Здравствуйте, меня зовут
Александр Зеленин и я веб-разработчик.
Информация — основа любого приложения или сервиса.

Более 10 лет назад я общался с владельцем покер-рума, и он показал мне страницу, приносившую около
10 000$ в день. Это была совершенно банально оформленная страница. На ней не было ни стилей, ни графики. Сплошной текст, разбитый заголовками, секциями и ссылками. У меня просто не укладывалось в голове — ну как вот это может приносить такие деньги?
Секрет в том, что «вот это» было одним из первых исчерпывающих руководств по игре в покер онлайн. У страницы был PageRank 10/10 (или 9, не суть), и в поисковой выдаче это было первое, на что натыкались.
Цель вашего приложения, какое бы оно ни было — донести (получить, обработать) некоторую информацию до пользователя.
Интернет магазин: информация о товаре, способы приобретения и доставки. Даже если это будет ужасный, некрасивый и неудобный сайт, пользователи всё равно найдут тот товар, который искали. Особенно, если вы торгуете чем-то достаточно уникальным (хотя бы в вашем регионе). Плюс поисковики вам помогут, выводя пользователя сразу к нужному товару.
Конечно, конверсия может быть ниже, или пользователь может быть не очень доволен опытом работы с сайтом, но, если сам товар будет именно тем, что он искал — всё остальное будет малозначимо.
Я не рассматриваю магазины, продающие «на эмоциях», и покупки, о которых пользователь может потом пожалеть.
Многопользовательская онлайн игра: информация об игроке, друзьях и окружающем его мире Примеры могут варьироваться в зависимости от жанра и других параметров, но в целом пользователя интересуют такие вещи, как история мира, переписка/общение с союзниками, информация о текущих событиях, информация об его персонаже/деревне/корабле/чем-угодно-другом.
Очень часто способ доступа к этой информации уходит за пределы самого клиента игры. С помощью мобильного приложения можно проверить, не нападает ли на тебя кто, или выставить какие-нибудь товары на внутриигровой аукцион, даже не заходя в саму игру.
Музыкальный стриминговый сервис — мета-информация + музыкальные файлы Пользователь хочет найти интересующую его музыку. Все обёртки, умные очереди, лицензионность и прочая шелуха мало кого интересует.
Конечно, хорошо использовать лицензионный контент, но если пользователь не может найти то, что искал — он уйдет и найдет это в другом месте. В интернете люди не запоминают информацию как таковую, они запоминают место, где эту информацию нашли. Поэтому, если на вашем сайте нет песен группы Х, но зато есть ссылка на страницу группы Х, где они продают свои альбомы, ваш сервис все равно в плюсе, потому что пользователь запомнил, где он взял информацию о группе Х и вернется к вам еще раз поискать информацию о группе Y.
Я работал в нескольких музыкальных проектах, и очень часто всё упиралось именно в наличие необходимых треков, несмотря на десятки терабайт данных.
Видео-сервис — видеозаписи В какой-то момент youtube набрал критическую массу видеозаписей и стал лидером рынка. У них был не самый удобный сайт, не самые лучшие условия. Вообще многое было не так, но именно обилие контента привлекало посетителей, и как следствие, контента становилось только больше.
Думаю, идею вы уже уловили. Примеры можно приводить бесконечно (вот ещё один: на википедию не за дизайном ходят. Более того, часть информации с википедии выводится сразу в поисковой выдаче, без открытия даже самого сайта), и если думаете, что в вашем случае это неприменимо — напишите в комментариях (или на почту / в личку), и я объясню, почему всё же применимо.
Так вот: чем бы вы ни занимались, первичной всегда будет информация. Хорошую, качественную информацию пользователи обязательно найдут и обратятся к вам.
Я расскажу, как организовать работу с информацией так, чтобы это было:
1. Масштабируемо — репликация, шардирование и т.п. настраивается БЕЗ вмешательства в работу приложения.
2. Удобно для пользователей — легко документировать, понятно как использовать.
3. Удобно для ваших разработчиков — быстрое прототипирование, возможности оптимизации только необходимого.
Данный подход не имеет смысла для вас, если у вас маленький проект с небольшим количеством компонентов и разработчиков.



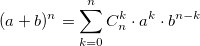 также использует биномиальные коэффициенты. Для их расчета можно использовать формулу, выражающую биномиальный коэффициент через факториалы:
также использует биномиальные коэффициенты. Для их расчета можно использовать формулу, выражающую биномиальный коэффициент через факториалы: 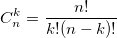 или использовать рекуррентную формулу:
или использовать рекуррентную формулу: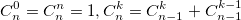 Из бинома Ньютона и рекуррентной формулы ясно, что биномиальные коэффициенты — целые числа.
Из бинома Ньютона и рекуррентной формулы ясно, что биномиальные коэффициенты — целые числа. 

 Мы продолжаем рассказывать интересные зарисовки из жизни колл-центров, телекомов и облачной телефонии. Случалось ли вам отвечать на звонок и слышать “пожалуйста подождите, оператор сейчас свяжется с вами”? Первая мысль, которая приходит в голову обычно нецензурна, вторая — “они что, вконец обнаглели?!?”. Получивший такой звонок пользователь — жертва хитрой технологии “предиктивного обзвона”, которая позволяет колл-центрам экономить сотни часов времени, но иногда приводит к забавным результатам. Под катом я расскажу про эту штуку подробнее и покажу, как она может быть реализована в несколько строк кода на нашей облачной платформе voximplant
Мы продолжаем рассказывать интересные зарисовки из жизни колл-центров, телекомов и облачной телефонии. Случалось ли вам отвечать на звонок и слышать “пожалуйста подождите, оператор сейчас свяжется с вами”? Первая мысль, которая приходит в голову обычно нецензурна, вторая — “они что, вконец обнаглели?!?”. Получивший такой звонок пользователь — жертва хитрой технологии “предиктивного обзвона”, которая позволяет колл-центрам экономить сотни часов времени, но иногда приводит к забавным результатам. Под катом я расскажу про эту штуку подробнее и покажу, как она может быть реализована в несколько строк кода на нашей облачной платформе voximplant
 Разработка Parallels Access потребовала создания геораспределенного сервиса, позволяющего безопасно устанавливать связь между компьютерами и мобильными клиентами пользователей в различных точках земного шара. Команда, которая над ним трудится, хочет поделиться полученным опытом в форме цитат, чтобы облегчить участь тем, кто только планирует создание своего клиент/серверного продукта, и погрузить в ностальгию профессионалов, имеющих за спиной дюжину успешных проектов:
Разработка Parallels Access потребовала создания геораспределенного сервиса, позволяющего безопасно устанавливать связь между компьютерами и мобильными клиентами пользователей в различных точках земного шара. Команда, которая над ним трудится, хочет поделиться полученным опытом в форме цитат, чтобы облегчить участь тем, кто только планирует создание своего клиент/серверного продукта, и погрузить в ностальгию профессионалов, имеющих за спиной дюжину успешных проектов: