Сравнение матричной факторизации с трансформерами на наборе данных MovieLens с применением библиотеки pytorch-acceleratd

Современный человек много чем занимается в интернете: ходит по магазинам, слушает музыку, читает новости. Все эти задачи подразумевают поиск и выбор того, что ему нужно. При этом важную роль тут играют рекомендательные системы. Они помогают людям не утонуть в многообразии вариантов и увидеть именно то, что им подойдёт, то, что иначе им сложно было бы найти. Предоставление пользователям качественных рекомендаций — это важнейшая часть обеспечения первоклассного уровня удовлетворения клиента. Это — один из самых эффективных способов взращивания лояльности клиентов и повышения ценности продукта или услуги в их глазах. Всё это так важно, что целые бизнес-модели некоторых компаний построены вокруг предоставления их клиентам наилучших рекомендаций, что делает рекомендательные системы важнейшими факторами, влияющими на прибыль подобных компаний! В результате неудивительно то, что клиенты проекта Microsoft CSE часто обращаются к нам с просьбами, касающимися реализации эталонных рекомендательных техник. Один из таких проектов был моим первым опытом в данной сфере.



 Еще я веду канал в Telegram:
Еще я веду канал в Telegram: 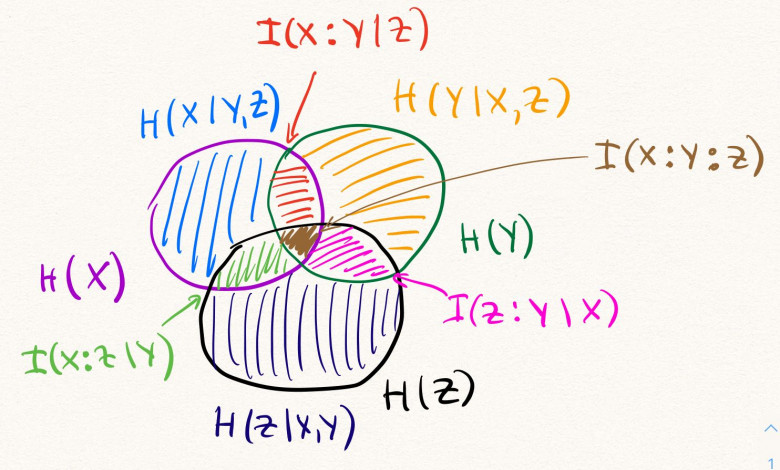

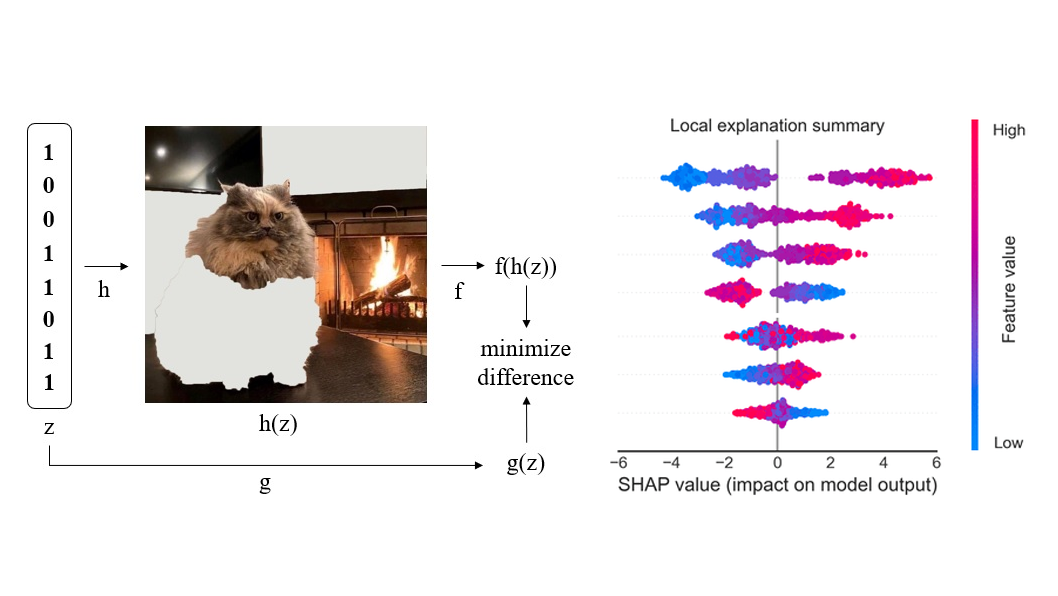
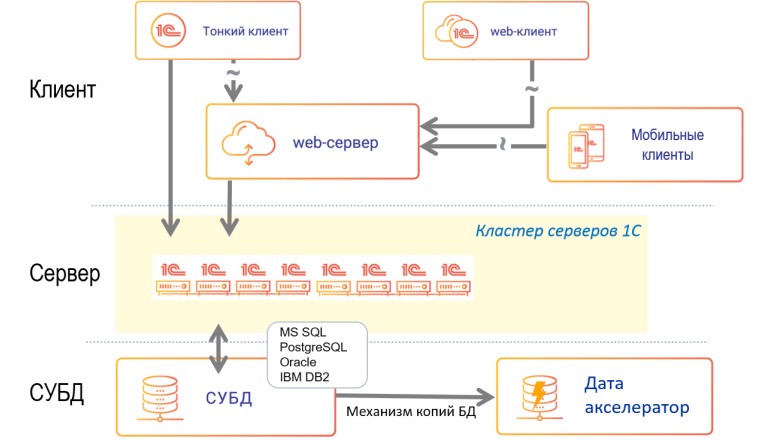
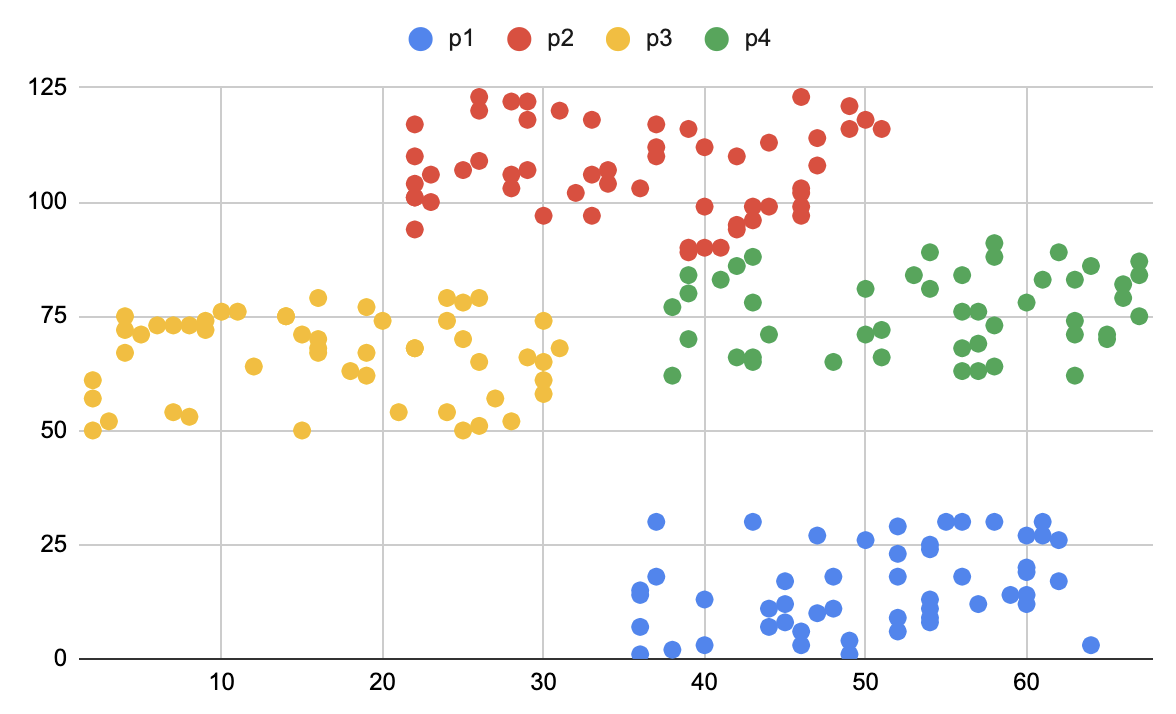

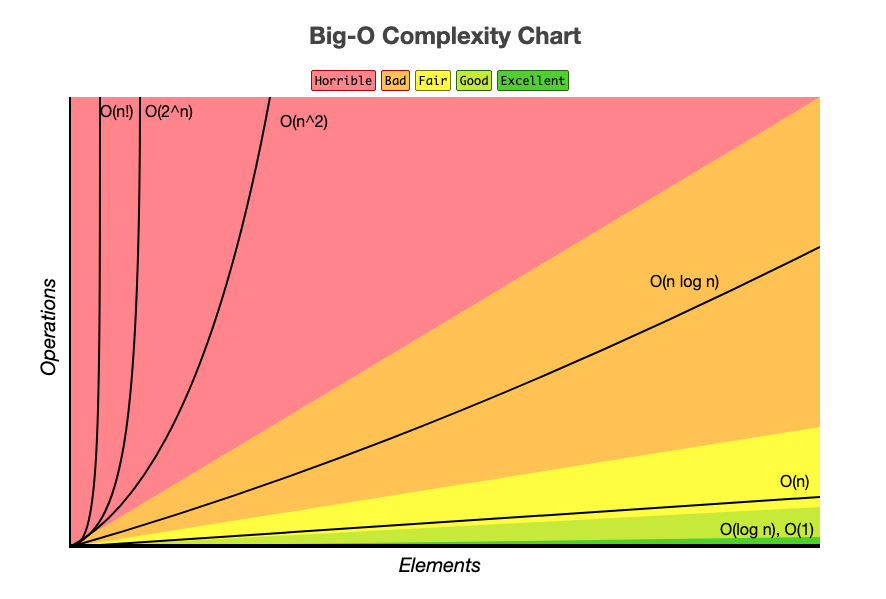
 при сортировке слиянием. Или переход от линейной сложности к логарифмической, при реализации поиска элемента в отсортированном массиве (см. бинарный поиск).
при сортировке слиянием. Или переход от линейной сложности к логарифмической, при реализации поиска элемента в отсортированном массиве (см. бинарный поиск).