Началось все, как водится, с ошибки. Я первый раз работал с
Java Native Interface и делал в C++ части обертку над функцией, создающей Java объект. Эта функция —
CallVoidMethod — вариативна, т.е. помимо указателя на среду
JNI, указателя на тип создаваемого объекта и идентификатора вызываемого метода (в данном случае конструктора), она принимает произвольное число других аргументов. Что логично, т.к. эти другие аргументы передаются вызываемому методу на стороне Java, а методы могут быть разные, с разным числом аргументов любых типов.
Соответственно и свою обертку я тоже сделал вариативной. Для передачи произвольного числа аргументов в
CallVoidMethod использовал
va_list, потому что по-другому в данном случае никак. Да, так и отправил
va_list в
CallVoidMethod. И уронил JVM банальным segmentation fault.
За 2 часа я успел перепробовать несколько версий JVM, от 8-ой до 11-ой, потому что: во-первых это мой первый опыт с
JVM, и в этом вопросе я StackOverflow доверял больше, чем себе, а во-вторых кто-то на StackOverflow посоветовал в таком случае использовать не OpenJDK, а OracleJDK, и не 8, а 10. И лишь потом я наконец заметил, что помимо вариативной
CallVoidMethod есть
CallVoidMethodV, которая произвольное число аргументов принимает через
va_list.
Что мне больше всего не понравилось в этой истории, так это то, что я не сразу заметил разницу между эллипсисом (многоточием) и
va_list. А заметив, не смог объяснить себе, в чем принципиальное отличие. Значит, надо разобраться и с эллипсисом, и с
va_list, и (поскольку речь все-таки о C++) с вариативными шаблонами.




 Современные компьютерные технологии, технические и программные решения — всё это сильно облегчает и ускоряет проведение различных научных исследований. Зачастую компьютерное моделирование — единственный способ проверки многих теорий. Научный софт имеет свои особенности. Например, такой софт зачастую подвергается очень тщательному тестированию, но слабо документирован. Тем не менее программное обеспечение пишется людьми, а люди допускают ошибки. Ошибки в научных программах могут ставить под сомнение целые исследования. В этой статье будут приведены десятки проблем, обнаруженных в коде пакета программ NCBI Genome Workbench.
Современные компьютерные технологии, технические и программные решения — всё это сильно облегчает и ускоряет проведение различных научных исследований. Зачастую компьютерное моделирование — единственный способ проверки многих теорий. Научный софт имеет свои особенности. Например, такой софт зачастую подвергается очень тщательному тестированию, но слабо документирован. Тем не менее программное обеспечение пишется людьми, а люди допускают ошибки. Ошибки в научных программах могут ставить под сомнение целые исследования. В этой статье будут приведены десятки проблем, обнаруженных в коде пакета программ NCBI Genome Workbench.

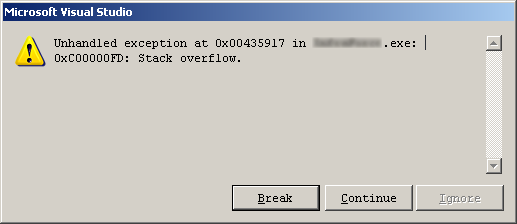
 Я говорю о неверном использовании функции
Я говорю о неверном использовании функции 







.jpg){kind=link}
{kind=link}