
Развертывание нескольких моделей машинного обучения на одном сервере

В коммерческой разработке многие сценарии использования машинного обучения подразумевают мультитенантную архитектуру и требуют обучения отдельной модели для каждого клиента и/или пользователя.
В качестве примера можно рассмотреть прогнозирование закупок и спроса на какие-либо продукты с помощью машинного обучения. Если вы управляете сетью розничных магазинов, вы можете использовать данные истории покупок клиентов и итогового спроса на эти продукты для прогнозирования расходов и объёмов закупок для каждого магазина по отдельности.
Чаще всего в таких случаях для развёртывания моделей пишут службу Flask и помещают её в контейнер Docker. Примеров одномодельных серверов машинного обучения очень много, но когда дело доходит до развёртывания нескольких моделей, у разработчика остаётся не так много доступных вариантов для решения проблемы.
В мультитенантных приложениях количество арендаторов заранее не известно и может быть практически не ограничено — в какой-то момент у вас может быть только один клиент, а в другой момент вы можете обслуживать отдельные модели для каждого пользователя тысячам пользователей. Вот здесь и начинают проявляться ограничения стандартного подхода к развертыванию:



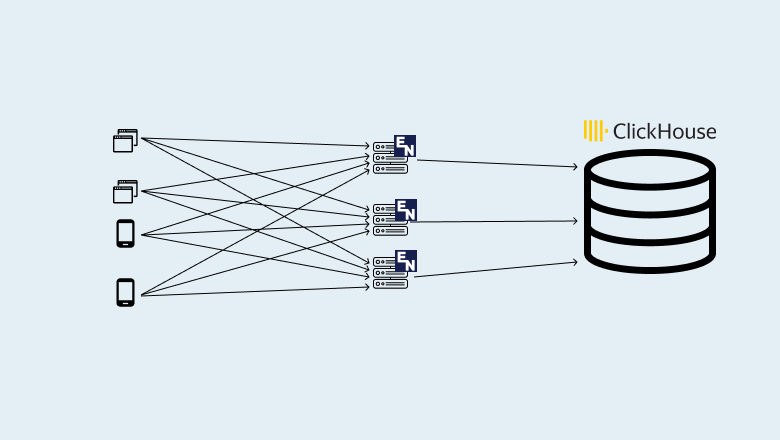



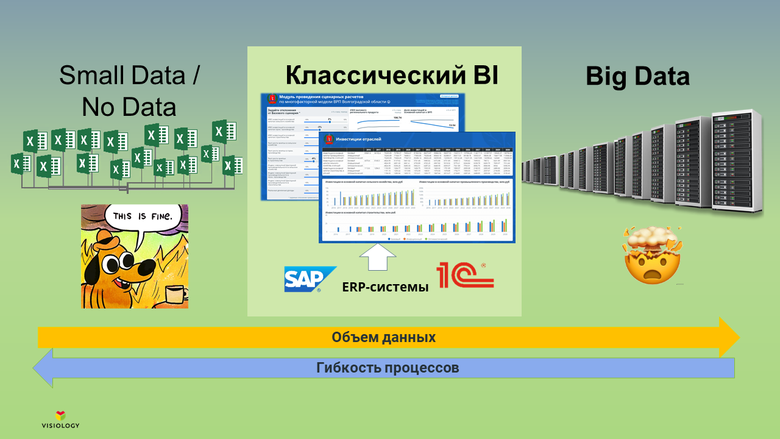

 Уэс МакКинни, о котором писали в Quartz как о человеке, «создавшем наиболее важный инструмент в области Data Science» (речь о пакете для анализе данных Pandas), отправляется в новое плавание – он запускает стартап под названием Ursa Computing.
Уэс МакКинни, о котором писали в Quartz как о человеке, «создавшем наиболее важный инструмент в области Data Science» (речь о пакете для анализе данных Pandas), отправляется в новое плавание – он запускает стартап под названием Ursa Computing.



