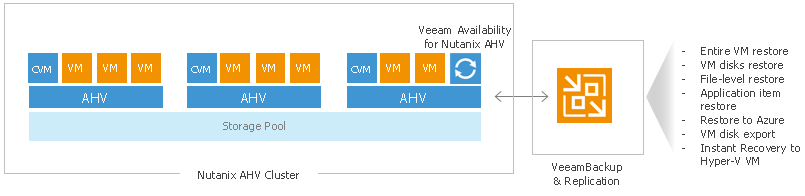
Спасти содержимое vCenter Content Library
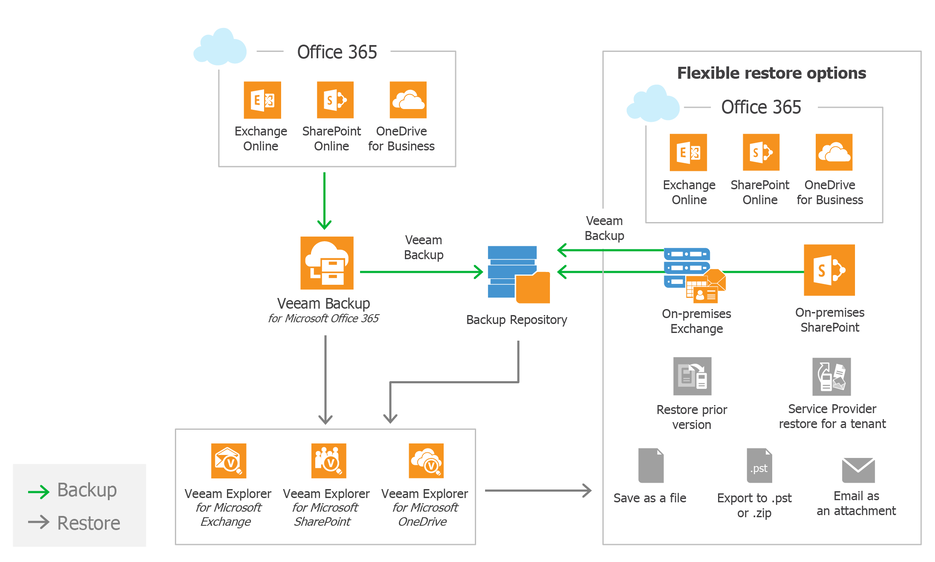
Начиная с шестой версии, в VMware vSphere есть удобная фича, позволяющая следить за актуальностью виртуальной инфраструктуры на удалённых площадках и филиалах, насаждая огнём и мечом стандарты виртуальной инфраструктуры главного офиса. Называется она Content Library и занимается распространением шаблонов между вашими дата центрами.
Для чего это надо? Ну, самый банальный пример — у вас есть набор истинно верных и благословлённых всеми службами шаблонов виртуальных машин, из которых должно деплоиться всё в вашей организации. То, что они есть лично на вашем хосте в центральном офисе, ещё не значит, что все остальные получат их вовремя, их версия будет актуальной и на местах не придётся городить свои огороды. Поэтому вы просто подписываете ваши филиалы на обновления из головного офиса, и администраторы удалённых площадок всегда будут иметь доступ к необходимым шаблонам. Очень удобно.
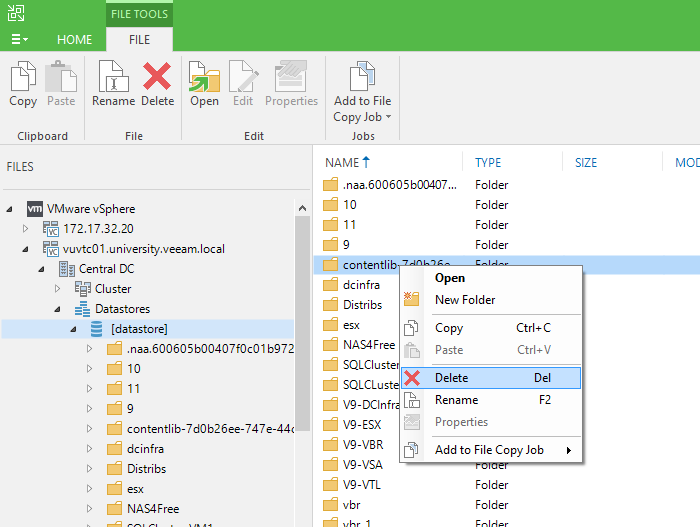
В Content Library можно ещё добавлять сопутствующие файлы, образы дисков и многое другое, но мы сегодня поговорим не про это. Несмотря на три года за плечами, всё ещё многие задаются вопросом “Как бекапить объекты внутри Content Library?”. Там лежат совершенно обычные файлы, с которыми точно так же может случиться любая беда, но доступа к ним через обычные варианты резервного копирования для виртуальных сред нет. Поэтому отвечаем под катом на столь важный вопрос...