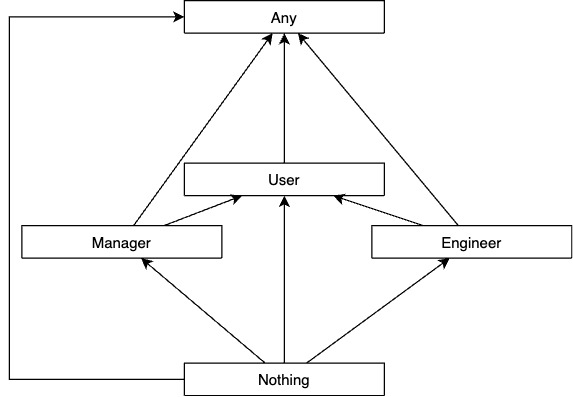
Хотя,
Clang и используется в качестве инструмента для рефакторинга и статического анализа, у него есть серьёзный недостаток: в абстрактном синтаксическом дереве не предоставляется информации о происхождении конкретных расширений-макросов на
CPP, за счёт которых может надстраиваться конкретный узел AST. Кроме того, Clang не понижает расширения-макросы на уровень LLVM, то есть, до кода в формате промежуточного представления (IR). Из-за этого оказывается запредельно сложно конструировать такие схемы статического анализа, при которых учитывались бы макросы. Сейчас эта тема активно исследуется. Но ситуация налаживается, поскольку прошлым летом был создан инструмент
Macroni, упрощающий статический анализ именно такого рода.
В Macroni разработчики могут определять синтаксис новых языковых конструкций на C с применением макросов, а также предоставлять семантику для этих конструкций при помощи
MLIR (многоуровневого промежуточного представления). В Macroni используется инструмент
VAST, понижающий код C до MLIR. В свою очередь, инструмент
PASTA позволяет выяснить, откуда те или иные макросы попали в AST, и на основании этой информации макросы также удаётся понизить до MLIR. После этого разработчики могут определять с
обственные MLIR-конвертеры для преобразования вывода Macroni в предметно-ориентированные диалекты MLIR, чтобы анализировать предмет с учётом многочисленных нюансов. В этой статье будет на нескольких примерах показано, как Macroni позволяет дополнять C более безопасными языковыми конструкциями и организовать анализ безопасности C.