Терминальная графика
8 мин
Туториал
Когда printf — мало, а ncurses — много
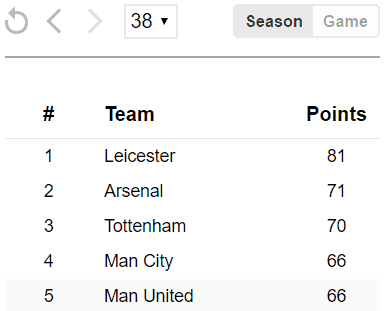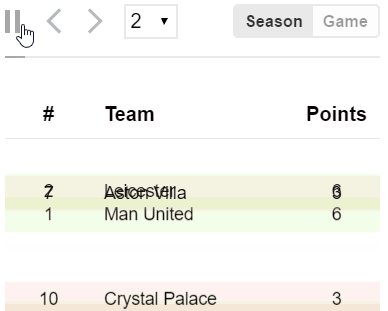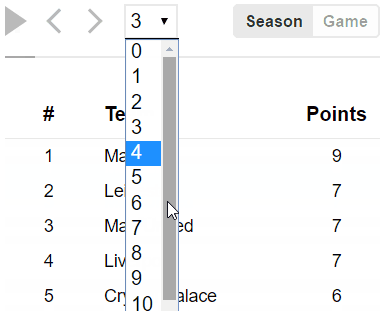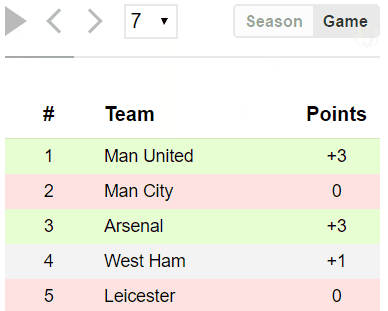
Когда данных становится слишком много, бывает не хватает стандартного вывода printf в консольной программе. Особенно если различных событий много и различные данные превращаются в безумный листинг. Эти данные могут поступать от контроллера через UART, и тут нечего и думать о какой-то gui-программе. Может так же быть и обычный bash-скрипт, к которому хочется прикрутить какой-никакой псевдографический интерфейс.
Когда данных становится слишком много, бывает не хватает стандартного вывода printf в консольной программе. Особенно если различных событий много и различные данные превращаются в безумный листинг. Эти данные могут поступать от контроллера через UART, и тут нечего и думать о какой-то gui-программе. Может так же быть и обычный bash-скрипт, к которому хочется прикрутить какой-никакой псевдографический интерфейс.