Для пользователя
наш СБИС представляется единой системой управления бизнесом, но внутри состоит из множества взаимодействующих сервисов. И чем их становится больше — тем выше вероятность возникновения каких-то неприятностей, которые необходимо вовремя отлавливать, исследовать и пресекать.
Поэтому, когда на каком-то из
тысяч подконтрольных серверов случается аномальное потребление ресурсов (CPU, памяти, диска, сети, ...), возникает потребность разобраться «кто виноват, и что делать».
Для оперативного мониторинга использования ресурсов Linux-сервера «в моменте» существует
утилита pidstat. То есть если пики нагрузки периодичны — их можно «высидеть» прямо в консоли. Но мы-то хотим эти данные
анализировать постфактум, пытаясь найти процесс, создавший максимальную нагрузку на ресурсы.
То есть хочется иметь возможность смотреть по ранее собранным данным разные красивые отчеты с группировкой и детализацией на интервале типа таких:
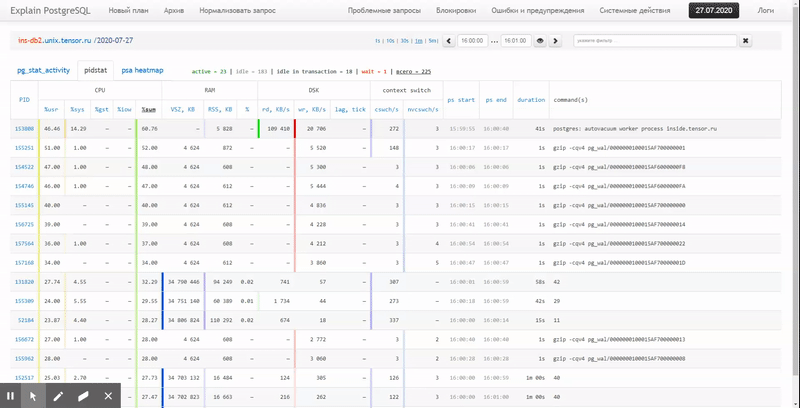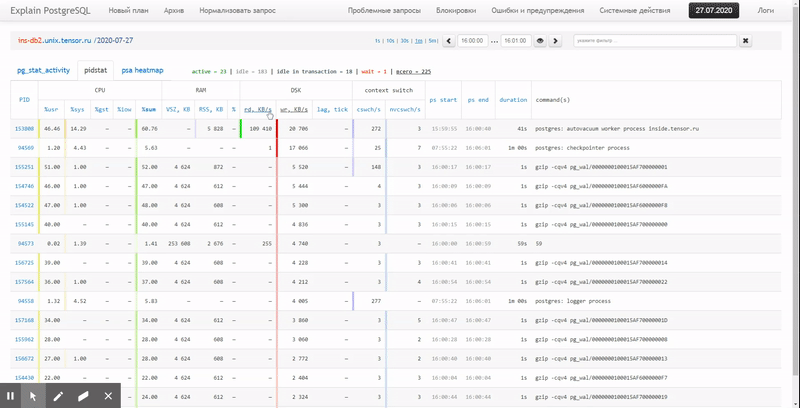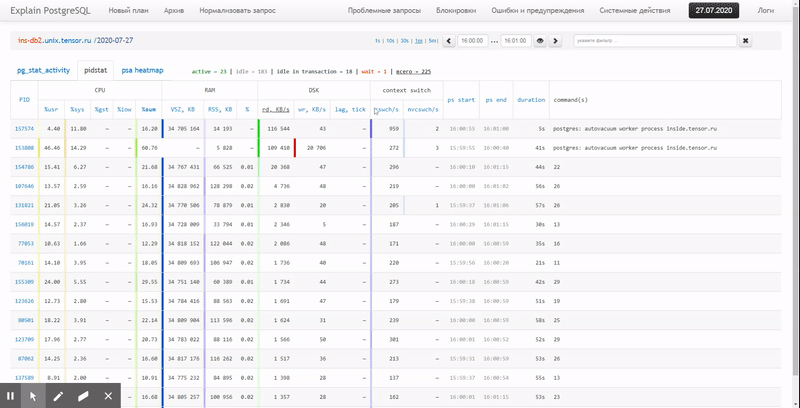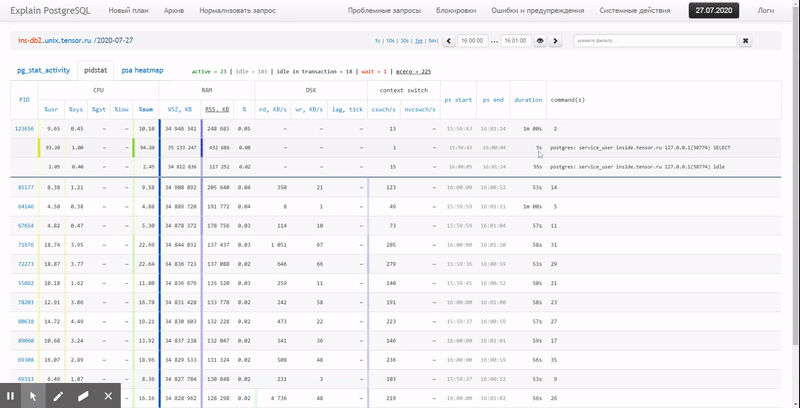
В этой статье рассмотрим, как все это можно экономично расположить в БД, и как максимально эффективно собрать по этим данным отчет с помощью
оконных функций и GROUPING SETS.