Как обложить сервис метриками и не облажаться
6 мин
Меня зовут Евгений Жиров, я разработчик в инфраструктурной команде Контур.Экстерна. Этот пост — текстовая версия моего доклада с недавнего митапа Perm Tech Talks.
У нас в команде 200 микросервисов, которые должны быть отказоустойчивыми, чтобы пользователи не замечали никаких проблем. А проблемы, конечно, возникают. Поэтому мы собираем метрики, чтобы знать, как дела у конкретных сервисов и у системы в целом. Метрики помогают вовремя среагировать и всё починить.
Метрики можно собирать, хранить и визуализировать. И есть много способов собрать метрики неправильно, нарисовать с ошибками и сделать неверные выводы.
Я расскажу о нескольких примерах из своей работы и поделюсь советами.
Какие бывают метрики?
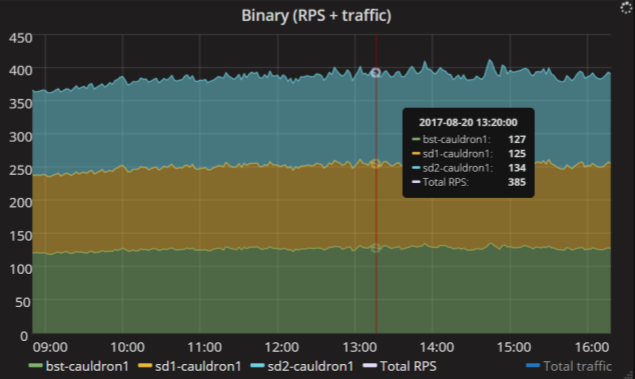
Метрика requests.count.byhost.*