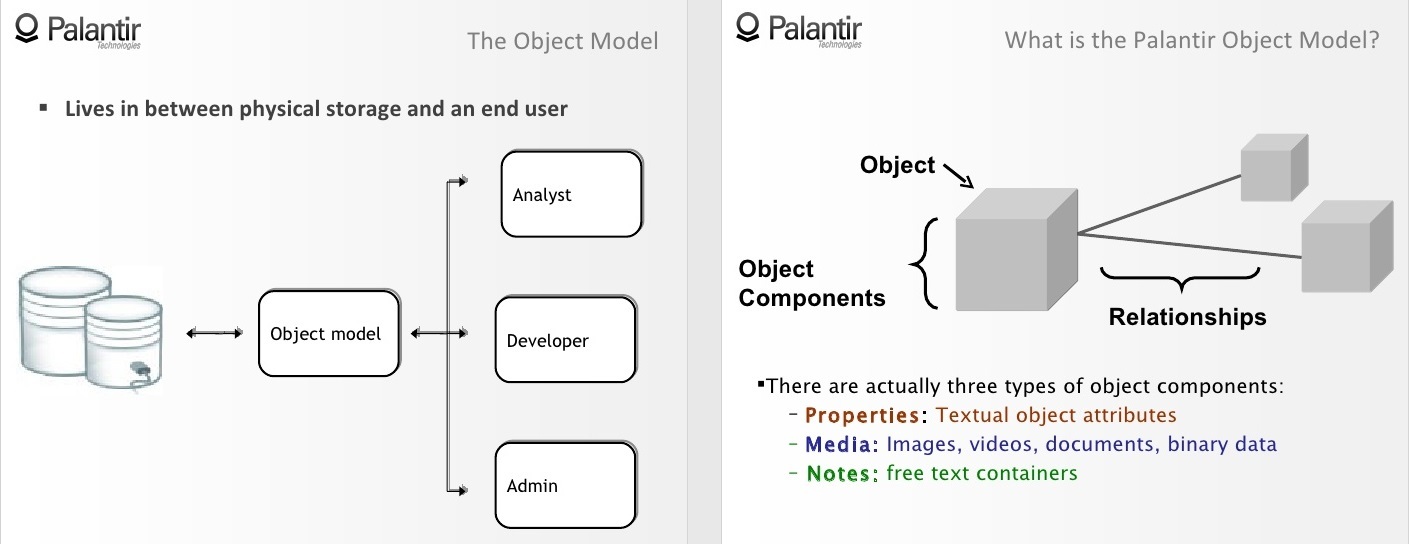
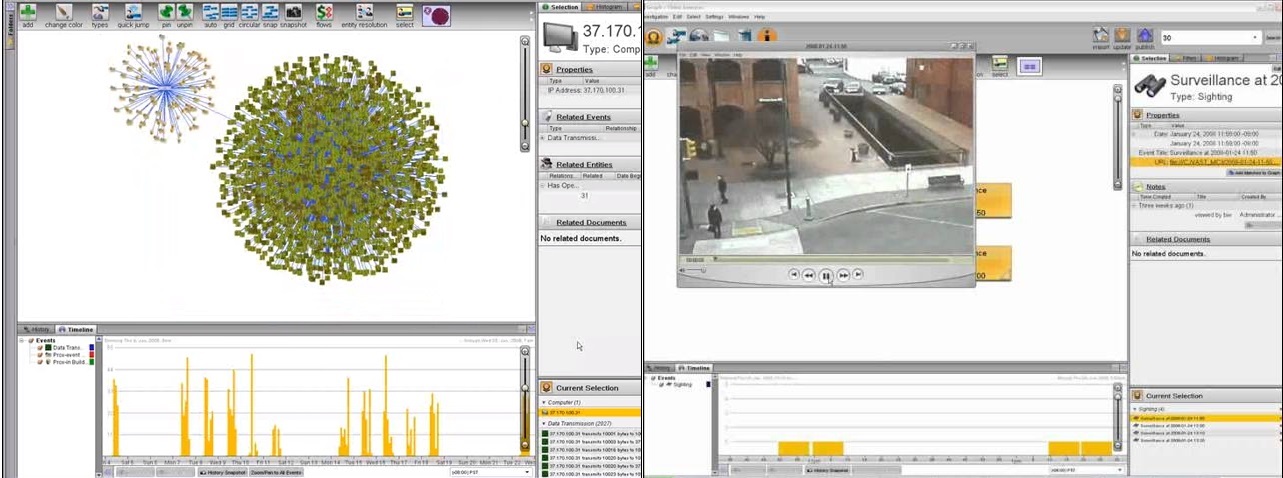
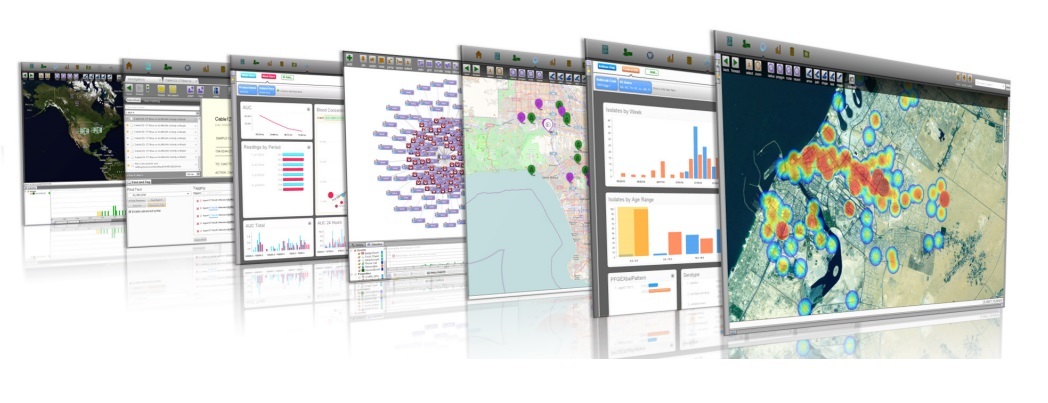
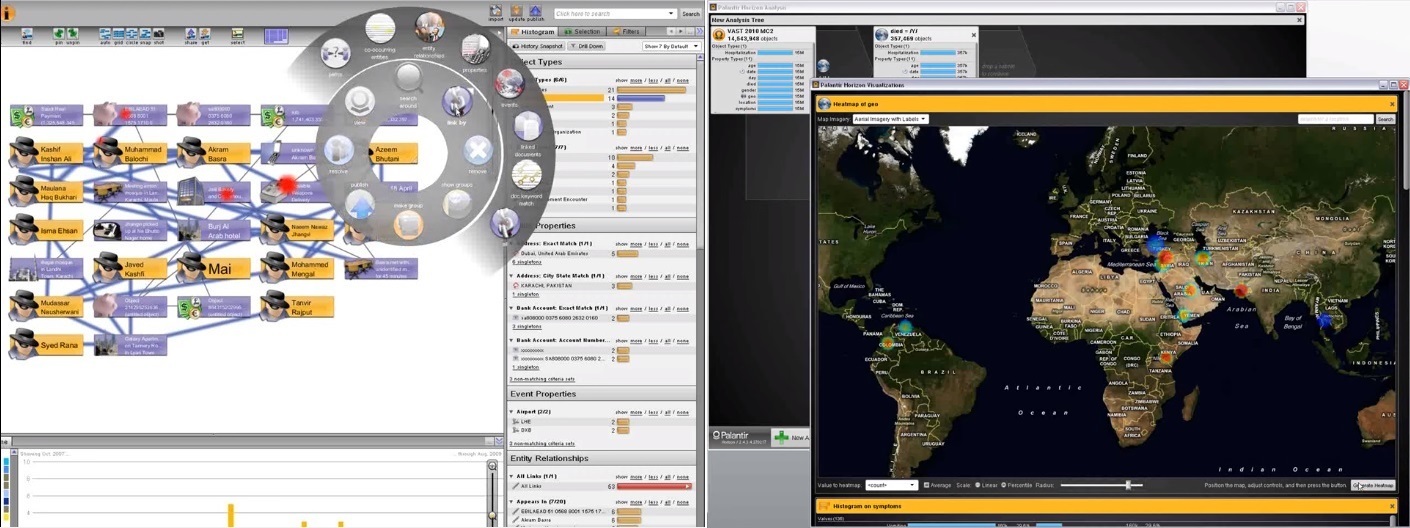
Термин «Большие данные» появился не так давно — впервые его использовали в журнале Nature в 2008 году. В том номере (от 3 сентября) большими данными читателям было предложено называть набор специальных методов и инструментов для обработки огромных объемов информации и представления её в виде, понятном пользователю.
Очень скоро исследователи новоявленной области пришли к выводу, что большие данные не просто годятся для анализа, а могут оказаться полезными в целом ряде областей: от предсказания вспышек гриппа по результатам анализа запросов в Google до определения выгодной стоимости билетов на самолет на основе огромного массива авиационных данных.
Апологеты этого направления утверждают даже, что тандем мощных современных технологий и «мощных» объемов информации, доступных в цифровую эпоху, обещает стать грозным инструментом для решения практически любой проблемы: расследования преступлений, охраны здоровья, образования, автомобильной промышленности и так далее. «Нужно лишь собрать и проанализировать данные».


 За несколько лет, прошедших со времени выхода первого издания, известный нам мир претерпел невероятные изменения. Мы живем в эпоху цифровых технологий, когда объем имеющейся в мире информации увеличивается за два года более чем вдвое, а в следующем десятилетии IT-отделам придется справляться с информационными объемами, увеличившимися более чем в 50 раз, и это при том, что количество специалистов в области информационных технологий возрастет всего лишь в полтора раза. Теперь виртуализация и облачные вычисления для предприятий уже не просто один из возможных вариантов, а настоятельное условие для выживания на рынке. А так называемые большие данные предоставляют организациям новые, весьма действенные возможности анализа, обработки и управления возросшим объемом своего наиболее ценного актива — информации и приобретения весомых конкурентных преимуществ.
За несколько лет, прошедших со времени выхода первого издания, известный нам мир претерпел невероятные изменения. Мы живем в эпоху цифровых технологий, когда объем имеющейся в мире информации увеличивается за два года более чем вдвое, а в следующем десятилетии IT-отделам придется справляться с информационными объемами, увеличившимися более чем в 50 раз, и это при том, что количество специалистов в области информационных технологий возрастет всего лишь в полтора раза. Теперь виртуализация и облачные вычисления для предприятий уже не просто один из возможных вариантов, а настоятельное условие для выживания на рынке. А так называемые большие данные предоставляют организациям новые, весьма действенные возможности анализа, обработки и управления возросшим объемом своего наиболее ценного актива — информации и приобретения весомых конкурентных преимуществ.