Визуализация concurrency в Go с WebGL
12 мин
Одной из самых сильных сторон языка программирования Go является встроенная поддержка concurrency, основанная на труде Тони Хоара «Communicating Sequential Processes». Go создан для удобной работы с многопоточным программированием и позволяет очень легко строить довольно сложные concurrent-программы. Но задумывались ли вы когда-нибудь, как выглядят различные паттерны concurrency визуально?
Конечно, задумывались. Все мы, так или иначе, мыслим визуальными образами. Если я попрошу вас о чём-то, что включает числа «от 1 до 100», вы мгновенно их «увидите» в своей голове в той или иной форме, вероятно даже не отдавая себе в этом отчёт. Я, к примеру, ряд от 1 до 100 вижу как линия с числами уходящая от меня, поворачивающая на 90 градусов вправо на числе 20 и продолжающая до 1000+. И, покопавшись в памяти, я вспоминаю, что в самом первом детском саду в раздевалке вдоль стены были написаны номерки, и число 20 было как-раз в углу. У вас же, вероятно, какое-то свое представление. Или вот, другой частый пример — представьте круглый год и 4 сезона года — кто-то их видит как квадрат, каждая грань которого принадлежит сезону, кто-то — как круг, кто-то ещё как-то.
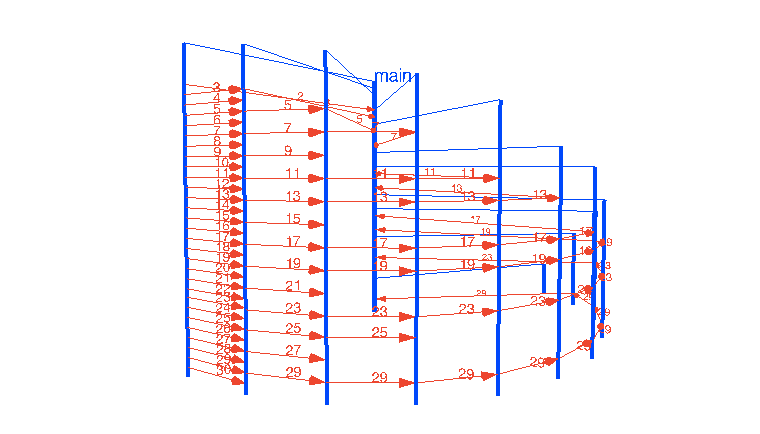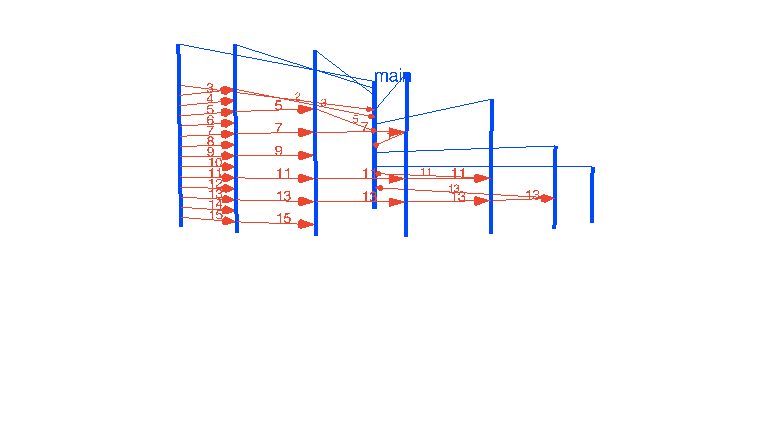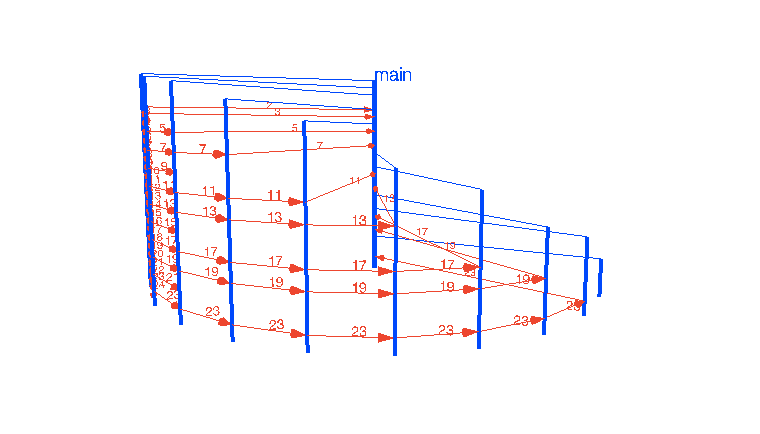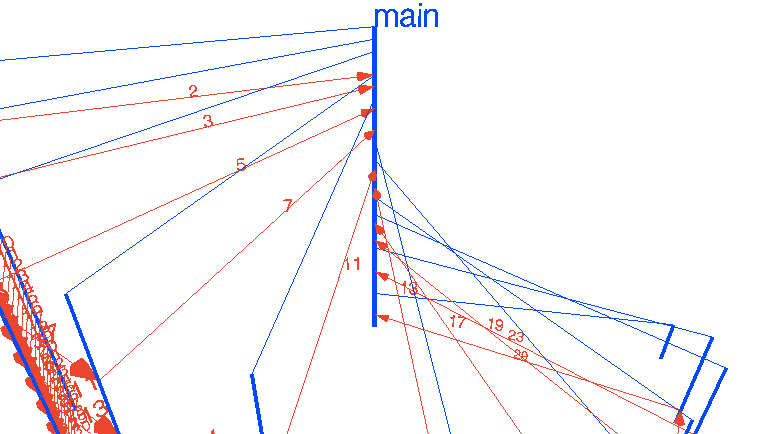
Так или иначе, позвольте мне показать мою попытку визуализировать основные паттерны concurrency с помощью Go и WebGL. Эти интерактивные визуализации более-менее отражают то, как я вижу это в своей голове. Интересно будет услышать, насколько это отличается от визуализаций читателей.
Конечно, задумывались. Все мы, так или иначе, мыслим визуальными образами. Если я попрошу вас о чём-то, что включает числа «от 1 до 100», вы мгновенно их «увидите» в своей голове в той или иной форме, вероятно даже не отдавая себе в этом отчёт. Я, к примеру, ряд от 1 до 100 вижу как линия с числами уходящая от меня, поворачивающая на 90 градусов вправо на числе 20 и продолжающая до 1000+. И, покопавшись в памяти, я вспоминаю, что в самом первом детском саду в раздевалке вдоль стены были написаны номерки, и число 20 было как-раз в углу. У вас же, вероятно, какое-то свое представление. Или вот, другой частый пример — представьте круглый год и 4 сезона года — кто-то их видит как квадрат, каждая грань которого принадлежит сезону, кто-то — как круг, кто-то ещё как-то.
Так или иначе, позвольте мне показать мою попытку визуализировать основные паттерны concurrency с помощью Go и WebGL. Эти интерактивные визуализации более-менее отражают то, как я вижу это в своей голове. Интересно будет услышать, насколько это отличается от визуализаций читателей.


 Призы
Призы 
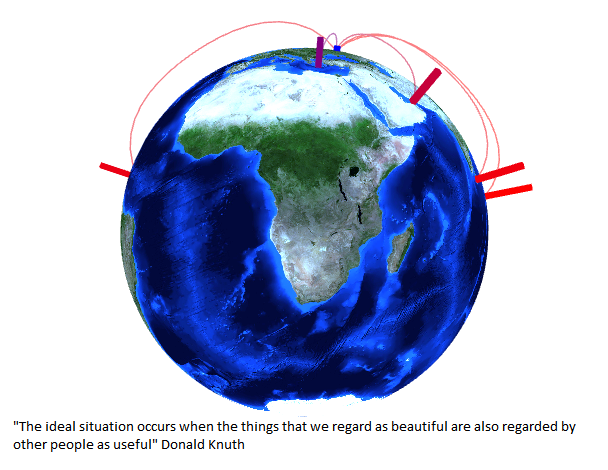 В то время как за окном температура на пути к очередным рекордам, интересно посмотреть, а какие вообще бывали температуры в произвольный интервал времени, за любые года за последние несколько десятилетий в 30 000 точках по всему миру. А может не прогадать с днями отпуска, и взять их в те дни, когда есть какое-то «статистическое преимущество» в выбранном местоположении по теплой погоде, а может быть по холодной, оценив его визуально на любой из трех типов диаграмм. Ну или можно просто повращать глобус, визуально оценить разнообразие температур и «как прекрасен этот мир».
В то время как за окном температура на пути к очередным рекордам, интересно посмотреть, а какие вообще бывали температуры в произвольный интервал времени, за любые года за последние несколько десятилетий в 30 000 точках по всему миру. А может не прогадать с днями отпуска, и взять их в те дни, когда есть какое-то «статистическое преимущество» в выбранном местоположении по теплой погоде, а может быть по холодной, оценив его визуально на любой из трех типов диаграмм. Ну или можно просто повращать глобус, визуально оценить разнообразие температур и «как прекрасен этот мир».  Недавно мы рассказывали здесь о том,
Недавно мы рассказывали здесь о том,