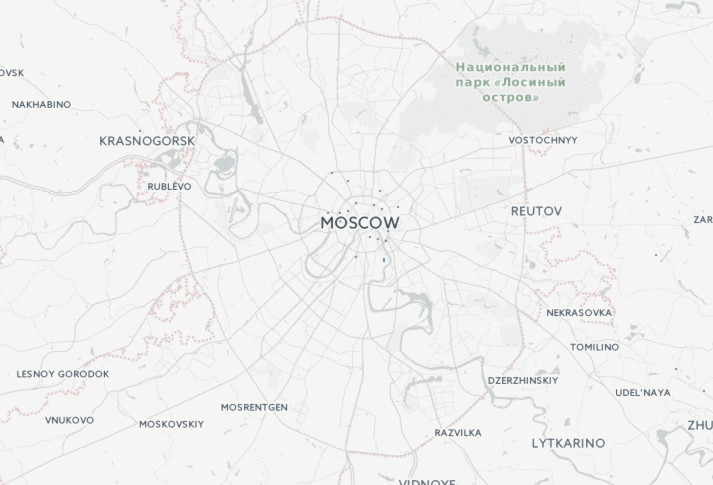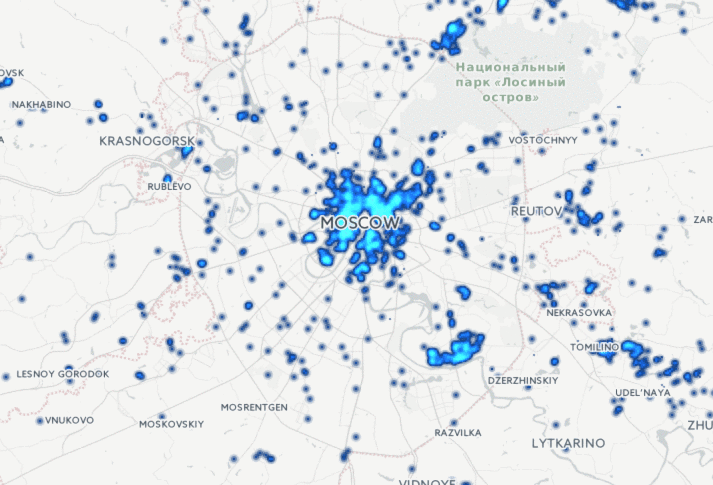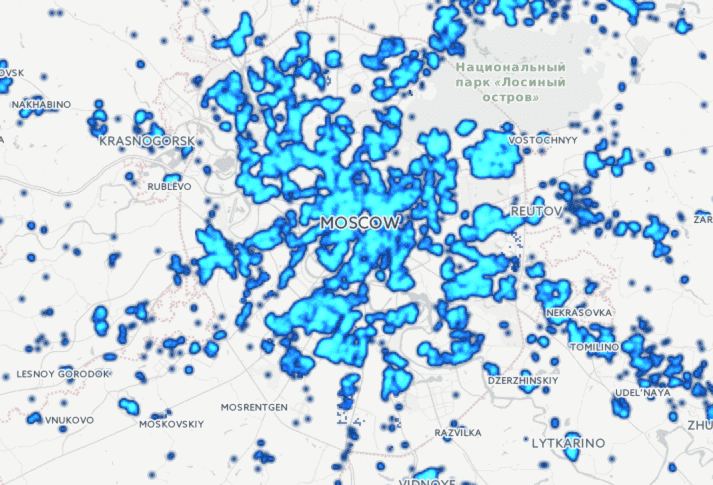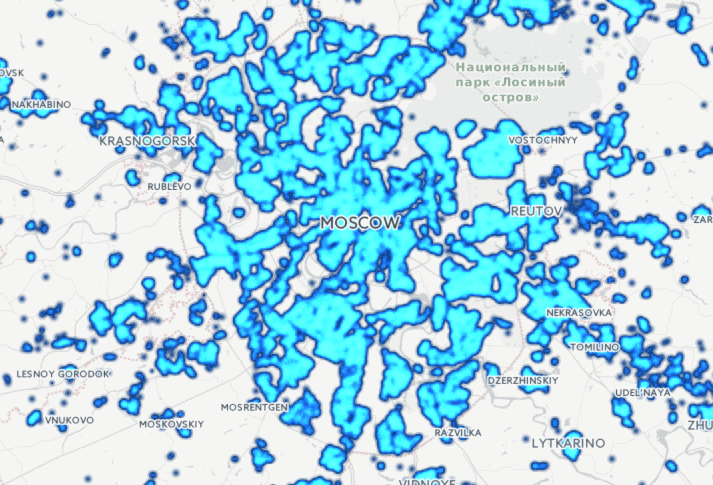
Сегодня мы анонсируем новую технологию
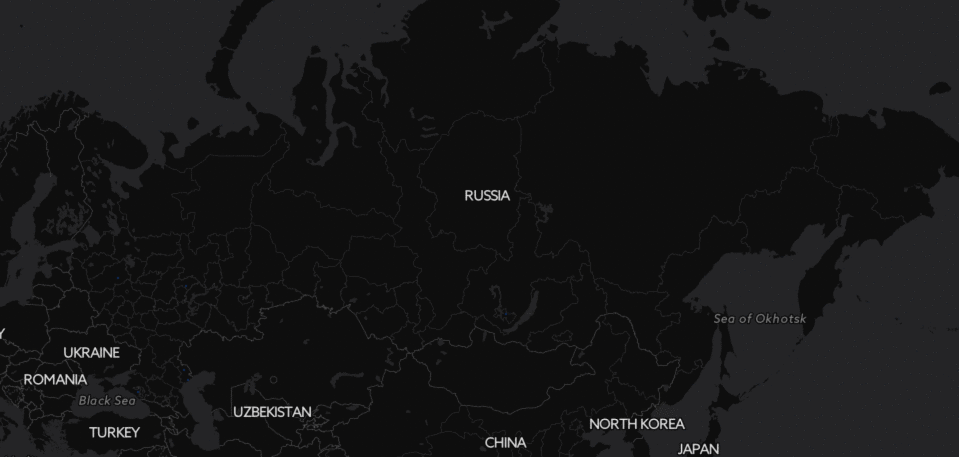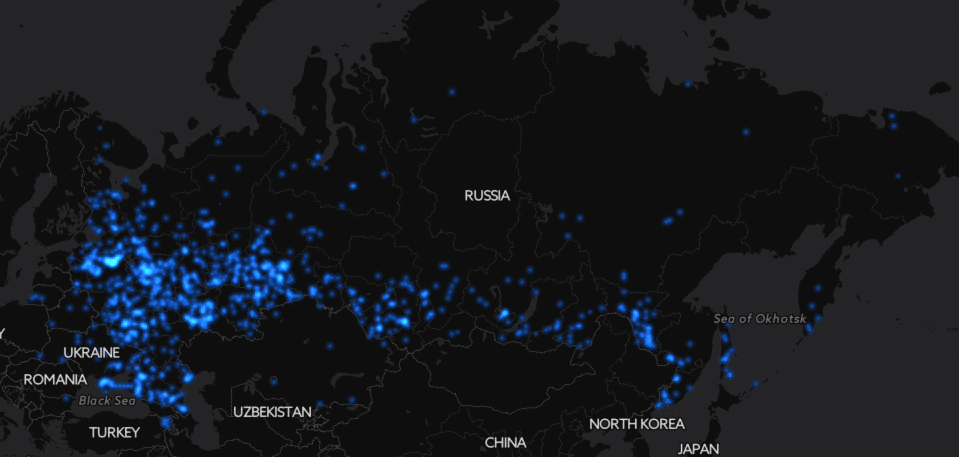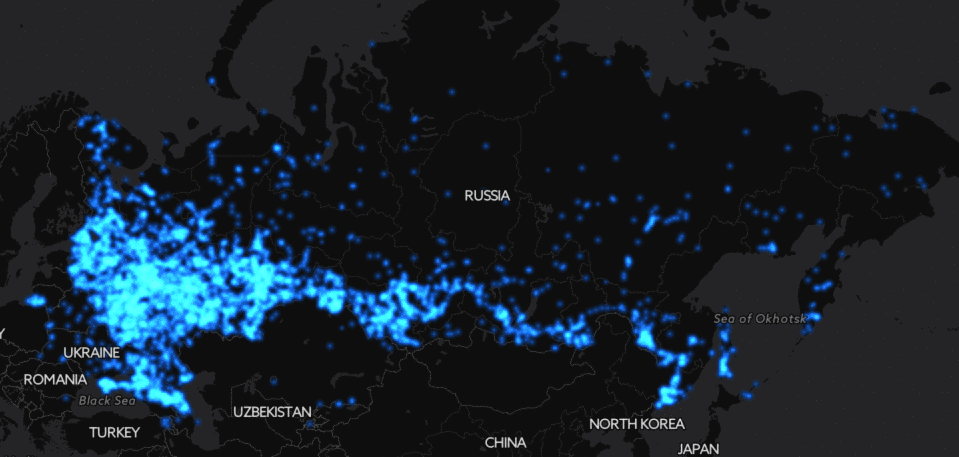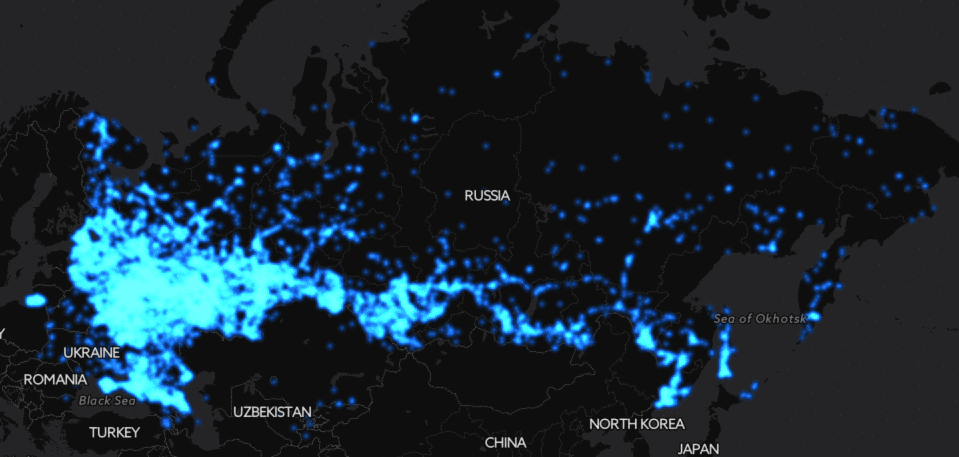
Метеум — теперь с её помощью Яндекс.Погода будет строить собственный прогноз погоды, а не полагаться только на данные партнёров, как это было раньше.
Причём прогноз будет рассчитываться отдельно для каждой точки, из которой вы его запрашиваете, и пересчитываться каждый раз, когда вы на него смотрите, чтобы быть максимально актуальным.

В этом посте я хочу рассказать немного о том, как в наше время устроен мир погодных моделей, чем наш подход отличается от обычных, почему мы решились строить собственный прогноз и почему верим, что у нас получится лучше, чем у всех остальных.
Мы построили собственный прогноз с использованием традиционной модели атмосферы и максимально подробной сеткой, но и постарались собрать все возможные источники данных об атмосферных условиях, статистику о том, как ведёт себя погода на деле, и применили к этим данным машинное обучение, чтобы уменьшить вероятность ошибок.
Сейчас в мире есть несколько основных моделей, по которым предсказывают погоду. Например, модель с открытым исходным кодом
WRF, модель GFS, которые изначально являлись американской разработкой. Сейчас ее развитием занимается агентство
NOAA.