным повторением, то в новой интерпретации. Наверное все, кто хоть чуть-чуть работал с фотошопом — видели эффект outer glow для слоя, и пробовали с ним играться. В фотошопе есть 2 техники этого самого outer glow. Soft и precise. Soft мне был не так интересен, а вот глядя на precise — я задумался.
Наверное все, кто хоть чуть-чуть работал с фотошопом — видели эффект outer glow для слоя, и пробовали с ним играться. В фотошопе есть 2 техники этого самого outer glow. Soft и precise. Soft мне был не так интересен, а вот глядя на precise — я задумался.


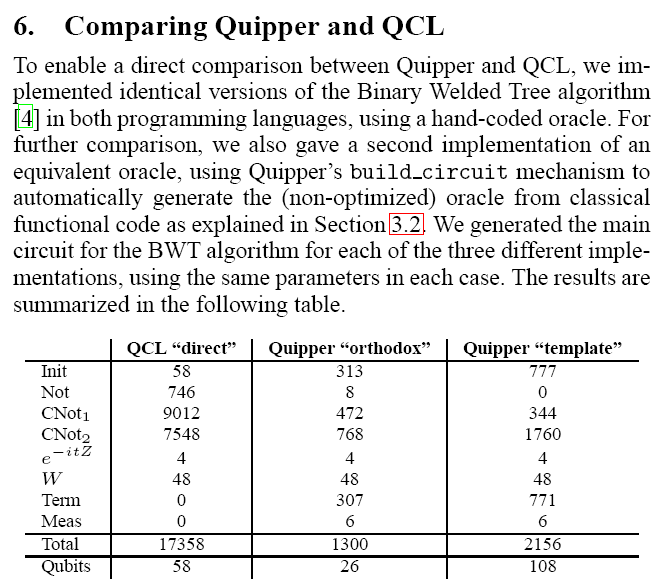
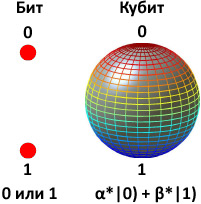 Хотя квантовые компьютеры существуют пока только в теории, но это не мешает делать обоснованные предположения об их будущей архитектуре и, что более важно, об интерфейсе взаимодействия с ними. Таким образом, уже сейчас есть возможность проектировать программные симуляторы квантовых компьютеров — и писать софт.
Хотя квантовые компьютеры существуют пока только в теории, но это не мешает делать обоснованные предположения об их будущей архитектуре и, что более важно, об интерфейсе взаимодействия с ними. Таким образом, уже сейчас есть возможность проектировать программные симуляторы квантовых компьютеров — и писать софт. 
 Созданная программная платформа сканирует социальные медиа и другие интернет-источники для создания отчетов о репутации своих клиентов — среди которых есть Европейская комиссия, Air France и другие крупные заказчики. Как и большая часть подобного ПО, приложение занимается анализом семантики, лингвистики и эвристики. Однако, как и любая другая система с машинным анализом данных, их инструмент часто испытывает проблемы с такими тонкими частями человеческой речи, как сарказм и ирония — и, вроде бы, как раз эту проблему Spotter и удалось преодолеть — пусть их руководители и признают, что результат пока что далек от идеального, и что полностью доверять машине еще рано. Процент распознавания достигает 80%, и, по заявлению авторов, еще несколько лет назад даже подобный результат был немыслим — тогда сарказм опознавался в 50% случаев. Авторы говорят, что алгоритм работает с 29 языками (включая русский и китайский), а чаще всего им приходится иметь дело с распознаванием сообщений о плохом уровне обслуживания.
Созданная программная платформа сканирует социальные медиа и другие интернет-источники для создания отчетов о репутации своих клиентов — среди которых есть Европейская комиссия, Air France и другие крупные заказчики. Как и большая часть подобного ПО, приложение занимается анализом семантики, лингвистики и эвристики. Однако, как и любая другая система с машинным анализом данных, их инструмент часто испытывает проблемы с такими тонкими частями человеческой речи, как сарказм и ирония — и, вроде бы, как раз эту проблему Spotter и удалось преодолеть — пусть их руководители и признают, что результат пока что далек от идеального, и что полностью доверять машине еще рано. Процент распознавания достигает 80%, и, по заявлению авторов, еще несколько лет назад даже подобный результат был немыслим — тогда сарказм опознавался в 50% случаев. Авторы говорят, что алгоритм работает с 29 языками (включая русский и китайский), а чаще всего им приходится иметь дело с распознаванием сообщений о плохом уровне обслуживания.
{kind=link}