Методы приближенного поиска ближайших соседей
Довольно часто программисты и специалисты из области data science сталкиваются с задачей поиска похожих профилей пользователей или подбора схожей музыки. Решения могут сводиться к преобразованию объектов в векторную форму и поиску ближайших.
Мы тоже столкнулись с необходимостью поиска ближайших соседей в задаче распознавания лиц. Там мы формируем векторные представления лиц при помощи нейросети и ищем ближайшие векторы уже известных людей. Изначально для поиска мы выбрали Annoy, как хорошо известный и проверенный алгоритм, используемый в том числе в Spotify. Но быстро поняли, что с его аппетитами по памяти мы либо не вмещаемся в RAM, либо сильно теряем в точности. Это привело к небольшому исследованию. О результатах которого пойдет речь ниже.



 Приветствую вас, коллеги. Оказывается, не все компьютерное зрение сегодня делается с использованием нейронных сетей. Хотя многие стартапы и заявляют, что у них дип лернинг везде, спешу вас разочаровать, они просто хотят хайпануть немножечко. Рассмотрим, например, задачу сегментации. В
Приветствую вас, коллеги. Оказывается, не все компьютерное зрение сегодня делается с использованием нейронных сетей. Хотя многие стартапы и заявляют, что у них дип лернинг везде, спешу вас разочаровать, они просто хотят хайпануть немножечко. Рассмотрим, например, задачу сегментации. В 
 Здравствуйте, коллеги. В конце 1960-ых годов прошлого века
Здравствуйте, коллеги. В конце 1960-ых годов прошлого века 
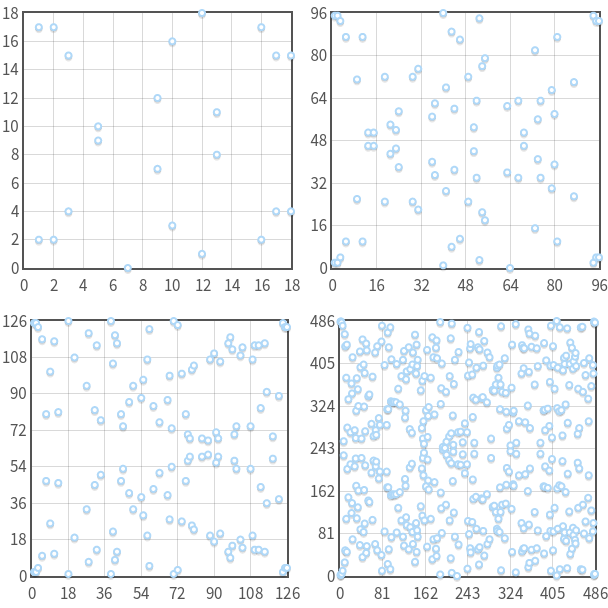
 На днях
На днях 



 Предположим, что я дал вам относительно длинную строку, а вы хотите удалить из неё все пробелы. В ASCII мы можем определить пробелы как знак пробела (‘ ’) и знаки окончания строки (‘\r’ и ‘\n’). Меня больше всего интересуют вопросы алгоритма и производительности, так что мы можем упростить задачу и удалить все байты со значениями меньшими либо равными 32.
Предположим, что я дал вам относительно длинную строку, а вы хотите удалить из неё все пробелы. В ASCII мы можем определить пробелы как знак пробела (‘ ’) и знаки окончания строки (‘\r’ и ‘\n’). Меня больше всего интересуют вопросы алгоритма и производительности, так что мы можем упростить задачу и удалить все байты со значениями меньшими либо равными 32.