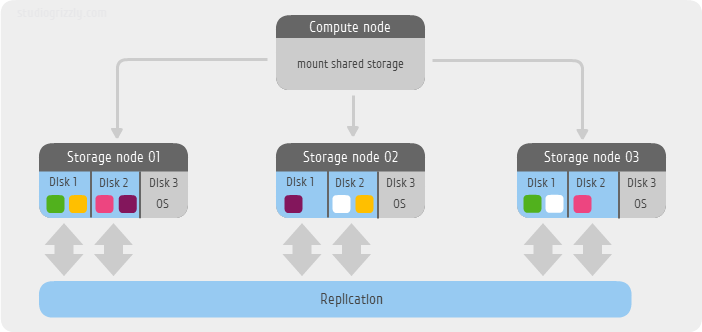
Раз уж мы начали рассматривать историю хранения данных — познакомимся поближе с одной из технологий, которую мы в прошлой статье упомянули только вскользь. Удивительно в этой технологии то, что, появившись в самом начале 80-х, она с разными изменениями дожила до современности, и не собирается уступать позиции. Речь пойдет о SCSI.
«Отцами-основателями» SCSI можно считать компанию Shugart Associates, стандарт из которого родился впоследствии SCSI изначально носил слегка неблагозвучное для русского уха название SASI (Shugart Associates System Interface). Компания эта, ныне не так широко известная, в конце 70-х практически доминировала на рынке дисководов, и именно эта компания предложила популярный формат 5¼ дюймов. Контроллеры SASI обычно были размером в половину диска и подключались 50-пиновым плоским кабелем, который впоследствии стал коннектором SCSI-1.

За переименованием стандарта стоял ANSI, к 1982 году разработавший стандарт этого интерфейса. Дело в том, что политика ANSI не разрешает использовать названия компаний названии стандартов, поэтому SASI был переименован в «Small Computer System Interface», что и дало знакомую нам аббревиатуру. «Отец» стандарта Ларри Бушер (Larry Boucher) хотел, чтоб эта аббревиатура читалась как «сэкси», но прочтение от Дал Аллана (Dal Allan) «сказзи» прижилось больше.
Несмотря на то, что в основном SCSI ассоциируется с жесткими дисками, этот стандарт позволяет создавать практически любые устройства, подключаемые по данному интерфейсу. Со SCSI выпускалась масса устройств: жесткие диски, магнитооптические накопители, CD и DVD приводы, стриммеры, принтеры и даже сканеры (LPT порт был слишком медленным для работы цветных сканеров высокого разрешения).
Несмотря на то, что в большинстве «простых компьютеров» SCSI как интерфейс не встречается, набор команд этого стандарта широко используется. Например, набор команд SCSI программно реализован в едином стеке Windows для поддержки устройств хранения данных. Так же, практически стандартом стала реализация команд SCSI поверх IDA/ATA и SATA интерфейсов, используемых для работы с CD/DVD и BlueRay, названная ATAPI. Так же эта система команд, реализованная поверх USB, стала частью стандарта Mass Storage Device, что позволяет использовать любые внешние USB хранилища данных.













 Недавно нам удалось пообщаться с великим Монти — Майклом Видениусом, автором оригинальной версии открытой СУБД MySQL, который в настоящее время работает над ее ответвлением, MariaDB. (Кстати, обе эти базы поддерживаются в
Недавно нам удалось пообщаться с великим Монти — Майклом Видениусом, автором оригинальной версии открытой СУБД MySQL, который в настоящее время работает над ее ответвлением, MariaDB. (Кстати, обе эти базы поддерживаются в 
