Гегель считал, что общество становится современным, когда новости заменяют религию.
The News: A User's Manual, Alain de Botton
Читать все новости стало разительно невозможно. И дело не только в том, что пишет их Стивен Бушеми в перерывах между боулингом с Лебовски, а скорее в том, что их стало слишком много. Тут нам на помощь приходят агрегаторы новостей и естественным образом встаёт вопрос: а кого и как они агрегируют?
Заметив пару интересных статей на Хабре про API и сбор данных популярного новостного сайта Meduza, решил расчехлить щит Персея и продолжить славное дело. Meduza мониторит множество различных новостных сайтов, и сегодня разберемся какие источники в ней преобладают, можно ли их осмысленно сгруппировать и есть ли здесь ядро, составляющее костяк новостной ленты.
Краткое определение того, что такое Meduza:
«Помните, как неумные люди все время называли «Ленту»? Говорили, что «Лента» — агрегатор. А давайте мы и в самом деле сделаем агрегатор» (интервью Forbes)
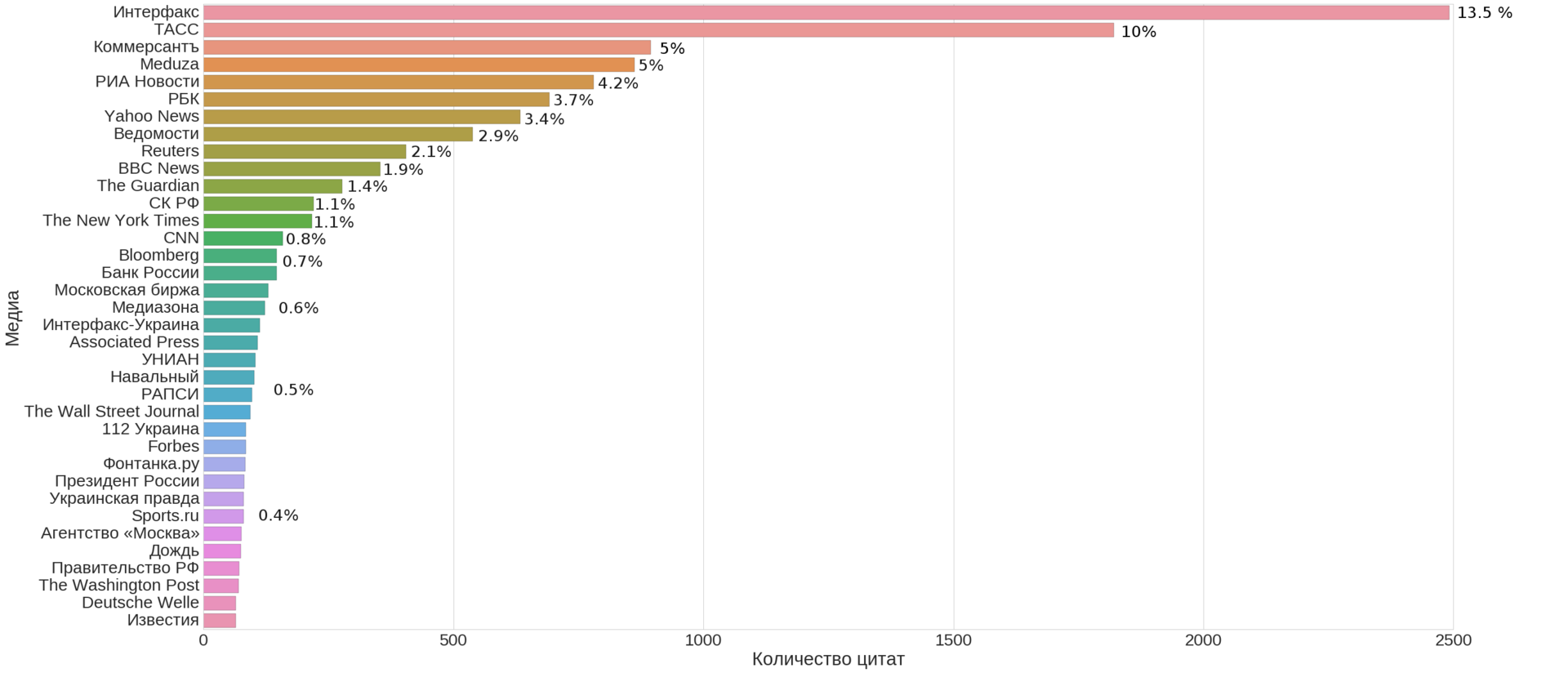
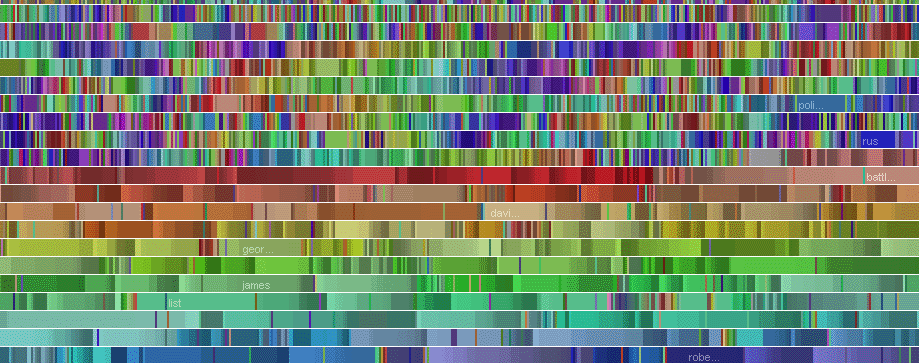
(это не просто КДПВ, а топ-35 медиа по числу новостей указанных в качестве источника на сайте Meduza, включая её саму)
Конкретизируем и формализуем вопросы:
- Q1: Из каких ключевых источников состоит лента новостей?
Иначе говоря, можем ли мы выбрать небольшое число источников достаточно покрывающих всю ленту новостей?
- Q2: Есть ли на них какая-то простая и интерпретируемая структура?
Проще говоря, можем ли мы кластеризовать источники в осмысленные группы?
- Q3: Можно ли по этой структуре определить общие параметры агрегатора?