Пересечение морд доменов топ 1,000,000 по N-граммам
2 мин
Задачей исследования является визуализация дуплицированности главных страниц доменов по пятисловным шинглам в рамках общей базы.


Если вы ни разу не слышали об игре Pokemon Go, можно считать, что вам повезло. Новости о покемонах мелькают в новостных лентах, толпы людей бродят в ночи по кладбищам и воюют за сферы влияния. Только в Москве по данным МТС в Pokemon Go играет 180 000 человек, притом что в России официального запуска еще не было.
Мы в DaData.ru решили посмотреть, чем можем помочь любителям покемонов.


D3.js — это библиотека JavaScript для управления документами, в основе которых лежат данные. D3 помогает претворить данные в жизнь, используя HTML, SVG и CSS. D3 позволяет привязывать произвольные данные к DOM, и затем применять результаты манипуляций с ними к документу.

Внимание, футбол на Хабре! Вот этот пост побудил меня загрузить данные о распределении игроков команд-участниц Евро 2016 по национальным лигам, в которых они выступают. На значимый турнир в национальные сборные вызывают сильнейших на данный момент футболистов. По этой выборке мы можем сравнить между собой европейские футбольные первенства. Какие лиги самые представительные на Евро 2016 и за счет чьих сборных? Под катом графики (трафик) и немного рассуждений. Свисток, игра началась!


Однажды, мне стало интересно: насколько статьи на Хабре связаны между собой? Поэтому сегодня мы займемся исследованием связности статей, и конечно не только посчитаем численные метрики, но и увидим картину целиком.
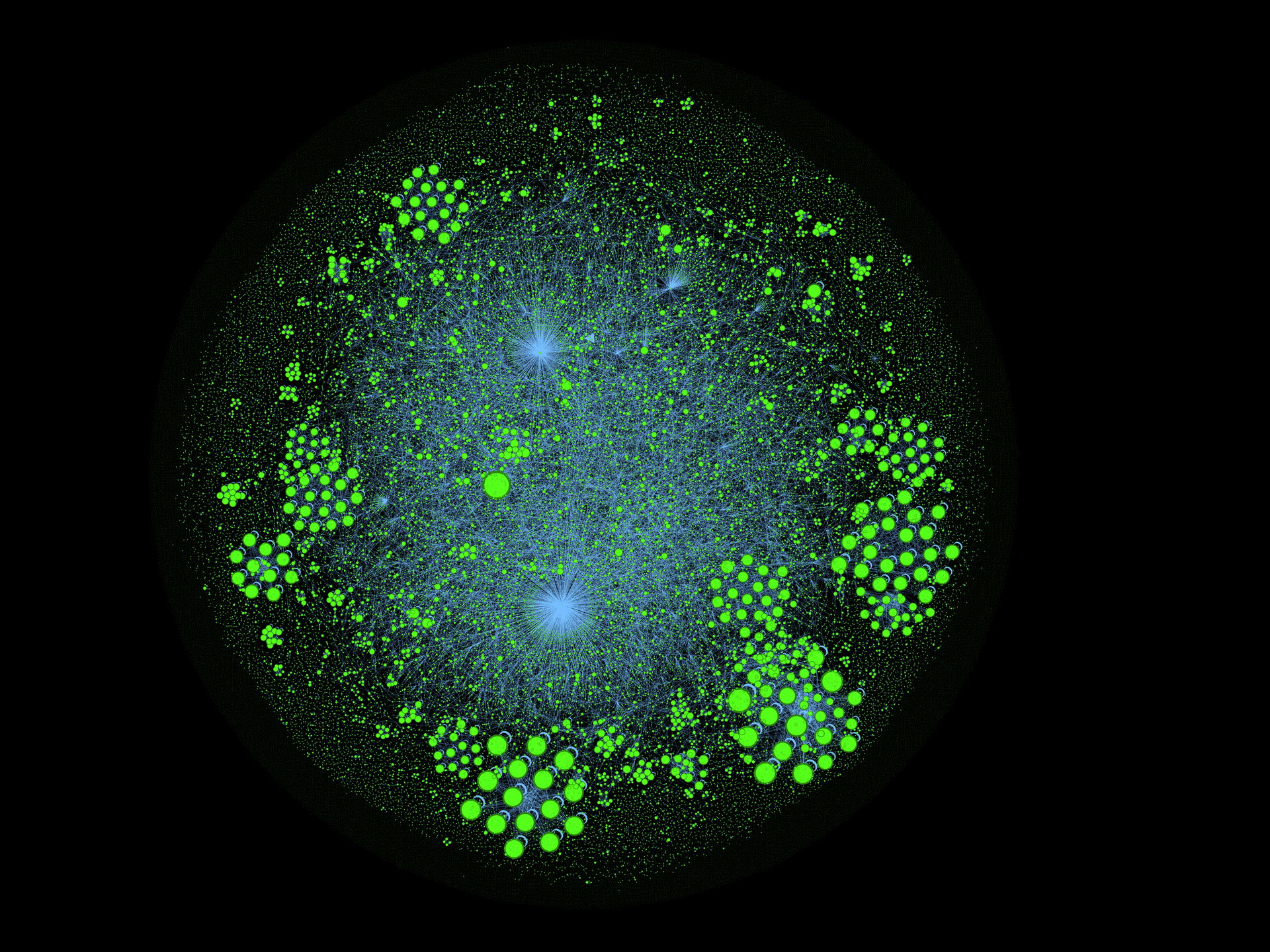
(это не просто картинка для привлечения внимания, а граф цитирования статей внутри Хабрахабра, где размер вершин определяется числом входящих рёбер, i.e., "количеством цитат внутри Хабра")
Началось всё с того, что в комментариях к статье про Хабра-граф и карму Tiberius и Loriowar озвучили идею, фактически витающую в воздухе: а почему бы не взглянуть на граф цитирования статьёй внутри самого Хабра?
Вы спрашивали? Мы отвечаем. Для того чтобы рассказ не был размахиванием рук, конкретизируем разбираемые вопросы:
Q1: Как выглядит граф цитирования Хабрахабра и какие в нём хабы (hubs and authorities)?
Q2: Насколько связным является сообщество (граф цитирования) и какие в нём кластеры?
Под катом трафик. Все картинки кликабельны.
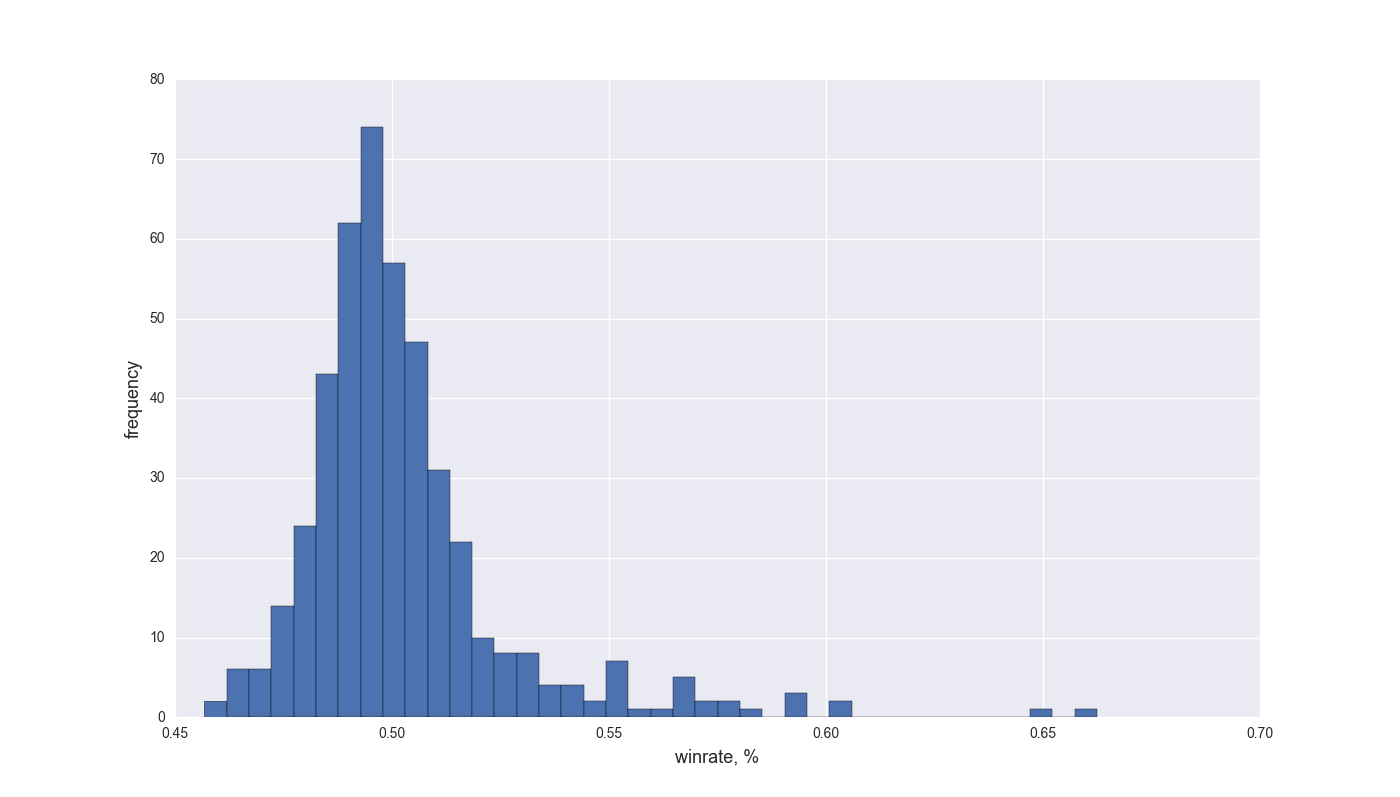
Сегодня мы поговорим об использовании Wargaming API, построим много графиков и проанализируем, от чего же зависит винрейт танков. Сразу хочу отметить, что я не гуру World of Tanks, и если я где-то ошибся, то напишите пожалуйста в комментариях. Все графики кликабельны.



На днях завершился очередной чемпионат мира по хоккею.
За просмотром матчей родилась идея. Когда в перерывах телевизионная камера показывает уходящих в раздевалку игроков, трудно не заметить, насколько они огромные. На фоне тренеров, функционеров команд, сотрудников ледовой арены, журналистов или просто фанатов они, как правило, выглядят очень внушительно.
И я задался вопросами. Действительно ли хоккеисты выше обычных людей? Как изменяется рост хоккеистов со временем в сравнении с обычными людьми? Есть ли устойчивые межстрановые различия?
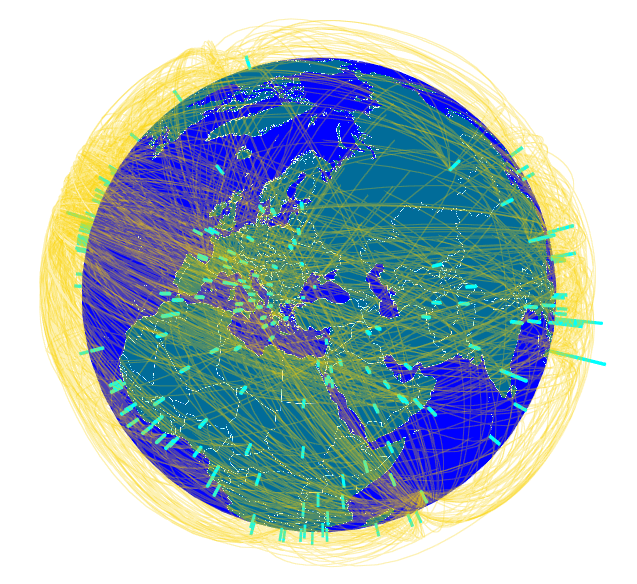 Как многим известно из прессы, международный консорциум журналистов-расследователей (ICIJ) выложил в свободный доступ, так называемый «Панамский архив»: сведения о лицах, связанных с офшорными компаниями по всему миру, полученные неизвестными лицами из панамской юридической фирмы Mossack Fonseca.
Как многим известно из прессы, международный консорциум журналистов-расследователей (ICIJ) выложил в свободный доступ, так называемый «Панамский архив»: сведения о лицах, связанных с офшорными компаниями по всему миру, полученные неизвестными лицами из панамской юридической фирмы Mossack Fonseca.
Можно по разному относиться и к самим этим данным, к способу их получения и публикации в открытом доступе. Но, если абстрагироваться от этих вопросов, то это просто информация, которую можно обработать и на которую можно посмотреть с разных углов (в прямом смысле).

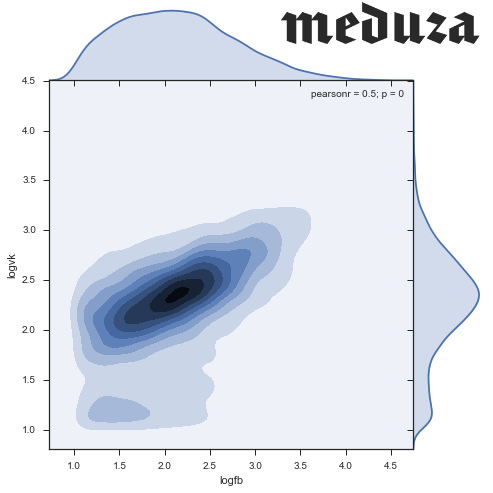
Как-то раз, читая новости на Медузе, я обратил внимание на то, что у разных новостей разное соотношение лайков из Facebook и ВКонтакте. Какие-то новости мегапопулярны на fb, а другими люди делятся только во ВКонтакте. Захотелось присмотреться к этим данным, попытаться найти в них интересные закономерности. Заинтересовавшихся приглашаю под кат!