
Лекция Дмитрия Ветрова о математике больших данных: тензоры, нейросети, байесовский вывод
2 мин
Сегодня лекция одного из самых известных в России специалистов по машинному обучению Дмитрия Ветрова, который руководит департаментом больших данных и информационного поиска на факультете компьютерных наук, работающим во ВШЭ при поддержке Яндекса.
Как можно хранить и обрабатывать многомерные массивы в линейных по памяти структурах? Что дает обучение нейронных сетей из триллионов триллионов нейронов и как можно осуществить его без переобучения? Можно ли обрабатывать информацию «на лету», не сохраняя поступающие последовательно данные? Как оптимизировать функцию за время меньшее чем уходит на ее вычисление в одной точке? Что дает обучение по слаборазмеченным данным? И почему для решения всех перечисленных выше задач надо хорошо знать математику? И другое дальше.
Люди и их устройства стали генерировать такое количество данных, что за их ростом не успевают даже вычислительные мощности крупных компаний. И хотя без таких ресурсов работа с данными невозможна, полезными их делают люди. Сейчас мы находимся на этапе, когда информации так много, что традиционные математические методы и модели становятся неприменимы. Из лекции Дмитрия Петровича вы узнаете, почему вам надо хорошо знать математику для работы с машинным обучением и обработкой данных. И какая «новая математика» понадобится вам для этого. Слайды презентации — под катом.
Как можно хранить и обрабатывать многомерные массивы в линейных по памяти структурах? Что дает обучение нейронных сетей из триллионов триллионов нейронов и как можно осуществить его без переобучения? Можно ли обрабатывать информацию «на лету», не сохраняя поступающие последовательно данные? Как оптимизировать функцию за время меньшее чем уходит на ее вычисление в одной точке? Что дает обучение по слаборазмеченным данным? И почему для решения всех перечисленных выше задач надо хорошо знать математику? И другое дальше.
Люди и их устройства стали генерировать такое количество данных, что за их ростом не успевают даже вычислительные мощности крупных компаний. И хотя без таких ресурсов работа с данными невозможна, полезными их делают люди. Сейчас мы находимся на этапе, когда информации так много, что традиционные математические методы и модели становятся неприменимы. Из лекции Дмитрия Петровича вы узнаете, почему вам надо хорошо знать математику для работы с машинным обучением и обработкой данных. И какая «новая математика» понадобится вам для этого. Слайды презентации — под катом.
 Привет, Хабр!
Привет, Хабр!

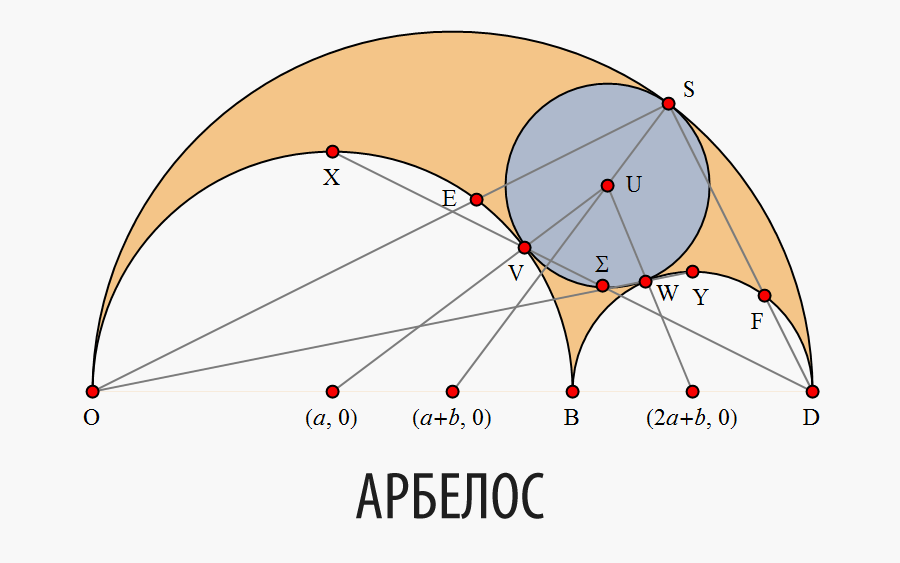


 Здравствуй, Хабр!
Здравствуй, Хабр!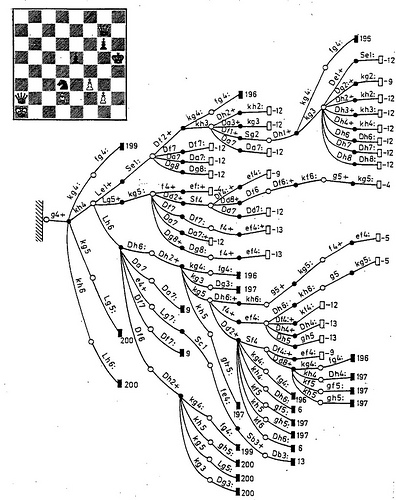
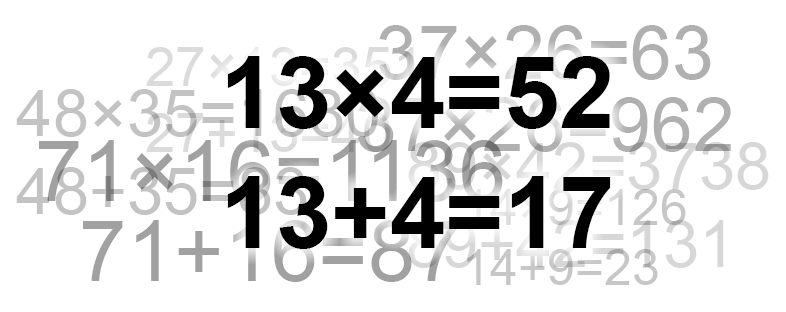




 Привет, Хабр, давно не виделись. В этом посте мне хотелось бы рассказать о таком относительно новом понятии в машинном обучении, как
Привет, Хабр, давно не виделись. В этом посте мне хотелось бы рассказать о таком относительно новом понятии в машинном обучении, как 



{kind=link}